文本分类模型(一)——RCNN
文本分类模型(一) RCNN
文章目录
- 文本分类模型(一) RCNN
-
- 一、概述
- 二、背景
- 三、RCNN原理
-
- 3.1 模型结构
- 3.2 前向传播
-
- 1)Word Representation Learning
- 2)Text Representation Learning
- 3.3 反向传播
- 四、RCNN处理文本分类
-
- 4.1 在RNN模型的基础上修改实现RCNN的文本二分类
- 4.2 RCNN文本多分类并利用TensorBoard可视化
- 4.3 模型过拟合的处理
- 五、总结
一、概述
TextRCNN是2015年中科院发表的一篇文本分类的论文Recurrent Convolutional Neural Networks for Text Classification。TextRCNN通过RNN取代TextCNN的特征提取,先使用双向RNN获取输入文本的上语义和语法信息,接着使用最大池化自动地筛选出最重要的特征,然后接一个全连接层用于分类。
二、背景
在NN中,RNN和CNN作为文本分类问题的主要模型架构,都存在各自的优点及局限性。RNN擅长处理序列结构,能够考虑到句子的上下文信息,但RNN属于“biased model”,一个句子中越往后的词重要性越高,这有可能影响最后的分类结果,因为对句子分类影响最大的词可能处在句子任何位置。CNN属于无偏模型,能够通过最大池化获得最重要的特征,但是CNN的滑动窗口大小不容易确定,选的过小容易造成重要信息丢失,选的过大会造成巨大参数空间。
为了解决二者的局限性,提出了RCNN的架构,用双向循环结构获取上下文信息,相较于CNN在学习文本表达时可以大范围的保留词序。其次使用最大池化层获取文本的重要部分,自动判断哪个特征在文本分类过程中起更重要的作用。
三、RCNN原理
3.1 模型结构
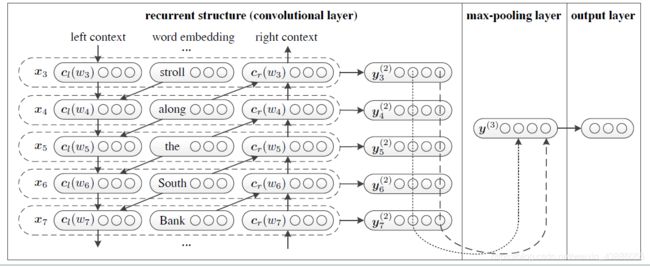
模型的第一部分是一个Bi-RNN结构,第二部分是max-pooling层,第三部分是全连接层。第一部分主要用来学习word representation,第二部分和第三部分用来学习text representation。
3.2 前向传播
1)Word Representation Learning
1.学习单词的左上文与右下文的信息
c l ( w i ) = f ( W ( l ) c l ( w i − 1 ) + W ( s l ) e ( w i − 1 ) ) c_l(w_i) = f(W^{(l)}c_l (w_{i-1}) + W^{(sl)} e(w_i-1)) cl(wi)=f(W(l)cl(wi−1)+W(sl)e(wi−1))
c r ( w i ) = f ( W ( r ) c r ( w i + 1 ) + W ( s r ) e ( w i + 1 ) ) c_r(w_i) = f(W^{(r)}c_r (w_{i+1}) + W^{(sr)} e(w_i+1)) cr(wi)=f(W(r)cr(wi+1)+W(sr)e(wi+1))
其中,
{ c l ( w i ) 表 示 单 词 W i 的 左 上 文 c r ( w i ) 表 示 单 词 W i 的 左 上 文 e ( w i ) 表 示 单 词 w i 的 嵌 入 向 量 W ( l ) 为 权 重 矩 阵 , 将 上 一 个 单 词 的 左 上 文 c l ( w i − 1 ) 传 递 到 下 一 个 单 词 的 左 上 文 c l ( w i ) 中 W ( s l ) 是 一 个 矩 阵 , 结 合 当 前 词 e ( w i − 1 ) 的 语 义 到 下 一 个 词 的 左 上 文 中 , s 表 示 的 是 s e m a n t i c 。 \begin{cases} c_l(w_i)表示单词W_i的左上文 \\ c_r(w_i)表示单词W_i的左上文 \\ e(w_i)表示单词w_i的嵌入向量 \\ W^{(l)}为权重矩阵,将上一个单词的左上文c_l(w_{i-1})传递到下一个单词的左上文c_l(w_i)中 \\ W^{(sl)}是一个矩阵,结合当前词e(w_{i−1})的语义到下一个词的左上文中,s表示的是semantic。 \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧cl(wi)表示单词Wi的左上文cr(wi)表示单词Wi的左上文e(wi)表示单词wi的嵌入向量W(l)为权重矩阵,将上一个单词的左上文cl(wi−1)传递到下一个单词的左上文cl(wi)中W(sl)是一个矩阵,结合当前词e(wi−1)的语义到下一个词的左上文中,s表示的是semantic。
2.计算单词 w i w_i wi的隐藏语义向量 (潜在语义表示)
将单词 w i w_i wi的左上文、嵌入向量和右下文表示连接起来表示单词 w i w_i wi:
x i = [ c l ( w i ) ; e ( w i ) ; c r ( w i ) ] x_i = [c_l(w_i); e(w_i); c_r(w_i)] xi=[cl(wi);e(wi);cr(wi)]
使用线性变换激活函数计算单词 w i w_i wi的隐藏语义向量:
y i ( 2 ) = tanh ( W ( 2 ) x i + b ( 2 ) ) y_i^{(2)} = \tanh (W^{(2)}x_i + b^{(2)}) yi(2)=tanh(W(2)xi+b(2))
2)Text Representation Learning
3.max-pooling层
