JUST技术:基于时空孪生神经网络的轨迹识别
轨迹识别问题旨在验证传入的轨迹是否是由所要求的人员产生, 即给定一组单独的人员历史轨迹(例如行人,出租车司机)以及由特定人员生成的一组新轨迹,判定两组轨迹是否由同一个人员生成。这个问题在许多实际应用中都很重要,例如出租车驾驶人员身份认证、汽车保险公司风险分析以及危险驾驶识别等。轨迹识别的现有工作除了需要轨迹数据之外,还需要其他来源的数据,如传感器、摄像头等,但这些数据无法普遍获得且成本较高。此外,目前的工作只能局限于已有的人员身份识别,无法扩展至未经训练的人员。为了应对这些挑战,在这项工作中,我们首次尝试通过提出一种新颖而有效的框架时空孪生网络(ST-SiameseNet),仅从观察到的轨迹数据匹配人员身份。对于每个人员,我们从他们的轨迹中提取特征,来预测每个人轨迹的相似性。
一、问题背景
线上打车在现代社会越来越多地被应用,甚至说成为主流。根据纽约出租车协会数据显示(图1),截止2020年6月,纽约市每天有超过10万人次使用打车服务,线上打车服务占比超过70%。然而,随着行业从业人员的增加,从业人员就显得鱼龙混杂,经常会有安全事故被报道(图2)。尽管现在的平台会对司机进行实名认证,但仍会发生李代桃僵的事情。

图1 打车服务各类型占比

图2 线上打车服务安全事故报道案例
如图3所示,除了出租车安全认证之外,这项技术在汽车的保险行业也有着发展前景,比如投保人与肇事者是否是同一人,或者该驾驶员是否有危险驾驶行为,例如酒驾,等等。于是我们提出了“Human Mobility Signature Identification”,即通过轨迹信息的挖掘,进而分析驾驶人的驾驶行为,最终判断驾驶人是否是同一人。
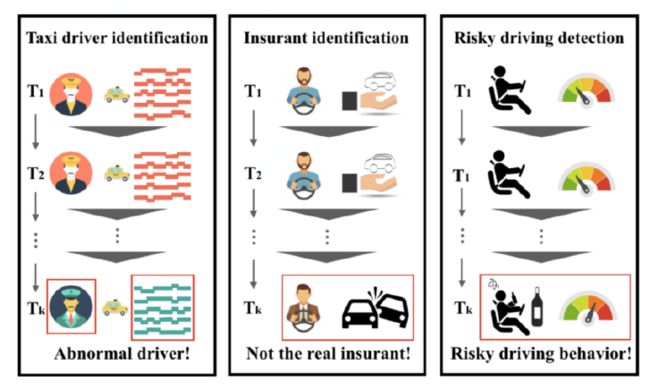
图3 驾驶人员身份识别应用场景
驾驶人员身份识别问题有很多相关工作,然而前期工作仍存在诸多问题,1)很多工作在识别司机的身份时,除GPS轨迹之外还需要额外的数据,例如车载的摄像机,方向盘和刹车的传感器等,这类数据成本高昂,很难普遍获取。2)一些工作利用传统的聚类或者多分类模型去识别司机身份,但这类方法识别数量有限,无法满足现实中识别百万级司机身份的需要。3)就我们所知,前期工作普遍存在泛化性不足的问题,模型面对训练集外的司机往往束手无策。
基于以上问题,我们提出了基于时空孪生神经网络的轨迹识别模型。该模型只依赖于GPS轨迹信息,可处理大规模驾驶员的识别问题,并且有较强的泛化能力,可识别未在训练集出现的驾驶员身份。
二、背景知识
首先,我们介绍一些相关的背景知识。我们提出了基于时空孪生神经网络的轨迹识别模型(ST-SiameseNet),那么什么是Siamese Network呢?Siamese是“孪生,连体”的意思,SiameseNetwork就如同字面的意思,是孪生神经网络,这一过程是通过共享权重实现的。将两个实体输入到同一个神经网络中,随后映射到新的空间,从而计算两个输入的相似度,从而判断二者是否属于同一个实体。基本模型框架如图4所示:

