大数据Hive和Impala经典分析
目录
一、Impala是什么???
二、Impala架构
三、Impala和Hive的关系
四、Impala的安装(含使用CM和手动安装)
五、Impala缺点
六、Impala shell
七、Impala管理
八、Impala存储和分区
九、Impala SQL
十、Impala数据处理(加载和存储)
十一、Impala 和HBase整合
十二、Impala通过JDBC方式访问(Kerberos和无Kerberos环境情况)
十三、Impala性能优化
一、Impala是什么???
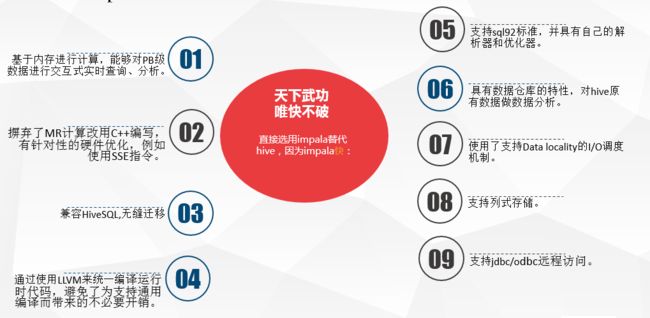
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
Impala是参照谷歌新三篇论文Dremel的开源实现,和Shark、Drill功能相似。Impala是Cloudera公司主导开发并开源。基于Hive并使用内存进行计算,兼顾数据仓库,具有实时、批处理、多并发等优点。是使用CDH的首选PB级大数据实时查询分析引擎。
谷歌旧三篇论文:mapreduce(mapreduce) 、 bigtable(HBase) 、 gfs(HDFS)
谷歌新三篇论文:Dremel(Impala)、Caffeine、Pergel。
同时,Impala由Cloudera公司开发,可以对存储在HDFS、HBase的海量数据提供交互式查询的SQL接口。除了和Hive使用相同的统一存储平台,Impala还提供了一个熟悉的面向批量或实时查询的统一平台。Impala的特点是查询非常迅速,其性能大幅领先于Hive。
注意:Impala并没有基于MapReduce的计算框架,这也是Impala可以大幅领先Hive的原因,Impala是定位是OLAP。
二、Impala架构
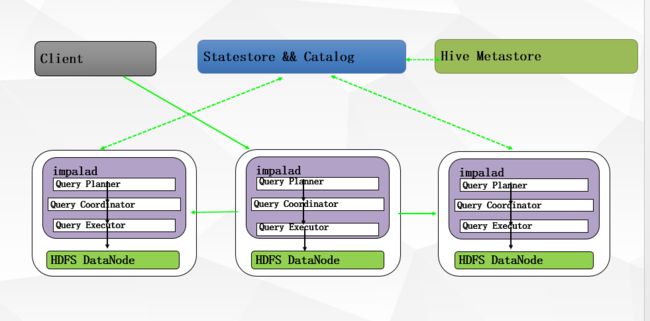
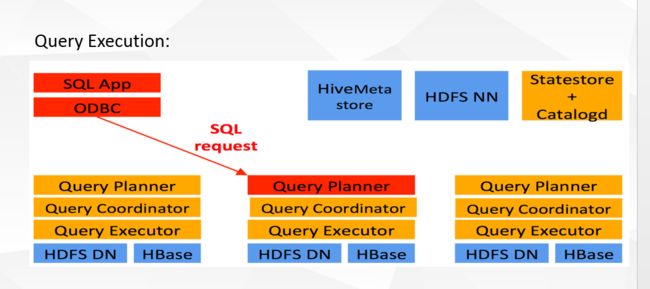
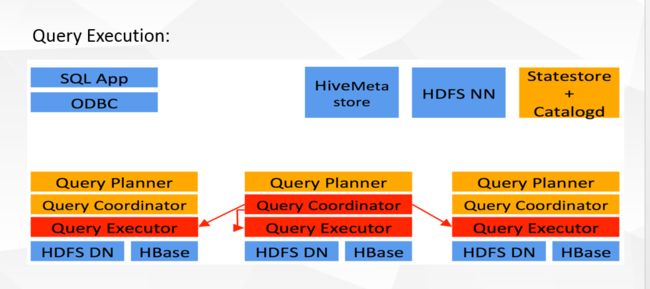
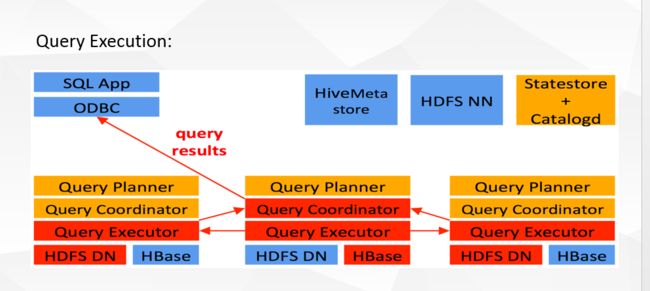
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的 Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。其架构如图 1所示,Impala主要由Impalad, State Store和CLI组成。
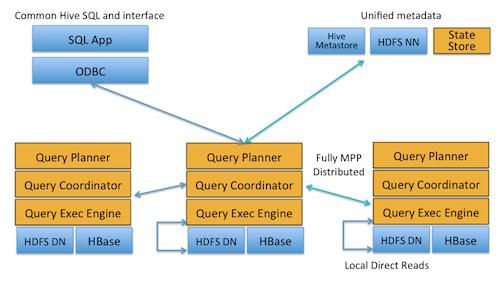
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为 Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应 数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给 客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各 Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
Impala三大进程由Impalad,statestored,catalogd

三、Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
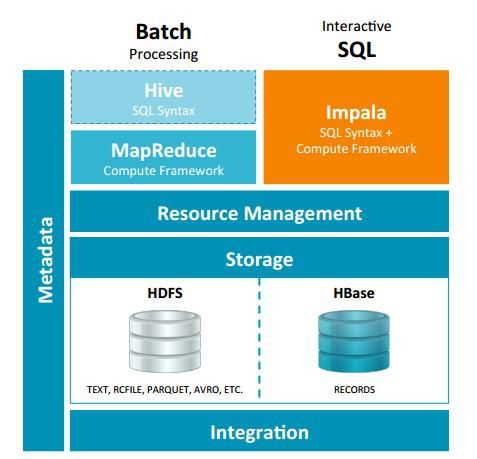
Impala相对于Hive所使用的优化技术
-