y ( 3 ) = max i = 1 n y i ( 2 ) y^{(3)} = \max_{i=1}^n \ y_i^{(2)} y(3)=i=1maxn yi(2)
取每一个向量 y ( 2 ) y^{(2)} y(2)中的最大值组成向量 y ( 3 ) y^{(3)} y(3),最大池化可以帮助找到句子中最重要的潜在语义信息。
4.全连接层
y ( 4 ) = W ( 4 ) y ( 3 ) + b ( 4 ) y^{(4)}=W^{(4)}y^{(3)}+b^{(4)} y(4)=W(4)y(3)+b(4)
p j = exp ( y j ( 4 ) ) ∑ k = 1 n exp ( y k ( 4 ) ) p_j = \frac{\exp(y_j^{(4)})}{\sum_{k=1}^n \exp(y_k^{(4)})} pj=∑k=1nexp(yk(4))exp(yj(4))
将 y ( 3 ) y^{(3)} y(3)输入到全连接层,然后通过softmax进行分类。
3.3 反向传播
定义训练网络参数 θ \theta θ:
θ = { E , b ( 2 ) , ( 4 ) , c l ( w 1 ) , c r ( w n ) , W ( 2 ) , W ( 4 ) , W ( l ) , W ( r ) , W ( s l ) , W ( s r ) } \theta=\{E,b^{(2)},^{(4)},c_l(w_1),c_r(w_n),W^{(2)},W^{(4)},W^{(l)},W^{(r)},W^{(sl)},W^{(sr)}\} θ={E,b(2),(4),cl(w1),cr(wn),W(2),W(4),W(l),W(r),W(sl),W(sr)}
使用最大似然函数来评估模型的效果:
θ ↦ ∑ D ∈ D log p ( c l a s s D ∣ D , θ ) \theta \mapsto \sum_{D \in \mathbb{D}} \log p(class_D|D,\theta) θ↦D∈D∑logp(classD∣D,θ)
其中 D \mathbb{D} D为训练集, c l a s s D class_D classD为文本的正确分类。
采用随机梯度下降来优化训练目标。在每一步中,随机选择样本 ( D , c l a s s D ) (D, class_D) (D,classD)并做渐变步骤。
θ ← θ + α ∂ log p ( c l a s s D ∣ D , θ ) ∂ θ \theta \leftarrow \theta + \alpha \frac{\partial \log p(class_D|D,\theta)}{\partial \theta} θ←θ+α∂θ∂logp(classD∣D,θ)
文本的预训练采用Skip-Gram模型。
四、RCNN处理文本分类
RCNN作为CNN与RNN的结合体,在文本分类上相比于之前有一定的优势。
4.1 在RNN模型的基础上修改实现RCNN的文本二分类
首先从文件中读取相应训练集和测试集的语料,利用jieba对文本进行分词,然后利用nltk去停用词。这里nltk_data中并没有中文的停用词,我从网上找了一个中文的停用词文件放在对应的stopwords目录下,并命名为chinese。
def tokenizer(text):
sentence = jieba.lcut(text, cut_all=False)
stopwords = stopwords.words('chinese')
sentence = [_ for _ in sentence if _ not in stopwords]
return sentence
利用torchtext包处理预处理好的语料,将所提供的语料集转化为相应的词向量模型。由于每一个词均为一个向量,作为模型的输入。
train_set, validation_set = data.TabularDataset.splits(
path='corpus_data/',
skip_header=True,
train='corpus_train.csv',
validation='corpus_validation.csv',
format='csv',
fields=[('label', label), ('text', text)],
)
text.build_vocab(train_set, validation_set)
将处理好的词向量输入到RCNN模型中进行处理。
self.lstm = nn.lstm(embedding_dim, self.hidden_size, batch_first=True)
self.linear = nn.Linear(embedding_dim, label_num)
self.linear_cat = nn.Linear(self.hidden_size + embedding_dim, embedding_dim)
def forward(self, x):
# 输入x的维度为(batch_size, max_len),
x = self.embedding(x) # 经过embedding,x的维度为(batch_size, time_step, embedding_dim)
# 隐层初始化
# h0,c0维度为(direction_num, batch_size, hidden_size)
h0 = torch.rand(1, x.size(0), self.hidden_size)
c0 = torch.zeros(1, x.size(0), self.hidden_size)
# out维度为(batch_size, seq_length, hidden_size)
out, (hn, cn) = self.lstm(x, (h0,c0))
