faster-rcnn源码详解
Faster-rcnn详细注释版源码地址,从参数到每一步代码,都有详细的解析
https://download.csdn.net/download/qq_52053775/86105490
如果对源码使用有问题,欢迎在评论区留言
1.faster-rcnn介绍
当一张图片传入到faster-rcnn时,他会被resize到600*800大小,然后将这张图片传入到主干特征提取网络,得到38*50网格的特征图 ,每个网格包含若干个先验框,利用RPN建议网络可以获得先验框的调整参数以及这些先验框是否包含物体,此时我们就得到了建议框,利用这些建议框在特征层上进行截取,截取的特征图进入到ROI pooling层调整到相同大小,然后利用分类与回归预测建议框中是否包含目标,同时对建议框进行调整。
整体来说,网络运行包含两步,一步是粗略的筛选,一步是精细的调整。
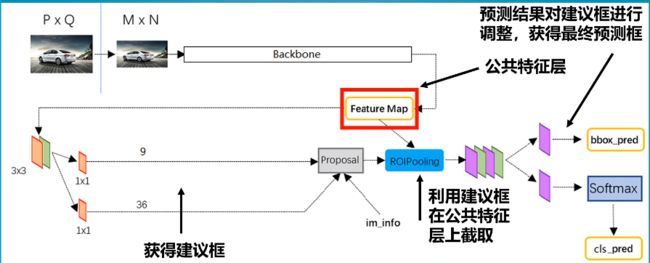
2.Faster R-CNN整体结构
首先输入的图片会保持原来的长宽比,调整到600*800大小,然后经过backbone网络被压缩四次,最终得到38*50大小的特征图,常见的backbone网络可以是vgg,resnet,xpation.
Faster-RCNN的主干特征提取网络部分只包含了长宽压缩了四次的内容,第五次压缩后的内容在ROI中使用。即Faster-RCNN在主干特征提取网络所用的网络层如图所示。
以输入的图片为600x600为例,shape变化如下:
resnet_50网络构建如下:
from tensorflow.keras import layers
from tensorflow.keras.layers import (Activation, Add, AveragePooling2D,
BatchNormalization, Conv2D, MaxPooling2D,
TimeDistributed, ZeroPadding2D)
def res_block(input_tensor, kernel_size, filters, strides=1, padding="same", conv_shortcut=True, name=None):
if conv_shortcut:
short_cut = Conv2D(4 * filters, (1, 1), strides=strides, padding=padding, kernel_initializer="he_normal",
name=name + 'conv_0')(input_tensor)
short_cut = BatchNormalization(name=name + "bn_0")(short_cut)
else:
short_cut = input_tensor
x = Conv2D(filters, (1, 1), strides=strides, padding="same", kernel_initializer="he_normal",
name=name + 'conv_2')(input_tensor)
x = BatchNormalization(name=name + 'bn_2')(x)
x = Activation('relu', name=name + "relu_2")(x)
x = Conv2D(filters, kernel_size, padding='same', kernel_initializer="he_normal",
name=name + 'conv_3')(x)
x = BatchNormalization(name=name + 'bn_3')(x)
x = Activation('relu', name=name + "relu_3")(x)
x = Conv2D(4 * filters, (1, 1), kernel_initializer="he_normal", name=name + 'conv_4')(x)
x = BatchNormalization(name=name + 'bn_4')(x)
x = layers.Add(name=name + "add")([x, short_cut])
x = Activation('relu', name=name + "out")(x)
return x
def ResNet50(inputs):
# -----------------------------------#
# 假设输入进来的图片是600,600,3
# -----------------------------------#
# 600,600,3 -> 300,300,64
x = Conv2D(64, (7, 7), strides=(2, 2), padding="same", name='conv1')(inputs)
x = BatchNormalization(trainable=False, name='bn_conv1')(x)
x = Activation('relu')(x)
# 300,300,64 -> 150,150,64
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
# 150,150,64 -> 150,150,256
x = res_block(x, 3, 64, strides=2, name="res_block_1_")
for i in range(2, 4):
x = res_block(x, 3, 64, conv_shortcut=False, name="res_block_%d_" % i)
# 150,150,256 -> 75,75,512
x = res_block(x, 3, 128, strides=2, name="res_block_4_")
for i in range(5, 9):
x = res_block(x, 3, 128, conv_shortcut=False, name="res_block_%d_" % i)
# 75,75,512 -> 38,38,1024
x = res_block(x, 3, 256, strides=2, name="res_block_9_")
for i in range(10, 16):
x = res_block(x, 3, 256, conv_shortcut=False, name="res_block_%d_" % i)
# 最终获得一个38,38,1024的共享特征层
return x2.设置先验框
(1)设置基础先验框
首先定义了generate_anchor函数生成基础的先验框(其实就是一个矩阵的运算),具体过程为首先生成一个9*4的矩阵,然后设置第2列与第3列的值分别为128,256,512,128,256,512,256,512,1024;128,256,512,256,512,1024,128,256,512,最后第0列与第2列减去第2列值的一半,最后第1列与第3列减去第3列值的一半,
(2)获得backbone最后特征图的大小
这个代码的特征图大小的计算方式是基于特征图减小时的卷积操作或池化操作,为了保证特征图缩小为原来的一半,在卷积或者池化时用0填充边缘,同时paading设置为“valid” 。因此特征图计算公式为(input_length + 2 * 填充 - 卷积核大小)//步长+1.
我个人习惯于直接使用padding="same”,因此特征图大小为input_size//步长,向上取整
(3)获取所有的先验框
定义shift函数,基于特征图上的每个锚点,找到每个锚点对应的9个先验框。
具体实现为:
(1)找到特征图每个锚点对应的原图中心点,strides为缩放的倍数,使用np.meshird()将横纵坐标一一对应
(2) 将横纵坐标降为一维后,横纵坐标堆叠两遍,方便找出先验框左上角和右上角的坐标,
(4)调整矩阵维度后将基础先验框与每一个先验框中心点相加,得到每一个先验框的左上角和右下角的坐标,即确定先验框的位置
(5)将坐标化为小数(比例),并限制在0和1之间
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
# ---------------------------------------------------#
# 生成基础的先验框
# ---------------------------------------------------#
def generate_anchors(sizes=[128, 256, 512], ratios=[[1, 1], [1, 2], [2, 1]]):
num_anchors = len(sizes) * len(ratios)
anchors = np.zeros((num_anchors, 4))
anchors[:, 2:] = np.tile(sizes, (2, len(ratios))).T
for i in range(len(ratios)):
anchors[3 * i: 3 * i + 3, 2] = anchors[3 * i: 3 * i + 3, 2] * ratios[i][0]
anchors[3 * i: 3 * i + 3, 3] = anchors[3 * i: 3 * i + 3, 3] * ratios[i][1]
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchors
# ---------------------------------------------------#
# 对基础的先验框进行拓展获得全部的建议框
# ---------------------------------------------------#
def shift(shape, anchors, stride=16):
# ---------------------------------------------------#
# [0,1,2,3,4,5……37]
# [0.5,1.5,2.5……37.5]
# [8,24,……]
# ---------------------------------------------------#
shift_x = (np.arange(0, shape[0], dtype=keras.backend.floatx()) + 0.5) * stride
shift_y = (np.arange(0, shape[1], dtype=keras.backend.floatx()) + 0.5) * stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y)
shift_x = np.reshape(shift_x, [-1]) # 降维
shift_y = np.reshape(shift_y, [-1])
# print(shift_x,shift_y)
shifts = np.stack([
shift_x,
shift_y,
shift_x,
shift_y
], axis=0) # 按行拼接,四行n列
shifts = np.transpose(shifts) # 转置
number_of_anchors = np.shape(anchors)[0]
k = np.shape(shifts)[0]
# # 矩阵相加,每个锚点9个先验框
shifted_anchors = np.reshape(anchors, [1, number_of_anchors, 4]) + np.array(np.reshape(shifts, [k, 1, 4]),
keras.backend.floatx())
shifted_anchors = np.reshape(shifted_anchors, [k * number_of_anchors, 4])
# ---------------------------------------------------#
# 进行图像的绘制
# ---------------------------------------------------#
# fig = plt.figure()
# ax = fig.add_subplot(111)
# # plt.ylim(-300, 900)
# # plt.xlim(-300, 900)
# plt.ylim(0,600)
# plt.xlim(0,600)
# plt.scatter(shift_x, shift_y)
# box_widths = shifted_anchors[:, 2] - shifted_anchors[:, 0]
# box_heights = shifted_anchors[:, 3] - shifted_anchors[:, 1]
# initial = 0
# for i in [initial + 0, initial + 1, initial + 2, initial + 3, initial + 4, initial + 5, initial + 6, initial + 7,
# initial + 8]:
# rect = plt.Rectangle([shifted_anchors[i, 0], shifted_anchors[i, 1]], box_widths[i], box_heights[i], color="r",
# fill=False)
# ax.add_patch(rect)
# plt.show()
return shifted_anchors
# ---------------------------------------------------#
# 获得resnet50对应的baselayer大小
# ---------------------------------------------------#
def get_resnet50_output_length(height, width):
def get_output_length(input_length):
filter_sizes = [7, 3, 1, 1]
padding = [3, 1, 0, 0]
stride = 2
for i in range(4):
input_length = (input_length + 2 * padding[i] - filter_sizes[i]) // stride + 1
return input_length
return get_output_length(height), get_output_length(width)
# ---------------------------------------------------#
# 获得vgg对应的baselayer大小
# ---------------------------------------------------#
def get_vgg_output_length(height, width):
def get_output_length(input_length):
filter_sizes = [2, 2, 2, 2]
padding = [0, 0, 0, 0]
stride = 2
for i in range(4):
input_length = (input_length + 2 * padding[i] - filter_sizes[i]) // stride + 1
return input_length
return get_output_length(height), get_output_length(width)
def get_anchors(input_shape, backbone, sizes=[128, 256, 512], ratios=[[1, 1], [1, 2], [2, 1]], stride=16):
if backbone == 'vgg':
feature_shape = get_vgg_output_length(input_shape[0], input_shape[1])
print(feature_shape)
else:
feature_shape = get_resnet50_output_length(input_shape[0], input_shape[1])
anchors = generate_anchors(sizes=sizes, ratios=ratios)
anchors = shift(feature_shape, anchors, stride=stride)
anchors[:, ::2] /= input_shape[1]
anchors[:, 1::2] /= input_shape[0]
anchors = np.clip(anchors, 0, 1)
print(anchors)
return anchors
if __name__ == "__main__":
get_anchors([600, 600], 'resnet50')2、获得Proposal建议
获得的公用特征层在图像中就是Feature Map,有两个路径,一个是和ROIPooling结合使用、另一个是进行一次3x3的卷积后,进行一个9通道的1x1卷积,还有一个36通道的1x1卷积。
在Faster-RCNN中,num_priors也就是先验框的数量就是9,所以两个1x1卷积的结果实际上也就是:
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
当我们输入的图片的shape是600x600x3的时候,公用特征层的shape就是38x38x1024,相当于把输入进来的图像分割成38x38的网格,然后每个网格存在9个先验框,这些先验框有不同的大小,在图像上密密麻麻。
9 x 4的卷积的结果会对这些先验框进行调整,获得一个新的框。
9 x 1的卷积会判断上述获得的新框是否包含物体。
到这里我们可以获得了一些有用的框,这些框会利用9 x 1的卷积判断是否存在物体。
def get_rpn(base_layers, num_anchors):
#----------------------------------------------------#
# 利用一个512通道的3x3卷积进行特征整合
#----------------------------------------------------#
x = Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer=RandomNormal(stddev=0.02), name='rpn_conv1')(base_layers)
#----------------------------------------------------#
# 利用一个1x1卷积调整通道数,获得预测结果
#----------------------------------------------------#
x_class = Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer=RandomNormal(stddev=0.02), name='rpn_out_class')(x)
x_regr = Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer=RandomNormal(stddev=0.02), name='rpn_out_regress')(x)
x_class = Reshape((-1, 1),name="classification")(x_class)
x_regr = Reshape((-1, 4),name="regression")(x_regr)
return [x_class, x_regr]3、Proposal建议框的解码
通过第二步我们获得了38x38x9个先验框的预测结果。预测结果包含两部分。
9 x 4的卷积 用于预测 公用特征层上 每一个网格点上 每一个先验框的变化情况。
9 x 1的卷积 用于预测 公用特征层上 每一个网格点上 每一个预测框内部是否包含了物体。
相当于就是将整个图像分成38x38个网格;然后从每个网格中心建立9个先验框,一共38x38x9个,12996个先验框。
当输入图像shape不同时,先验框的数量也会发生改变。
论文中提到的RPN检验结果与建议框的对应关系为:

因此,我们可以根据此公式解码出建议框。然后根据有无物体的置信度进行排序,进行最大值抑制,选出最终的建议框。
def decode_boxes(self, mbox_loc, anchors, variances):
# 获得先验框的宽与高
anchor_width = anchors[:, 2] - anchors[:, 0]
anchor_height = anchors[:, 3] - anchors[:, 1]
# 获得先验框的中心点
anchor_center_x = 0.5 * (anchors[:, 2] + anchors[:, 0])
anchor_center_y = 0.5 * (anchors[:, 3] + anchors[:, 1])
# 建议框距离先验框中心的xy轴偏移情况,variance我的理解是对结果进行缩放,利于梯度下降
detections_center_x = mbox_loc[:, 0] * anchor_width * variances[0]
detections_center_x += anchor_center_x
detections_center_y = mbox_loc[:, 1] * anchor_height * variances[1]
detections_center_y += anchor_center_y
# 真实框的宽与高的求取
detections_width = np.exp(mbox_loc[:, 2] * variances[2])
detections_width *= anchor_width
detections_height = np.exp(mbox_loc[:, 3] * variances[3])
detections_height *= anchor_height
# 获取真实框的左上角与右下角
detections_xmin = detections_center_x - 0.5 * detections_width
detections_ymin = detections_center_y - 0.5 * detections_height
detections_xmax = detections_center_x + 0.5 * detections_width
detections_ymax = detections_center_y + 0.5 * detections_height
# 真实框的左上角与右下角进行堆叠
detections = np.concatenate((detections_xmin[:, None],
detections_ymin[:, None],
detections_xmax[:, None],
detections_ymax[:, None]), axis=-1)
# 防止超出0与1
detections = np.minimum(np.maximum(detections, 0.0), 1.0)
return detections
def detection_out_rpn(self, predictions, anchors, variances=[0.25, 0.25, 0.25, 0.25]):
# ---------------------------------------------------#
# 获得种类的置信度
# ---------------------------------------------------#
mbox_conf = predictions[0]
# ---------------------------------------------------#
# mbox_loc是回归预测结果
# ---------------------------------------------------#
mbox_loc = predictions[1]
results = []
# 对每一张图片进行处理,由于在predict.py的时候,我们只输入一张图片,所以for i in range(len(mbox_loc))只进行一次
for i in range(len(mbox_loc)):
# --------------------------------#
# 利用回归结果对先验框进行解码
# --------------------------------#
detections = self.decode_boxes(mbox_loc[i], anchors, variances)
# --------------------------------#
# 取出先验框内包含物体的概率
# --------------------------------#
c_confs = mbox_conf[i, :, 0]
c_confs_argsort = np.argsort(c_confs)[::-1][:self.rpn_pre_boxes]
# ------------------------------------#
# 原始的预测框较多,先选一些高分框
# ------------------------------------#
confs_to_process = c_confs[c_confs_argsort]
boxes_to_process = detections[c_confs_argsort, :]
# --------------------------------#
# 进行iou的非极大抑制
# --------------------------------#
idx = tf.image.non_max_suppression(boxes_to_process, confs_to_process, self._min_k,
iou_threshold=self.rpn_nms).numpy()
# --------------------------------#
# 取出在非极大抑制中效果较好的内容
# --------------------------------#
good_boxes = boxes_to_process[idx]
results.append(good_boxes)
return np.array(results)4、RoiPoolingConv 池化与建议框的分类与回归
让我们对建议框有一个整体的理解:
事实上建议框就是对图片哪一个区域有物体存在进行初步筛选。
通过主干特征提取网络,我们可以获得一个公用特征层,当输入图片为600x600x3的时候,它的shape是38x38x1024,然后建议框会对这个公用特征层进行截取。
其实公用特征层里面的38x38对应着图片里的38x38个区域,38x38中的每一个点相当于这个区域内部所有特征的浓缩。
建议框会对这38x38个区域进行截取,也就是认为这些区域里存在目标,然后将截取的结果进行resize,resize到14x14x1024的大小。
ROI 池化的输出大小为:batch_size*num_rois*pool_size*pool_size*depth
每次输入的建议框的数量默认情况是32。
然后再对每个建议框再进行Resnet原有的第五次压缩。压缩完后进行一个平均池化,再进行一个Flatten,最后分别进行一个num_classes的全连接和(num_classes-1)x4全连接。
num_classes的全连接用于对最后获得的框进行分类,(num_classes-1)x4全连接用于对相应的建议框进行调整,之所以-1是不包括被认定为背景的框。
通过这些操作,我们可以获得所有建议框的调整情况,和这个建议框调整后框内物体的类别。
事实上,在上一步获得的建议框就是ROI的先验框。
对Proposal建议框加以利用的过程与shape变化如图所示:

ROI池化的实现基于crop_ and_resize实现
class RoiPoolingConv(Layer):
def __init__(self, pool_size, **kwargs):
self.pool_size = pool_size
super(RoiPoolingConv, self).__init__(**kwargs)
# --------------------------------#
# channels:保持baselayer输出通道数
# resnet50时是1024
# --------------------------------#
def build(self, input_shape):
self.nb_channels = input_shape[0][3]
# --------------------------------#
# 输出大小:
# num_rois,pool_size,pool_size,nb_channels
# --------------------------------#
def compute_output_shape(self, input_shape):
input_shape2 = input_shape[1]
return None, input_shape2[1], self.pool_size, self.pool_size, self.nb_channels
def call(self, x, mask=None):
assert(len(x) == 2)
#--------------------------------#
# 共享特征层
# batch_size, 38, 38, 1024
#--------------------------------#
feature_map = x[0]
#--------------------------------#
# 建议框
# batch_size, num_rois, 4
#--------------------------------#
rois = x[1]
#---------------------------------#
# 建议框数量,batch_size大小
#---------------------------------#
num_rois = tf.shape(rois)[1]
batch_size = tf.shape(rois)[0]
#---------------------------------#
# 生成建议框序号信息
# 用于在进行crop_and_resize时
# 帮助建议框找到对应的共享特征层
#---------------------------------#
box_index = tf.expand_dims(tf.range(0, batch_size), 1)
# ---------------------------------#
#
# ---------------------------------#
box_index = tf.tile(box_index, (1, num_rois))
# ---------------------------------#
#
# ---------------------------------#
box_index = tf.reshape(box_index, [-1])
# ---------------------------------#
#
# ---------------------------------#
# ---------------------------------#
# 输出:num_rois, 14, 14, 1024
# ---------------------------------#
rs = tf.image.crop_and_resize(feature_map, tf.reshape(rois, [-1, 4]), box_index, (self.pool_size, self.pool_size))
#---------------------------------------------------------------------------------#