图4 Siamese Network
之所以将孪生神经网络引用至我们的模型,是因为其适合用于大规模实体的相似度判断。其学习的内容是实体间的相似度,因此未被训练过的数据仍然可以被拿来判断是否相似。
孪生神经网络已经解决了上述的后两个问题,即分类数量和泛化性。那么接下来就要解决第一个问题,数据成本。我们采用了易于获得的GPS行驶轨迹作为数据源。每个GPS点由经纬度和时间构成,一条轨迹则由一组GPS点构成。轨迹数据具有很强的时序性,因此我们引入LSTM来学习轨迹特征。为进一步挖掘轨迹数据的特征,我们从GPS数据中提取出司机的个人偏好,如最经常出现的位置、出发及结束时间、平均路程长度等等。与此同时,我们根据驾驶轨迹的状态,将轨迹分为了两类,例如出租车轨迹可分为载客轨迹与空车轨迹,私家车轨迹可分为上下班通勤以及日常生活轨迹等。
三、解决方案
在模型实现中,我们将出租车司机身份识别作为应用。GPS数据采自于2016年7月深圳出租车行驶记录,我们共筛选出2197位司机在10个工作日的GPS数据。
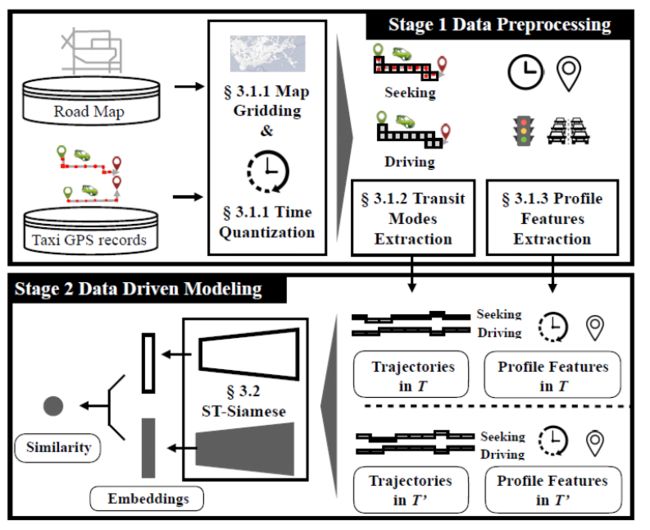
图5 模型流程图
图5展示了我们模型的基本流程。首先,我们将获得的GPS数据转化为一个个对应的格子,使得经纬度信息转化为更适合计算机处理的x,y坐标及对应的时间ID。而后,我们根据出租车是否载客将出租车轨迹分为载客轨迹与空车轨迹,并且从轨迹中提取了司机的个人偏好,如经常出现的位置、出车收车时间、平均寻客路程及时间、平均载客路程及时间、每日接单数量等。
为识别出租车司机身份,需要对一名司机两天的轨迹或者两名司机一天的轨迹进行比较,用以判断这些轨迹是否产生于同一个人。为此,我们选取了一个工作日内的5条空车轨迹和5条载客轨迹,这个数据的选择覆盖了所收集的司机的情况。图6显示了ST-SiameseNet模型具体框架:
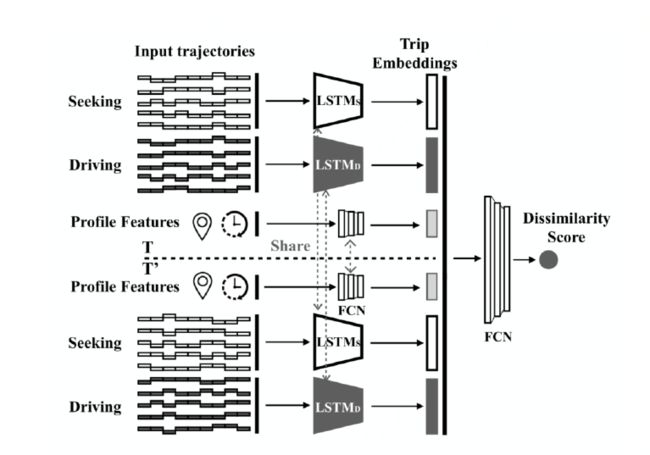
图6 ST-SiameseNet模型框架图
从整体来看,模型目的在于判断两天的轨迹是否属于同一个司机,所以在模型输入中等概率的选择同一个司机不同天,或者不同司机不同天的数据,即输入数据的正负样本概率相同。
区别于传统孪生神经网络只共享一个神经网络,我们将其扩展至共享三个神经网络,即LSTMD,LSTMs和FCN。前两个模块分别学习载客轨迹和空车轨迹特征,FCN模块学习司机行为偏好。由此,我们得到6个embedding对应模型的6个输入。最后,通过embeddings后经由全卷积网络获得非相似度。其中数值越接近1,不是同一人的可能性越大。
四、实验结果
我们在2197名司机10天的轨迹数据上验证了方法的有效性。QQ靓号转让表1在对比不同模型中,我们采用了500位司机的前5天作为训练数据,另外的197位司机的后5天作为测试数据,保证了数据的充足性和独立性。
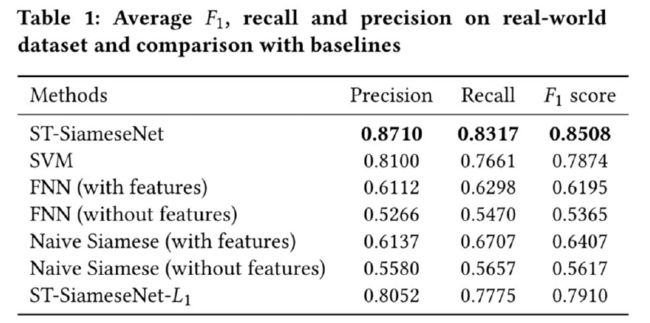
表1 不同模型实验效果验证表
对于SVM,由于无法输入轨迹信息,所以输入数据为司机个人偏好特征信息,经过绝对值相减后输入SVM,获得非相似度。对于FNN,区别在于是否包含个人偏好特征,两个输入GPS数据连接成一个大的数据输入FCN中,获得非相似度。这个对比旨在获取神经网络在提取特征方面的能力。对于Naïve Siamese,与我们提出的模型相比,只有一个FCN网络,而输入的GPS数据首尾相连组成一个长数据,通过FCN和embeddings后得到非相似度。
最后对比结果可以看到,我们提出的模型结构在各个指标上都有着优异的表现。而在同类模型的对比中,加入个人偏好的模型要比不加入偏好的模型性能表现要好,这也证明了除去轨迹特征外,司机的个人偏好对于相似度识别也有贡献。
此外,我们对模型泛化能力,也进行了轨迹天数与司机数量两方面的测试。图7是固定了500位司机,以工作日为变量的结果;图8是固定为5天的工作量,以司机数量为变量的结果。以图7为例,所有的数据集总共包含697位司机10个工作日的轨迹数据,其中500名司机作为训练集,197名司机为验证和测试集,假设训练集采用了头3天的数据做训练,那么验证集和测试集则使用剩余的后7天作为测试,以此类推。图8逻辑同理。


