吴恩达机器学习ex8-协同过滤推荐系统
目录
1.导包
2.加载并检查数据
3.代价函数cost
4.梯度下降gradient
5.正则化代价函数cost和梯度下降函数gradient
6.训练前的准备工作
7.训练
1.导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from scipy.io import loadmat
from scipy.optimize import minimize2.加载并检查数据
data=loadmat('F:\机器学习课程2014源代码\python代码\ex8-anomaly detection and recommendation\data\ex8_movies.mat') #自定义路径
data
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Thu Dec 1 17:19:26 2011',
'__version__': '1.0',
'__globals__': [],
'Y': array([[5, 4, 0, ..., 5, 0, 0],
[3, 0, 0, ..., 0, 0, 5],
[4, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8),
'R': array([[1, 1, 0, ..., 1, 0, 0],
[1, 0, 0, ..., 0, 0, 1],
[1, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)}
定义Y和R:Y是“电影×用户”的值域在[1,5]数组,值表示某个用户对某个电影的评分;R也是“电影×用户”的数组,值表示某个用户是否对某个电影评分,1表示是,0表示否。两个矩阵的维度必须是一样的。
Y=data['Y']
R=data['R']
print(Y.shape,R.shape)(1682, 943) (1682, 943)
Y[1,np.where(R[1,:]==1)[0]]
array([3, 3, 3, 2, 3, 5, 1, 3, 3, 4, 4, 3, 2, 2, 3, 4, 4, 3, 3, 4, 2, 3,
4, 3, 3, 2, 3, 4, 5, 3, 2, 1, 4, 4, 3, 4, 3, 2, 3, 2, 4, 1, 2, 5,
4, 4, 4, 2, 3, 3, 4, 4, 3, 3, 1, 4, 4, 2, 3, 4, 3, 4, 4, 1, 5, 4,
3, 2, 1, 4, 3, 5, 4, 3, 2, 3, 5, 3, 2, 3, 4, 3, 4, 4, 4, 3, 4, 3,
1, 3, 2, 4, 3, 3, 3, 4, 3, 4, 3, 3, 4, 4, 3, 3, 3, 1, 3, 3, 5, 4,
4, 3, 4, 3, 3, 3, 4, 5, 4, 2, 2, 3, 4, 3, 4, 3, 3, 3, 3, 4, 5],
dtype=uint8)
可以通过将矩阵渲染成图像来尝试“可视化”数据(检查步骤,可做可不做)
fig,ax=plt.subplots(figsize=(12,12))
ax.imshow(Y)
ax.set_xlabel('Users')
ax.set_ylabel('Movies')
fig.tight_layout() #自动调整子图参数,使之填充整个图像区域
plt.show()
3.代价函数cost
先定义序列化矩阵和逆序列化矩阵的函数
def serialize(X,theta):
#序列化两个矩阵
# X (movie, feature), (1682, 10): movie features
# theta (user, feature), (943, 10): user preference
return np.concatenate((X.ravel(),theta.ravel()))
def deserialize(param,n_movie,n_user,n_features):
#逆序列化
return param[:n_movie * n_features].reshape(n_movie,n_features),param[n_movie * n_features:].reshape(n_user,n_features)基于协同过滤的代价函数
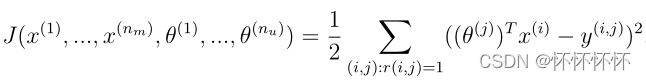
def cost(param,Y,R,n_features):
"""compute cost for every r(i, j)=1
Args:
param: serialized X, theta
Y (movie, user), (1682, 943): (movie, user) rating
R (movie, user), (1682, 943): (movie, user) has rating
"""
#theta(user,feature),(943,10):user preference
#X(movie,feature),(1682,10):movie features
n_movie,n_user=Y.shape
X,theta=deserialize(param,n_movie,n_user,n_features)
inner=np.multiply(X @ theta.T - Y, R)
return np.power(inner,2).sum()/2为了测试代价函数,提供了一组可以评估的预训练参数,出于时间考虑只选择一小段数据进行训练
param_data=loadmat('F:\机器学习课程2014源代码\python代码\ex8-anomaly detection and recommendation\data\ex8_movieParams.mat') #自定义路径