# 最终的输出为
# (batch_size, num_rois, 14, 14, 1024)
#---------------------------------------------------------------------------------#
final_output = K.reshape(rs, (batch_size, num_rois, self.pool_size, self.pool_size, self.nb_channels))
return final_output
因为此时的输入大小为: batch_size*num_rois*pool_size*pool_size*depth,需要对每一个建议框做分类和回归,因此需要使用TimeDistributed对每一个建议框(时间步长)进行处理。代码如下:
def res_block_td(input_tensor, kernel_size, filters, strides=1, padding="same", conv_shortcut=True, name=None):
if conv_shortcut:
short_cut = TimeDistributed(
Conv2D(4 * filters, (1, 1), strides=strides, padding=padding, kernel_initializer="he_normal"),
name=name + 'conv_td_0')(input_tensor)
short_cut = TimeDistributed(BatchNormalization(), name=name + "bn_td_0")(short_cut)
else:
short_cut = input_tensor
x = TimeDistributed(Conv2D(filters, (1, 1), strides=strides, padding="same", kernel_initializer="he_normal"),
name=name + 'conv_td_2')(input_tensor)
x = TimeDistributed(BatchNormalization(), name=name + 'bn_td_2')(x)
x = Activation('relu', name=name + "relu_2")(x)
x = TimeDistributed(Conv2D(filters, kernel_size, padding='same', kernel_initializer="he_normal"),
name=name + 'conv_td_3')(x)
x = TimeDistributed(BatchNormalization(), name=name + 'bn_td_3')(x)
x = Activation('relu', name=name + "relu_3")(x)
x = TimeDistributed(Conv2D(4 * filters, (1, 1), kernel_initializer="he_normal"), name=name + 'conv_td_4')(x)
x = BatchNormalization(name=name + 'bn_4')(x)
x = layers.Add(name=name + "add")([x, short_cut])
x = Activation('relu', name=name + "out")(x)
return x
def resnet50_classifier_layers(x):
# batch_size, num_rois, 14, 14, 1024 -> batch_size, num_rois, 7, 7, 2048
x = res_block_td(x, 3, 512, strides=2, name="res_block_td_14_")
# batch_size, num_rois, 7, 7, 2048 -> batch_size, num_rois, 7, 7, 2048
x = res_block_td(x, 3, 512, conv_shortcut=False, name="res_block_td_15_")
# batch_size, num_rois, 7, 7, 2048 -> batch_size, num_rois, 7, 7, 2048
x = res_block_td(x, 3, 512, conv_shortcut=False, name="res_block_td_16_")
# batch_size, num_rois, 7, 7, 2048 -> batch_size, num_rois, 1, 1, 2048
x = TimeDistributed(AveragePooling2D((7, 7)), name='avg_pool')(x)
return x5.预测的过程
(1)加载图片
(2)图像转RGB并resize到短边为600的大小上,添加上batch_size维度
(3)获得rpn网络预测结果和base_layer,生成先验框并解码
(4)利用建议框获得classifier网络预测结果
(5)利用classifier的预测结果对建议框进行解码,获得预测框
其中,预测参数的修改:
#----------------------------------------------------#
# 将单张图片预测、摄像头检测和FPS测试功能
# 整合到了一个py文件中,通过指定mode进行模式的修改。
#----------------------------------------------------#
import time
import cv2
import numpy as np
import tensorflow as tf
from PIL import Image
from frcnn import FRCNN
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if __name__ == "__main__":
frcnn = FRCNN()
#----------------------------------------------------------------------------------------------------------#
# mode用于指定测试的模式:
# 'predict' 表示单张图片预测,如果想对预测过程进行修改,如保存图片,截取对象等,可以先看下方详细的注释
# 'video' 表示视频检测,可调用摄像头或者视频进行检测,详情查看下方注释。
# 'fps' 表示测试fps,使用的图片是img里面的street.jpg,详情查看下方注释。
# 'dir_predict' 表示遍历文件夹进行检测并保存。默认遍历img文件夹,保存img_out文件夹,详情查看下方注释。
#----------------------------------------------------------------------------------------------------------#
mode = "predict"
#-------------------------------------------------------------------------#
# crop 指定了是否在单张图片预测后对目标进行截取
# count 指定了是否进行目标的计数
# crop、count仅在mode='predict'时有效
#-------------------------------------------------------------------------#
crop = False
count = False
#----------------------------------------------------------------------------------------------------------#
# video_path 用于指定视频的路径,当video_path=0时表示检测摄像头
# 想要检测视频,则设置如video_path = "xxx.mp4"即可,代表读取出根目录下的xxx.mp4文件。
# video_save_path 表示视频保存的路径,当video_save_path=""时表示不保存
# 想要保存视频,则设置如video_save_path = "yyy.mp4"即可,代表保存为根目录下的yyy.mp4文件。
# video_fps 用于保存的视频的fps
#
# video_path、video_save_path和video_fps仅在mode='video'时有效
# 保存视频时需要ctrl+c退出或者运行到最后一帧才会完成完整的保存步骤。
#----------------------------------------------------------------------------------------------------------#
video_path = 0
video_save_path = ""
video_fps = 25.0
#----------------------------------------------------------------------------------------------------------#
# test_interval 用于指定测量fps的时候,图片检测的次数。理论上test_interval越大,fps越准确。
# fps_image_path 用于指定测试的fps图片
#
# test_interval和fps_image_path仅在mode='fps'有效
#----------------------------------------------------------------------------------------------------------#
test_interval = 100
fps_image_path = "img/street.jpg"
#-------------------------------------------------------------------------#
# dir_origin_path 指定了用于检测的图片的文件夹路径
# dir_save_path 指定了检测完图片的保存路径
#
# dir_origin_path和dir_save_path仅在mode='dir_predict'时有效
#-------------------------------------------------------------------------#
dir_origin_path = "img/"
dir_save_path = "img_out/"
if mode == "predict":
'''
1、该代码无法直接进行批量预测,如果想要批量预测,可以利用os.listdir()遍历文件夹,利用Image.open打开图片文件进行预测。
具体流程可以参考get_dr_txt.py,在get_dr_txt.py即实现了遍历还实现了目标信息的保存。
2、如果想要进行检测完的图片的保存,利用r_image.save("img.jpg")即可保存,直接在predict.py里进行修改即可。
3、如果想要获得预测框的坐标,可以进入frcnn.detect_image函数,在绘图部分读取top,left,bottom,right这四个值。
4、如果想要利用预测框截取下目标,可以进入frcnn.detect_image函数,在绘图部分利用获取到的top,left,bottom,right这四个值
在原图上利用矩阵的方式进行截取。
5、如果想要在预测图上写额外的字,比如检测到的特定目标的数量,可以进入frcnn.detect_image函数,在绘图部分对predicted_class进行判断,
比如判断if predicted_class == 'car': 即可判断当前目标是否为车,然后记录数量即可。利用draw.text即可写字。
'''
while True:
img = input('Input image filename:')
try:
image = Image.open(img)
except:
print('Open Error! Try again!')
continue
else:
r_image = frcnn.detect_image(image, crop = crop, count = count)
r_image.show()
elif mode == "video":
capture=cv2.VideoCapture(video_path)
if video_save_path!="":
fourcc = cv2.VideoWriter_fourcc(*'XVID')
size = (int(capture.get(cv2.CAP_PROP_FRAME_WIDTH)), int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT)))
out = cv2.VideoWriter(video_save_path, fourcc, video_fps, size)
fps = 0.0
while(True):
t1 = time.time()
# 读取某一帧
ref,frame=capture.read()
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# 转变成Image
frame = Image.fromarray(np.uint8(frame))
# 进行检测
frame = np.array(frcnn.detect_image(frame))
# RGBtoBGR满足opencv显示格式
frame = cv2.cvtColor(frame,cv2.COLOR_RGB2BGR)
fps = ( fps + (1./(time.time()-t1)) ) / 2
print("fps= %.2f"%(fps))
frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow("video",frame)
c= cv2.waitKey(1) & 0xff
if video_save_path!="":
out.write(frame)
if c==27:
capture.release()
break
capture.release()
out.release()
cv2.destroyAllWindows()
elif mode == "fps":
img = Image.open(fps_image_path)
tact_time = frcnn.get_FPS(img, test_interval)
print(str(tact_time) + ' seconds, ' + str(1/tact_time) + 'FPS, @batch_size 1')
elif mode == "dir_predict":
import os
from tqdm import tqdm
img_names = os.listdir(dir_origin_path)
for img_name in tqdm(img_names):
if img_name.lower().endswith(('.bmp', '.dib', '.png', '.jpg', '.jpeg', '.pbm', '.pgm', '.ppm', '.tif', '.tiff')):
image_path = os.path.join(dir_origin_path, img_name)
image = Image.open(image_path)
r_image = frcnn.detect_image(image)
if not os.path.exists(dir_save_path):
os.makedirs(dir_save_path)
r_image.save(os.path.join(dir_save_path, img_name.replace(".jpg", ".png")), quality=95, subsampling=0)
else:
raise AssertionError("Please specify the correct mode: 'predict', 'video', 'fps' or 'dir_predict'.")
6.数据集格式
数据集目录下有三个文件件夹,JPEGlmages存放图片,Annoation数据集上存放xml格式标签, ImagesSet下存放划分的训练集测试集文件名,运行后生成相应的图片路径。

7.数据集的处理
在完成数据集的摆放之后,我们需要对数据集进行下一步的处理,目的是获得训练用的2007_train.txt以及2007_val.txt,需要用到根目录下的voc_annotation.py。
voc_annotation.py里面有一些参数需要设置。
分别是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次训练可以仅修改classes_path
import os
import random
import xml.etree.ElementTree as ET
import numpy as np
from utils.utils import get_classes
#--------------------------------------------------------------------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#--------------------------------------------------------------------------------------------------------------------------------#
annotation_mode = 0
#-------------------------------------------------------------------#
# 必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
# 与训练和预测所用的classes_path一致即可
# 如果生成的2007_train.txt里面没有目标信息
# 那么就是因为classes没有设定正确
# 仅在annotation_mode为0和2的时候有效
#-------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#--------------------------------------------------------------------------------------------------------------------------------#
# trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
# train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
# 仅在annotation_mode为0和1的时候有效
#--------------------------------------------------------------------------------------------------------------------------------#
trainval_percent = 0.9
train_percent = 0.9
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'
VOCdevkit_sets = [('2007', 'train'), ('2007', 'val')]
classes, _ = get_classes(classes_path)
#-------------------------------------------------------#
# 统计目标数量
#-------------------------------------------------------#
photo_nums = np.zeros(len(VOCdevkit_sets))
nums = np.zeros(len(classes))
def convert_annotation(year, image_id, list_file):
in_file = open(os.path.join(VOCdevkit_path, 'VOC%s/Annotations/%s.xml'%(year, image_id)), encoding='utf-8')
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = 0
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)), int(float(xmlbox.find('ymax').text)))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
nums[classes.index(cls)] = nums[classes.index(cls)] + 1
if __name__ == "__main__":
random.seed(0)
if " " in os.path.abspath(VOCdevkit_path):
raise ValueError("数据集存放的文件夹路径与图片名称中不可以存在空格,否则会影响正常的模型训练,请注意修改。")
if annotation_mode == 0 or annotation_mode == 1:
print("Generate txt in ImageSets.")
xmlfilepath = os.path.join(VOCdevkit_path, 'VOC2007/Annotations')
saveBasePath = os.path.join(VOCdevkit_path, 'VOC2007/ImageSets/Main')
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval= random.sample(list,tv)
train = random.sample(trainval,tr)
print("train and val size",tv)
print("train size",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("Generate txt in ImageSets done.")
if annotation_mode == 0 or annotation_mode == 2:
print("Generate 2007_train.txt and 2007_val.txt for train.")
type_index = 0
for year, image_set in VOCdevkit_sets:
image_ids = open(os.path.join(VOCdevkit_path, 'VOC%s/ImageSets/Main/%s.txt'%(year, image_set)), encoding='utf-8').read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w', encoding='utf-8')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg'%(os.path.abspath(VOCdevkit_path), year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
photo_nums[type_index] = len(image_ids)
type_index += 1
list_file.close()
print("Generate 2007_train.txt and 2007_val.txt for train done.")
def printTable(List1, List2):
for i in range(len(List1[0])):
print("|", end=' ')
for j in range(len(List1)):
print(List1[j][i].rjust(int(List2[j])), end=' ')
print("|", end=' ')
print()
str_nums = [str(int(x)) for x in nums]
tableData = [
classes, str_nums
]
colWidths = [0]*len(tableData)
len1 = 0
for i in range(len(tableData)):
for j in range(len(tableData[i])):
if len(tableData[i][j]) > colWidths[i]:
colWidths[i] = len(tableData[i][j])
printTable(tableData, colWidths)
if photo_nums[0] <= 500:
print("训练集数量小于500,属于较小的数据量,请注意设置较大的训练世代(Epoch)以满足足够的梯度下降次数(Step)。")
if np.sum(nums) == 0:
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("在数据集中并未获得任何目标,请注意修改classes_path对应自己的数据集,并且保证标签名字正确,否则训练将会没有任何效果!")
