Pytorch+LSTM 的词汇预测
# !/usr/bin/env Python3 # -*- coding: utf-8 -*- # @version: v1.0 # @Author : Meng Li # @contact: [email protected] # @FILE : torch_LSTM.py # @Time : 2022/6/7 10:59 # @Software : PyCharm # @site: # @Description : 采用LSTM进行语料库预测,即根据一行语句的前部分,预测后部分 import torch import torch.nn.functional as F import torch.nn as nn import torchsummary import numpy as np from torch.utils.data import DataLoader, Dataset class Net(nn.Module): def __init__(self, features, hidden_size): super(Net, self).__init__() self.features = features # 输入特征维度 self.hidden_size = hidden_size # 输出特征维度 self.lstm = nn.LSTM(features, hidden_size) self.fc = nn.Linear(hidden_size, features) # 全连接输出为语料库大小 self.criterion = torch.nn.CrossEntropyLoss() def forward(self, x, y): # x.shape = [batch_size , seq_len , embedding_size] -> [seq_len , batch_size , embedding_size] # torch.nn.LSTM(input,(h_0,c_0)) API里面规定输入格式是(seq_len,batch,input_size) x = x.permute(1, 0, 2) # [seq_len , batch_size , embedding_size] output, (_, _) = self.lstm(x.float()) # output.size -> [seq_len,batch_size,hidden_size] output = output[-1] # output[-1].size -> [batch_size,hidden_size] output = self.fc(output) pred = torch.argmax(output, 1) # 输出预测值 loss = self.criterion(output, y) # 输出损失值 return pred, loss class my_dataset(Dataset): def __init__(self, input_data, target_data): self.input_data = input_data self.target_data = target_data def __getitem__(self, index): return self.input_data[index], self.target_data[index] def __len__(self): return self.input_data.size(0) def make_data(): vocab = [i for i in "abcdefghijklmnopqrstuvwxyz"] idx2word = {i: j for i, j in enumerate(vocab)} word2idx = {j: i for i, j in enumerate(vocab)} seq_data = ['make', 'need', 'coal', 'word', 'love', 'hate', 'live', 'home', 'hash', 'star'] V = len(word2idx) input_data = [] target_data = [] for seq in seq_data: input = [word2idx[n] for n in seq[:-1]] # 'm', 'a' , 'k' is input target = word2idx[seq[-1]] # 'e' is target input_data.append(np.eye(V)[input]) target_data.append(target) return torch.tensor(input_data), torch.LongTensor(target_data) def train(): vocab = [i for i in "abcdefghijklmnopqrstuvwxyz"] idx2word = {i: j for i, j in enumerate(vocab)} word2idx = {j: i for i, j in enumerate(vocab)} input_data, target_data = make_data() tensor_dataset = my_dataset(input_data, target_data) batch_size = 4 train_iter = torch.utils.data.DataLoader(tensor_dataset, batch_size, shuffle=True) n_hidden = 128 net = Net(features=len(word2idx), hidden_size=n_hidden) optim = torch.optim.Adam(net.parameters(), lr=0.001) net.train() for i in range(1000): for input_data, target_data in train_iter: pred, loss = net(input_data, target_data) optim.zero_grad() loss.backward() optim.step() if i % 100 == 0: print("step {0} loss {1}".format(i, loss.float())) net.eval() for input_data, target_data in train_iter: pred, _ = net(input_data, target_data) for j in range(0,batch_size-1): pr_temp = "" for i in range(0,3): pr_temp += idx2word[np.argmax(input_data[j,i,:].numpy())] print(pr_temp+" -> " + idx2word[pred.numpy()[j]]) break if __name__ == '__main__': train()
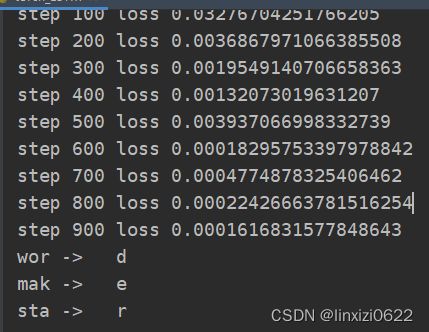
采用LSTM网络对语料库进行模型训练,能够根据单词的第一个字母到倒数第二个字母来预测最后一个字母。一个单词的前后是具有时序关系的,可以用循环神经网络进行预测。主要是为了锻炼采用LSTM进行NLP模型搭建的能力。
这里的输入是采用的one-hot形式,后面如果上大语料库数据集的话,还是会考虑其他的词向量化方法,eg:bag-of-word,word2vec&&glove等分布式固定向量化,或者elmo&&gpt&&elmo等分布式动态向量化方式。
这种建模方式可以延伸股票预测等方面,只要是具有前后时序关系的场景我觉得读可以用LSTM构建一个循环神经网络进行学习