使用LSTM进行预测,有一对一、多对一、多对多的预测,其中有一些疑问一起探讨(一)
数据说明
我的数据是1万6千多的数据,想用4个特征(这个特征未加输出)预测2个输出,也就是多对多的预测。
使用LSTM 一对一的预测
先用对一的预测简单一些,就是用一段时序数据取预测,代码例子看的MATLAB工具箱的例子
%代码测试可行。大致看了下,没看蛮懂,继续看
%后用我的数据带入进去看下
clc
clear all;
close all;
%% 加载示例数据。
%chickenpox_dataset 包含一个时序,其时间步对应于月份,值对应于病例数。
%输出是一个元胞数组,其中每个元素均为单一时间步。将数据重构为行向量。
[num1,str1,raw1]=xlsread("shuju1.xlsx");
% data = num1(1:5:3000,7)'; %600个行数据
data = num1(1:5:16374,7)'; %600个行数据
% data = chickenpox_dataset;%自带的数据集
% data = [data{:}]; %cell变double
figure(1);
plot(data)
xlabel("Month")
ylabel("Cases")
title("Monthly Cases of Chickenpox")
%% 对训练数据和测试数据进行分区。
%序列的前 90% 用于训练,后 10% 用于测试。
numTimeStepsTrain = floor(0.9*numel(data));%numTimeStepsTrain训练集数目 ;字面翻译:训练的时间步长
dataTrain = data(1:numTimeStepsTrain+1); %1行n列
dataTest = data(numTimeStepsTrain+1:end);
%% 标准化数据
%为了获得较好的拟合并防止训练发散,将训练数据标准化为具有零均值和单位方差。
%在预测时,您必须使用与训练数据相同的参数来标准化测试数据。
mu = mean(dataTrain');% mean函数默认是列的均值 。我这里转置了的,但是原始文件之前没有,结果一样。
sig = std(dataTrain');
dataTrainStandardized = (dataTrain - mu) / sig;
%% 准备预测变量和响应
%要预测序列在将来时间步的值,请将响应指定为将值移位了一个时间步的训练序列。
%也就是说,在输入序列的每个时间步,LSTM 网络都学习预测下一个时间步的值。预测变量是没有最终时间步的训练序列。
XTrain = dataTrainStandardized(1:end-1);%这个输入是时间序列的1-n-1
YTrain = dataTrainStandardized(2:end); %这个输出是时间序列的2-n
%% 定义 LSTM 网络架构
%创建 LSTM 回归网络。指定 LSTM 层有 200 个隐含单元
numFeatures = 1; %输入
numResponses = 1; %输出
numHiddenUnits = 200;%隐含层层数
layers = [ ...
sequenceInputLayer(numFeatures)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numResponses)
regressionLayer];%第四个参数说明用于回归问题
%指定训练选项。 这里的隐含层似乎可以多层
%将求解器设置为 'adam' 并进行 250 轮训练 这个参数是最大迭代次数,即进行250次训练,每次训练后更新神经网络参数。
%要防止梯度爆炸,请将梯度阈值设置为 1。
%指定初始学习率 0.005,在 125 轮训练后通过乘以因子 0.2 来降低学习率。
options = trainingOptions('adam', ...
'MaxEpochs',250, ...
'GradientThreshold',1, ...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ...
'LearnRateDropFactor',0.2, ...
'Verbose',0, ...
