论文笔记:Auto-Encoding Scene Graphs for Image Captioning
Auto-Encoding Scene Graphs for Image Captioning
感觉这篇论文老多地方没读懂!
1、提出问题
当我们将一张包括未见过的场景的图片输入到网络中时,我们通常会得到一个关于一些显著对象的简单而琐碎的描述,如:“there is a dog on the floor”,这和目标检测得到的结果差不多。而人类在语句中使用 inductive bias 来构成搭配和语境推理,而传统的编码器-解码器模型做不到。
**language inductive bias:**比如从场景抽象出的 “helmet-on-human” 和 “road dirty” 中,我们可以用 “country road is dirty” 这样的常识性知识说出 “a man with a helmet in contryside” 。
2、创新点
在本文中,我们提出将语言生成的 inductive bias 纳入图像描述的编码器-解码器框架中。 场景图(G)是通过有向边将图像(I)或句子(S)中的 (1) 对象(或实体)(2) 它们的属性和 (3) 它们的关系连接起来的统一表示。 用空间图卷积网络(GCN)将图结构用矢量表示,从而送到编解码器中。
本文提出了 Scene Graph Auto-Encode(SGAE),它是一个 S→G→D→S 的句子自重构网络,其中D是一个用于节点特征重新编码的可训练字典,S→G 模块使用的是一个固定的场景图语言解析器,D→S 是一个可训练的基于 RNN 的语言解码器。 注意,D是我们从训练SGAE中提取的“juice”——language inductive bias。 通过在编码器-解码器的训练管道中共享 D : I→G→D→S ,即可利用语言先验来指导端到端模型。 特别地,I→G 模块是一个视觉场景图检测器,我们在 G→D 模块引入了一个多模态 GCN,以补充由于不完善的视觉检测而丢失的必要的视觉信息。
本文贡献:
-
提出了一种新的 Scene Graph Auto-Encoder (SGAE)用于学习 language inductive bias 的特征表示。
-
提出一种多模态图卷积网络,用于将场景图调制为视觉表示。
-
提出一种基于SGAE的编码器-解码器图像描述器,并具有指导语言解码的共享字典。
3、方法
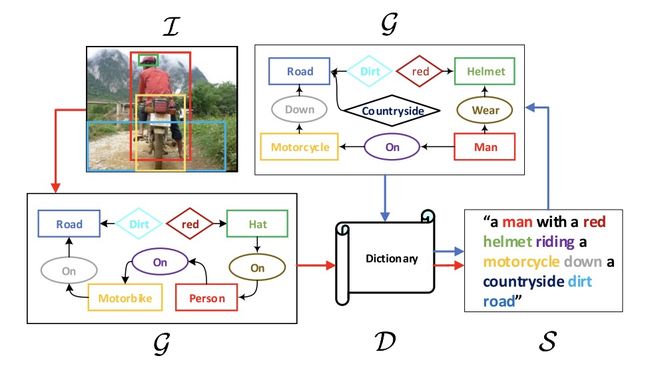
图1:图示为将自动编码的场景图(蓝色箭头)用于的传统的编码器-解码器的图像描述框架中(红色箭头),其中 language inductive bias 被编码在可训练的共享字典中。单词的颜色对应于图像和句子的场景图中的节点。
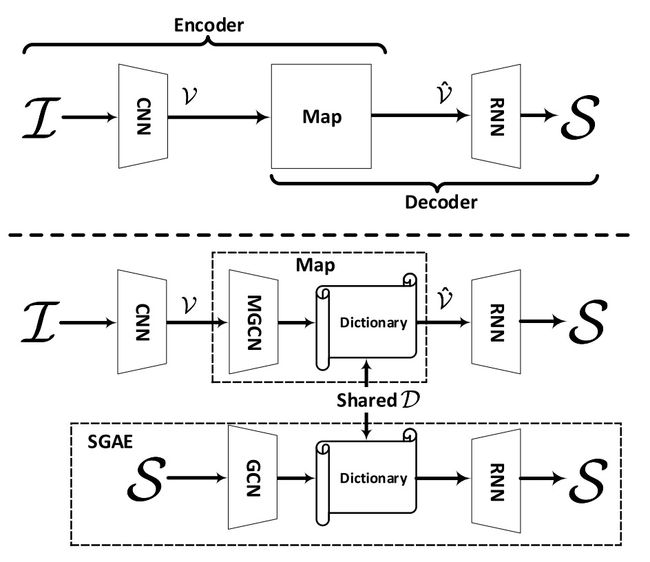
图2:上面:传统的编码器-解码器;下面:我们提出的编码器-解码器,其中新颖的 SGAE 将 language inductive bias 嵌入到共享字典中。
3.1、Encoder-Decoder Revisited
给定图像 I,目标是生成描述图像的自然语言句子 S = {w1,w2, …, wT }。最先进的编码器-解码器的模型可以表示为:

通常,编码器是提取图像特征 V 的卷积神经网络 CNN ;map 一般是注意力机制,它将视觉特征重新编码为信息量更大的 V^,对于语言生成来说是动态的;解码器是基于 RNN 的语言解码器,用来预测 S 序列。
给定 I 一个 ground truth caption S*,我们可以通过最小化交叉熵损失来训练模型:

或最大化基于强化学习 (RL) 的奖励:

其中 r 是采样句子 Ss 和真实值 S* 的句子级度量,例如 CIDEr-D 度量。
这几乎是目前最先进的图像描述基本架构,但是它存在 dataset bias ,为了解决这个问题,我们建议使用 language inductive bias,所提出的框架表述为:

我们只修改了 Map 模块,将场景图 G 引入由共享字典 D 参数化的重新编码器 R。
3.2、Auto-Encoding Scene Graphs
这一节中,我们将介绍如何通过自重构句子 S 来学习字典 D。
重构 S 的过程也是一个编码器-解码器管道。因此,我们可以将 SGAE 表述为:

3.2.1、Scene Graphs
这里我们介绍如何实现步骤 G← S,即从句子到场景图。
场景图是一个元组 G =(N, ξ \xi ξ) ,其中 N 和 ξ \xi ξ 分别是节点和边的集合。 N中共有三种节点:object 节点 o 、attribute 节点 a 和 relationship 节点 r 。我们将 oi 表示为第 i 个对象,rij 表示对象 oi 和 oj 之间的关系,ai,l 表示第 l 个对象 oi 的属性。对于 N 中的每个节点,它由一个 d 维向量表示,即 eo、ea 和 er 。我们把 d 设置为1000。节点特征是可训练的 label embedding 。
ξ \xi ξ 中边的形式有下面几种:
-
如果 object oi 拥有attribute ai,l ,则 ai,l 到 oi 有一条有向边;
-
如果出现一个关系三元组 < oi - rij - oj > ,则从 oi 到 rij 和从 rij 到 oj 有两条有向边。
图中显示了 G 的一个示例,它在 N 中包含 7 个节点,在 ξ \xi ξ 中包含 6 个有向边。
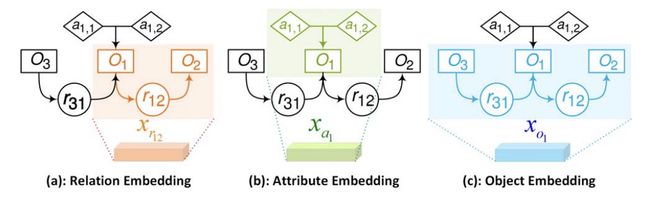
图3:图卷积网络。它是空间卷积,其中彩色部分被“卷积”以作为结果嵌入。
我们使用场景图解析器(前人提出)从句子中提取场景图 G,然后构建句法依赖树(前人提出)应用基于规则的方法(前人提出)将树转换为场景图。
3.2.2、Graph Convolution Network
我们这里介绍步骤 X← G 的实现,即如何将原始节点的 embedding eo、ea 和 er 转换为一组新的上下文的 embedding X。
X 包含三种 d 维 embedding :relationship 节点 rij 的 relationship embedding xrij,object 节点 oi 的 object embedding xoi ,object 节点 oi 的 attribute embedding xai。我们的d 设置为1000。我们使用四个空间图卷积:gr、ga、gs 、go 来生成上述三种 embedding 。这四个函数都具有相同的结构和独立的参数:一个向量连接输入到一个全连接层,然后是一个 ReLU。
Relationship Embedding xrij : 给定 G 中的一个关系三元组
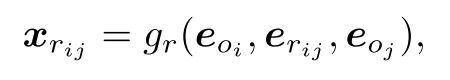
将关系三元组的上下文结合在一起。
**Attribute Embedding xai *给定 G 中的一个对象节点 oi 及其所有属性 ai,1:Nai ,其中 Nai 是对象 oi 具有的属性数,则 oi 的 xai 为:
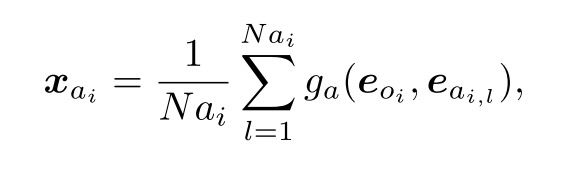
该对象的上下文及其所有属性都包含在其中。
**Attribute Embedding xai *在 G 中,oi 可以充当关系中的“主体”或“客体”。