# 拼接左右上下文信息
out = torch.cat((out, x), dim=2)
out = torch.tanh(self.linear_cat(out))
out = torch.transpose(out, 1, 2)
# 经过最大池化层
out = F.max_pool1d(input=out, kernel_size=x.size(1))
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
利用训练集对模型进行训练,同时评估训练效果,并利用测试集对模型的准确性进行评估。为了防止偶然性产生的不确定,每一轮迭代会产生100个模型,分别评估其效率,进行调优后再用测试集测试其效率。
在训练初期,测试集的准确率在88%左右。

多轮迭代之后,模型的准确率大概稳定在90%以上。

4.2 RCNN文本多分类并利用TensorBoard可视化
首先导入相关环境和库
import jieba
import torch.nn as nn
import numpy as np
from torchtext import data
from torchtext.vocab import Vectors, GloVe
import torch.nn.functional as F
from torchtext.data import LabelField, Field, TabularDataset
然后从.csv文件中导入相关的训练集、评估集和测试集数据,并进行一定的处理,转化为DataSet。词向量采用globe.6B dim=300的已训练好的词向量。
ID = Field(sequential=False, use_vocab=False)
LABEL = LabelField(sequential=False, use_vocab=True, is_target=True)
INFO = Field(sequential=True, tokenize=jieba.lcut, include_lengths=True)
fields = [
('id', ID),
(None, None),
('label', LABEL),
('info', INFO),
]
# 加载数据
train_data = TabularDataset(
os.path.join('data', 'train.csv'),
format='csv',
fields=fields,
csv_reader_params={'delimiter': '\t'}
)
··· # 评估集和测试集数据加载省略
# 创建字典
INFO.build_vocab(train_data, vectors='glove.6B.300d')
LABEL.build_vocab(train_data)
return LABEL, INFO, train_data, valid_data, test_data
构建模型:采用双向LSTM的模型,继承nn.LSTM,并重写其中的forward函数。
class TextRCNN(nn.Module):
def __init__(self, vocab_size, label_size, embedding_dim, hidden_size, layer_num, bidirectional=False, dropout=float(0.1)):
super().__init__()
# embedding层
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# rnn层
self.rnn = nn.LSTM(
embedding_dim,
hidden_size,
num_layers=layer_num,
bidirectional=bidirectional,
dropout=dropout
)
# 全连接层
num_direction = 2 if bidirectional else 1 # 双向
self.fc_cat = nn.Linear(hidden_size * num_direction + embedding_dim, embedding_dim * num_direction)
self.fc = nn.Linear(hidden_size * num_direction, label_size)
# dropout层
self.dropout = nn.Dropout(p=dropout)
def forward(self, text, text_len):
embedded = self.embedding(text)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_len)
# 通过RNN层
packed_output, (h_n,c_n) = self.lstm(packed_embedded)
packed_output, output_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
packed_output = self.dropout(packed_output)
# 拼接左右上下文信息
out = torch.cat((packed_output, embedded), dim=2)
out = self.fc_cat(out)
out = torch.tanh(out)
out = torch.transpose(out, 0, 2)
# 经过最大池化层
out = F.max_pool1d(input=out, kernel_size=embedded.size(0))