1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
- 2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
- 3、充分利用可用的硬件指令(SSE4.2)。
- 4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
- 5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
- 6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
-
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
- 元数据:两者使用相同的元数据。
- SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
- Hive: 任务调度依赖于Hadoop的调度策略。
- Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器 目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
容错:
- Hive: 依赖于Hadoop的容错能力。
- Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个 Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不 会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
适用面:
- Hive: 复杂的批处理查询任务,数据转换任务。
- Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
impala 与Hive都是构建在Hadoop之上的数据查询工具,但是各有不同侧重,那么我们为什么要同时使用这两个工具呢?单独使用Hive或者Impala不可以吗?
1、介绍Impala和Hive
(1)Impala和Hive都是提供对HDFS/Hbase数据进行SQL查询的工具,Hive会转换成MapReduce,借助于YARN进行调度从而实现对HDFS的数据的访问,而Impala直接对HDFS进行数据查询。但是他们都是提供如下的标准SQL语句,在机身里运行。
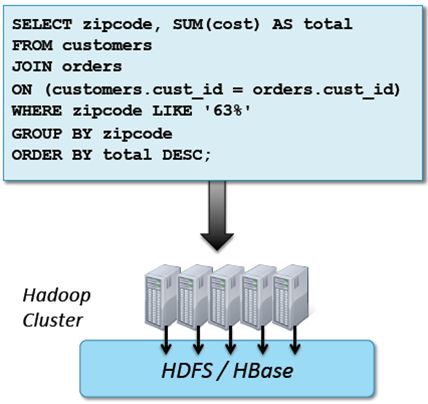
(2)Apache Hive是MapReduce的高级抽象,使用HiveQL,Hive可以生成运行在Hadoop集群的MapReduce或Spark作业。Hive最初由Facebook大约在2007年开发,现在是Apache的开源项目。
Apache Impala是高性能的专用SQL引擎,使用Impala SQL,因为Impala无需借助任何的框架,直接实现对数据块的查询,所以查询延迟毫秒级。Impala受到Google的Dremel项目启发,2012年由Cloudera开发,现在是Apache开源项目。
2、Impala和Hive有什么不同?
(1)Hive有很多的特性:
1、对复杂数据类型(比如arrays和maps)和窗口分析更广泛的支持
2、高扩展性
3、通常用于批处理
(2)Impala更快
1、专业的SQL引擎,提供了5x到50x更好的性能
2、理想的交互式查询和数据分析工具
3、更多的特性正在添加进来
3、高级概述:
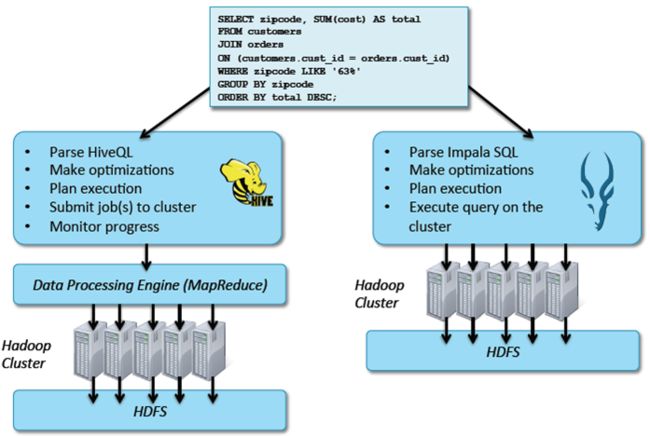
4、为什么要使用Hive和Impala?
1、为数据分析人员带来了海量数据分析能力,不需要软件开发经验,运用已掌握的SQL知识进行数据的分析。
2、比直接写MapReduce或Spark具有更好的生产力,5行HiveQL/Impala SQL等同于200行或更多的Java代码。
3、提供了与其他系统良好的互操作性,比如通过Java和外部脚本扩展,而且很多商业智能工具支持Hive和Impala。
5、Hive和Impala使用案例
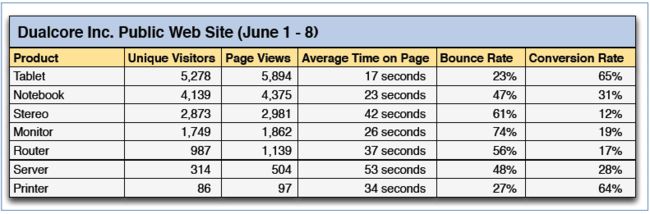
(1)日志文件分析
日志是普遍的数据类型,是当下大数据时代重要的数据源,结构不固定,可以通过Flume和kafka将日志采集放到HDFS,然后分析日志的结构,根据日志的分隔符去建立一个表,接下来运用Hive和Impala 进行数据的分析。例如:
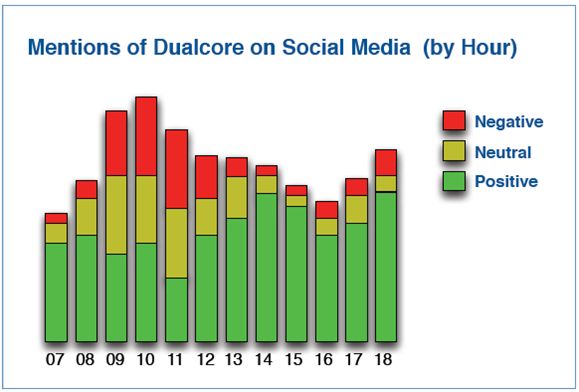
(2)情感分析
很多组织使用Hive或Impala来分析社交媒体覆盖情况。例如:
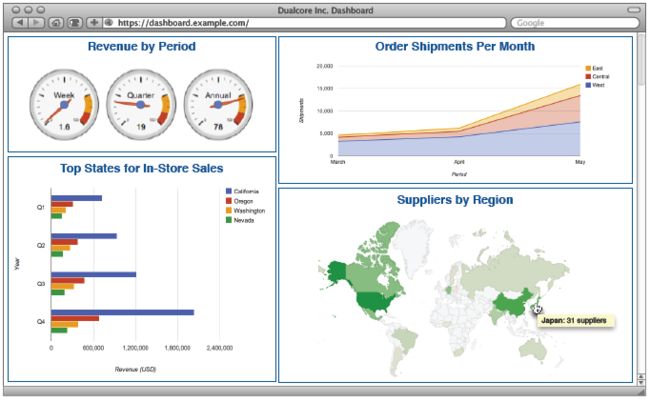
(3)商业智能
很多领先的BI工具支持Hive和Impala
四、Impala的安装(含使用CM和手动安装)
1、 Impala有两种安装方式:
1)使用CM安装Impala
2)手动安装Impala
注意:Impala不支持在Debian/Ubuntu, SuSE, RHEL/CentOS 6.5系统中安装。
2、基于CM的Impala安装
首先在CM端安装Hive,再安装Impala的组件。 参考博客 : https://blog.csdn.net/yangshaojun1992/article/details/78243031
3、手动安装Impala
参考博客:
http://blog.csdn.net/shenliang1985/article/details/51420056
http://blog.csdn.net/cqboy1991/article/details/38293733?utm_source=tuicool&utm_medium=referral
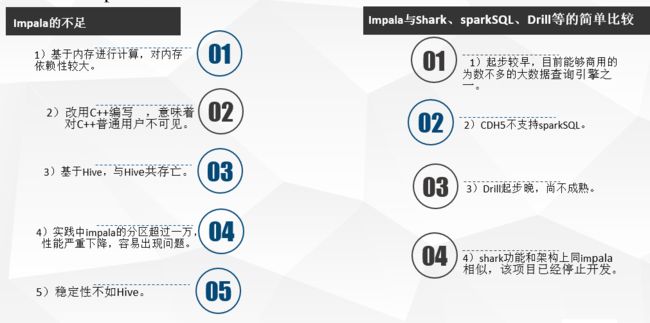
五、Impala缺点
优点:
- 支持SQL查询,快速查询大数据。
- 可以对已有数据进行查询,减少数据的加载,转换。
- 多种存储格式可以选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
- 可以与Hive配合使用。
缺点:
- 不支持用户定义函数UDF。
- 不支持text域的全文搜索。
- 不支持Transforms。
- 不支持查询期的容错。
- 对内存要求高。
六、Impala shell



impala-shell 命令行选项
你可以在启动 impala-shell 时设置以下选项,用于修改命令执行环境。
![]() Note:
Note:
这些选项与 impalad 守护进程的配置选项不同。关于 impalad 选项,参见 Modifying Impala Startup Options。
| 选项 |
描述 |
|---|---|
| -B or --delimited |
导致使用分隔符分割的普通文本格式打印查询结果。当为其他 Hadoop 组件生成数据时有用。对于避免整齐打印所有输出的性能开销有用,特别是使用查询返回大量的结果集进行基准测试的时候。使用 --output_delimiter 选项指定分隔符。使用 -B 选项常用于保存所有查询结果到文件里而不是打印到屏幕上。在 Impala 1.0.1 中添加 |
| --print_header |
是否打印列名。整齐打印时是默认启用。同时使用 -B 选项时,在首行打印列名 |
| -o filename or --output_file filename |
保存所有查询结果到指定的文件。通常用于保存在命令行使用 -q 选项执行单个查询时的查询结果。对交互式会话同样生效;此时你只会看到获取了多少行数据,但看不到实际的数据集。当结合使用 -q 和 -o 选项时,会自动将错误信息输出到 /dev/null(To suppress these incidental messages when combining the -q and -o options, redirect stderr to /dev/null)。在 Impala 1.0.1 中添加 |
| --output_delimiter=character |
