机器学习2普通knn算法
文章目录
- KNN算法-k近邻算法(k-Nearest Neighbors)前言
-
- KNN优点:
- 快捷键:
- 一、普通knn算法是什么?
-
- 解析:
- 二、普通knn算法基础
-
- 1.分布解析
- 2.使用pycharm函数封装的形式运行KNN算法
- 3.使用scikit-learn中的knn
- 三、普通KNN小结
KNN算法-k近邻算法(k-Nearest Neighbors)前言
KNN优点:
1.思想极度简单;
2、应用数学知识少(近乎为零);
3、效果好;
4、可以解释机器算法使用过程中的很多细节问题;
5、更完整的刻画机器学习应用的流程;
快捷键:
Y :单元格转换成code类型。
M :单元格转换成Markdown类型。
R :单元格转换成Raw NBConvert类型。
Enter :进入编辑模式。
A :在当前单元格上方插入新单元格。
B :在当前单元格下方插入新单元格。
C :复制当前单元格。
D(两次) :删除当前单元格。
V :粘贴到当前单元格的下方。
Shift + V :粘贴到当前单元格的上方。
Z :撤销删除。
Ctrl+Shift+“-”:快速将一个代码块分割成两块
一、普通knn算法是什么?
解析:
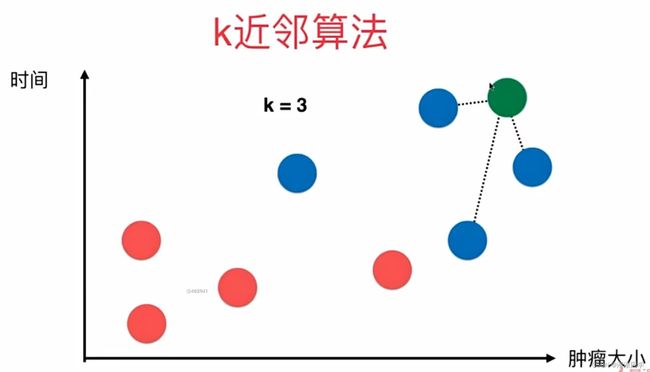
如图,就是一个肿瘤病人相关的数据,横轴代表发现肿瘤病人肿块的大小,纵轴代表发现肿瘤块的时间,每一个病人肿瘤发现时间及大小就构成图上一个点,恶性肿瘤用蓝色点表示,良性用红色。这就是初始信息,如果现状新来一个病人(绿点),那么分析他最有可能是良性肿瘤患者还是恶性肿瘤患者?我们采用K近邻算法来算。首先取一个k值,k=3;
在所有的点中寻找离绿点最近的三个点,之后这三个点用自己的属性进行投票,如图,蓝色:红色=3:0,因此就说这个绿点有很高的概率也是蓝色的点,即这个新的病人很有可能是一个恶性肿瘤患者;
这就是k近邻算法;

二、普通knn算法基础
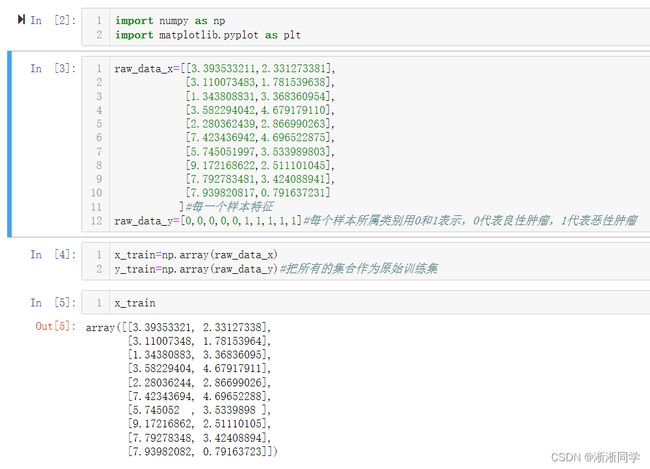
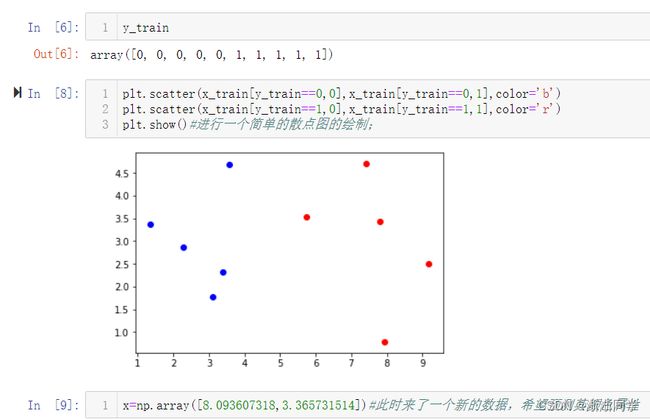
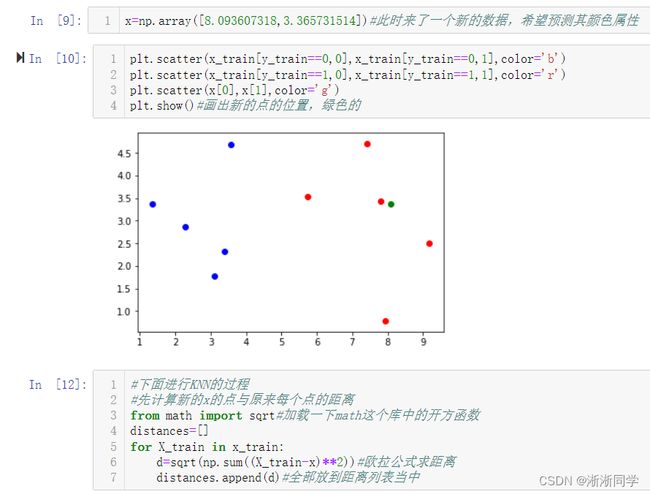
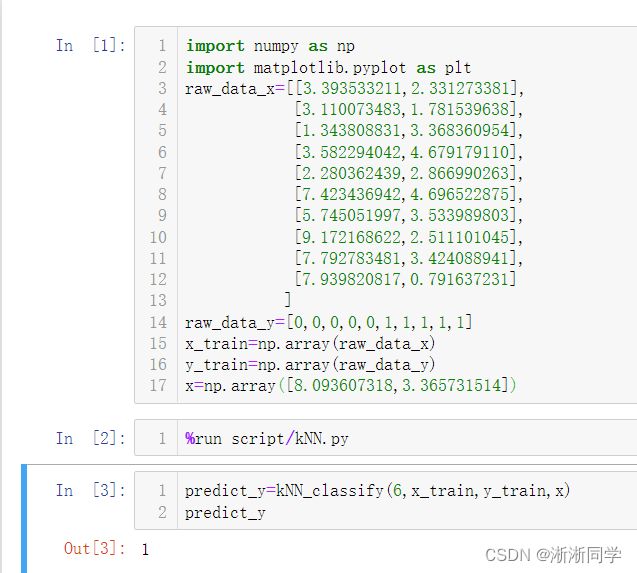
1.分布解析

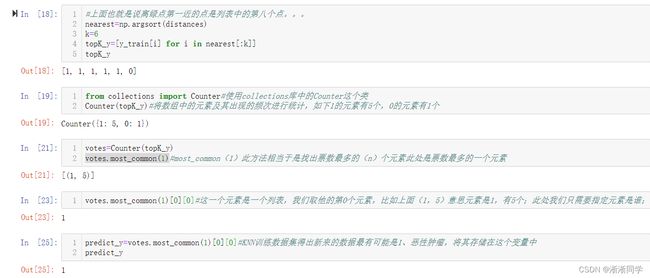
2.使用pycharm函数封装的形式运行KNN算法
使用pycharm函数封装的形式运行KNN算法:
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k,x_train,y_train,x):
assert 1<=k<=x_train.shape[0],“k must be valid”
assert x_train.shape[0]==y_train.shape[0],
“the size of x_train must equal to the size of y_train”
assert x_train.shape[1]==x.shape[0],
“the feature number of x must bu equal to x_train”
distances=[sqrt(np.sum((X_train-x)**2)) for X_train in x_train]
nearest = np.argsort(distances)
topK_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k,x_train,y_train,x):
assert 1<=k<=x_train.shape[0],"k must be valid"
assert x_train.shape[0]==y_train.shape[0],\
"the size of x_train must equal to the size of y_train"
assert x_train.shape[1]==x.shape[0],\
"the feature number of x must bu equal to x_train"
distances=[sqrt(np.sum((X_train-x)**2)) for X_train in x_train]
nearest = np.argsort(distances)
topK_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]


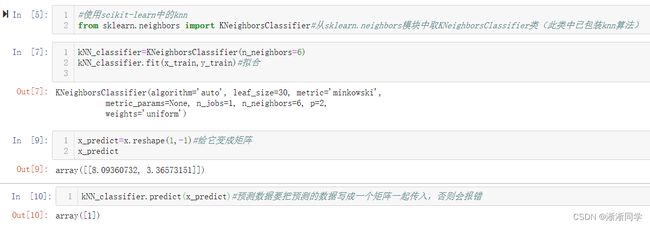
3.使用scikit-learn中的knn
使用scikit-learn中的knn:
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
# 初始化KNN分类器
def init(self,k):
assert k>=1,“k must be valid”
self.k=k
self._x_train=None
self._y_train = None
def fit(self,x_train,y_train):
“”“根据训练数据集训练knn分类器”“”
assert x_train.shape[0] == y_train.shape[0],
“the size of x_train must equal to the size of y_train”
assert self.k<=x_train.shape[0],
“the size of x_train must be at least k.”
self._x_train = x_train
self._y_train = y_train
return self
def predict(self,x_predict):
assert self._x_train is not None and self._y_train is not None,
“must fit before predict!”
assert x_predict.shape[1]==self._x_train.shape[1],
“the feature number of x_predict must be equal to x_train”
