自己对 RepVGG 的一点理解
RepVGG
论文地址:https://arxiv.org/abs/2101.03697
代码:GitHub - DingXiaoH/RepVGG: RepVGG: Making VGG-style ConvNets Great Again
一、为啥提出这个论文
1.作者指出,现有的很多模型其比较复杂,多分枝占内存,推理速度不快。基于这些,作者提出了自己的创新点:RepVGG
(1)推理时没有任何分支结构
(2)模型推理只使用 3x3 卷积和 ReLuU
(3)具体的结构是预先定义好的,不需要通过自动搜索,也没有复杂的设计
作者对比了RepVGG与现有的一些网络差异,也有纯plain网络,但是这样网络精度低于resnet,以及一些 re-parameter 的网络,但是作者的这个对于 trainning plain CovNets 更为关键。(论文中这句话没看懂)原文: Compared to our method, the difference is that they are designed for component-level improvements and used as a drop-in replacement for conv layers in any architecture, while our structural re-parameterization is critical for training plain ConvNets, as shown in Sect. 4.2.
接着作者说一些硬件还有库对3x3卷积有着很好的加速。
使用简单网络的三个原因:快,内存占用小,灵活
作者的网络在训练的时候是: y =x + g(x) + f (x)
网络结构:
-
5个stage,每个stage有 3x3 卷积层,第一个 stage 进行下采样,stride=2
-
用一个全局平均池化层+全连接层作为网络的head,用于分类
后面作者就介绍了 RepVGG的网络构成,以及一些实验。
自己对每层参数理解:
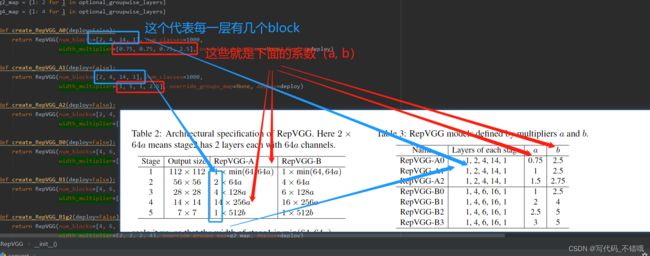
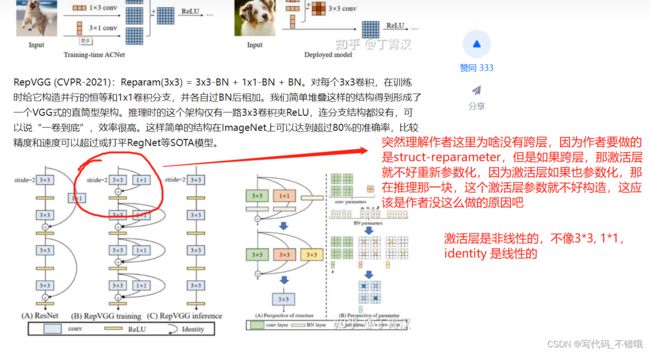
自己对作者没有跨层操作的理解:
自己对参数的理解:

这篇论文的创新点就是训练的时候有分支,然后推理的时候把训练出来的参数进行合并,然后放到3x3纯卷积中,那这一部分代码主要就是 repvgg.py 中:
def repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):
print(model)
if do_copy:
model = copy.deepcopy(model) # 先拷贝模型
for module in model.modules():
if hasattr(module, 'switch_to_deploy'): # 如果有这个方法,那就进入 switch_to_deploy() 进行转换,这个方法就是核心
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model接下来就是:
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias() # 核心就是这个里面是读取 3x3 1x1 identity 里面的权重,然后提取出来给下面的 self.rbr_reparam
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)# 一般bias=False,这里设置了True,因为self.rbr_reparam后面也没有接BathNorm层
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True这里是提取参数:
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense) #提取参数就这里
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1,1,1,1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential): # 提取卷积中的权重和bn层权重
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)# 这是对identity层
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups # 这个网上说根据多GPU更快训练,我个人没看懂有更快
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 这个是把对应的位置赋值为1,这样值为1,周边的为0,就相当于进行卷积没进行任何改变
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt() # 这里和下面一行就是公式,标准流程
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std问题:
1.怎么理解 “ 同时,单路架构非常快,因为并行度高。 ”?
参考:
1.结构重参数化:利用参数转换解耦训练和推理结构 - 知乎 这是原文作者写的
2.RepVGG论文和代码解析|RepVGG-“白嫖”多分支结构的性能, 让VGG性能超越ResNet|CVPR2021_哔哩哔哩_bilibili b站讲解,讲解的还不错
3.深度解读:RepVGG - 知乎 深度解读:RepVGG
4.图解RepVGG - 知乎 图解RepVGG
5.比ResNet更强的RepVGG代码详解_潮生灬的博客-CSDN博客_repvgg代码 讲解RepVGG代码,讲的还可以
6.比ResNet更强的RepVGG代码详解_潮生灬的博客-CSDN博客_repvgg代码 这个人讲的也不错,其里面有github地址,github里面也有讲解,总的来说蛮好的
yolov5 b站讲解,还不知道讲的怎样,没看
Yolo v5代码详解第二讲BN与Pooling_哔哩哔哩_bilibili
Pytorch:model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别 - 知乎 这个讲解model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别 还是不错的,特别是评论
之前对dim或者axis不是很能理解,如sum(1),知道是按照dim=1或者axis=1进行求和,但是求和后的shape有时就想不通,通过如下例子,辅助理解:

上图是一个shape=(1,3,4,5),按照axis=3进行求和,我们这里理解:当按照axis=3进行求和,那剩下的是什么维度,就是(1,3,5),最后一个维度是5,所以列的维度是5列;可以这么记,用哪个维度,那没用的维度就是sum的shape,
再如下也是一样的:

这里是按照axis=0,那结果的维度就是剩下的(3,4,5)
for module in model.modules(): # 这个就是遍历模型,遍历里面每个模块,先从大的整体,然后遍历里面每个细的
if hasattr(module, 'switch_to_deploy'): # 判断模型是否有这个属性,这个属性包括字段、方法
print(module)
RepVGG(
(stage0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(3, 48, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
如上面的,会依次整体打印,然后打印每个子部分,然后再细分下去
(stage0): RepVGGBlock(
(nonlinearity): ReLU()
(se): Identity()
(rbr_dense): Sequential(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(rbr_1x1): Sequential(
(conv): Conv2d(3, 48, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
接着打印:
ReLU()
接着打印:
Identity()
接着打印:
Sequential(
(conv): Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
接着打印:
Conv2d(3, 48, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
接着打印:
BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
注意,在cnn中,如果卷积层之后接Bn层,那么一般设置bias为0,因为bias会在下一层BN归一化时减去均值消掉,徒增计算,这也是为什么我们看到很多时候卷积层设置bias,有时候又不设置。
参考:卷积神经网络卷积层BN层计算原理和卷积BN层融合_MidasKing的博客-CSDN博客_卷积神经网络的bn