当使用 -B 选项以普通文件格式打印查询结果时,用于指定字段之间的分隔符(Specifies the character to use as a delimiter between fields when query results are printed in plain format by the -B option)。默认是制表符 tab ('\t')。假如输出结果中包含了分隔符,该列会被引起且/或转义( If an output value contains the delimiter character, that field is quoted and/or escaped)。在 Impala 1.0.1 中添加 |
| -p or --show_profiles |
对 shell 中执行的每一个查询,显示其查询执行计划 (与 EXPLAIN 语句输出相同) 和发生低级故障(low-level breakdown)的执行步骤的更详细的信息 |
| -h or --help |
显示帮助信息 |
| -i hostname or --impalad=hostname |
指定连接运行 impalad 守护进程的主机。默认端口是 21000。你可以连接到集群中运行 impalad 的任意主机。假如你连接到 impalad 实例通过 --fe_port 标志使用了其他端口,则应当同时提供端口号,格式为 hostname:port |
| -q query or --query=query |
从命令行中传递一个查询或其他 shell 命令。执行完这一语句后 shell 会立即退出。限制为单条语句,可以是 SELECT, CREATE TABLE, SHOW TABLES, 或其他 impala-shell 认可的语句。因为无法传递 USE 语句再加上其他查询,对于 default 数据库之外的表,应在表名前加上数据库标识符(或者使用 -f 选项传递一个包含 USE 语句和其他查询的文件) |
| -f query_file or --query_file=query_file |
传递一个文件中的 SQL 查询。文件内容必须以分号分隔 |
| -k or --kerberos |
当连接到 impalad 时使用 Kerberos 认证。如果要连接的 impalad 实例不支持 Kerberos,将显示一个错误 |
| -s kerberos_service_name or --kerberos_service_name=name |
Instructs impala-shell to authenticate to a particular impalad service principal. 如何没有设置 kerberos_service_name ,默认使用 impala。如何启用了本选项,而试图建立不支持 Kerberos 的连接时,返回一个错误(If this option is used in conjunction with a connection in which Kerberos is not supported, errors are returned) |
| -V or --verbose |
启用详细输出 |
| --quiet |
关闭详细输出 |
| -v or --version |
显示版本信息 |
| -c |
查询执行失败时继续执行 |
| -r or --refresh_after_connect |
建立连接后刷新 Impala 元数据,与建立连接后执行 REFRESH 语句效果相同 |
| -d default_db or --database=default_db |
指定启动后使用的数据库,与建立连接后使用 USE 语句选择数据库作用相同,如果没有指定,那么使用 default 数据库 |
| -l | 启用 LDAP 认证 |
| -u | 当使用 -l 选项启用 LDAP 认证时,提供用户名(使用短用户名,而不是完整的 LDAP 专有名称(distinguished name)) ,shell 会提示输入密码 |
1、Impala 外部 Shell
Impala外部Shell 就是不进入Impala内部,直接执行的ImpalaShell 例如通过外部Shell查看Impala帮助可以使用: $ impala-shell -h 这样就可以查看了;
再例如显示一个SQL语句的执行计划: $ impala-shell -p select count(*) from t_stu
下面是Impala的外部Shell的一些参数:
• -h (--help) 帮助
• -v (--version) 查询版本信息
• -V (--verbose) 启用详细输出
• --quiet 关闭详细输出
• -p 显示执行计划
