0907实战KAGGLE房价预测数据
数据集:
本文主要对KAGGLE房价预测数据进行预测,并提供模型的设计以及超参数的选择。
该数据集共有1460个数据样本,80个样本特征
数据集介绍可参照:
House Prices - Advanced Regression Techniques | Kaggle
实现代码:
0 导入库
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
from scipy import stats
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l1.探索性数据分析
1.1 数据载入
##训练集
train_data=pd.read_csv(open('G:/Program/driver-fatigue-detection-system-master/kaggle_house_price/train.csv'))
##测试集
test_data=pd.read_csv(open('G:/Program/driver-fatigue-detection-system-master/kaggle_house_price//test.csv'))
#数据可视化
#查看自变量与因变量的相关性
fig = plt.figure(figsize=(14,8))
abs(train_data.corr()['SalePrice']).sort_values(ascending=False).plot.bar()
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)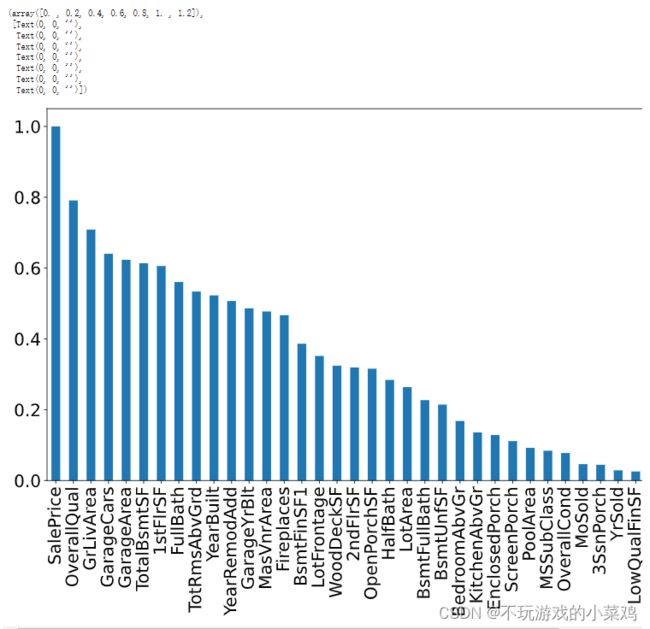
train和test分别是训练集和测试集,分别有 1460 个样本,80 个特征。
SalePrice列代表房价,是我们要预测的。
1.2 数据分布:
对数据集中的房价(SalePrice)进行取值分布
train_data['SalePrice'].describe()
#查看房价是否符合正态分布
sns.distplot(train_data['SalePrice']);
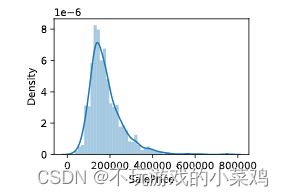
#从图上可以看出,SalePrice列峰值比较陡,并且峰值向左偏。
#也可以直接调用skew()和kurt()函数计算SalePrice具体的偏度和峰度值。
#对于偏度和峰度都比较大的情况,建议对SalePrice列取log()进行平滑。
sns.distplot(np.log(train_data['SalePrice']));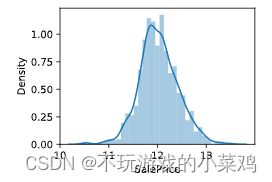
1.3房价相关特征
房价特征相关矩阵
corrmat = train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);
重点关注10个与房价相关性最强的特征
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
1.4 剔除噪声样本
#异常值处理
figure=plt.figure()
sns.pairplot(x_vars=['OverallQual','GrLivArea','YearBuilt','TotalBsmtSF'],
y_vars=['SalePrice'],data=train_data,dropna=True)
plt.show()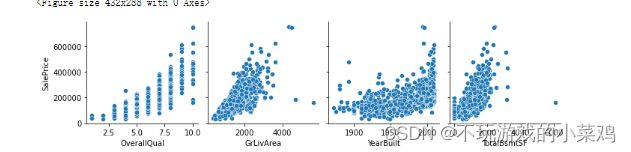
#删除异常值
train_data = train_data.drop(train_data[(train_data['OverallQual']<5) &
(train_data['SalePrice']>200000)].index)
train_data = train_data.drop(train_data[(train_data['GrLivArea']>4000) &
(train_data['SalePrice']<300000)].index)
train_data = train_data.drop(train_data[(train_data['YearBuilt']<1900) &
(train_data['SalePrice']>400000)].index)
train_data = train_data.drop(train_data[(train_data['TotalBsmtSF']>6000) &
(train_data['SalePrice']<200000)].index)
#检查是否还存在异常值
figure=plt.figure()
sns.pairplot(x_vars=['OverallQual','GrLivArea','YearBuilt','TotalBsmtSF'],
y_vars=['SalePrice'],data=train_data,dropna=True)
plt.show()
2.特征工程
2.1 修正特征类型
features['MSSubClass'] = features['MSSubClass'].apply(str)
features['YrSold'] = features['YrSold'].astype(str)
features['MoSold'] = features['MoSold'].astype(str)2.2 填充缺失数值
#观察数据的缺失情况
