《数字电路实验》之FPGA板强化学习实验
中国科学技术大学计算机学院《数字电路实验》之FPGA板强化学习实验
写在前面
最近翻出来19年做数字电路实验的时在FPGA上面运行强化学习算法的实验报告,整个工程花费了大约两周的正常工作量,原始的markdown文档打包后再拿出来查阅比较麻烦,放在博客上。这个工作包含了实验环境的搭建和Qlearning算法的构建,以及一些杂七杂八的可以当时可以给实验加分的插件(如用PWM播放音乐,VGA可视化实验环境)。现在看两年以前的代码,有很多冗余的部分而且结构非常的不清晰;在处理FPGA板上随机数生成的部分也有瑕疵,整个随机数的序列长度有时候不够跑完一次实验。
目录:
实验概况
强化学习简介以及项目实现目标
外接与相关显示实现介绍
- 平台与外设
- 代码框架以及输入输出介绍
- 实验所用频率介绍
- 八段数码管显示介绍
- 音频输出介绍
- 视频输出介绍
相关数值处理
- 伪随机数
- 比较有符号数大小
算法更新部分
- 选择动作
- 更新Q值
- 更新环境
实验结果分析与展示
对比试验以及相似工作
总结与展望
一、实验概况
实验目的:
- 熟悉了解VGA显示的原理方法,同时进行实践
- 学会使用PWM(Pulse-Width Modulation)进行音频输出
- 熟练掌握八段数码管显示数字
- 在FPGA板上尝试实现最基础的Value-Based的强化学习算法QLearning,并能够在创建的环境中学习到最优策略。
实验环境:
- PC一台
- Windows操作系统
- FPGA实验平台
二、强化学习简介以及项目实现目标
1.强化学习简介
强化学习(Reinforcement learing)是一类算法, 是让计算机实现从一开始什么都不懂, 通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法. 这就是一个完整的强化学习过程. 实际中的强化学习例子有很多. 比如近期最有名的 Alpha go, 机器头一次在围棋场上战胜人类高手, 让计算机自己学着玩经典游戏 Atari, 这些都是让计算机在不断的尝试中更新自己的行为准则, 从而一步步学会如何下好围棋, 如何操控游戏得到高分.
若要了解更多,可以访问 什么是强化学习
2.项目介绍
本项目将在FPGA上通过最近基础的基于Value的RL算法Qlearning,最终agent(环境中的蓝色小方块)能够在对整个环境一无所知的初始状态下,能够通过不断探索环境最终到达黄色空心菱形位置,同时避开红色的方块。
下面是Qlearning算法的伪代码:
其中Q(s,a)为处在state s选取动作a的预期回报,S为state集合,A(s)为处于state s 时的动作集合;R为每一个state的回报reward,α为学习效率,γ为衰减系数decay。
可以看出,整个算法最重要的更新公式是倒数第三行的更新Q值,更新步长为学习效率α×(实际回报×衰减系数-理想回报)
在项目中,超参数值如下:
//学习效率和衰减系数以及epsilon
reg [3:0] learning_rate = 1;
reg [3:0] decay = 8; //8/10
reg [7:0] epsilon=216; //epsilon-greedy选择中的epsilon
//以及到达goal获得reward100000
- 因为FPGA中涉及到小数运算过于复杂,因此将reward设置成100000
- 通常情况下learing_rate为0.01,在处理一些更为复杂的问题时(比如连续动作空间中机械手打字)learing rate通常更低,在0.0001附近,但怕迭代次数过多reward被迭代没了,将learning rate设定成1
- decay为0.8,通常情况下,当decay越大,agent越"远视",能预判更多未来的步骤,decay越小,agent越"近视”。
- 整个算法选择action符合epsilon-greedy,为了让agent能够更广泛的探索环境而不会掉入局部最优。因为产生伪随机数为0-255,将epsilon设置为216,比例接近0.9
- 本项目中环境只含有16个state,每一个state都有4个action供agent选择(实际上更新迭代过程的代码占了整个top模块绝大部分,将近900行)
构建QTable以及初始化每一个state的reward:
//每一个state向左走的Q
Q_left[0]<=-100; Q_left[1]<=0; Q_left[2]<=0; Q_left[3]<=0;
Q_left[4]<=-100; Q_left[5]<=0; Q_left[6]<=0; Q_left[7]<=0;
Q_left[8]<=-100; Q_left[9]<=0; Q_left[10]<=0; Q_left[11]<=0;
Q_left[12]<=-100; Q_left[13]<=0; Q_left[14]<=0; Q_left[15]<=0;