'Plots','training-progress');
%% 训练 LSTM 网络
%使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(XTrain,YTrain,layers,options);
%% 预测将来时间步
%要预测将来多个时间步的值,请使用 predictAndUpdateState 函数一次预测一个时间步,并在每次预测时更新网络状态。 对于每次预测,使用前一次预测作为函数的输入。
%使用与训练数据相同的参数来标准化测试数据。
dataTestStandardized = (dataTest - mu) / sig;
XTest = dataTestStandardized(1:end-1);
%要初始化网络状态,请先对训练数据 XTrain 进行预测。
%接下来,使用训练响应的最后一个时间步 YTrain(end) 进行第一次预测。
%循环其余预测并将前一次预测输入到 predictAndUpdateState。
%对于大型数据集合、长序列或大型网络,在 GPU 上进行预测计算通常比在 CPU 上快;其他情况下,在 CPU 上进行预测计算通常更快;对于单时间步预测,请使用 CPU。
%使用 CPU 进行预测,请将 predictAndUpdateState 的 'ExecutionEnvironment' 选项设置为 'cpu'。
net = predictAndUpdateState(net,XTrain); %请先对训练数据 XTrain 进行预测。
[net,YPred] = predictAndUpdateState(net,YTrain(end)); %使用训练响应的最后一个时间步 YTrain(end) 进行第一次预测。
numTimeStepsTest = size(XTest,2); %返回数组A中元素的数量 字面翻译:测试时间步长
for i = 2:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,YPred(:,i-1),'ExecutionEnvironment','cpu');
end
%使用先前计算的参数对预测去标准化。
YPred = sig*YPred + mu;
%训练进度图会报告根据标准化数据计算出的均方根误差 (RMSE)。根据去标准化的预测值计算 RMSE。
YTest = dataTest(2:end);
rmse = sqrt(mean((YPred-YTest).^2))
%使用预测值绘制训练时序。
figure(2);
plot(dataTrain(1:end-1))
hold on
idx = numTimeStepsTrain:(numTimeStepsTrain+numTimeStepsTest);
plot(idx,[data(numTimeStepsTrain) YPred],'.-')
hold off
xlabel("Month")
ylabel("Cases")
title("Forecast")
legend(["Observed" "Forecast"])
%将预测值与测试数据进行比较。
figure(3)
subplot(2,1,1)
plot(YTest)
hold on
plot(YPred,'.-')
hold off
legend(["Observed" "Forecast"])
ylabel("Cases")
title("Forecast")
subplot(2,1,2)
stem(YPred - YTest);%按照茎状形式绘制
xlabel("Month")
ylabel("Error")
title("RMSE = " + rmse)
%% 使用观测值更新网络状态
%如果您可以访问预测之间的时间步的实际值,则可以使用观测值而不是预测值更新网络状态。
%首先,初始化网络状态。要对新序列进行预测,请使用 resetState 重置网络状态。
%重置网络状态可防止先前的预测影响对新数据的预测。重
%置网络状态,然后通过对训练数据进行预测来初始化网络状态。
net = resetState(net);
net = predictAndUpdateState(net,XTrain);
%对每个时间步进行预测。对于每次预测,使用前一时间步的观测值预测下一个时间步。
%将 predictAndUpdateState 的 'ExecutionEnvironment' 选项设置为 'cpu'。
YPred = [];
numTimeStepsTest = numel(XTest);
for i = 1:numTimeStepsTest
[net,YPred(:,i)] = predictAndUpdateState(net,XTest(:,i),'ExecutionEnvironment','cpu');
end
%使用先前计算的参数对预测去标准化。
YPred = sig*YPred + mu;
%计算均方根误差 (RMSE)。
rmse = sqrt(mean((YPred-YTest).^2))
%将预测值与测试数据进行比较。
figure
subplot(2,1,1)
plot(YTest)
hold on
plot(YPred,'.-')
hold off
legend(["Observed" "Predicted"])
ylabel("Cases")
title("Forecast with Updates")
subplot(2,1,2)
stem(YPred - YTest)
xlabel("Month")
ylabel("Error")
title("RMSE = " + rmse)
这里的仿真结果,用的matlab自带的的数据集,效果就很好:对于预测的后49步


明显可以看出效果不错,但是后者更好一些。在一些文章里面提到:前面的才叫多步预测,毕竟都已知真实值了还需要取预测嘛?
我的工作多半只需要单步预测就够了,所以我就用后者也没关系。
但是带入我的数据,对其中一个输出采用上面的代码测试:

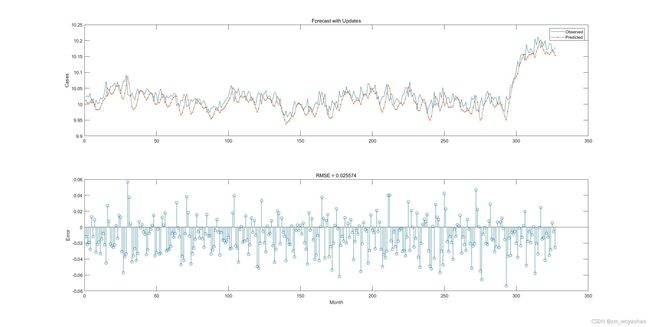
明显可以看出效果太差了。前面的简直南辕北辙,可能是我的滑动窗口设置的问题,我取得数据量的0.9,我的总数据量一万多个。后面的还凑合,但是毕竟把前一个的真实值作为输入了的。
所以这个输入输出对于我的数据用这个方案是不合适的。
2.多对单(多)的预测
我目前还不知道多个特征需要加上输出吗?也就是把前一个的输出也作为特征。
我下面的数据是加了的,测试下:
%% 多输入多步预测
%后用我的数据带入进去看下 这个以LSTM1的样式改 多变量多步预测。
%过拟合;梯度爆炸 训练过程中的一系列问题
%代码初步跑通,但是差别太大了。 再调下代码或者加大数据
clc;
clear all;
close all;
% [num1,str1,raw1]=xlsread("shuju1.xlsx");
[num1,~,~]=xlsread("shuju3.xlsx"); %放风阀变化大一些的, 数据三不能做时序数据的预测,由于部分冗余的数据我踢掉了导致有部分数据前后不对。
data = num1(1:5:end,:);
input_0_0=data(:,1:4);
%增加一个特征,把要预测的也作为特征
input_0_1=zeros(size(data,1),1);
input_0_1(1)=data(1,6);
for i=2:size(data,1)
input_0_1(i)=data(i-1,6);
end
input_0=horzcat(input_0_0,input_0_1);
% output_0=data(:,6:7);
output_0=data(:,6);
[input_1,input_normopt] =mapminmax(input_0',0,1);
[output_1,output_normopt] = mapminmax(output_0',0,1);
% 预测的流量压力的滑动窗口大小为16000,初步设置为这个
%分类的LSTM:它必须从序列输入层开始,C是一个包含序列或时间序列预测器的元胞数组。C是d行1列,d代表有多少个训练样本,每个训练样本又包括N行M列,N代表训练样本的数据维度,M代表序列长度,
% y是标签的分类向量,是categorical类型。因此,训练数据应该转换成元胞数组,训练数据标签应该转换成categorical类型。
% 对于回归问题,Y是目标矩阵或数字序列的单元数组
k =1; %滑动窗口设置为1 具体设多少需要衡量
for i = 1:size(input_1,2)-k+1
input_cell{i,1} = input_1(:,i:i+k-1); %将其分为101个序列,每个序列长度500,特征5个
output_cell(i,:)= output_1(:,i+k-1);
end
% 时间步长设置
% 对训练数据和测试数据进行分区。 序列的前 90% 用于训练,后 10% 用于测试。
n = floor(0.8*size(input_cell,1)); %训练集,测试集样本数目划分
input_traincell = input_cell(1:n,:);
output_traincell = output_cell(1:n,:);
input_testcell = input_cell(n+1:end,:);
output_testcell = output_cell(n+1:end,:);
%% 定义 LSTM 网络架构
%创建 LSTM 回归网络。 (LSTM1里面用的是两层隐含层)
inputSize = 5; %数据输入x的特征维度 ,增加了前一秒的输出作为特征
outputSize = 1; %数据输出y的特征维度
numhidden_units1=200;
numhidden_units2=200;
% lstm
layers = [ ...
sequenceInputLayer(inputSize,'name','input') %输入层设置
% lstmLayer(numhidden_units1,'Outputmode','sequence') %学习层设置(cell层)
lstmLayer(numhidden_units1,'Outputmode','sequence','name','hidden1') %隐藏层1
dropoutLayer(0.3,'name','dropout_1') %隐藏层1权重丢失率,防止过拟合
lstmLayer(numhidden_units2,'Outputmode','last','name','hidden2') %隐藏层2
dropoutLayer(0.3,'name','dropout_2') %隐藏层2权重丢失率,防止过拟合 是不是丢失太多了
fullyConnectedLayer(outputSize,'name','fullconnect') %全连接层设置(outputsize:预测值的特征维度)
regressionLayer('name','out')]; %回归层(因为负荷预测值为连续值,所以为回归层)
% r sequence-to-one regression, ----lstmLayer(numHiddenUnits,'OutputMode','last')
% sequence-to-sequence regression---lstmLayer(numHiddenUnits,'OutputMode','sequence')
options = trainingOptions('adam', ... %优化算法
'MaxEpochs',5000, ... %遍历样本最大循环数 进行MaxEpochs轮训练 这个参数是最大迭代次数,即进行MaxEpochs次训练,每次训练后更新神经网络参数 %似乎迭代次数是他的倍数
'GradientThreshold',1,... %梯度阈值,防止梯度爆炸
'ExecutionEnvironment','cpu',... %运算环境
'InitialLearnRate',0.00001, ... %初始学习率
'LearnRateSchedule','piecewise', ... % 学习率计划
'LearnRateDropPeriod',50, ... %10个epoch后学习率更新
'LearnRateDropFactor',0.2, ... %学习率衰减速度 学习率变为0.0002
'Shuffle','once',... % 是否重排数据顺序,防止数据中因连续异常值而影响预测精度
'MiniBatchSize',300,... % 批处理样本大小 分块尺寸 作为小批量数
'Verbose',0, ... %命令控制台是否打印训练过程 还有verbose=false
'Plots','training-progress'... % 打印训练进度
);
% 'SequenceLength',60,... %LSTM时间步长 这是之前的参数
%指定训练选项,求解器设置为adam, 250 轮训练。
%梯度阈值设置为 1。指定初始学习率 0.005,在 125 轮训练后通过乘以因子 0.2 来降低学习率。
% 'SequenceLength', 'longest',...
% bilstmLayer(numHiddenUnits,'OutputMode','last') 双向LSTM层
% options = trainingOptions('adam', ...
% 'MaxEpochs',100, ...
% 'GradientThreshold',1, ...
% 'InitialLearnRate',0.0005, ...
% 'LearnRateSchedule','piecewise', ...
% 'LearnRateDropPeriod',50, ...
% 'LearnRateDropFactor',0.02, ...
% 'Verbose',0, ...
% 'Plots','training-progress');
%bias: 隐层状态是否带bias,默认为true。bias是偏置值,或者偏移值。没有偏置值就是以0为中轴,或以0为起点。偏置值的作用请参考单层感知器相关结构
%'L2Regularization',0.0010, ...
% 'Shuffle','never', ...
% 训练 LSTM 网络
%使用 trainNetwork 以指定的训练选项训练 LSTM 网络。
net = trainNetwork(input_traincell,output_traincell,layers,options);
%% 预测 代码用的单输入到单输出的样式 代码有问题,不知道是不适合还是我的理解问题
% net = resetState(net);
% net = predictAndUpdateState(net,input_traincell);
% %对每个时间步进行预测。对于每次预测,使用前一时间步的观测值预测下一个时间步。
% %将 predictAndUpdateState 的 'ExecutionEnvironment' 选项设置为 'cpu'。
% YPred = [];
% numTimeStepsTest = numel(output_testcell);
% for i = 1:numTimeStepsTest
% [net,YPred(:,i)] = predictAndUpdateState(net,input_testcell(:,i),'ExecutionEnvironment','cpu');
% end
%% 预测,用的多输入的样式
% %疑问1:这里分k_0次预测,前一个预测会对后一个有影响吗? 疑问2:我的输出的样式对吗?我的有两个参数 疑问3:样本少了所以不准?
% k_0=4; %预测4分钟
% for i=1:k_0
% period = 1+(i-1)*12:i*12; %每次预测周期长度,这里为1分钟
% [net,yprenorm] = predictAndUpdateState(net,input_testcell(period,:)); %动态更新,预测 首次运行会报错误
% ypre(:, period ) = mapminmax('reverse',yprenorm',output_normopt); %预测值反归一化
% ytest(:,period) = mapminmax('reverse',output_testcell(period,:)',output_normopt);
% figure(1);
% subplot(2,2,i)
% plot(ypre(1,period),'r--');
% hold on;
% plot(ytest(1,period),'b+');
% % stem(ypre(period)-ytest(period));
% legend('ypre','real','Location','westoutside')
%
% figure(2);
% subplot(2,2,i)
% plot(ypre(2,period),'r--');
% hold on;
% plot(ytest(2,period),'b+');
% end
%对于单输出的演示
period = 1:800; %预测测试集
[net,yprenorm] = predictAndUpdateState(net,input_testcell(period,:)); %动态更新,预测 首次运行会报错误
ypre(:, period ) = mapminmax('reverse',yprenorm',output_normopt); %预测值反归一化
ytest(:,period) = mapminmax('reverse',output_testcell(period,:)',output_normopt);
figure(1);
plot(ypre(1,period),'r--');
hold on;
plot(ytest(1,period),'b+');
legend("预测值","真实值");
[c,l]=size(ypre(1,period));
error=ypre(1,period)-ytest(1,period);
MAPE1=sum(abs(error)./ytest(1,period))/l;%平均绝对百分比误差MAPE,平均绝对误差没有分母
MAE1=sum(abs(error))/l; %平均绝对误差
MSE1=error*error'/l; %均方误差
RMSE1=MSE1^(1/2); %均方根误差
R_1=1-sum((ypre(1,period)-ytest(1,period)).^2)/sum((ytest(1,period)-mean(ytest(1,period))).^2); %决定系数
%命令行展示模型效果
disp(['-----------------------误差计算--------------------------'])
disp(['平均绝对百分比误差MAPE为:',num2str(MAPE1)])
disp(['平均绝对误差MAE为:',num2str(MAE1)])
disp(['均方误差MSE为: ',num2str(MSE1)])
disp(['均方根误差RMSE为: ',num2str(RMSE1)])
disp(['决定系数R为: ',num2str(R_1)])
上述代码对于多对单和多对多的预测都可以跑通,修改为多对多的只需要把输出增加就可以了
数据有4千多个,但是预测效果很差劲…
第一个options 参数仿真过程,特别快,是一条直线,我也不知道为什么

第二个options 参数,仿真过程慢一些 。比上一个好但是趋势和偏差也相差太大了,好垃圾
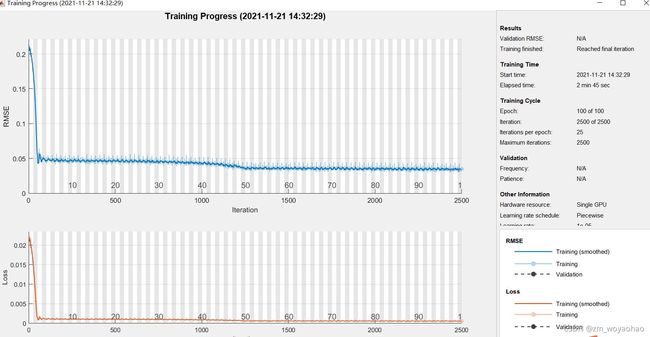

调了两天的参数,看了csdn和知乎的例子,但是查看的论文也不会具体到所有的参数都会告知,不知道为什么?这个结果太离谱了
我的滑动窗口k就设置的1, 单步预测
不知道是我的数据不适合用lstm,还是代码问题 或者参数没调对 迷茫…
我只是lstm的小白一枚,欢迎大家和我探讨。qq:1003041115