X=param_data['X']
theta=param_data['Theta']
X.shape,theta.shape((1682, 10), (943, 10))
users=4
movies=5
features=3
X_sub=X[:movies,:features] #X的前5行3列
theta_sub=theta[:users,:features] #theta的前4行3列
Y_sub=Y[:movies,:users] #Y的前5行3列
R_sub=R[:movies,:users] #Y的前5行3列
parma_sub=serialize(X_sub,theta_sub)
cost(parma_sub,Y_sub,R_sub,features)22.224603725685675
param=serialize(X,theta) #total real params
cost(serialize(X,theta),Y,R,10)27918.64012454421
4.梯度下降gradient
利用代价函数cost来计算梯度

def gradient(param,Y,R,n_features):
# theta (user, feature), (943, 10): user preference
# X (movie, feature), (1682, 10): movie features
n_movies,n_users=Y.shape
X,theta=deserialize(param,n_movies,n_users,n_features)
inner=np.multiply(X @ theta.T-Y,R) #(1682,943)
#X_grad (1682,10)
X_grad=inner @ theta
#theta_grad (943,10)
theta_grad=inner.T @ X
return serialize(X_grad,theta_grad)测试梯度的结果
n_movie,n_user=Y.shape
X_grad,theta_grad=deserialize(gradient(param,Y,R,10),n_movie,n_user,10)
X_grad,theta_grad
(array([[-6.26184144, 2.45936046, -6.87560329, ..., -4.81611896,
3.84341521, -1.88786696],
[-3.80931446, 1.80494255, -2.63877955, ..., -3.55580057,
2.1709485 , 2.65129032],
[-3.13090116, 2.54853961, 0.23884578, ..., -4.18778519,
3.10538294, 5.47323609],
...,
[-1.04774171, 0.99220776, -0.48920899, ..., -0.75342146,
0.32607323, -0.89053637],
[-0.7842118 , 0.76136861, -1.25614442, ..., -1.05047808,
1.63905435, -0.14891962],
[-0.38792295, 1.06425941, -0.34347065, ..., -2.04912884,
1.37598855, 0.19551671]]),
array([[-1.54728877, 9.0812347 , -0.6421836 , ..., -3.92035321,
5.66418748, 1.16465605],
[-2.58829914, 2.52342335, -1.52402705, ..., -5.46793491,
5.82479897, 1.8849854 ],
[ 2.14588899, 2.00889578, -4.32190712, ..., -6.83365682,
1.78952063, 0.82886788],
...,
[-4.59816821, 3.63958389, -2.52909095, ..., -3.50886008,
2.99859566, 0.64932177],
[-4.39652679, 0.55036362, -1.98451805, ..., -6.74723702,
3.8538775 , 3.94901737],
[-3.75193726, 1.44393885, -5.6925333 , ..., -6.56073746,
5.20459188, 2.65003952]]))
5.正则化代价函数cost和梯度下降函数gradient
正则化中有个额外的learning rate,此处称为"lambda"
def regularized_cost(param,Y,R,n_features,l=1):
reg_term=np.power(param,2).sum()*(l/2)
return cost(param,Y,R,n_features)+reg_term
def regularized_gradient(param,Y,R,n_features,l=1):
grad=gradient(param,Y,R,n_features)
reg_term=l*param
return grad+reg_term测试正则化后的函数
regularized_cost(parma_sub,Y_sub,R_sub,features,l=1.5)
regularized_cost(param, Y, R, 10, l=1) # total regularized cost31.3440562442742232520.682450229557
n_movie,n_user=Y.shape
