四个问题,Yoshua等27位前沿研究者,这是一份NLP领域的请回答2018

大数据文摘出品
作者:魏子敏、蒋宝尚
今年9月份,深度学习Indaba2018峰会在南非斯泰伦博斯举办,包括谷歌大脑Jeff Dean在内的一众研究者都到场进行了分享。一位来自Insight数据分析研究中心的博士生Sebastian Ruder在准备自己的分享期间,就四个问题咨询了包括Yoshua Bengio在内的20+位这个领域的前沿研究者。
昨天,Sebastian Ruder在推特上公开了完整的20余份问答实录,以及他对这些答案相关的分享总结。从中可以一窥自然语言处理这一领域近期的发展。
先来看看这四个引入深省的大问题:
1.你认为目前NLP面临最大的三个问题是什么?
What do you think are the three biggest open problems in NLP at the moment?
2.过去十年,你认为对NLP领域影响最深远的研究是什么?
What would you say is the most influential work in NLP in the last decade, if you had to pick just one?
3.如果有的话,是哪些因素让这个领域走向了错误的方向?
What, if anything, has led the field in the wrong direction?
4. 你有什么建议给NLP领域的硕士研究生?
What advice would you give a postgraduate student in NLP starting their project now?
共有20余位来自自然语言处理业界和学界的前沿研究者受邀回答了这些问题。大数据文摘选取了神经网络之父、“花书”作者Yoshua Bengio和芝加哥大学副教授Kevin Gimpel的回答作为代表进行了编译,完整问答实录可在大数据文摘后台留言“20181212”(今天的日期)获取。
大咖列表如下?
Hal Daumé III,Barbara Plank,Miguel Ballesteros,Anders Søgaard,Manaal Faruqui,Mikel Artetxe,Sebastian Riedel,Isabelle Augenstein,Bernardt Duvenhage,Lea Frermann,Brink van der Merwe,Karen Livescu,Jan Buys,Kevin Gimpel,Christine de Kock,Alta de Waal,Michael Roth,Maletěabisa Molapo,Annie Louise,Chris Dyer,Yoshua Bengio,Felix Hill,Kevin Knight,Richard Socher,George Dahl,Dirk Hovy,Kyunghyun Cho
Yoshua Bengio
1.你认为目前NLP面临最大的三个问题是什么?
基础语言学习,即共同学习世界模型以及如何用自然语言处理中引用模型;
在深度学习框架内融合语言理解和推理;
常识的理解,只有解决了上述两个问题,才能解决常识问题。
2.哪些因素让这个领域走向了错误的方向?
是贪婪。
我们总是在意短期回报,我们总是想办法利用一切我们可支配的数据训练模型,然后希望模型能够智能的理解和生成语言。但是,如果我们不能建立世界模型,不能深层次的理解世界是如何运作的,我们永远不会找到智能语言的秘密,即使我们设计的神经网络模型有多么精巧。因此,我们必须要紧牙关,致力于用NLP解决AI,而不是孤立的理解自然语言处理。
4.你对研究生开始他们的NLP项目有什么建议?
广泛阅读,不要局限于阅读NLP论文。阅读大量机器学习,深度学习,强化学习论文。博士学位是一个人一生中实现追求目标的大好时机,即使是朝着这个目标迈出一小步也是值得珍惜的。
Kevin Gimpel
1.你认为NLP目前最大的三个问题是什么?
最大的问题与自然语言的理解有关,即使在生成任务中,所有的挑战都可以这么理解:计算机不理解文字对人的作用是什么。
设计的模型应该像人类那样阅读和理解文本,通过形成文本世界的表示法,包括对象、设置、目标愿望、信念等要素。当然,还要有人类理解文字背后所需的其他因素。
在设计出理想模型之前,所有的进步都基于提高模型模式匹配的能力。模式匹配对于开发和改善产品是有效的。我不认为仅仅需要模式匹配就能产生一台“理性”机器。
2. 过去十年中,在NLP方面,最有影响力的一部作品是什么?
《自然语言处理几乎从零开始(Natural Language Processing (Almost) from Scratch)》,这一论文由 Ronan Collobert、Jason Weston、Leon Bottou、Michael Karlen、Koray Kavukcuoglu和 Pavel Kuksa等人合力完成,并在2011年发表。简单来说,它以Colobert和Weston在2008年的一篇论文为基础,但对其进行了扩展与发挥。该论文介绍了当前NLP设计常见的几种方法,例如,使用神经网络进行NLP多任务学习、使用未标记数据进行预训练词嵌入等等。
3. 是什么原因导致我们踏进了自然语言处理的“陷阱”
我认为是当前NLP传统的处理方法,例如采用的传统的监督学习,其中有一条假设是,测试数据与训练数据服从相同的概率分布,这与现实实际完全不符合。至少,真实的测试数据与训练数据在时间上的分布是不同的,有时甚至是几十年的差距!所以,我们应该致力于域外学习,时间迁移等。
传统的无监督学习和传统的监督学习都是不现实的,所以很高兴看到NLP研究人员最近关注混合使用,无论给它们起什么名字,半监督也好,弱监督也可,它们都是一种混合的设置。
4. 你对NLP的研究生现在开始他们的项目有什么建议?
不要害怕创新,要勇于尝试新鲜事物。通常来说,风险越大,收益也越大。如果失败了,或者说不符合预期,你也可能在过程中学到许多非常有趣的事情,非常有可能为你发表论文积累材料。
Sebastian Ruder也整理了20余位研究者的回应,并在大会的报告中给出了以下总结。
自然语言处理领域发展的里程碑?

问题一:NLP研究领域最大的问题

总结25位研究者的回答后,我们得出了这四大问题?
1、自然语言理解
2、低资源情景下的NLP
3、大规模或多文件推理
4、数据集,问题及评估

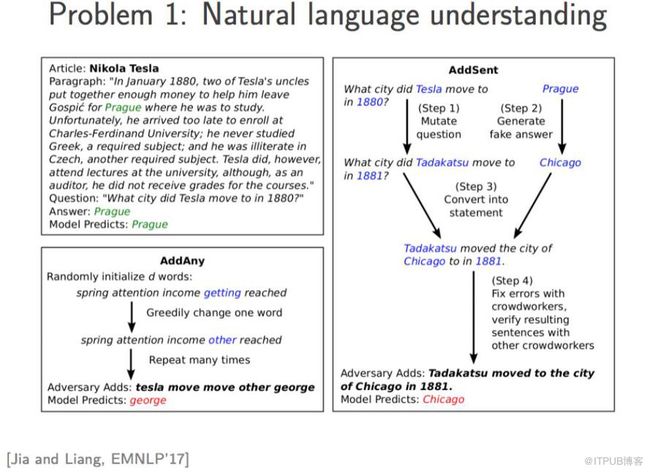







问题二:哪些因素让这个领域走向了错误的方向?

问题三:你有什么建议给NLP领域的硕士研究生?


来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31562039/viewspace-2285049/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31562039/viewspace-2285049/