//每一个state向上走的Q
Q_up[0]<=-100; Q_up[1]<=-100; Q_up[2]<=-100; Q_up[3]<=-100;
Q_up[4]<=0; Q_up[5]<=0; Q_up[6]<=0; Q_up[7]<=0;
Q_up[8]<=0; Q_up[9]<=0; Q_up[10]<=0; Q_up[11]<=0;
Q_up[12]<=0; Q_up[13]<=0; Q_up[14]<=0; Q_up[15]<=0;
//每一个state向右走dQ
Q_right[0]<=0; Q_right[1]<=0; Q_right[2]<=0; Q_right[3]<=-100;
Q_right[4]<=0; Q_right[5]<=0; Q_right[6]<=0; Q_right[7]<=-100;
Q_right[8]<=0; Q_right[9]<=0; Q_right[10]<=0; Q_right[11]<=-100;
Q_right[12]<=0; Q_right[13]<=0; Q_right[14]<=0; Q_right[15]<=-100;
//每一个state向下走的Q
Q_down[0]<=0; Q_down[1]<=0; Q_down[2]<=0; Q_down[3]<=0;
Q_down[4]<=0; Q_down[5]<=0; Q_down[6]<=0; Q_down[7]<=0;
Q_down[8]<=0; Q_down[9]<=0; Q_down[10]<=0; Q_down[11]<=0;
Q_down[12]<=-100; Q_down[13]<=-100; Q_down[14]<=-100; Q_down[15]<=-100;
//每一个state的reward
R[0]<=0; R[1]<=0; R[2]<=0; R[3]<=0;
R[4]<=0; R[5]<=0; R[6]<=-100; R[7]<=0;
R[8]<=0; R[9]<=-100; R[10]<=100000; R[11]<=0;
R[12]<=0; R[13]<=0; R[14]<=0; R[15]<=0;
三、外接与相关显示实现介绍
1.平台与外设
- 本实验设计基于一块Nexys4 DDR Artix-7 FPGA开发板(Xilinx产品编号XC7A100T-1CSG324C)。Artix-7 FPGA可以实现高性能逻辑优化,凭借其大容量的FPGA和USB、以太网和其他端口的集合,Nexys A7可以承载从入门的组合电路到强大的嵌入式处理器的设计。一些内置的外围设备,包括加速度计、温度传感器、数字麦克风、扬声器放大器和大量I/O设备,使Nexys4 DDR Artix-7 FPGA可以用于广泛的设计,而可以通过添加组件实现更加复杂的设计。
相关参数如下:
| Product Variant | Logic Slices | Block RAM | Clock Tiles | DSP Slices | Internal Clock | DDR2 Memory |
|---|---|---|---|---|---|---|
| XC7A100T-1CSG324C | 15,850 (4 6-input LUTs & 8 flip flops each) | 4,860 Kbits | 6 (each with PLL) | 240 | 450 MHz+ | 128MB |

- 整个工程基于Verilog语言编写,使用Vivado2019.1.3版本进行编写仿真以及生成比特流。
- 本实验用到一块外接最大具有800X480的VGA显示屏(型号为Wareshare 5inch HDMI LCD(G))用于图像展示输出。
- 本实验用到FPGA板自带的PWM接口进行音频输出,可以接耳机或扬声器进行音频输出。
- 本实验用到八段数码管显示强化学习算法运行的相关参数,可以显示算法当前运行状态。
2.代码框架以及输入输出介绍:
整个项目由一个主模块"top“控制,里面调用了三个模块,分别用于产生音频信号、生成数码管显示以及产生VGA信号,其中用于产生音频信号的模块调用了用于分频的IP核clk_wiz_0。
主模块下的输入输出如下:
module top(
input clk, //100MHz的板载频率
input rst, //开始/重新开始训练agent
//music部分
input button_music, //是否输出音频
output audio,
// hvsync_generator部分
output VGA_HS,
output VGA_VS,
//Nixie_tube_display
output wire [7:0]id, //数码管地址
output wire [7:0]seg, //数码显现
//RGB输出
output [3:0]VGA_R,
output [3:0]VGA_G,
output [3:0]VGA_B
);
3.实验所用频率介绍:
本实验中FPGA板载频率为100MHz,因为不同的输出需求,要运用到多个不同频率。
分频方法
-
12MHz:通过分频IP核clk_wiz_0产生
-
其他频率:通过计数将100MHz分频
#####主要频率用途。 -
100MHz(clk): 板载频率,是所用的最高频率,同时为其他分频的基础,同时用于判断有符号数大小、强化学习算法中选择action、计算MaxQ、输出RGB信号的时序逻辑部分
-
25MHz(clk_25MHz):产生VGA信号模块使用的频率,同时用于生成伪随机数的时序逻辑部分
-
12MHz(clk_12MHz):通过PWM输出音频信号使用的频率
-
8Hz(clk_8Hz):音频输出模块中遍历乐谱的频率(相当于一个节拍器)
-
10Hz(clk_100ms)(用于产生5Hz(clk_200ms)、2.5Hz(clk_400ms)的频率,同时也为更新强化学习环境以及QTable的备选频率(生成仿真波形时被屏蔽)
-
100Hz(clk_10mz):用于生成bit stream写进FPGA板中更新强化学习当前环境以及更新QTable的时序逻辑
-
10Hz、5Hz、2.5Hz、100Hz的万分之一(clk_100mz):用于仿真测试时代替写入板中的10Hz\5Hz\2.5Hz,生成bit stream时被屏蔽。
-
其他频率:产生主要频率的工具。
4.八段数码管显示介绍:
采用板载八段数码管显示输出,可以看到,在主模块中,在模块“Nixie_tube_display”中实现相关操作。
数码管显示从左到右依次是:成功次数、运行总episode数量以及当前agent所在的state。
下面是该模块输入输出以及定义的临时变量
module state_display(
input clk,
input [3:0] state, //agent当前所处的state
input [9:0] episode, //运行总次数
input [6:0] success, //成功次数
input [1:0] action, //当前选择动作,调试时显示,最终没有显示
output wire [7:0]id_out, //数码管地址
output wire [7:0]seg //数码显现
);
reg [7:0]seg_;
reg [31:0] cnt,cnt2; //计数
reg [3:0] in; //用于输入寄存器
wire pulse_1000hz; //分频千分之一
wire pulse_200hz; //分频两百分之一
reg [3:0] episode_1,episode_2,episode_3,success_1,success_2;
//success的个,十位,success为成功回合数
//episode的个,十,百,位,episode为总训练回合
reg [7:0]id_in;
通过以下代码可以将success与episode转换成十进制显示输出,用到两百分之一分频:
always@(posedge clk) //转换success和episode到10进制
if(pulse_200hz)
begin
episode_3<=episode/100;
episode_2<=episode/10-episode_3*10;
episode_1<=episode-episode_2*10-episode_3*100;
success_2<=success/10;
success_1<=success-success_2*10;
end
为了显示出每一段数码管上的数字,用到了千分之一分频,输出数码管的id循环转换:
always@(posedge clk) //数码管显示部分
begin
if(pulse_1000hz)
begin
if(id_in== 8'b1111_1110) begin id_in<=8'b1111_1011; in<=episode_1; end
else if(id_in==8'b1111_1011) begin id_in<=8'b1111_0111; in<=episode_2; end
else if(id_in==8'b1111_0111) begin id_in<=8'b1110_1111; in<=episode_3; end
else if(id_in==8'b1110_1111) begin id_in<=8'b1011_1111; in<=success_1; end
else if(id_in==8'b1011_1111) begin id_in<=8'b0111_1111; in<=success_2; end
else begin id_in<=8'b1111_1110; in<=state; end
end
end