X_grad, theta_grad = deserialize(regularized_gradient(param, Y, R, 10),n_movie, n_user, 10)6.训练前的准备工作
创建自己的电影评分,使该模型能用来生成个性化推荐
movie_list=[]
f=open('F:\机器学习课程2014源代码\python代码\ex8-anomaly detection and recommendation\data\movie_ids.txt',encoding='gbk')
for line in f:
tokens=line.strip().split(' ')
movie_list.append(' '.join(tokens[1:]))
movie_list=np.array(movie_list)
movie_list
array(['Toy Story (1995)', 'GoldenEye (1995)', 'Four Rooms (1995)', ...,
'Sliding Doors (1998)', 'You So Crazy (1994)',
'Scream of Stone (Schrei aus Stein) (1991)'], dtype='
使用练习中提供的评分
ratings=np.zeros((1682,1))
ratings[0] = 4
ratings[6] = 3
ratings[11] = 5
ratings[53] = 4
ratings[63] = 5
ratings[65] = 3
ratings[68] = 5
ratings[97] = 2
ratings[182] = 4
ratings[225] = 5
ratings[354] = 5
ratings.shape(1682, 1)
将自己的评级向量添加到现有数据集中
Y=data['Y']
Y=np.append(ratings,Y,axis=1)
R=data['R']
R=np.append(ratings!=0,R,axis=1)
Y.shape,R.shape((1682, 944), (1682, 944))
movies=Y.shape[0]
users=Y.shape[1]
features=10
learning_rate=10
X=np.random.random(size=(movies,features))
theta=np.random.random(size=(users,features))
params=serialize(X,theta)
X.shape,theta.shape,params.shape((1682, 10), (944, 10), (26260,))
Y_norm=Y-Y.mean()
Y_norm.mean()4.6862111343939375e-17
7.训练
fmin=minimize(fun=regularized_cost,x0=params, args=(Y_norm, R, features, learning_rate),method='TNC', jac=regularized_gradient)
#fun: 求最小值的目标函数 x0:变量的初始猜测值 args:常数值 method:求极值的方法 jac:梯度下降函数
fmin
fun: 69380.70267946375
jac: array([-2.79388237e-06, -2.91075603e-06, -3.07049781e-06, ...,
1.90335971e-06, -1.09002153e-06, -1.96462224e-07])
message: 'Converged (|f_n-f_(n-1)| ~= 0)'
nfev: 1105
nit: 43
status: 1
success: True
x: array([0.93549074, 0.50534218, 1.05315942, ..., 0.59228714, 1.06654338,
0.39303852])
训练好的参数是X和Theta。 可以使用这些来为添加的用户创建一些建议。
X_train,theta_trained=deserialize(fmin.x,movies,users,features)
X_train.shape,theta_trained.shape((1682, 10), (944, 10))
最后使用训练出的数据给出推荐电影
prediction=X_train @ theta_trained.T
my_preds=prediction[:,0]+Y.mean()
idx=np.argsort(my_preds)[::-1] #Descending order
idx.shape(1682,)
my_preds[:10]
array([3.51704802, 2.66293004, 2.36019366, 2.75300681, 2.58102171,
2.41766556, 3.16619018, 2.94876977, 2.94647058, 2.56269444])
给出最终的推荐结果
for m in movie_list[idx][:10]:
print(m)Titanic (1997) Star Wars (1977) Raiders of the Lost Ark (1981) Good Will Hunting (1997) Shawshank Redemption, The (1994) Braveheart (1995) Return of the Jedi (1983) Empire Strikes Back, The (1980) Terminator 2: Judgment Day (1991) As Good As It Gets (1997)

对推荐系统和图神经网络感兴趣的网友可以关注我的微信公众号“BoH工作室”,以后会陆续分享一些推荐系统和图神经网络的学习心得,欢迎大家关注并一起探讨。