nan_index=((all_features.isnull().sum()/len(all_features))).sort_values(ascending=False)
#将列表中数值型的数据索引出来
numeric_features=all_features.dtypes[all_features.dtypes!='object'].index
#对数据进行标准化
all_features[numeric_features]=all_features[numeric_features].apply(
lambda x:(x-x.mean())/(x.std()))
#标准化后,每个数值特征的均值变为0,可以直接用0来替换缺失值
all_features[numeric_features]=all_features[numeric_features].fillna(0)
#离散数值转成指示特征
all_features=pd.get_dummies(all_features,dummy_na=True)#2.3生成最终训练数据
#先把合并的数据集重新分割为训练集和测试集
n_train=train_data.shape[0]
#通过values属性得到Numpy格式的数据,并转成Tensor方便后面的训练
#训练样本特征
train_features=torch.tensor(all_features[:n_train].values,dtype=torch.float)
#测试样本特征
test_features=torch.tensor(all_features[n_train:].values,dtype=torch.float)
#训练样本标签
train_labels=torch.tensor(train_data.SalePrice.values,dtype=torch.float).view(-1,1)3.模型训练
3.1线性回归模型
#定义线性回归模型
def get_net(feature_num):
net=nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(feature_num,256),
nn.ReLU(),
nn.Linear(256,1),
)
#模型参数初始化
for param in net.parameters():
nn.init.normal_(param,mean=0,std=0.01)
return net
#对数均方误差的实现
def log_rmse(net,features,labels):
with torch.no_grad():
#将小于1的值设成1,使的取对数时数值更稳定
clipped_preds=torch.max(net(features),torch.tensor(1.0))
rmse=torch.sqrt(loss(clipped_preds.log(),labels.log()))
return rmse.item()
#对数均方误差的实现
def log_rmse(net,features,labels):
with torch.no_grad():
#将小于1的值设成1,使的取对数时数值更稳定
clipped_preds=torch.max(net(features),torch.tensor(1.0))
rmse=torch.sqrt(loss(clipped_preds.log(),labels.log()))
return rmse.item()
def train(net,train_features,train_labels,test_features,test_labels,
num_epochs,learning_rate,weight_decay,batch_size):
train_ls,test_ls=[],[]
#把dataset放入DataLoader
dataset=torch.utils.data.TensorDataset(train_features,train_labels)
train_iter=torch.utils.data.DataLoader(dataset,batch_size,shuffle=True)
#这里使用了Adam优化算法
optimizer=torch.optim.Adam(params=net.parameters(),lr=learning_rate,weight_decay=weight_decay)
net=net.float()#将神经网络中的数据类型设置维浮点型
for epoch in range(num_epochs):
for X,y in train_iter:
l=loss(net(X.float()),y.float())
optimizer.zero_grad()
l.backward()
optimizer.step()
train_ls.append(log_rmse(net,train_features,train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net,test_features,test_labels))
return train_ls,test_ls测试集中的数据量m不同,因为有累加操作,所以随着数据的增加 ,误差会逐渐积累;因此衡量标准和 m 相关。为了抵消掉数据量的形象,可以除去数据量,抵消误差。通过这种处理方式得到的结果叫做 均方误差MSE(Mean Squared Error):均方误差MSE,定义如下:
上式中,yi为一个batch_size中第 i 个数据的正确答案,而为神经网络给出的预测值。