对于每个节点 oj ∈ \in ∈sbj(oi) ,它充当“客体”,而 oi 充当“主体”。 Nri = |sbj(i)| + |obj(i)|是存在 oi 的关系三元组的数量。
3.2.3、Dictionary
这里我们介绍如何学习字典 D ,然后使用它进行重新编码 X^ ← R(X; D)。
我们的目的是将 language inductive bias 嵌入到语言中。 因此我们提出将词典学习置于句子自重构框架中。
我们把 D 表示为一个 d×K 的矩阵 D={D1,D2,…,DK}。 k被设置为10,000。 给定嵌入向量 x ∈ \in ∈X,重新编码器函数RD可表述为:

其中 α=softmax(DTx) 。
如图所示,这种重新编码在人类常识推理中提供了一些有趣的“想象力”。 例如,从“yellow and dotted banana”,在重新编码后,该特征将更有可能生成“ripe banana”。

3.3、Overall Model: SGAE-based Encoder-Decoder
在本节中,我们将介绍整体的模型:基于 SGAE 的编码器-解码器模型。
3.3.1、Multi-modal Graph Convolution Network
我们提出了一种多模态图卷积网络(MGCN):
在这里,场景图 G 由包含对象检测器、属性分类器和关系分类器的图像场景图解析器提取。我们使用 Faster-RCNN 作为对象检测器,MOTIFS 关系检测器作为关系分类器,并且我们使用我们自己的属性分类器:fcReLU-fc-Softmax 。
句子解析的 G 和图像解析的 G 之间的表示区别在于图像解析的 G 的节点 oi 不仅仅是标签嵌入。
我们使用从 Faster RCNN 预训练的 RoI 特征,然后将检测到的标签嵌入 eoi 与视觉特征 voi 融合成一个新的节点特征 uoi:
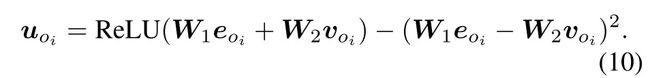
uri,j 和 uai 使用同样的方法生成。其中 W1、W2 是参数。
生成 G 之后,后面的步骤和 GCN 类似,MGCN 也有四个函数 fr、fa、fs 和 fo 的集合。关系、属性和对象嵌入的计算类似于 GCN 。
3.3.2、Training and Inference
我们使用 SGAE 预训练的 D 作为我们整体模型中用于图像描述的 D 的初始化。
我们使用非常小的学习率(例如 10-5)来微调 D 以实现共享目的。
整体训练损失是混合的:我们使用交叉熵损失进行20 个 epoch,然后使用基于 RL 的奖励再进行 40 个 epoch。
对于语言生成中的推理,我们采用束搜索策略,束大小为 5。