图7 500名司机工作日实验效果 图8 5天工作量司机数量实验效果
从上面的两幅图可以看出,随着训练天数和训练人数的增加,模型的泛化能力得到了提升,有效的避免了过拟合的问题。而且模型性能的拐点分别出现在5天的训练天数和500位司机的训练数量,之后的测试集结果增长不明显。说明500位司机和5个工作日的训练数量就能够获得较好性能的模型。
我们还进一步对比了轨迹运行模式与司机偏好特征对模型的影响。首先对比了运行模式对模型的影响,图9展示了不同运行模式下的测试准确率,粉色线包含了空车模式和载客模式,灰线仅包含了空车模式,黄线仅包含了载客模式。可以看出即使只包含有单一的运行模式,在一定程度上能够判断轨迹是否属于同一位司机。空车模式轨迹的准确率普遍高于载客模式轨迹的准确率,这与人的直觉是一致的,因为载客时司机无法选择目的地,而空车时不同司机会有不同的策略寻找乘客,因此可以更好的体现司机的特征。当两种运行模型同时作用于模型时,我们得到了最好的结果(粉色线)。与图7图8趋势一致,随着司机数量及训练天数的增加,模型的测试准确率有了提高。

图9 运行模式对比
图10对比了司机个人偏好在模型训练中的作用。红色线展示了轨迹数据及个人偏好作为输入时的测试集准确率,棕色线展示了只有轨迹数据的测试准确率,紫色线代表只有个人偏好特征作为输入的测试准确率。同图7图8趋势一致,随着司机数量及训练天数的增加,模型的测试准确率有了提高。在对比三种输入中,我们发现如果只使用司机的个人偏好特征作为输入,模型得到了较差的结果,这说明高度抽象的特征虽然在一定程度上可以识别司机,但也损失了很多其他有效信息。而单纯使用轨迹数据作为输入(棕色线),其准确率仍低于我们的模型(红色线),很可能是因为模型在处理轨迹数据时,很难获取全局的统计信息,比如平均寻客路程与时间,平均载客路程及时间等。当轨迹信息与个人偏好特征结合起来时,我们的模型得到了最优结果。

图10 个人偏好特征对比