• -i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000
• -r(--refresh_after_connect)刷新所有元数据
• -q query (--query=query) 从命令行执行查询,不进入impala-shell
• -d default_db (--database=default_db) 指定数据库
• -B(--delimited)去格式化输出
• --output_delimiter=character 指定分隔符
• --print_header 打印列名
• -f query_file(--query_file=query_file)执行查询文件,以分号分隔
• -o filename (--output_file filename) 结果输出到指定文件
• -c 查询执行失败时继续执行
• -k (--kerberos) 使用kerberos安全加密方式运行impala-shell
• -l 启用LDAP认证
• -u 启用LDAP时,指定用户名
2、Impala内部Shell
使用命令 $ impala-sehll 可以进入impala,在这里可以像Hive一样正常使用SQL,而且还有一些内部的impala命令:
• help
• connect
• refresh
• invalidate metadata 全量刷新元数据库
• explain
• set explain_level 设置显示级别(0,1,2,3)
• shell
• profile (查询完成后执行) 查询最近一次查询的底层信息
例:查看帮助可以直接使用: help ,要刷新一个表的增量元数据可以使用 refresh t_stu;
七、Impala管理
可以通过下面的链接来访问Impala的监护管理页面:
• 查看StateStore
– http://node1:25020/
• 查看Catalog
– http://node1:25010/
注意:我这里是放在netcloud01节点上。
八、Impala存储和分区
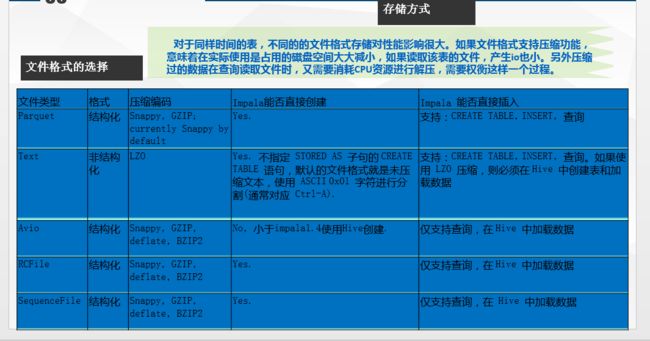

hive的元数据存储在/user/hive/warehouse
Impala的内部表也在/user/hive/warehouse。
那两者怎么区分,看前面的第一列。
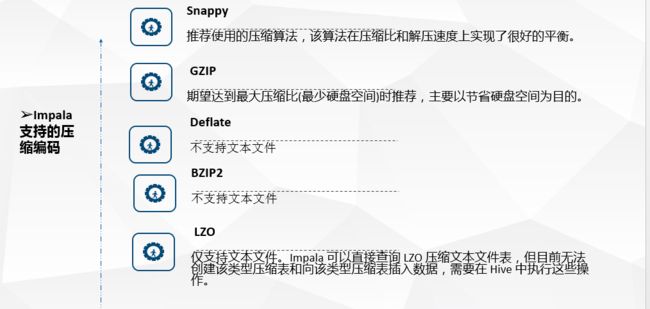
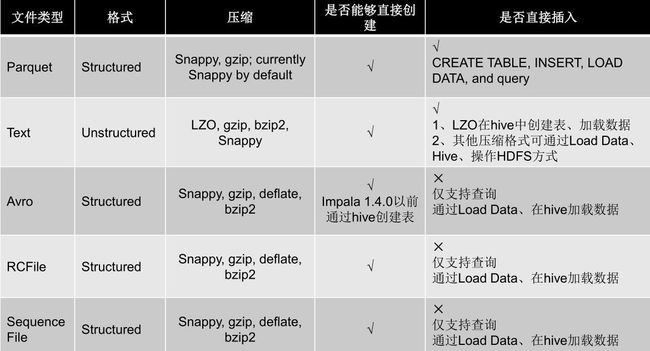
下面是Impala对文件的格式及压缩类型的支持
• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);• 分区内添加数据
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23)
insert into t_person partition (type='coder') values(3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)
• 查询指定分区数据
select id,name from t_person where type=‘coder
进行数据分区将会极大的提高数据查询的效率,尤其是对于当下大数据的运用,是一门不可或缺的知识。那数据怎么创建分区呢?数据怎样加载到分区
1、 Impala/Hive按State分区Accounts
(1)示例:accounts是非分区表

通过以上方式创建的话,数据就存放在accounts目录里面。那么,如果Loudacre大部分对customer表的分析是按state来完成的?比如:

这种情况下如果数据量很大,为了避免全表扫描的发生,我们可以去创建分区。如果不创建分区的话,它会默认所有查询不得不扫描目录的所有文件。创建分区按state将数据存储到不同的子目录,当按照“NY”的条件进行查询的时候,它只会扫描到子目录,下面我具体来看一下分区创建。
2、分区创建
(1)使用PARTITIONED BY来创建分区表
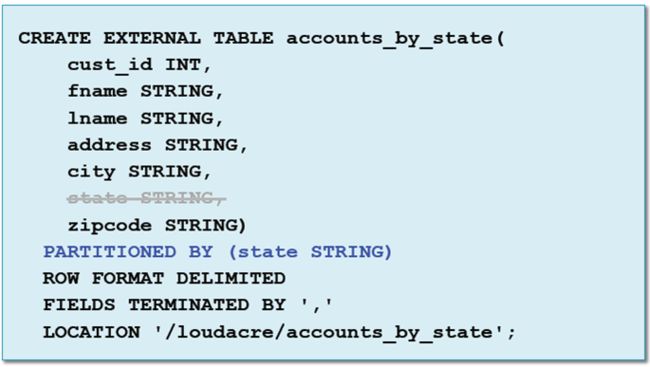
在这里注意state是被删除掉的,因为它作为分区字段,我们知道分区数据是不会出现在实际的文件当中的,所以state作为分区字段是不会出现在列当中的。换句话说,分区键就是一个虚列,它是不会存在列当中的。那么,如何去查看我们分区的列呢?它会出现在我们的结构当中吗?会的。
3、查看分区列
使用DESCRIBE显示分区列,它会出现在结构最后一列,它是一个虚列,并不是真实在数据中存在的列。

我们创建单个分区,但有时候会有嵌套分区,如何来处理呢?
4、创建嵌套分区:
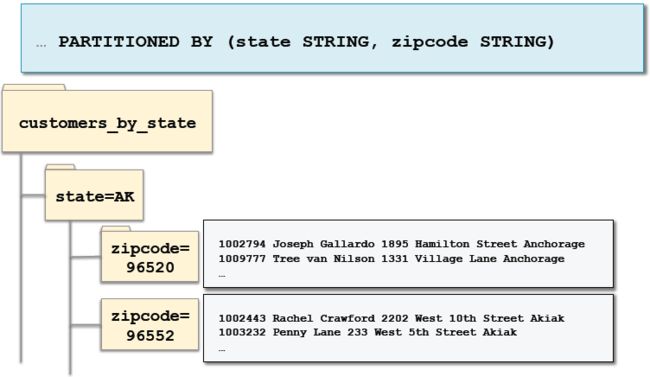
创建好了分区,我们怎么加载数据到分区呢?有两种方式动态分区和静态分区。动态分区是指Impala/Hive在加载的时候自动添加新的分区,数据基于列值存储到正确的分区(子目录)。而静态分区需要我们通过ADD PARTITION提前去定义分区的名称,当加载数据的时候,指定存储数据到哪个分区。那么动态分区和静态分区各有什么特征呢?后续为大家接着分享。
九、Impala SQL




其实,跟hive差不多,大家可以去参考我写的hive学习概念系列。
1、Impala SQL VS HiveQL
下面是Impala对基础数据类型和扩展数据类型的支持

• 此外,Impala不支持HiveQL以下特性:
– 可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
– XML、JSON函数
– 某些聚合函数:
• covar_pop, covar_samp, corr, percentile, percentile_approx,histogram_numeric, collect_set
• Impala仅支持:AVG,COUNT,MAX,MIN,SUM
– 多Distinct查询
– HDF、UDAF
– 以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、
DESCRIBE DATABASE、EXPORT TABLE、IMPORT TABLE、SHOW
TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS
2、Impala SQL
--创建数据库
create database db1;
use db1;
-- 删除数据库
use default;
drop database db1;
--创建表(内部表)
-- 默认方式创建表:
create table t_person1(
id int,
name string)
--指定存储方式:
create table t_person2(
id int,
name string
)
row format delimited
fields terminated by ‘\0’ (impala1.3.1版本以上支持‘\0’ )
stored as textfile;
--其他方式创建内部表
--使用现有表结构:
create table tab_3 like tab_1;
--指定文本表字段分隔符:
alter table tab_3 set serdeproperties(‘serialization.format’=‘,’,’field.delim’=‘,’);
--插入数据
-- 直接插入值方式:
insert into t_person values (1,hex(‘hello world’));
--从其他表插入数据:
insert (overwrite) into tab_3 select * form tab_2 ;
--批量导入文件方式方式:
load data local inpath ‘/xxx/xxx’ into table tab_1;
--创建表(外部表)
--默认方式创建表:
create external table tab_p1(
id int,
name string
)
location ‘/user/xxx.txt’
--指定存储方式:
create external table tab_p2 like parquet_tab
‘/user/xxx/xxx/1.dat’
partition (year int , month tinyint, day tinyint)
location ‘/user/xxx/xxx’
stored as parquet;
--视图
--创建视图:
create view v1 as select count(id) as total from tab_3 ;
--查询视图:
select * from v1;
--查看视图定义:
describe formatted v1• 注意:
– 1)不能向impala的视图进行插入操作
– 2)insert 表可以来自视图
• 数据文件处理
– 加载数据:
• 1、insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
• 2、load data方式:再进行批量插入时使用这种方式比较合适
• 3、来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
– 空值处理:
• impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段过滤,
• 也可以使用以下方式进行处理:
alter table name set tblproperties(“serialization.null.format”=“null”)
十、Impala数据处理(加载和存储)

Hive与Impala都是构建在Hadoop之上的数据查询工具,那么在实际的应用中,它们是如何加载和存储数据的呢?
Hive和Impala存储和加载表,和所有的关系型数据库一样,有自己的数据管理结构,从它的Server到Database再到表和视图。
在其他的数据库中,表都是以自己特定的文件格式来存储的,比如Oracle有自己的存储格式,而对Hive而言,一个表就是包含一个或多个文件的HDFS目录,这个文件是属于表下面的内容,默认存储路径:/user/hive/warehouse/
以上就是数据的存储,那么每一个表、每一个结构都有自己的列或者类型定义的信息,这些信息该如何去保存呢?它们存储在Metastore里,而所有的数据都存储在HDFS之上,所以我们想要获得表结构信息,就需要知道hive的元数据中每个表的含义和结构。在hive中,有简单的命令可以大概的查看表的结构信息:describe formatted tableName; hive metastore表结构如下:

因为Hive和Impala使用相同的数据,表在HDFS,元数据在Metastore,所以以上的存储及结构介绍同样适用于Impala。
数据加载及存储示例:
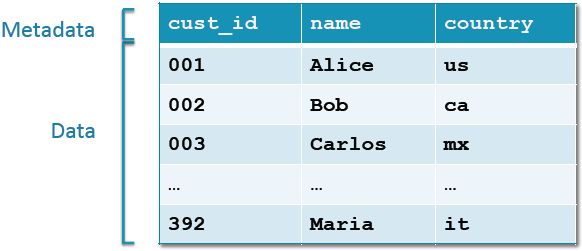
在这里呢我们必须要区分两个概念:数据和元数据。数据指的是你存储和处理的信息,比如账单记录、传感器读数和服务日志等。而元数据用来描述数据的形态,比如字段名和顺序等。
Hive与Impala都是构建在Hadoop之上的数据查询工具,那么在实际的应用中,它们是如何加载和存储数据的呢?
Hive和Impala存储和加载表,和所有的关系型数据库一样,有自己的数据管理结构,从它的Server到Database再到表和视图。
十一、Impala 和HBase整合

Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
• 步骤1:创建hbase 表,向表中添加数据
create 'test_info', 'info'
put 'test_info','1','info:name','zhangsan’
put 'test_info','2','info:name','lisi'• 步骤2:创建hive表
CREATE EXTERNAL TABLE test_info(key string,name string )
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES
("hbase.table.name" = "test_info");• 步骤3:刷新Impala表
invalidate metadata
十二、Impala通过JDBC方式访问(Kerberos和无Kerberos环境情况)
1)无Kerberos认证环境
示例代码:
package com.sunmnet.bigdata.web.config;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* package: com.netcloud.impala
* describe: 该事例主要讲述通过JDBC连接非Kerberos环境下的Impala
* creat_date: 2020/03/04
* creat_time: 上午10:00
*/
public class NoneKBSimple {
private static String JDBC_DRIVER = "com.cloudera.impala.jdbc41.Driver";
private static String CONNECTION_URL = "jdbc:impala://172.16.240.103:21050/";
static {
try {
Class.forName(JDBC_DRIVER);
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
System.out.println("通过JDBC连接非Kerberos环境下的Impala");
Connection connection = null;
ResultSet rs = null;
PreparedStatement ps = null;
try {
connection = DriverManager.getConnection(CONNECTION_URL);
ps = connection.prepareStatement("select * from test");
rs = ps.executeQuery();
while (rs.next()) {
System.out.println(rs.getInt(1) + "-------" + rs.getString(2));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.disconnect(connection, rs, ps);
}
}
}
2)Kerberos环境
在Kerberos环境下的Impala需要准备Kerberos的krb5.conf文件及keytab文件。
注意:下面测试环境是在Mac系统下,所以将kdc和Impala Daemon服务的IP地址修改为外网地址。JDBC URL后Kerberos信息是连接的Impala Daemon服务对应Prinical信息。


-
krb5.conf配置,直接将集群的krb5.conf文件拷贝至本地开发环境下 并修改 kdc和admin_server为ip地址
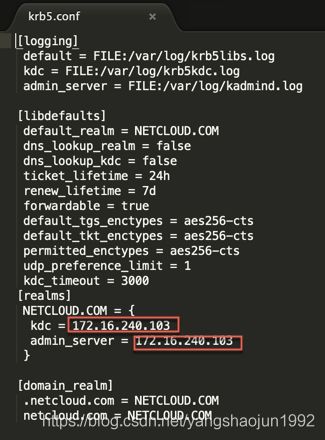
note: krb5.conf 默认路径 /etc/krb5.conf
- keytab文件生成
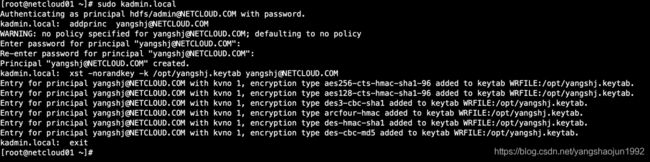
note:yangshj.keytab 路径 /opt/yangshj.keytab
示例代码:
package com.sunmnet.bigdata.web.config;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.IOException;
