MobileNetv1、v2网络详解、使用pytorch搭建模型MobileNetv2并基于迁移学习训练
1.MobileNetv1网络详解
传统卷积神经网络专注于移动端或者嵌入式设备中的轻量级CNN网络,相比于传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)
网络的创新点:
(1)Depthwise Coinvolution(大大减少运算量和参数数量)
(2)增加超参数α、β
(1)Depthwise Coinvolution
传统卷积:卷积核channel = 输入特征矩阵channel
输出特征矩阵channel = 卷积核个数
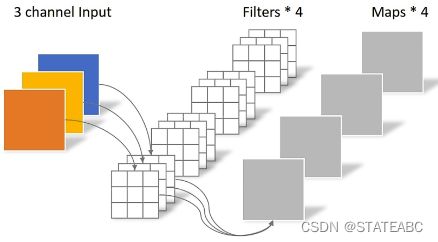
DW卷积(Depthwise Conv): 卷积核channel = 1
输入特征矩阵channel = 卷积核个数 = 输出特征矩阵channel

PW卷积(Pointwise Conv):与普通卷积类似,但是卷积核大小为1

深度可分卷积(Depthwise Separable Conv):将DW卷积和PW卷积一起使用,理论上普通卷积核计算量是DW+PW的8~9倍。
(关于计算量的细节可以看MobileNetv1原论文的3.1和3.2章节)
MobileNetv1网络参数
Conv表示普通卷积,3x3x3x32表示卷积核的高x宽x输入特征矩阵深度x卷积核个数;
Conv dw表示dw卷积,3x3x32表示卷积核的高x宽x输入特征矩阵深度(dw中为1)x卷积核个数。

(2)超参数α、β
α(Width Multiplier):卷积核个数倍率,控制卷积过程中采用卷积核个数

β(Resolution Multiplier):输入图像分辨率参数

在MobileNetv1网络的实际使用中会发现dw卷积的部分卷积核容易废掉(即卷积核参数为0),针对这个问题在MobileNetv2网络有所改善
2.MobileNetv2网络详解
网络的创新点:
(1)Inverted Residuals(倒残差结构)
(2)Linear Bottlenecks
(1)Inverted Residuals(倒残差结构)
ResNet的残差结构:对于输入特征矩阵采用1x1卷积进行压缩,再通过3x3卷积核进行卷积处理,最后再采用1x1卷积核扩充channel
倒残差结构:对于输入特征矩阵采用1x1卷积核将channel变得更深,再通过3x3的卷积核进行dw卷积,最后再采用1x1卷积核进行降维处理

在普通残差结构中采用的是ReLU激活函数,在倒残差结构中采用的是ReLU6激活函数:

倒残差结构图:
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut连接。

(2)Linear Bottlenecks
针对倒残差结构的最后一个1x1卷积层,使用了线性激活函数,而不是ReLU激活函数
在原论文中作者通过实验得出:ReLU激活函数会对低维特征信息造成大量损失,对高维造成损失比较小,而在倒残差结构中的输出是一个低维特征向量,因此使用线性激活函数避免特征信息损失。
MobileNetv2模型参数
t是扩展因子,即倒残差结构第一层1x1卷积核个数的扩展倍率;
c是输出特征矩阵的深度channel;
n是bottleneck的重复次数,对应论文中的到残差结构;
s是步长,代表每一个block所对应的第一层bottleneck的步长,其他的为1。如n=2时,bottleneck的重复2遍,第一层bottleneck的步长为s,第二层bottleneck的步长为1。(一个block由一系列bottleneck组成)

