Reducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder 论文笔记
Reducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder 论文笔记
- 一、Abstract
- 二、引言
- 三、Related Works
- 四、Visually-Grounded Question Encoder (VGQE)
-
- 4.1 VGQE cell
-
- VGW module
- 4.2 Using VGQE cell to encode the question
- 4.3 Baseline VQA architecture
- 五、Experiments and Results
-
- 5.1 Results
- 5.3 Performance of VGQE on other baselines
- 5.4 Performance of VGQE on the standard VQAv2 benchmark
- 六、结论
- 七、补充细节材料
写在前面
这篇文章同样之前已经看过一遍,现在拿出来再复习一下,此文有个最牛皮的地方在于并未减小VQA模型在VQAv2数据集上的精度,反而提升了该精度。与之相比,目前我所看到的文章only this能做到这一点,也就是 哼,一个能打的都木有,值得称赞!
- 论文链接:Reducing Language Biases in Visual Question Answering with Visually-Grounded Question Encoder
- 代码链接:暂无~
- 收录于 ECCV 2020
一、Abstract
当前VQA模型极度依赖于训练集中的语言Bias,本文提出新的model-agnostic问题编码器,Visually-Grounded Question Encoder(VGQE,下同)。VGQE平等的利用了视觉和语言模态的信息,加在三个VQA模型上的VGQE能够在VQAv2数据集以及VQA-CPv2数据集上提升模型性能。重点指出了不像之前的方法并未在VQAv2数据集上降低模型的性能,反而增加了这些模型的性能。
二、引言
视觉问答所需要的能力:目标检测与识别,物体计数,基于知识的推理,细粒度识别,常识推理等。因此这样一种多领域任务能够衡量出计算机是否能够达到与人类同等的能力。
提出数据集→文献证明存在语言bias→泛化能力差→原因:VQA数据集存在语言bias→解决方法:有一些方法尝试减少语言长尾的分布,另一些方法尝试提高模型的visual-grounding能力。但目前这些方法都导致了模型在VQAv2数据集上性能的下降。
接下来叙述一下现有VQA模型的一般思路,点出这些模型的问题表示并未依赖于图像的ground,而是直接依赖于答案(相同的答案太多以至于和问题绑定在一起),这使得模型会学习问题类型和答案之间的强烈关联,导致模型过度拟合最频繁的答案所关联的问题表示,因此忽略了图像模态。
本文提出一种一般化的问题编码器VGQE,其不仅通过问题中的语言信息来编码问题,而且能够利用图像中的视觉信息进行编码。下图给出了VGQE与传统VQA编码问题的模型对比,

VGQE,对于每一个问题词,都会去寻找到最重要的视觉特征并产生视觉定位的词嵌入向量,因此产生的向量既包含问题信息又包含视觉信息。然后将这些视觉定位的词嵌入向量通过一个RNN(嵌入到VGQE内部)来进一步编码问题。由于VGQE会考虑到视觉对象的不同,因此能够减少训练集中的特定问题样式和最频繁的答案之间的关联。
VGQE的优点:能够非常简单地融入到现有的VQA模型中去,从而替代传统的基于语言的问题编码器;应用到MUREL、UpDn、BAN,能够提升这些模型的性能;在VQA-CPv2上,性能很强;不像其他方法在VQAv2数据集上使得模型在精度上下降,反而提高了这些模型的性能,我觉得这一点才是最牛皮的。
三、Related Works
简单说明一下数据集Bias的由来,且无可避免,然后举出了一些,点出本文重点关注的是VQA模型中的语言Bias及其解决方法。
- 针对数据集的解决方法:
