deeplabv3p 阅读笔记
摘要
Spatial pyramid pooling module or encode-decoder structure
are used in deep neural networks for semantic segmentation task. The
former networks are able to encode multi-scale contextual information by
probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information
语义分割任务通常会用到空间金字塔模块和编解码模块。前者有利于提取多尺度上下文信息,后者更容易捕获边缘信息。
In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network
本文结合了这两种方法的优势,deeplabv3+通过增加了简单并且高效的编码模块来改进分割结果。我们进一步发现了Xception,并且将深度可分离卷积作用到金字塔模块和编码模块来获得更快更强的网络。
引言
In summary, our contributions are:
– We propose a novel encoder-decoder structure which employs DeepLabv3 as a powerful encoder module and a simple yet effective decoder module.
– In our structure, one can arbitrarily control the resolution of extracted encoder features by atrous convolution to trade-off precision and runtime, which is not possible with existing encoder-decoder models.
– We adapt the Xception model for the segmentation task and apply depthwise separable convolution to both ASPP module and decoder module, resulting in a faster and stronger encoder-decoder network.
– Our proposed model attains a new state-of-art performance on PASCAL VOC 2012 and Cityscapes datasets. We also provide detailed analysis of design choices and model variants.
– We make our Tensorflow-based implementation of the proposed model publicly available at https://github.com/tensorflow/models/tree/master/
research/deeplab.
我们的贡献主要有:
1)提出了一种新的编解码结构
2)通过atrous 卷积来控制分辨率,从而权衡精度和时间
3)采用Xception模型来处理分割任务并且在ASPP 模块和编码模块加入深度可分离卷积,从而获得更快更强的网络
4)在PASCAL VOC 2012 上获得了最佳效果
5)开源了Tensorflow版本的实现
相关工作
Spatial pyramid pooling: Models, such as PSPNet [24] or DeepLab [39,23], perform spatial pyramid pooling [18,19] at several grid scales (including imagelevel pooling [52]) or apply several parallel atrous convolution with different rates (called Atrous Spatial Pyramid Pooling, or ASPP). These models have shown promising results on several segmentation benchmarks by exploiting the multi-scale information.
空间金字塔模型已经在分割任务中展示了很好的性能
Encoder-decoder: The encoder-decoder networks have been successfully applied to many computer vision tasks, including human pose estimation [53], object detection [54,55,56], and semantic segmentation [11,57,21,22,58,59,60,61,62,63,64]. Typically, the encoder-decoder networks contain (1) an encoder module that gradually reduces the feature maps and captures higher semantic information, and (2) a decoder module that gradually recovers the spatial information. Building on top of this idea, we propose to use DeepLabv3 [23] as the encoder module and add a simple yet effective decoder module to obtain sharper segmentations
编解码模块也已经在视觉的很多任务中成功应用。
Depthwise separable convolution: Depthwise separable convolution [27,28] or group convolution [7,65], a powerful operation to reduce the computation cost and number of parameters while maintaining similar (or slightly better) performance. This operation has been adopted in many recent neural network designs [66,67,26,29,30,31,68]. In particular, we explore the Xception model [26], similar to [31] for their COCO 2017 detection challenge submission, and show improvement in terms of both accuracy and speed for the task of semantic segmentation.
深度可分离卷积是保持相似精度的前提下,有效的减少运算时间和参数量的一种方法。
方法
Atrous convolution
主要通过r来扩大感受野,当r=1,相当于普通的卷积,当r=2时,感受野相当于5*5的卷积,具体计算公式如下:
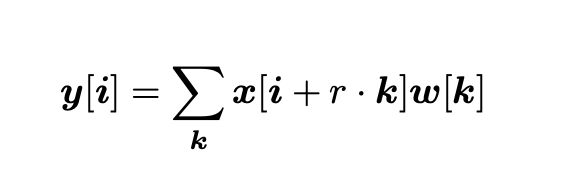
深度可分离卷积
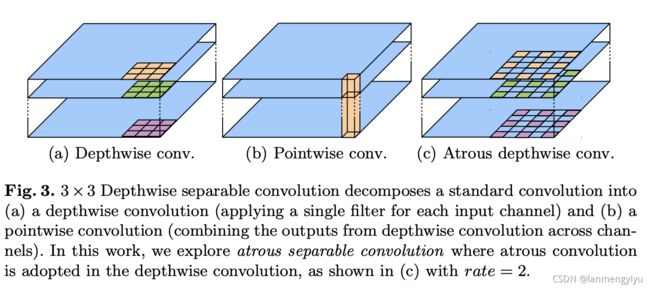
深度可分离卷积将参数减少为原来的约1/9,主要参数集中在图b中。
编码部分
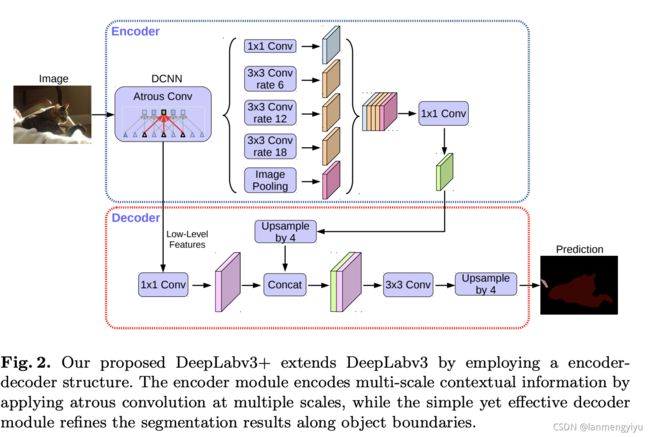
在编码部分,分别从backbone中抽取两个特征层出来,backbone可以是Xception也可以是mobilenet系列,重点在于深层的特征提取出来后,通过空洞卷积生成5个特征层,然后cancat到一起,再通过1*1卷积融合通道特征。这里空洞卷积系数分别是6,12,18
解码部分
深层特征四倍上采样后与浅层特征cancat,之后再四倍上采样恢复原图尺寸,得到的就是预测结果。loss部分可以是交叉熵损失也可以是dice loss
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation