稀疏奖励及模仿学习(DataWhale组队学习笔记)
稀疏奖励
在用强化学习解决现实问题时,我们对学习目标设置相应的奖励,但在庞大的状态空间中,智能体想要通过随机试错来获取奖励的概率是极低的,不获得奖励就没办法学习,我们将这种情况称作稀疏奖励。
针对稀疏奖励问题,我们介绍以下几种解决方案。
1、Reward Shaping
Reward Shaping的意思是说,我们人为的设计一些引导性质的奖励,来为智能体设计一些学习路线,这样来丰富获得奖励的途径,从而避免奖励过于稀疏的问题。其中人为设计部分是调出来的,有些奖励设计并不能让智能体学习到最终目标,有可能是因为缺乏中间奖励,或者是奖励的设计与最终目标的相关性较低。
Curiosity是设计奖励的一种思路,我们在设计奖励的时候,希望鼓励智能体多进行探索。
为此,设计一个ICM(intrinsic curiosity module),在这个算法中,我们先训练一个预测网络net1,给网络输入状态  、动作
、动作  以及状态
以及状态 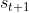 ,我们训练网络对
,我们训练网络对 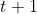 时刻的状态进行预测
时刻的状态进行预测 ![]() 。
。
然后对实际学习过程中的状态和动作,输出一个奖励 ![]() ,如果
,如果 ![]() 与 差距越大,奖励越高。这样会使得智能体倾向于进行那些使未来更不确定的动作。
与 差距越大,奖励越高。这样会使得智能体倾向于进行那些使未来更不确定的动作。
ICM算法中会遇到一个问题,就是在训练过程中,可能会由于环境本身不可预测,导致智能体训练出的动作不是我们需要的。例如:树叶飘动不可预测,智能体什么都不做就能得到高额的 ![]() 。
。
为此,我们训练另一个网络net2,同样给网络输入状态 、动作 以及状态 ,我们训练网络对智能体动作的预测  ,再将结果带回到实际训练中,对预测准确的给予高额奖励,以此来过滤掉那些无关的动作。
,再将结果带回到实际训练中,对预测准确的给予高额奖励,以此来过滤掉那些无关的动作。
2、Curriculum learning
Curriculum learning的意思是说,给智能体设计一些学习路线,让它从简单的学习目标逐渐的学习更难的目标,最终达到我们的需求。
Reverse Curriculum Generation的方法是说,我们从最终目标 ![]() (gold state)倒推学习路线,由
(gold state)倒推学习路线,由 ![]() 设置一些临近状态
设置一些临近状态 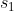 、
、 等,然后让机器从这些状态开始与环境互动,看是否学习到
等,然后让机器从这些状态开始与环境互动,看是否学习到 ![]() 。
。
最后把学习过程中奖励极端的情况排除掉即可。reward很大,说明机器很容易就学会了从这一状态到达 ![]() ,因此这个临近状态就太简单了,没有太大意义;reward很小,说明机器很难从这一状态学会东西到达
,因此这个临近状态就太简单了,没有太大意义;reward很小,说明机器很难从这一状态学会东西到达 ![]() ,那么这个路线就太难了。
,那么这个路线就太难了。
这样我们最终就可以得到一条难度适中的学习路线。
3、分层强化学习(hierarchical reinforcement learning,HRL)
分层强化学习的原理很简单,就是说我们在学习一个大的目标时,可以将其分解为很多小目标,并且我们可以将这个规划目标的任务也同样交给一个智能体来做。
也就是说,有一些智能体  用来提出具有层次规划的愿景,另一些智能体
用来提出具有层次规划的愿景,另一些智能体  来学习这些大目标小目标。如果智能体 愿景提的好,智能体 能够学习成功,那么 和 就都能够获得奖励,如果 没学成功,那么这个愿景提的就不好,大家就得不到奖励,从而来训练 如何提出愿景。
来学习这些大目标小目标。如果智能体 愿景提的好,智能体 能够学习成功,那么 和 就都能够获得奖励,如果 没学成功,那么这个愿景提的就不好,大家就得不到奖励,从而来训练 如何提出愿景。
模仿学习
在多数的强化学习问题中,我们都没办法真的从环境中获得奖励,例如聊天机器人的学习问题。
这时候,我们考虑能否收集到一些专家的示范,比如人类的动作数据。通过对专家智能体进行学习,从而避免奖励设置困难的问题。
1、行为克隆
行为克隆是说,智能体完全去学习专家的策略 ![]() ,根据对专家的决策数据进行收集,将策略
,根据对专家的决策数据进行收集,将策略 ![]() 下的状态动作对
下的状态动作对 ![]() 当做监督学习问题的材料进行训练,让智能体直接去学习在什么状态下做出什么动作。
当做监督学习问题的材料进行训练,让智能体直接去学习在什么状态下做出什么动作。
行为克隆方法有一些难以解决的问题:
首先对于专家策略 ![]() 下能够观测到的状态动作对是很有限的,就好比自动驾驶问题中,你难以对撞车后的状态进行学习。
下能够观测到的状态动作对是很有限的,就好比自动驾驶问题中,你难以对撞车后的状态进行学习。
这时候我们引入一个数据集聚合的方法,这个方法是说,收集数据时,给出答案动作 的仍然是专家,但与环境交互的是另一个演员智能体。这样,在收集到撞车后所给出的动作结果后,智能体就可以学习到这部分内容。
另一个问题是,机器会完全模仿专家的行为,一些与解决问题无关的个人习惯也有可能被学到。由于网络训练的精度不会达到100%,所以学习结果可能反而没有学到应该学习的策略。因此让机器知道哪些应该学习就变得很重要。
另一个很可能遇到的问题是,学到的策略和专家策略总会有误差,在实际情况中,由于强化学习问题通常都是连续的状态空间,很小的误差也能够造成较大的差异。
因此我们介绍另一种模仿学习的方法。
2、逆强化学习
逆强化学习的核心原理与GAN类似。
首先我们有一个专家策略 ![]() 和演员策略
和演员策略 ![]() ,通过与环境交互得到状态序列。根据这n条状态的轨迹去学习一个奖励函数,使得专家的奖励大于演员的奖励。
,通过与环境交互得到状态序列。根据这n条状态的轨迹去学习一个奖励函数,使得专家的奖励大于演员的奖励。
根据这个学习出来的奖励去重新训练一个演员  ,再重复上述过程。
,再重复上述过程。
如果我们训练的演员策略  最终收敛,那么就可以学习到接近专家的策略。但实际上这个训练不一定会收敛。
最终收敛,那么就可以学习到接近专家的策略。但实际上这个训练不一定会收敛。
上述学习奖励函数的过程,实际上就类似GAN中打分的过程,通过GAN的方法来给专家打高分,给演员打低分。
注:本文参考《蘑菇书EasyRL》第十章至第十一章内容
来源:蘑菇书EasyRL (datawhalechina.github.io)