机器学习之-KNN算法学习笔记
1 KNN核心思想
KNN的全称是K Nearest Neighbors,也就是k最近邻算法,所谓K最近邻,就是k个最近的邻居的意思。KNN的核心思想就是当预测一个新值x的时候,根据它距离最近的K个点中最多数是什么类别来判断x属于哪个类别。
2 KNN算法流程
2.1 计算测试对象到训练集中每个对象的距离 。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

2.2 按照距离的远近排序 。
2.3 选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居。
该如何确定K取多少值好呢?一般是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
通过交叉验证计算方差后会得到类似下面这样的图:
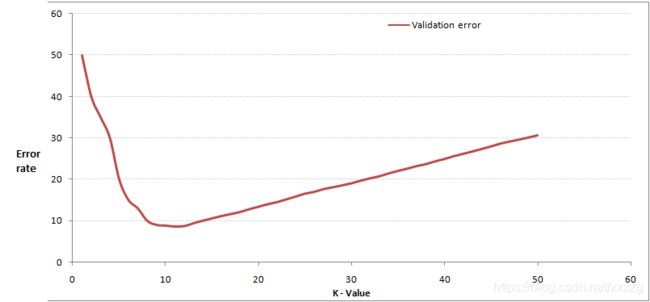
当增大k的时,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。
当K值更大的时候,错误率会更高。比如说你一共就50个样本,当你K增大到45的时候,KNN基本上就没意义了。
所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。
2.4 统计这k个邻居的类别频率。
2.5 k个邻居里频率最高的类别,即为测试对象的类别。
3 模型评估方法
3.1 划分数据集
在模型评估中,我们经常要对数据集进行训练集和测试集的划分,数据集划分通常要保证两个条件:
- 训练集和测试集的分布要与样本真实分布一致,即训练集和测试集都要保证是从样本真实分布中独立同分布采样而得。
- 训练集和测试集要互斥,即两个子集之间没有交集。
3.2 accuracy(分类准确度)
在划分出测试数据集后,就可以验证其模型准确率了。一般使用分类准确度(accuracy),验证其模型准确率了。accuracy_score:函数计算分类准确率,返回被正确分类的样本比例(default)或者是数量(normalize=False)
在多标签分类问题中,该函数返回子集的准确率,对于一个给定的多标签样本,如果预测得到的标签集合与该样本真正的标签集合严格吻合,则subset accuracy =1.0否则是0.0
因accuracy定义清洗、计算方法简单,因此经常被使用。但是它在某些情况下并不一定是评估模型的最佳工具。精度(查准率)和召回率(查全率)等指标对衡量机器学习的模型性能在某些场合下要比accuracy更好。
更多的时候,可以直接使用sklearn中封装好的方法,accuracy_score方法提供了准确度的计算。
4 数据归一化
4.1 为什么要数据归一化
- 归一化后加快了梯度下降求最优解的速度。
- 归一化有可能提高精度。
对于KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
4.2 常用的数据归一化有两种:
4.2.1 最值归一化(normalization)
把所有数据映射到0-1之间。最值归一化的使用范围是特征的分布具有明显边界的(分数0~100分、灰度0~255),受outlier的影响比较大。计算方法如下:
x_{scale} = \frac {x - x_{min}} {x_{max} - x_{min}}
4.2.2 均值方差归一化(standardization)
把所有数据归一到均值为0方差为1的分布中。适用于数据中没有明显的边界,有可能存在极端数据值的情况。计算方法如下:
x_{scale} = \frac {x - x_{mean}} {S}
5 kNN优缺点
5.1 KNN的主要优点
(1)简单,易于理解,易于实现,无需估计参数。
(2)训练时间为零。它没有显示的训练,不像其它有监督的算法会用训练集train一个模型(也就是拟合一个函数),然后验证集或测试集用该模型分类。KNN只是把样本保存起来,收到测试数据时再处理,所以KNN训练时间为零。
(3)KNN可以处理分类问题,同时天然可以处理多分类问题,适合对稀有事件进行分类。
(4)特别适合于多分类问题(multi-modal,对象具有多个类别标签), KNN比SVM的表现要好。
(5)KNN还可以处理回归问题,也就是预测。
(6)和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感。
5.2 KNN的主要缺点
(1)计算量太大,尤其是特征数非常多的时候。每一个待分类文本都要计算它到全体已知样本的距离,才能得到它的第K个最近邻点。
(2)可理解性差,无法给出像决策树那样的规则。
(3)是慵懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢。
(4)样本不平衡的时候,对稀有类别的预测准确率低。当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
(5)对训练数据依赖度特别大,对训练数据的容错性太差。如果训练数据集中,有一两个数据是错误的,刚刚好又在需要分类的数值的旁边,这样就会直接导致预测的数据的不准确。
6 kNN优化
6.1 样本不均衡优化
一个类的样本容量很大,而其他类样本数量很小时,很有可能导致当输入一个未知样本时,该样本的K个邻居中大数量类的样本占多数。但是这类样本并不接近目标样本,而数量小的这类样本很靠近目标样本。
这个时候,我们有理由认为该位置样本属于数量小的样本所属的一类,但是,KNN却不关心这个问题,它只关心哪类样本的数量最多,而不去把距离远近考虑在内,
因此,我们可以采用权值的方法来改进。和该样本距离小的邻居权值大,和该样本距离大的邻居权值则相对较小,由此,将距离远近的因素也考虑在内,避免因一个样本过大导致误判的情况。
6.2 计算量太大优化
K近邻法的重要步骤是对所有的实例点进行快速k近邻搜索。如果采用线性扫描(linear scan),要计算输入点与每一个点的距离,时间复杂度非常高。因此使用kd树来减少计算量。
kd树(K-dimensiontree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
类比“二分查找”:给出一组数据:[9 1 4 7 2 5 0 3 8],要查找8。如果挨个查找(线性扫描),那么将会把数据集都遍历一遍。而如果排一下序那数据集就变成了:[0 1 2 3 4 5 6 7 8 9],按前一种方式我们进行了很多没有必要的查找,现在如果我们以5为分界点,那么数据集就被划分为了左右两个“簇”[0 1 2 3 4]和[6 7 8 9]。因此,根本久没有必要进入第一个簇,可以直接进入第二个簇进行查找。把二分查找中的数据点换成k维数据点,这样的划分就变成了用超平面对k维空间的划分。空间划分就是对数据点进行分类,“挨得近”的数据点就在一个空间里面。