在第一个bottleneck中t=1,即第一层卷积层没有对输入特征矩阵的深度进行调整。在pytorch和tensorflow中没有使用1x1卷积层,因为没有起到作用。
3.使用Pytorch搭建MobileNetv2网络
文件结构:
MobileNetv2
├── model_v2.py: MobileNetv2模型搭建
├── model_v3.py: MobileNetv3模型搭建
├── train.py: 训练脚本
└── predict.py: 图像预测脚本
1.model_v2.py
定义Conv+BN+ReLU6的组合层
class ConvBNReLU(nn.Sequential): #定义Conv+BN+ReLU6的组合层,继承nn.Sequential副类(根据Pytorch官方样例,要使用官方预训练权重)
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1): #初始化函数,在pytorch中dw卷积也是调用的nn.Conv2d类,如果传入groups=1则为普通卷积;如果groups=in_channel则为dw卷积
padding = (kernel_size - 1) // 2 #卷积过程中需要设置的填充参数
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False), #卷积,groups默认为1
nn.BatchNorm2d(out_channel), #BN层
nn.ReLU6(inplace=True) #ReLU6
)
定义倒残差结构
class InvertedResidual(nn.Module): #定义倒残差结构
def __init__(self, in_channel, out_channel, stride, expand_ratio): #expand_ratio为扩展因子t
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio #hidden_channel为第一层卷积核的个数
self.use_shortcut = stride == 1 and in_channel == out_channel #判断在正向传播中是否使用捷径分支
layers = [] #定义层列表
if expand_ratio != 1: #如果扩展因子不等1,就有第一个1x1卷积层,等于1就没有
# 1x1 pointwise conv #在第一个bottleneck中t=1,不对输入特征矩阵深度扩充,不需要1x1卷积层
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers) #通过nn.Sequential()类将layers以未知参数的形式传入,将一系列层结构打包组合
def forward(self, x): #正向传播,输入特征矩阵x
if self.use_shortcut: #判断是否使用捷径分支
return x + self.conv(x) #捷径分支输出+主分支输出
else:
return self.conv(x) #直接使用主分支输出
定义MobileNetv2网络结构
class MobileNetV2(nn.Module): #定义MobileNetV2网络结构
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8): #初始化函数:类别个数、超参数α、
super(MobileNetV2, self).__init__()
block = InvertedResidual #将倒残差结构传给block
input_channel = _make_divisible(32 * alpha, round_nearest) #第一层卷积层所以使用的卷积核个数,_make_divisible()会将输出的通道个数调整为输入的整数倍,可能为了更好的调用硬件设备
last_channel = _make_divisible(1280 * alpha, round_nearest) #last_channel代表模型参数中conv2d 1x1卷积核
inverted_residual_setting = [ #根据模型参数创建list列表
# t, c, n, s #对应7个block
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = [] #定义空列表
# conv1 layer #第一个卷积层
features.append(ConvBNReLU(3, input_channel, stride=2)) #3为输入彩色图,输入特征矩阵卷积核个数,模型参数s=2
# building inverted residual residual blockes #定义一系列block结构
for t, c, n, s in inverted_residual_setting: #遍历inverted_residual_setting参数列表
output_channel = _make_divisible(c * alpha, round_nearest) #将输出channel个数进行调整
for i in range(n): #搭建每个block中的倒残差结构
stride = s if i == 0 else 1 #模型参数中的s对应第一层的步长,判断是否是第一层
features.append(block(input_channel, output_channel, stride, expand_ratio=t)) #在列表中添加一系列倒残差结构
input_channel = output_channel #将output_channel传入input_channel作为下一层的输入特征矩阵的深度
# building last several layers #定义模型参数中bottlenck下的1x1卷积层,1为卷积核的大小
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features) #将以上部分打包成特征提取部分
# building classifier #定义分类器部分
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) #平均池化下采样
self.classifier = nn.Sequential( #将dropout和去全连接层组合
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization #初始化权重流程
for m in self.modules(): #如果子模块是卷积层就会其权重进行初始化
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None: #如果存在偏置就将偏置设置为0
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d): #如果子模块是BN层就将方差设置为1,偏执设置为0
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear): #如果子模块是全连接层,就将其权重初始化
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x): #定义正向传播
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
预训练权重下载
download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
下载完成后将其名称改为mobilenet_v2.pth,存放在当前文件夹
数据集
数据集采用花分类数据集:使用pytorch搭建AlexNet并训练花分类数据集
2.train.py
训练脚本大部分代码同之前vgg、googlenet网络一样,不同之处有:
# create model
net = MobileNetV2(num_classes=5) #实例化模型,定义类别个数为5
model_weight_path = "./mobilenet_v2.pth" #预训练模型路径
assert os.path.exists(model_weight_path), "file {} dose not exist.".format(model_weight_path)
pre_weights = torch.load(model_weight_path, map_location='cpu')
# delete classifier weights #官方是在imageNet数据集上进行预训练,所以其最后一层的节点个数为1000,这里用不了
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()} #载入除了最后一层的预训练模型参数
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights #冻结特征提取部分的所有权重
for param in net.features.parameters():
param.requires_grad = False
记得修改自己的数据集路径:
data_root = os.path.abspath(os.path.join(os.getcwd(), "./dataset")) # get data root path
image_path = os.path.join(data_root,"flower_data") # flower data set path
训练结果

3.prrdict.py
与之前相同。
导师博客:https://blog.csdn.net/qq_37541097/article/details/103482003
导师github:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
代码用的导师的,自己又加了些备注,就放在自己的github里了:
https://github.com/Petrichor223/Deep_Learning/tree/master