用另外的数据集来干掉数据集中的Bias,e.g. VQAv2→VQAv1,但是VQAv2中也存在Bias,因此VQA-CP数据集闪亮登场。这里也给出了一组数据,在VQAv2上面约有66%的精度的模型,放到VQA-CPv2上,直接给干到约40%的精度了。 - 针对模型结构的解决方法:GVQA模型,设计比较复杂,很难适合其他模型使用;归一化技术应用到问题编码器上来减少Bias;Question-only分支的模型,采用降低区别性很强的答案特征对应的损失,DoE loss;RUBi,去除DoE损失,改用sigmoid操作来动态调整原始模型的输出,进而调节分类损失,达到减小Bias的作用。但是RUBi在减少Bias的同时也在削弱模型的推理性能;HINT,采用手工标注的注意力图微调模型;SCR,同样采用手工标注的注意力图来提升模型视觉定位的能力,然而这些方法需要额外的数据集进行补充,代价高昂的同时也会造成性能的下降;还有一种方法是建立在GVQA模型之上的,利用语言注意力模块将问题划分为三个部分:问题类型/参考目标/用于参考目标的特定特征,该方法进一步利用了图像中的信息来推理答案,但是在VQAv2上仍然使得模型性能下降了。
通过上述这些方法的对比,要么是减少语言侧的影响,要么通过标注数据来提升视觉定位的效果,但是这些方法在降低Bias的同时也使得在VQAv2上的性能下降,相反作者提出的方法(采用视觉定位的问题表示来提高问题的表示能力)在其他模型上都有着性能提高的表现,并且不需要外部的数据标注或者微调。
- 传统的问题编码方法及缺陷:
之前的方法一般采用循环序列(LSTM\GRU)来编码问题表示(one-hot 向量),缺陷是每一次都需要使用词表。之后采用预训练的词向量,例如Glove,BERT等等,再后来是ViLBERT、LXMERT等模型。这些模型在对问题进行编码时,同样只使用问题单词,因此未能基于视觉对象来区分问题,故仍然存在Bias。
再回过头来说作者的VGQE,同时利用视觉和语言模态来产生基于视觉定位的问题表示。与之类似的方法有FiLM,虽然FiLM使用了互补的信息,但利用的是问题上下文来影响图像编码,作者提出的VGQE是将视觉信息嵌入到问题编码中。
四、Visually-Grounded Question Encoder (VGQE)
首先概括框架,本文采用RNN作为VQA的基础模型,但是问题编码的RNN换成了VGQE。VGQE的输入为当前词的词嵌入向量以及图像中相关的视觉概念,然后输出视觉定位的问题词嵌入向量,这些词嵌入向量之后通过一个RNN结构来编码序列信息。下一段讲解一般的VQA模型的输入表示,图像特征 V = { v i ∈ R d v } i ∈ [ 1 , k ] V={\{}v_i \in {\mathbb R^{d_v}}{\}}_{i\in [1,k]} V={vi∈Rdv}i∈[1,k]、标签特征 L = { l i ∈ R d w } i ∈ [ 1 , k ] L={{\{}l_i \in \mathbb R^{d_w}{\}}_{i\in[1,k]}} L={li∈Rdw}i∈[1,k],第 t t h t^th tth个问题词的特征 q t ∈ R d w q_t\in \mathbb R^{d_w} qt∈Rdw
4.1 VGQE cell
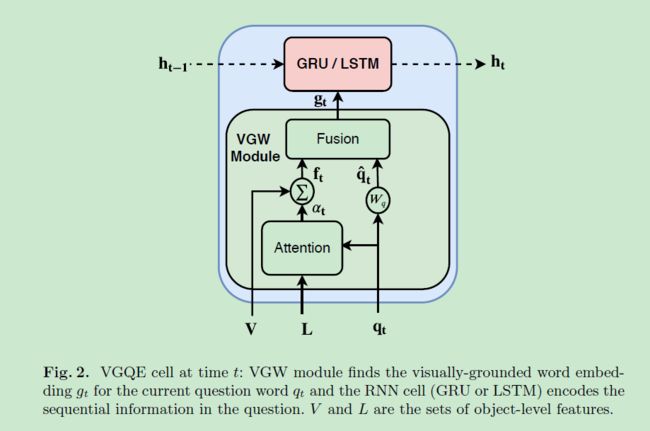
上面这幅图是VGQE的基本单元,输入为 V , L , q t , h t − 1 V,L,q_t,h_{t-1} V,L,qt,ht−1,输出为 h t h_t ht,即
h t = V G Q E ( V , L , q t , h t − 1 ) h_{t}=VGQE(V,L,q_t,h_{t-1}) ht=VGQE(V,L,qt,ht−1)下面就是对VGQE的解析,拆分为VGW和GRU/LSTM模块,其中VGW负责获取与当前词 q t q_{t} qt相关的视觉定位语义词向量 g t {g_t} gt。循环神经网络这一块没提,估计也就是个nn.LSTM或者nn.GRU搞定的事情,所以全文重点主要是对VGW模块的解析。
VGW module
该模块又得划分成Attention和Fusion子模块:
- Attention:计算视觉特征 f t f_t ft和问题词嵌入向量 q t q_t qt。