但是使用均方误差MSE受到量纲的影响。例如在衡量销售价格时,y的单位是(万元),那么衡量标准得到的结果是(万元平方)。为了解决量纲的问题,可以将其开方(为了解决方差的量纲问题,将其开方得到平方差)得到均方根误差RMSE(Root Mean Squarde Error):
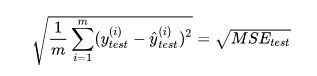
即便为了解决均方误差受到量纲的影响,采用的均方根误差,仍然存在其他影响,比如预测过程中昂贵房屋和廉价房屋的错误会给结果带来不同的影响,因此为解决这一问题,又引进对数均方差根误差,采取对数意味着预测昂贵房屋和廉价房屋的错误将同等影响结果。对数均方根误差:
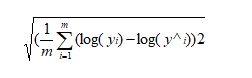
#K折交叉验证
def get_k_fold_data(k,i,X,y):
assert k>1
fold_size=X.shape[0]//k
X_train,y_train=None,None
for j in range(k):
idx=slice(j*fold_size,(j+1)*fold_size)
X_part,y_part=X[idx,:],y[idx]
#划分出验证数据集
if j==1:
X_valid,y_valid=X_part,y_part
elif X_train is None:
X_train,y_train=X_part,y_part
#划分出训练数据,剩下的进行合并
else:
X_train=torch.cat((X_train,X_part),dim=0)
#dim=0按列合并
y_train=torch.cat((y_train,y_part),dim=0)
return X_train,y_train,X_valid,y_valid
def k_fold(k,X_train,y_train,num_epochs,
learning_rate,weight_decay,batch_size):
train_l_sum,valid_l_sum=0,0
for i in range(k):
data=get_k_fold_data(k,i,X_train,y_train)
net=get_net(X_train.shape[1])
train_ls,valid_ls=train(net,*data,num_epochs,learning_rate,
weight_decay,batch_size)
#误差累计
train_l_sum+=train_ls[-1]
valid_l_sum+=valid_ls[-1]
if i==0:
d2l.semilogy(range(1,num_epochs+1),train_ls,
'epochs','rmse',
range(1,num_epochs+1),valid_ls,
['train','valid'])
#输出相应的结果:训练误差、验证误差
print('fold%d,train rmse %f,valid rmse %f'%
(i,train_ls[-1],valid_ls[-1]))
return train_l_sum/k,valid_l_sum/k3.2 模型选择
#模型选择
k,num_epochs,lr,weight_decay,batch_size=8,100,0.1,300,64
train_l,valid_l=k_fold(k,train_features,train_labels,num_epochs,lr,weight_decay,batch_size)
print('%d-fold validation:avg trian rmse %f,avg valid rmse %f'%
(k,train_l,valid_l))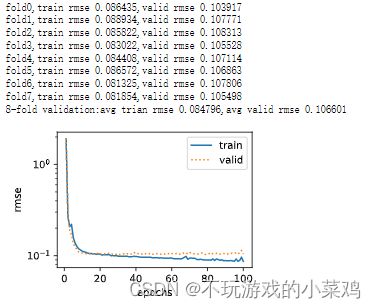
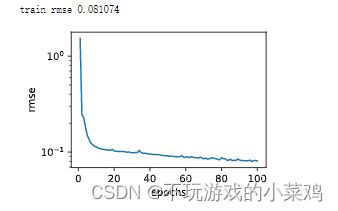
3.3模型预测
#模型预测
def train_and_pred(train_features,test_features,train_labeld,test_data,
num_epochs,lr,weight_decay,batch_size):
net=get_net(train_features.shape[1])
#第二个变量(测试误差)缺省,用_代替
train_ls,_=train(net,train_features,train_labels,None,None,
num_epochs,lr,weight_decay,batch_size)
d2l.semilogy(range(1,num_epochs+1),train_ls,'epochs','rmse')
print('train rmse %f'%train_ls[-1])
preds=net(test_features).detach().numpy()
test_data['SalePrice']=pd.Series(preds.reshape(1,-1)[0])
submission=pd.concat([test_data['Id'],test_data['SalePrice']],axis=1)
submission.to_csv('./submission.csv',index=False)
train_and_pred(train_features,test_features,train_labels,
test_data,num_epochs,lr,weight_decay,batch_size)