import java.security.PrivilegedAction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* package: com.netcloud.impala
* describe: 该事例主要讲述通过JDBC连接Kerberos环境下的Impala
* creat_user: yangshj
* creat_date: 2020/03/04
* creat_time: 上午11:00
*/
public class KBSimple {
private static String JDBC_DRIVER = "com.cloudera.impala.jdbc41.Driver";
//impala/[email protected]
/**
* jdbc:impala://172.16.240.103:21050/model 中的ip地址是Impala Daemon节点的地址 只要是Impala Daemon节点都可以
* 这里的ip地址和KrbHostFQDN=netcloud01 相对应 即ip的主机名 (不能配置为ip,一定是主机名并且还要在本地建立映射关系 /etc/hosts)
*/
private static String CONNECTION_URL = "jdbc:impala://172.16.240.103:21050/default;AuthMech=1;KrbRealm=NETCLOUD.COM;KrbHostFQDN=netcloud01;KrbServiceName=impala";
static {
try {
Class.forName(JDBC_DRIVER);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
System.out.println("通过JDBC连接Kerberos环境下的Impala");
//登录Kerberos账号
try {
System.setProperty("java.security.krb5.conf", "/Users/yangshaojun/Desktop/krb5.conf");
Configuration configuration = new Configuration();
configuration.set("hadoop.security.authentication" , "Kerberos");
UserGroupInformation. setConfiguration(configuration);
UserGroupInformation.loginUserFromKeytab("[email protected]", "/Users/yangshaojun/Desktop/yangshj.keytab");
System.out.println(UserGroupInformation.getCurrentUser() + "------" + UserGroupInformation.getLoginUser());
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
loginUser.doAs(new PrivilegedAction运行结果:
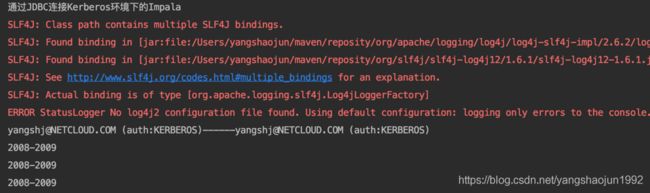
在运行上述示例的时候可能会遇到各种各样的问题
问题总结:
1)Caused by: KrbException: Identifier doesn't match expected value
使用keytab安全登录认证失败,原因是本地和服务器时间不一致
同步本机和hadoop服务器的时间
[root@esx4 ~]# ntpdate ntp.api.bz
21 Sep 14:39:09 ntpdate[24744]: the NTP socket is in use, exiting
[root@esx4 ~]# service ntpd stop
Shutting down ntpd: [ OK ]
[root@esx4 ~]# ntpdate ntp.api.bz
21 Sep 15:22:43 ntpdate[25723]: step time server 114.80.81.1 offset 2312.159684 sec
2)Caused by: sun.security.krb5.KrbException: Server not found in Kerberos database (7) - UNKNOWN_SERVER
KrbHostFQDN=netcloud01 一定要配置主机名称
并在Mac本地 /etc/hosts 或者 windows本地
c:\windows\system32\drivers\etc\hosts 配置服务器ip和主机名的映射关系
十三、Impala性能优化
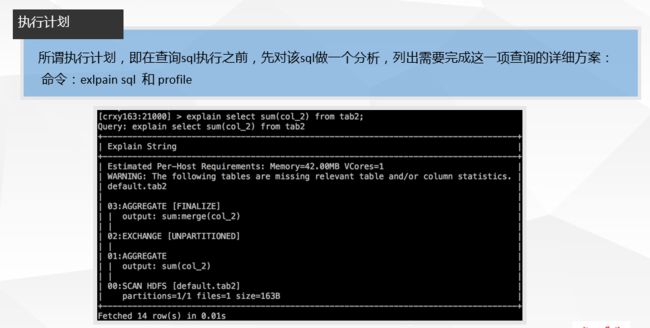

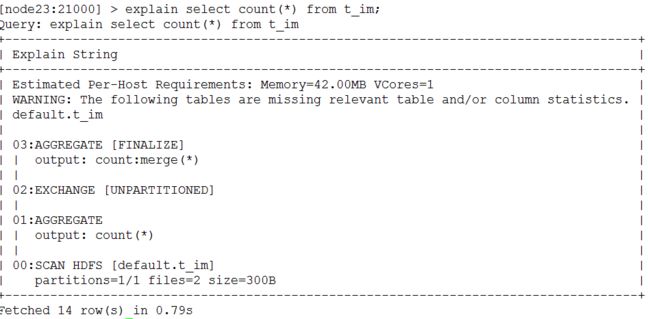
• 执行计划
– 查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的详细方案
– 命令:explain sql、profile
要点:
• 1、SQL优化,使用之前调用执行计划
• 2、选择合适的文件格式进行存储
• 3、避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表)
• 4、使用合适的分区技术,根据分区粒度测算
• 5、使用compute stats进行表信息搜集
• 6、网络io的优化:
– a.避免把整个数据发送到客户端
– b.尽可能的做条件过滤
– c.使用limit字句
– d.输出文件时,避免使用美化输出
• 7、使用profile输出底层信息计划,在做相应环境优化
• 8、如果是刷新表的新增元数据要使用refresh 表名 来刷新,不要使用impala-shell -r 或 invalidate metadata
• 9、如果执行SQL的结果内容较多的话可以使用 impala-shell -B 将一些不必要的样式输出去掉