print("(重要的事情说三遍)。")classes_path用于指向检测类别所对应的txt,以voc数据集为例,我们用的txt为:
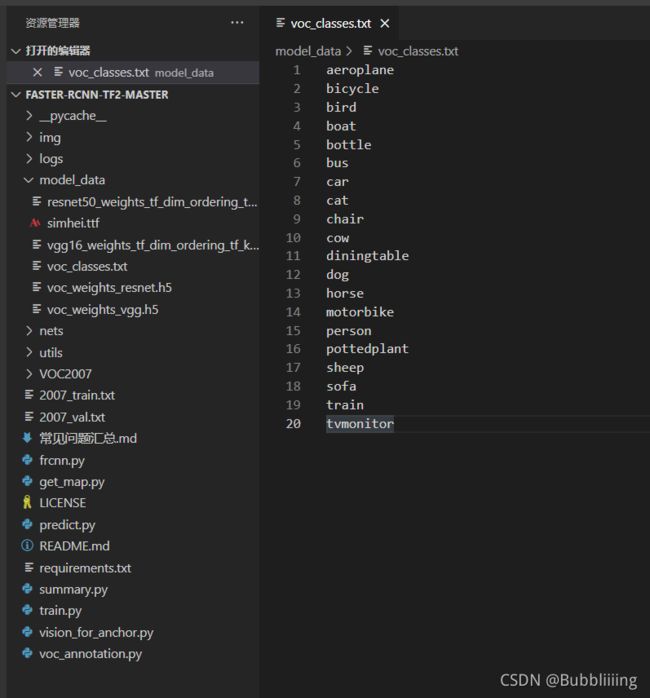
训练自己的数据集时,可以自己建立一个cls_classes.txt,里面写自己所需要区分的类别。
四、训练结果预测
修改模型参数:
import os
import xml.etree.ElementTree as ET
import tensorflow as tf
from PIL import Image
from tqdm import tqdm
from frcnn import FRCNN
from utils.utils import get_classes
from utils.utils_map import get_coco_map, get_map
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if __name__ == "__main__":
'''
Recall和Precision不像AP是一个面积的概念,因此在门限值(Confidence)不同时,网络的Recall和Precision值是不同的。
默认情况下,本代码计算的Recall和Precision代表的是当门限值(Confidence)为0.5时,所对应的Recall和Precision值。
受到mAP计算原理的限制,网络在计算mAP时需要获得近乎所有的预测框,这样才可以计算不同门限条件下的Recall和Precision值
因此,本代码获得的map_out/detection-results/里面的txt的框的数量一般会比直接predict多一些,目的是列出所有可能的预测框,
'''
#------------------------------------------------------------------------------------------------------------------#
# map_mode用于指定该文件运行时计算的内容
# map_mode为0代表整个map计算流程,包括获得预测结果、获得真实框、计算VOC_map。
# map_mode为1代表仅仅获得预测结果。
# map_mode为2代表仅仅获得真实框。
# map_mode为3代表仅仅计算VOC_map。
# map_mode为4代表利用COCO工具箱计算当前数据集的0.50:0.95map。需要获得预测结果、获得真实框后并安装pycocotools才行
#-------------------------------------------------------------------------------------------------------------------#
map_mode = 0
#--------------------------------------------------------------------------------------#
# 此处的classes_path用于指定需要测量VOC_map的类别
# 一般情况下与训练和预测所用的classes_path一致即可
#--------------------------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#--------------------------------------------------------------------------------------#
# MINOVERLAP用于指定想要获得的mAP0.x,mAP0.x的意义是什么请同学们百度一下。
# 比如计算mAP0.75,可以设定MINOVERLAP = 0.75。
#
# 当某一预测框与真实框重合度大于MINOVERLAP时,该预测框被认为是正样本,否则为负样本。
# 因此MINOVERLAP的值越大,预测框要预测的越准确才能被认为是正样本,此时算出来的mAP值越低,
#--------------------------------------------------------------------------------------#
MINOVERLAP = 0.5
#--------------------------------------------------------------------------------------#
# 受到mAP计算原理的限制,网络在计算mAP时需要获得近乎所有的预测框,这样才可以计算mAP
# 因此,confidence的值应当设置的尽量小进而获得全部可能的预测框。
#
# 该值一般不调整。因为计算mAP需要获得近乎所有的预测框,此处的confidence不能随便更改。
# 想要获得不同门限值下的Recall和Precision值,请修改下方的score_threhold。
#--------------------------------------------------------------------------------------#
confidence = 0.02
#--------------------------------------------------------------------------------------#
# 预测时使用到的非极大抑制值的大小,越大表示非极大抑制越不严格。
#
# 该值一般不调整。
#--------------------------------------------------------------------------------------#
nms_iou = 0.5
#---------------------------------------------------------------------------------------------------------------#
# Recall和Precision不像AP是一个面积的概念,因此在门限值不同时,网络的Recall和Precision值是不同的。
#
# 默认情况下,本代码计算的Recall和Precision代表的是当门限值为0.5(此处定义为score_threhold)时所对应的Recall和Precision值。
# 因为计算mAP需要获得近乎所有的预测框,上面定义的confidence不能随便更改。
# 这里专门定义一个score_threhold用于代表门限值,进而在计算mAP时找到门限值对应的Recall和Precision值。
#---------------------------------------------------------------------------------------------------------------#
score_threhold = 0.5
#-------------------------------------------------------#
# map_vis用于指定是否开启VOC_map计算的可视化
#-------------------------------------------------------#
map_vis = False
#-------------------------------------------------------#
# 指向VOC数据集所在的文件夹
# 默认指向根目录下的VOC数据集
#-------------------------------------------------------#
VOCdevkit_path = 'VOCdevkit'
#-------------------------------------------------------#
# 结果输出的文件夹,默认为map_out
#-------------------------------------------------------#
map_out_path = 'map_out'
image_ids = open(os.path.join(VOCdevkit_path, "VOC2007/ImageSets/Main/test.txt")).read().strip().split()
if not os.path.exists(map_out_path):
os.makedirs(map_out_path)
if not os.path.exists(os.path.join(map_out_path, 'ground-truth')):
os.makedirs(os.path.join(map_out_path, 'ground-truth'))
if not os.path.exists(os.path.join(map_out_path, 'detection-results')):
os.makedirs(os.path.join(map_out_path, 'detection-results'))
if not os.path.exists(os.path.join(map_out_path, 'images-optional')):
os.makedirs(os.path.join(map_out_path, 'images-optional'))
class_names, _ = get_classes(classes_path)
if map_mode == 0 or map_mode == 1:
print("Load model.")
frcnn = FRCNN(confidence = confidence, nms_iou = nms_iou)
print("Load model done.")
print("Get predict result.")
for image_id in tqdm(image_ids):
image_path = os.path.join(VOCdevkit_path, "VOC2007/JPEGImages/"+image_id+".jpg")
image = Image.open(image_path)
if map_vis:
image.save(os.path.join(map_out_path, "images-optional/" + image_id + ".jpg"))
frcnn.get_map_txt(image_id, image, class_names, map_out_path)
print("Get predict result done.")
if map_mode == 0 or map_mode == 2:
print("Get ground truth result.")