最后偷懒有没有寄存器IP核,通过if else语句实现单个数码管显示:
always@(posedge clk)
begin
if(in==0) seg_<=8'b11000000;
else if(in=='d1) seg_<=8'b11111001;
else if(in=='d2) seg_<=8'b10100100;
else if(in=='d3) seg_<=8'b10110000;
else if(in=='d4) seg_<=8'b10011001;
else if(in=='d5) seg_<=8'b10010010;
else if(in=='d6) seg_<=8'b10000010;
else if(in=='d7) seg_<=8'b11111000;
else if(in=='d8) seg_<=8'b10000000;
else if(in=='d9) seg_<=8'b10010000;
else if(in=='d10) seg_<=8'b10001000;
else if(in=='d11) seg_<=8'b10000011;
else if(in=='d12) seg_<=8'b11000110;
else if(in=='d13) seg_<=8'b10100001;
else if(in=='d14) seg_<=8'b10000110;
else seg_<=8'b10001110;
end
5.音频输出介绍:
- 采用PWM(Pulse-Width Modulatino)进行音频输出
- 输出曲目为”小小葫芦娃“
- 选择这个本来是想做一个”葫芦娃救爷爷“的游戏,通过强化学习算法训练"葫芦娃“(agent)去”救爷爷“(agent 到达 target goal),但是最后发现没有多少时间去完成了,但是改曲目又过于繁杂。
- PWM(脉冲宽度调制)的原理图如下:
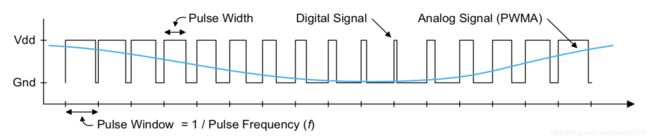
PWM信号以占空比决定输出信号高低,只要做合适的处理,可以通过控制输出音频高低的变化播放音乐。
下面是该模块输入输出以及定义的临时变量
module music(audio,button,music_clk);
input button,music_clk;
output audio; //输出蜂鸣器开关
reg [23:0] counter8Hz; //计算是否到8HZ
reg [16:0] count ; //用于控制蜂鸣器
reg clk_8Hz; //手动分频后4Hz的clk
wire clk_12MHz; //用IP核分频的12MHz 的clk
reg audiof; //控制audio开关
reg [4:0]j; //低,中,高的1 2 3 4 5 6 7
reg [16:0]quti; //每个音所对应的频率
reg [9:0] len; //乐谱长度
clk_wiz_0 clk12MHz(.clk_in1(music_clk),.clk_out1(clk_12MHz)); //获得12MHz的clk
下面为如何将低、中、高的1234567转换成频率,值得注意的是这是在节拍为8Hz的情况下所转换的频率,如果播放音乐所用的频率不同,每个音对应的频率也将不同。
always @(posedge clk_8Hz) //将1-7转换为频率
begin
case(j)
'd0:quti<='d0;
'd1:quti<='d22932;//低音
'd2:quti<='d20436;
'd3:quti<='d18024;
'd4:quti<='d17184;
'd5:quti<='d15312;
'd6:quti<='d13632;
'd7:quti<='d12144;
'd8:quti<='d11424;//中音
'd9:quti<='d10212;
'd10:quti<='d9096;
'd11:quti<='d8592;
'd12:quti<='d7656;
'd13:quti<='d6818;
'd14:quti<='d6072;
'd15:quti<='d5736;//高音
'd16:quti<='d5112;
'd17:quti<='d4548;
'd18:quti<='d4296;
'd19:quti<='d3828;
'd20:quti<='d3408;
'd21:quti<='d3036;
default:quti<='d0;
endcase
end
下面这段代码实现了如何发声
always @(posedge clk_12MHz) //audio模块,输出一定频率(quti)的声音
begin
if(count==quti) //quti为每一个音符频率
begin
count<=0;
audiof<=~audiof;
end
else
begin
count<=count+1;
end
end
下面这张图为乐曲的简谱,后面的代码展示了乐曲的前四个小结