将目标标签特征 L L L和问题词 q t q_t qt作为输入,并输出相关性得分 α t ∈ R k \alpha_t\in\mathbb R^k αt∈Rk, α t \alpha_t αt中的 k k k个值用来对图像中的 k k k个目标和当前词 q t q_t qt进行打分。之后将 α t \alpha_t αt对当前图像上提取的目标特征 V V V进行加权求和,输出视觉特征 f t f_t ft,即:
f t = ∑ i = 1 k α t [ i ] ∗ v i α t = softmax ( w a T ( W ( L ∗ ( 1 q t ) ) T ) ) \begin{aligned} f_{t} &=\sum_{i=1}^{k} \alpha_{t}[i] * v_{i} \\ \alpha_{t} &=\operatorname{softmax}\left(w_{a}^{T}\left(W\left(\mathbf{L} *\left(\mathbb{1} q_{t}\right)\right)^{T}\right)\right) \end{aligned} ftαt=i=1∑kαt[i]∗vi=softmax(waT(W(L∗(1qt))T)) - Fusion:用来融合 f t & q t f_t ~\&~q_t ft & qt,产生视觉定位词向量 g t g_t gt。这里各种融合方法例如逐元素相乘,双线性融合等都可拿来用,本文采用BLOCK融合方式 F m F_m Fm(果然还是这种吊打其他,嘿嘿)。
Ben-Younes, H., Cadene, R., Thome, N., Cord, M.: Block: Bilinear superdiagonal fusion for visual question answering and visual relationship detection. In: Proceedings of the AAAI Conference on Arti cial Intelligence. vol. 33, pp. 8102-8109 (2019)
用公式表示为: g t = F m ( f t , q ^ t ; Θ ) g_{t}=F_{m}\left(f_{t}, \hat{q}_{t} ; \Theta\right) gt=Fm(ft,q^t;Θ),其中 Θ \Theta Θ为训练参数, q ^ t = W ( q t ) \hat{q}_{t}=W(q_t) q^t=W(qt)为两层线性层,起到改变维度的作用。重点来了:对于相同的词汇,例如,那么问题词中的“黄绿“”就会根据 g t g_{t} gt的不同而区分开来。
4.2 Using VGQE cell to encode the question

本文搭建的网络图,主要是把原来的问题分支RNN给替换成了本文提出的VGQE,而VGQE里面的RNN采用GRU来搭建。
4.3 Baseline VQA architecture
采用了RUBi相同的Baseline网络,即简化版的MUREL:
Cadene, R., Ben-Younes, H., Cord, M., Thome, N.: Murel: Multimodal relational reasoning for visual question answering. In: IEEE Conference on Computer Vision and Pattern Recognition. pp. 1989{1998 (2019)
五、Experiments and Results
VQAv2数据集和VQA CPv2数据集,采用2048维度的UpDn特征,预训练的Glove词向量,Adam优化器。
5.1 Results




5.3 Performance of VGQE on other baselines
同表4.1。
5.4 Performance of VGQE on the standard VQAv2 benchmark

六、结论
不吹不黑,光凭增强VQAv2数据集的能力足够打到一众选手。
七、补充细节材料
如果目标标签包含两个词,对两个词的词向量相加;RNN1024隐藏层,512词嵌入向量维度,BLOCK融合采用15个chunks,投影空间维度1000,输出维度2048。
写在后面
已经记不清这篇开头是什么时候的了,只是知道鸽了好久,本以为半个月一篇,忙起来真是顾不了~~