for image_id in tqdm(image_ids):
with open(os.path.join(map_out_path, "ground-truth/"+image_id+".txt"), "w") as new_f:
root = ET.parse(os.path.join(VOCdevkit_path, "VOC2007/Annotations/"+image_id+".xml")).getroot()
for obj in root.findall('object'):
difficult_flag = False
if obj.find('difficult')!=None:
difficult = obj.find('difficult').text
if int(difficult)==1:
difficult_flag = True
obj_name = obj.find('name').text
if obj_name not in class_names:
continue
bndbox = obj.find('bndbox')
left = bndbox.find('xmin').text
top = bndbox.find('ymin').text
right = bndbox.find('xmax').text
bottom = bndbox.find('ymax').text
if difficult_flag:
new_f.write("%s %s %s %s %s difficult\n" % (obj_name, left, top, right, bottom))
else:
new_f.write("%s %s %s %s %s\n" % (obj_name, left, top, right, bottom))
print("Get ground truth result done.")
if map_mode == 0 or map_mode == 3:
print("Get map.")
get_map(MINOVERLAP, True, score_threhold = score_threhold, path = map_out_path)
print("Get map done.")
if map_mode == 4:
print("Get map.")
get_coco_map(class_names = class_names, path = map_out_path)
print("Get map done.")五.训练过程
(1)参数的设置,训练的参数的含义在代码中均有批注
(2) 获取classes和anchor
获取类别名称和类别数量
获取先验框,先验框是从baselayer得到的13*13网格的特征图中,每一个网格对应9种不同尺寸的先验框。(以resnet为例)
(3)多GPU载入模型和预训练权重
(4)读取数据集对应的txt
(5)设置训练步长、设置冻结训练和非冻结训练参数、
(6)学习率调度,学习率调度可以选用余弦调度或指数调度
(7)加载训练数据和测试数据,训练数据时使用随机的数据增强,对每一个先验框,找出每一个先验框重合度最大的真实框,对先验框与真实框进行逆向解码,设置iou>0.7为正样本,iou<0.3为负样本。并对先验框正样本和负样本进行平衡,如论文所示,尽量保持正负样本比例为1:1,正样本不够时使用负样本补齐。
(8)训练时的评估数据集,将验证集结果写入文件并计算map
(9) 构建多线程数据加载器
(10)开始训练,首先获得rpn预测结果,对先验框进行解码并进行非极大值抑制得到建议框,然后构建标签
import datetime
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import tensorflow.keras.backend as K
from tensorflow.keras.optimizers import SGD, Adam
from nets.frcnn import get_model
from nets.frcnn_training import (ProposalTargetCreator, classifier_cls_loss,
classifier_smooth_l1, get_lr_scheduler,
rpn_cls_loss, rpn_smooth_l1)
from utils.anchors import get_anchors
from utils.callbacks import EvalCallback, LossHistory
from utils.dataloader import FRCNNDatasets, OrderedEnqueuer
from utils.utils import get_classes, show_config
from utils.utils_bbox import BBoxUtility
from utils.utils_fit import fit_one_epoch
'''
训练自己的目标检测模型一定需要注意以下几点:
1、训练前仔细检查自己的格式是否满足要求,该库要求数据集格式为VOC格式,需要准备好的内容有输入图片和标签
输入图片为.jpg图片,无需固定大小,传入训练前会自动进行resize。
灰度图会自动转成RGB图片进行训练,无需自己修改。
输入图片如果后缀非jpg,需要自己批量转成jpg后再开始训练。
标签为.xml格式,文件中会有需要检测的目标信息,标签文件和输入图片文件相对应。
2、损失值的大小用于判断是否收敛,比较重要的是有收敛的趋势,即验证集损失不断下降,如果验证集损失基本上不改变的话,模型基本上就收敛了。
损失值的具体大小并没有什么意义,大和小只在于损失的计算方式,并不是接近于0才好。如果想要让损失好看点,可以直接到对应的损失函数里面除上10000。
训练过程中的损失值会保存在logs文件夹下的loss_%Y_%m_%d_%H_%M_%S文件夹中
3、训练好的权值文件保存在logs文件夹中,每个训练世代(Epoch)包含若干训练步长(Step),每个训练步长(Step)进行一次梯度下降。
如果只是训练了几个Step是不会保存的,Epoch和Step的概念要捋清楚一下。
'''
if __name__ == "__main__":
#---------------------------------------------------------------------#
# train_gpu 训练用到的GPU
# 默认为第一张卡、双卡为[0, 1]、三卡为[0, 1, 2]
# 在使用多GPU时,每个卡上的batch为总batch除以卡的数量。
#---------------------------------------------------------------------#
train_gpu = [0,]
#---------------------------------------------------------------------#
# classes_path 指向model_data下的txt,与自己训练的数据集相关
# 训练前一定要修改classes_path,使其对应自己的数据集
#---------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的。
# 如果想要让模型从主干的预训练权值开始训练,则设置model_path为主干网络的权值,此时仅加载主干。
# 如果想要让模型从0开始训练,则设置model_path = '',Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#
# 一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!
# 如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = 'model_data/voc_weights_resnet.h5'
#------------------------------------------------------#
# input_shape 输入的shape大小
#------------------------------------------------------#
input_shape = [600, 600]
#---------------------------------------------#
# vgg
# resnet50
#---------------------------------------------#
backbone = "resnet50"
#------------------------------------------------------------------------#
# anchors_size用于设定先验框的大小,每个特征点均存在9个先验框。
# anchors_size每个数对应3个先验框。
# 当anchors_size = [8, 16, 32]的时候,生成的先验框宽高约为:
# [128, 128]; [256, 256] ; [512, 512]; [128, 256];
# [256, 512]; [512, 1024]; [256, 128]; [512, 256];
# [1024, 512]; 详情查看anchors.py
# 如果想要检测小物体,可以减小anchors_size靠前的数。
# 比如设置anchors_size = [64, 256, 512]
#------------------------------------------------------------------------#
anchors_size = [128, 256, 512]
#----------------------------------------------------------------------------------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。
# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,此时仅仅进行冻结训练。
#
# 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:
# (一)从整个模型的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-4。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 150,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 150,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2。(不冻结)
# 其中:UnFreeze_Epoch可以在100-300之间调整。
# (二)从主干网络的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-4。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 150,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 150,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2。(不冻结)
# 其中:由于从主干网络的预训练权重开始训练,主干的权值不一定适合目标检测,需要更多的训练跳出局部最优解。
# UnFreeze_Epoch可以在150-300之间调整,YOLOV5和YOLOX均推荐使用300。
# Adam相较于SGD收敛的快一些。因此UnFreeze_Epoch理论上可以小一点,但依然推荐更多的Epoch。
# (三)batch_size的设置:
# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
# faster rcnn的Batch BatchNormalization层已经冻结,batch_size可以为1
#----------------------------------------------------------------------------------------------------------------------------#
#------------------------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:
# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100
# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。
# (断点续练时使用)
# Freeze_Epoch 模型冻结训练的Freeze_Epoch
# (当Freeze_Train=False时失效)
# Freeze_batch_size 模型冻结训练的batch_size
# (当Freeze_Train=False时失效)
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 4
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# SGD需要更长的时间收敛,因此设置较大的UnFreeze_Epoch