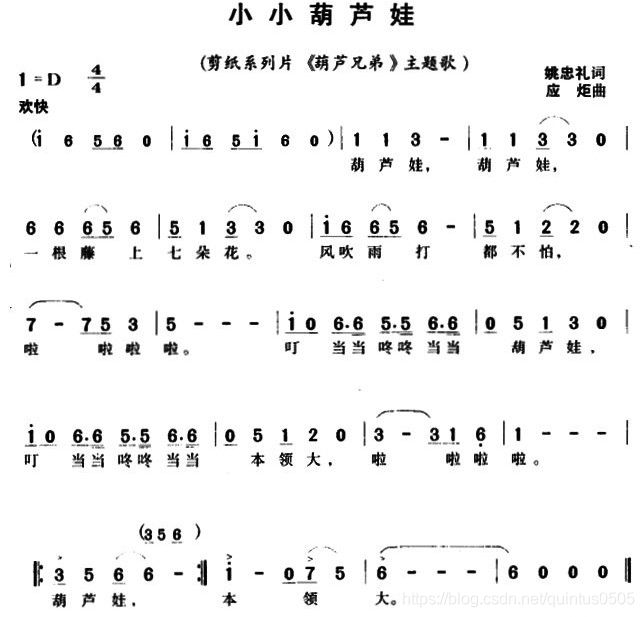
整个曲谱长度为340,这里只展示前67
always @(posedge clk_8Hz) //播放音乐
//if(clk_4Hz==1)
begin
if(button==0) //每次重新播放
len<=0;
else
begin
if(len==340) //整首歌曲长度
len<=0; //循环播放
else
len=len+1;
case(len) //以四分音符为一拍,每小节四拍
0:j=0;1:j=0;2:j=0;3:j=0;
4:j=15;5:j=15;6:j=15;7:j=15;
8:j=13;9:j=13;10:j=13;11:j=15;
12:j=12;13:j=12;14:j=13;15:j=13;
16:j=0;17:j=0;18:j=0;19:j=0;
20:j=15;21:j=15;22:j=13;23:j=13;
24:j=12;25:j=12;26:j=15;27:j=15;
28:j=13;29:j=13;30:j=13;31:j=13;
32:j=0;33:j=0;34:j=0;35:j=0;
36:j=8;37:j=8;38:j=8;39:j=0;
40:j=8;41:j=8;42:j=8;43:j=0;
44:j=10;45:j=10;46:j=10;47:j=10;
48:j=10;49:j=10;50:j=10;51:j=0;
52:j=8;53:j=0;54:j=8;55:j=8;
56:j=8;57:j=0;58:j=10;59:j=10;
60:j=10;61:j=10;62:j=10;63:j=10;
64:j=0;65:j=0;66:j=0;67:j=0;
6.视频输出介绍:
6.1VGA原理简述
-
视频输出采用VGA输出,输出分辨率选择640×480,输入时钟频率25MHz

-
上图展示了VGA的行时序以及场时序。
- a同步脉冲(Sync),b显示后沿(Back porch),c显示时序段(Display interval),d显示前沿(Front porc)。这四段组成了一个完整的时序。图中最后的同步脉冲a是下一个时序的。所以我们的消隐间隔就是上一个时序的显示前沿+本时序的同步脉冲+本时序的显示后沿。同步脉冲是包含在消音间隔中的。而显示时序段,就是我们上面提到的,用来传输像素点的时钟周期。
-
两者合二为一能更好展现出其工作方式:

-
本设计中VGA输出采用以下扫描参数:
| * | Vertical | Horizontal |
|---|---|---|
| Front Porch | 10 | 16 |
| Sync | 10 | 96 |
| Display | 640 | 480 |
| Back Porch | 33 | 48 |
6.2hvsync_generator模块介绍
下面为项目中生成VGA信号的hvsync_generator模块输入输出部分:
module hvsync_generator(
input pixel_clk, //输入时钟25MHz
input [11:0]h_fporch,
input [11:0]h_sync,
input [11:0]h_bporch,
input [11:0]v_fporch,
input [11:0]v_sync,
input [11:0]v_bporch,
output vga_hs, //输出行同步信号
output vga_vs, //输出场同步信号
output vga_blank, //输出inDisplayArea,用于RGB显示部分
output reg[11:0]CounterY, //输出屏幕上遇到的纵坐标
output reg[11:0]CounterX //输出屏幕上遇到的横坐标
);
下面仅展示一段非常重要的代码,在扫描到达了参数中Display范围时才会显示。对于VS信号有一段类似的代码,h_counter随时钟刷新。
always @(posedge pixel_clk)begin
if (h_counter < (h_total-1) ) h_counter <= h_counter+1;
else h_counter <= 0;
到达Display范围显示:
always @(posedge pixel_clk)begin
case(h_counter)
0:{VGA_BLANK_HS_o,VGA_HS_o}=2'b01;
h_fporch:{VGA_BLANK_HS_o,VGA_HS_o}=2'b00;
h_fporch+h_sync:{VGA_BLANK_HS_o,VGA_HS_o}=2'b01;
h_fporch+h_sync+h_bporch:{VGA_BLANK_HS_o,VGA_HS_o}=2'b11;
endcase
end
注:整个项目除此模块(hvsync_generator)代码来自17级某学长供学习参考外,其他部分完全由自己书写调试。
6.3视频输出部分:
在top模块中通过判断CounterX和CounterY的数值决定是否输出,下面以生成环境边界为例:
- 判断是否到达环境边界
wire border = ((CounterX[9:3]==10)||(CounterX[9:3]==24)||(CounterX[9:3]==39)||(CounterX[9:3]==54)||
(CounterX[9:3]==69)||(CounterY[8:3]==0)||(CounterY[8:3]==14)||(CounterY[8:3]==29)||(CounterY[8:3]==44)||
(CounterY[8:3]==59)) &&(CounterX[9:3]>=10)&&(CounterX[9:3]<=69);
- 通过再将border的信号传输给wire型R、G、B,通过VGA_R、VGA_G、VGA_B输出,
assign Red = border;
assign Green = border;
assign Blue = border;
assign VGA_R = {4{Red}} & {4{inDisplayArea}};
assign VGA_G = {4{Green}} & {4{inDisplayArea}};
assign VGA_B = {4{Blue}} & {4{inDisplayArea}};
环境中其他组成部分通过同样的方式输出。
四、相关数值处理
因为FPGA板中运行算法不同于PC机上运行,一些数据得到和运算需要自己写时序逻辑实现
伪随机数
在选择actions时,每一个action的选择需要一定的概率,可以通过判断一定范围内随机大小来实现。数在Vivado中虽然支持通过$random函数生成随机数,但是在FPGA板中,该函数无效。可以通过有限状态机中不同状态转换生成伪代码:
//生成随机数部分
reg [9:0]rand_num; //随机数
reg [9:0]rand; //用于选择动作
initial rand_num=8'b1111_1111;
//random_num get_rand(.clk(clk_50MHz),.rst(rst),.seed(rand_num),.rand_num(rand));
always@(posedge clk_20ms) //产生伪随机数
begin
rand_num[0] <= rand_num[7];
rand_num[1] <= rand_num[0];
rand_num[2] <= rand_num[1];
rand_num[3] <= rand_num[2];
rand_num[4] <= rand_num[3]^rand_num[7];
rand_num[5] <= rand_num[4]^rand_num[7];
rand_num[6] <= rand_num[5]^rand_num[7];
rand_num[7] <= rand_num[6];
end
always@(posedge clk_50MHz)
begin
rand<=rand_num; //产生0到256的随机数
end
比较有符号数大小
在选择action时,需要比较当前state四个action估计回报大小,有些回报为负数。在FPGA板中不支持有符号数的比较,可以通过以下时序逻辑实现:
//比较四个方向Q的大小(有符号数无法)
reg [2:0] comp01;
reg [2:0] comp02;
reg [2:0] comp03;
reg [2:0] comp12;
reg [2:0] comp13;
reg [2:0] comp23;
//以下是比较四个方向Q的逻辑。如comp01表示方向0和方向1,comp01==1,方向0的Q小,comp01==2,两个Q相同,comp01==3,方向0的Q更大。
always@(posedge clk)
begin
if(Q_left[state][31]==0&&Q_up[state][31]==0)
begin
if(Q_left[state][30:0]一共由六个比较,其他比较实现方法一模一样。
五、算法更新部分
Qlearning:

以下为环境的16个state分布
| a | b | c | d |
|---|---|---|---|
| e | f | g | h |
| i | j | k | l |
| m | n | o | p |

下面将对伪代码逐行说明如何实现:
选择动作
根据epsilon-greedy选择,四个action优劣排序一共有十二种情况,一共分四类:
- 四个action一样回报
if(Q_left[state]==Q_up[state]&&Q_left[state]==Q_right[state]&&Q_left[state]==Q_down[state])