y_predict=[self._predict(x) for x in x_predict]
return np.array(y_predict)
def _predict(self,x):
“”“给一个单个预测数据x,返回x的预测结果”“”
assert x.shape[0] ==self._x_train.shape[1],
“the feature number of x must be equal to x_train”
distances = [sqrt(np.sum((X_train - x) ** 2)) for X_train in self._x_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
# 初始化KNN分类器
def __init__(self,k):
assert k>=1,"k must be valid"
self.k=k
self._x_train=None
self._y_train = None
def fit(self,x_train,y_train):
"""根据训练数据集训练knn分类器"""
assert x_train.shape[0] == y_train.shape[0], \
"the size of x_train must equal to the size of y_train"
assert self.k<=x_train.shape[0],\
"the size of x_train must be at least k."
self._x_train = x_train
self._y_train = y_train
return self
def predict(self,x_predict):
assert self._x_train is not None and self._y_train is not None,\
"must fit before predict!"
assert x_predict.shape[1]==self._x_train.shape[1],\
"the feature number of x_predict must be equal to x_train"
y_predict=[self._predict(x) for x in x_predict]
return np.array(y_predict)
def _predict(self,x):
"""给一个单个预测数据x,返回x的预测结果"""
assert x.shape[0] ==self._x_train.shape[1],\
"the feature number of x must be equal to x_train"
distances = [sqrt(np.sum((X_train - x) ** 2)) for X_train in self._x_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]

三、普通KNN小结
knn算法可以说是机器算法中的唯一一种不需要训练过程的算法;
knn近邻算法是非常特殊的,可以被认为是没有模型的算法,为了和其他算法统一,可以认为训练数据集就是模型本身;