out = out.view(out.size(0), -1)
out = self.dropout(out)
# 转置并输出
out = torch.transpose(out,0,1)
loggits = self.fc(out)
return loggits
数据分批:将dataset中的数据进行分批,依次传入模型中运行。
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=args.batch_size,
sort_within_batch=True,
sort_key = lambda x: len(x.info),
device=torch.device('cpu')
)
定义优化器:
# 使用Adam优化器
optimizer = Adam(model.parameters(), args.learning_rate)
使用TensorBoard可视化:
writer = SummaryWriter()
writer.add_scalar('训练集/损失率', loss.item(), step)
writer.add_scalar('训练集/学习率', scheduler.get_last_lr()[0], step)
···
writer.close()
tensorboard --logdir ./runs
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.3.0 at http://localhost:6006/ (Press CTRL+C to quit)
在经过十几轮的迭代之后,模型的准确率能够达到83%左右。

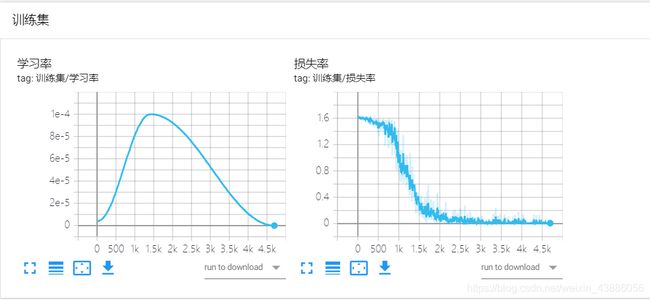
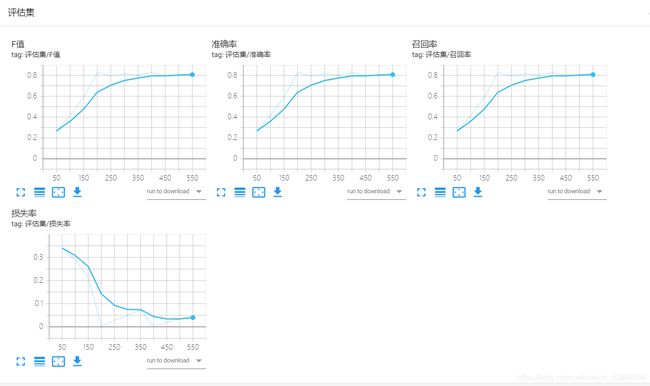
利用TensorBoard查看模型的相关曲线,包括针对训练集的学习率变化、损失率下降趋势;以及针对评估集的F值、准确率、召回率和损失率等的变化曲线。
4.3 模型过拟合的处理
查看在模型最后几次的准确率,发现在训练集上能够达到98%甚至99%的准确率,而在评估集上只能有80%出头。再查看评估集的损失率曲线,发现呈现出“先降低,后又有略微增加”的趋势,因此判断模型出现了过拟合的问题。
过拟合出现,主要是有如下几个可能的原因:
- 1.训练集的数量级和模型的复杂度不匹配。训练集的数量级要小于模型的复杂度;
- 2.训练集和测试集特征分布不一致;
- 3.样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
- 4.权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
而解决模型过拟合的问题,常见的解决方式有如下几种:
- 1.简化模型结构:调小模型复杂度,使其适合自己训练集的数量级(缩小宽度和减小深度)
- 2.增加数据:训练集越多,过拟合的概率越小。
- 3.正则化:正则化是指通过引入额外新信息来解决机器学习中过拟合问题的一种方法。这种额外信息通常的形式是模型复杂性带来的惩罚度。正则化可以保持模型简单,另外,规则项的使用还可以约束我们的模型的特性。
- 4.dropout:dropout方法在训练的时候让神经元以一定的概率不工作。
- 5.early stopping:Early stopping是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
- 6.ensemble:集成学习算法也可以有效的减轻过拟合。Bagging通过平均多个模型的结果,来降低模型的方差。Boosting不仅能够减小偏差,还能减小方差。
- 7.重新清洗数据:导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
由于在梯度下降的算法中,tanh函数容易产生梯度消失的问题,因此首先尝试用ReLU函数代替tanh作为激活函数:
# out = torch.tanh(out)
out = F.relu(out)

实验结果发现依然会存在过拟合问题。
接下来尝试调整学习率(将lr从0.001上调至0.01,或者下调至0.0001),或者修改dropout的丢弃概率,均没有达到很好的效果。
然后查看训练集的数据分布,发现每个label的出现均是集中出现,于是利用shuffle函数,打乱训练集的数据,过拟合现象有所缓解。
np.random.shuffle(train_data.examples)
最后利用shuffle方法,并添加early stop机制,基本上解决了过拟合的问题,最终的测试集准确率在83%~85%之间。
if best_acc > dev_acc and steps - last_step >= self.early_stopping:
print('\nearly stop by {} steps, acc: {:.4f}%'.format(args.early_stopping, best_acc))
raise KeyboardInterrupt
五、总结
Recurrent Convolutional Neural Network(RCNN)引用了双向递归结构,可以看作是CNN与RNN的结合,其相比于传统的CNN或者RNN模型,具有如下的优点:
- 比传统基于窗口的神经网络相比,引入的噪声少
- 学习单词表示时最大程度地捕获上下文信息
- 文本表示时可保留最大范围的单词排序
- 最大池化层判断哪些特征在文本分类中起关键作用
- 结合了RNN和CNN的优势,采用递归结构和max-pooling