//如果每个action回报相同,随机选择action
begin
show<=0;
if(rand<'d64) action<=0;
else if(rand<'d128) action<=1;
else if(rand<'d192) action<=2;
else //(rand<100)
action<=3;
end
- 四个action中三个回报一样大,一个最小
if(Q_left[state]==Q_up[state]&&Q_left[state]==Q_right[state]&&comp03==3) //只有下最小,其他都一样
begin
show<=1;
if(rand<'d77) action<=0;
else if(rand<'d154&&rand>='d77) action<=1;
else if(rand<'d231&&rand>='d154) action<=2;
else if(rand<'d256&&rand>='d231)action<=3;
end
- 两个action回报一样,且都大于剩下两个action的回报
if(Q_left[state]==Q_up[state]&&comp02==3&&comp03==3) //左和上最大
begin
show<=5;
if(rand<'d115) action<=0;
else if(rand<'d230) action<=1;
else if(rand<'d243) action<=2;
else action<=3;
end
- 存在唯一最大回报action
if(rand更新Q值
一共有十六中情况,只展示其中的一种,即上一个state为"f"时
*state f*
else if(pre_state==f)
begin
//更新Qtable
if(state==e)//左
begin
Q_left[pre_state]<=Q_left[pre_state]+learning_rate*(R[state]+decay
*maxQ/10-Q_left[pre_state]);
end
if(state==b)//上
begin
Q_up[pre_state]<=Q_up[pre_state]+learning_rate*(R[state]+decay
*maxQ/10-Q_up[pre_state]);
end
if(state==g)//右
begin
Q_right[pre_state]<=Q_right[pre_state]+learning_rate*(R[state]+decay
*maxQ/10-Q_right[pre_state]);
end
if(state==j)//下
begin
Q_down[pre_state]<=Q_down[pre_state]+learning_rate*(R[state]+decay
*maxQ/10-Q_down[pre_state]);
end
end
更新环境
- 如果依照aciton遇到到墙,则视为没有移动:
if(state==a)
begin
pre_state<=a;
case(action)
left:begin state<=a; end
up:begin state<=a; end
right:begin state<=b; end
down:begin state<=e; end
endcase
end
- 没有墙,自由运动
else if(state==f)
begin
pre_state<=f;
case(action)
left:begin state<=e; end
up:begin state<=b; end
right:begin state<=g; end
down:begin state<=j; end
endcase
end
- 遇到陷阱,返回出发点,episode总数加一
else if(state==g)
//掉入地狱
begin
state<=a;
pre_state<=g;
episode<=episode+1;
end
- 走到设定目标,返回出发点,episode总数和成功数success加一
else if(state==k)
begin
//成功
pre_state<=k;
state<=a;
episode<=episode+1;
success<=success+1;
end
六、实验结果分析与展示
下面通过几张仿真波形图来说明情况
-
在第一个episode中,agent在环境中不断探索,最终从state f 走到state j,同时Qtable得到有效的更新
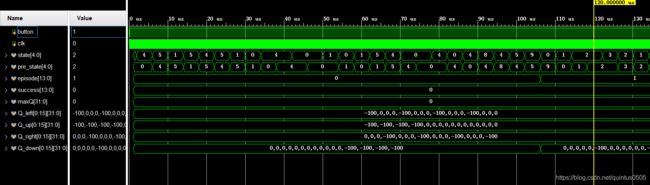
-
整体上,一个episode中agent经过的state总数越来越多,说明agent已经学习到环境的一些信息

-
在第五个episode末agent第一次走到设定目标

-
可以看到,随后每一个episode中agent经过的state越来越少,同时,maxQ(当前state最大预估回报)为0的概率越来越小

-
到了后期,agent已经可以轻车熟路的找到设定位置同时避开陷阱,但是由于是epsilon-greedy,仍有少数掉进陷阱的现象,同时每一步maxQ都不为0,而且QTable趋于稳定。

实物展示:

注:拍摄照片时一些超参数还没有调整到最合适的数值,所以学习的情况惨不忍睹(这是比较正常的)
七、对比试验以及相似工作
FPGA上与PC机上运行Qlearning效果对比
FPGA的速度优势(此次使用了莫凡python的代码)
FPGA相比于PC机运行Qlearning速度上有巨大优势。仿真时,运行完成200个episode只用时大约6ms
linux系统下用python运行Qlearning跑同样的环境,超参数设置如下:
learning rate = 1;
decay = 0.9;
epsilon = 0.8;
reward = 0/1/-1;
200个episode 用时为:
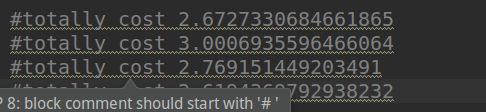
运行时间都在2.5s以上。
可见FPGA在速度上比PC机有巨大优势。
相关工作
在做完实验后浏览相关工作意外发现18年IEEE收录了一篇同样是Qlearning在FPGA实现的文章(Parallel Implementation of Reinforcement Learning Q-Learning Technique for FPGA)(找到矿了),这里稍微介绍一下:
摘要
- 这篇文章提出了一个可以在FPGA上运行的Qlearning算法(parallel fixed-point Q-learning algorithm architecture implemented)的框架。
- 展示了收敛状态
- 分析了不同state、不同的actions sizes scenarios、不同fixed-point formats的运行时间以及occupied area。
- 文章关注Qlearning最终学出来的效果以及可能发生的Qtable值衰减到0(FPGA不支持小数,lab10我把R设定的特别大就是为了避免这个)
- 文章在硬件部分做了大量的分析,如分析了Occupied area in multipliers以及Occupied area in register、Occupied area in LUTs、在不同的state和action的迭代次数以及相关操作的耗能等。这里感觉缺乏相关知识不是很了解
- Xilinx平台,Virtex-6 xc6vcx240t-1ff1156 as the target FPGA
环境

- agent需要通过自己探索走到S6,可以获得R=100
- 如果碰到边界(红色箭头)立即获得R=-500
- 其他情况状态转移R=0
Qlearning在FPGA中实现架构
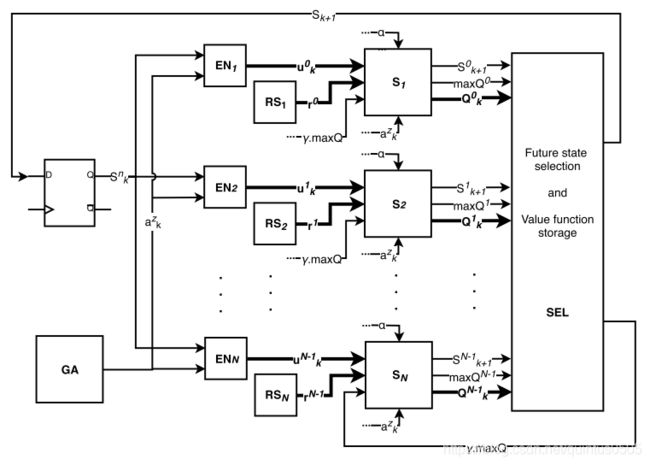
- GA为伪随机数生成器,用于选择action
- EN决定更新哪一个state-action pair
- RS存储每一个state的reward
- S存储每一个state,结合输入action产生下一个state
- SEL更新QTable相关操作
八、总结与展望
FPGA的不足
FPGA运行相关算法还有诸多问题。首先是FPGA板缺乏很多功能,需要自己实现,同时FPGA板实现for循环等要耗费巨大的空间资源。最重要的是,FPGA板很难更加高级的强化学习算法,试想如果state不止16个,而类似于高维空间的向量(如一些机械手有十多个自由度,这些自由度的数值构成了高维空间中的state)。虽然Qlearning的”进阶版“同样是基于值的DQN可能可以处理这种问题,但是需要构造两个基础的fully connected神经网络。这种情况一般下要用到基于概率的PPO或者DDPG,但是同样要构造神经网络。像Alpha go中还调用的更为复杂的卷积神经网络(虽然有人在做FPGA加速CNN),FPGA若要实现这些强化学习算法还有相当长的路。
本次实验的不足
- 本次实验的随机数只设置了256位,意味着每跑两百多次伪随机数就会重新回到初始状态,不适合长时间跑(事实上仿真时间长后,由于Qtable已经稳定,很容易发现agent在一大段时间内动作和转移状态与稍早时候一模一样),目前还没有很好的生成较大位数伪随机数的方法
- 因为时间和能力限制,本实验测试强化学习environment只设计了一个且非常简单,通常情况下只需要10到20个episode就可以训练的很好,FPGA相对于PC机的优势没有体现出来。
展望
- 如果verilog支持的库稍微丰富一些,FPGA在运行速度上的巨大优势可以碾压PC机,同时FPGA的时序逻辑可以轻松实现并行,同样可以加速一些强化学习算法