# Adam可以使用相对较小的UnFreeze_Epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 100
Unfreeze_batch_size = 2
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
# 如果设置Freeze_Train=False,建议使用优化器为sgd
#------------------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------------------#
# 其它训练参数:学习率、优化器、学习率下降有关
#------------------------------------------------------------------#
#------------------------------------------------------------------#
# Init_lr 模型的最大学习率
# 当使用Adam优化器时建议设置 Init_lr=1e-4
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# Min_lr 模型的最小学习率,默认为最大学习率的0.01
#------------------------------------------------------------------#
Init_lr = 1e-4
Min_lr = Init_lr * 0.01
#------------------------------------------------------------------#
# optimizer_type 使用到的优化器种类,可选的有adam、sgd
# 当使用Adam优化器时建议设置 Init_lr=1e-4
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# momentum 优化器内部使用到的momentum参数
#------------------------------------------------------------------#
optimizer_type = "adam"
momentum = 0.9
#------------------------------------------------------------------#
# lr_decay_type 使用到的学习率下降方式,可选的有'step'、'cos'
#------------------------------------------------------------------#
lr_decay_type = 'cos'
#------------------------------------------------------------------#
# save_period 多少个epoch保存一次权值
#------------------------------------------------------------------#
save_period = 5
#------------------------------------------------------------------#
# save_dir 权值与日志文件保存的文件夹
#------------------------------------------------------------------#
save_dir = 'logs'
#------------------------------------------------------------------#
# eval_flag 是否在训练时进行评估,评估对象为验证集
# 安装pycocotools库后,评估体验更佳。
# eval_period 代表多少个epoch评估一次,不建议频繁的评估
# 评估需要消耗较多的时间,频繁评估会导致训练非常慢
# 此处获得的mAP会与get_map.py获得的会有所不同,原因有二:
# (一)此处获得的mAP为验证集的mAP。
# (二)此处设置评估参数较为保守,目的是加快评估速度。
#------------------------------------------------------------------#
eval_flag = True
eval_period = 5
#------------------------------------------------------------------#
# num_workers 用于设置是否使用多线程读取数据,1代表关闭多线程
# 开启后会加快数据读取速度,但是会占用更多内存
# 在IO为瓶颈的时候再开启多线程,即GPU运算速度远大于读取图片的速度。
#------------------------------------------------------------------#
num_workers = 1
#------------------------------------------------------#
# train_annotation_path 训练图片路径和标签
# val_annotation_path 验证图片路径和标签
#------------------------------------------------------#
train_annotation_path = '2007_train.txt'
val_annotation_path = '2007_val.txt'
#------------------------------------------------------#
# 设置用到的显卡
#------------------------------------------------------#
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(str(x) for x in train_gpu)
ngpus_per_node = len(train_gpu)
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if ngpus_per_node > 1:
strategy = tf.distribute.MirroredStrategy()
else:
strategy = None
print('Number of devices: {}'.format(ngpus_per_node))
#----------------------------------------------------#
# 获取classes和anchor
#----------------------------------------------------#
class_names, num_classes = get_classes(classes_path)
num_classes += 1
anchors = get_anchors(input_shape, backbone, anchors_size)
#----------------------------------------------------#
# 判断是否多GPU载入模型和预训练权重
#----------------------------------------------------#
if ngpus_per_node > 1:
with strategy.scope():
model_rpn, model_all = get_model(num_classes, backbone = backbone)
if model_path != '':
#------------------------------------------------------#
# 载入预训练权重
#------------------------------------------------------#
print('Load weights {}.'.format(model_path))
model_rpn.load_weights(model_path, by_name=True)
model_all.load_weights(model_path, by_name=True)
else:
model_rpn, model_all = get_model(num_classes, backbone = backbone)
if model_path != '':
#------------------------------------------------------#
# 载入预训练权重
#------------------------------------------------------#
print('Load weights {}.'.format(model_path))
model_rpn.load_weights(model_path, by_name=True)
model_all.load_weights(model_path, by_name=True)
time_str = datetime.datetime.strftime(datetime.datetime.now(),'%Y_%m_%d_%H_%M_%S')
log_dir = os.path.join(save_dir, "loss_" + str(time_str))
#--------------------------------------------#
# 训练参数的设置
#--------------------------------------------#
callback = tf.summary.create_file_writer(log_dir)
loss_history = LossHistory(log_dir)
bbox_util = BBoxUtility(num_classes)
roi_helper = ProposalTargetCreator(num_classes)
#---------------------------#
# 读取数据集对应的txt
#---------------------------#
with open(train_annotation_path, encoding='utf-8') as f:
train_lines = f.readlines()
with open(val_annotation_path, encoding='utf-8') as f:
val_lines = f.readlines()
num_train = len(train_lines)
num_val = len(val_lines)
show_config(
classes_path = classes_path, model_path = model_path, input_shape = input_shape, \
Init_Epoch = Init_Epoch, Freeze_Epoch = Freeze_Epoch, UnFreeze_Epoch = UnFreeze_Epoch, Freeze_batch_size = Freeze_batch_size, Unfreeze_batch_size = Unfreeze_batch_size, Freeze_Train = Freeze_Train, \
Init_lr = Init_lr, Min_lr = Min_lr, optimizer_type = optimizer_type, momentum = momentum, lr_decay_type = lr_decay_type, \
save_period = save_period, save_dir = save_dir, num_workers = num_workers, num_train = num_train, num_val = num_val
)
#---------------------------------------------------------#
# 总训练世代指的是遍历全部数据的总次数
# 总训练步长指的是梯度下降的总次数
# 每个训练世代包含若干训练步长,每个训练步长进行一次梯度下降。
# 此处仅建议最低训练世代,上不封顶,计算时只考虑了解冻部分
#----------------------------------------------------------#
wanted_step = 5e4 if optimizer_type == "sgd" else 1.5e4
total_step = num_train // Unfreeze_batch_size * UnFreeze_Epoch
if total_step <= wanted_step:
wanted_epoch = wanted_step // (num_train // Unfreeze_batch_size) + 1
print("\n\033[1;33;44m[Warning] 使用%s优化器时,建议将训练总步长设置到%d以上。\033[0m"%(optimizer_type, wanted_step))
print("\033[1;33;44m[Warning] 本次运行的总训练数据量为%d,Unfreeze_batch_size为%d,共训练%d个Epoch,计算出总训练步长为%d。\033[0m"%(num_train, Unfreeze_batch_size, UnFreeze_Epoch, total_step))
print("\033[1;33;44m[Warning] 由于总训练步长为%d,小于建议总步长%d,建议设置总世代为%d。\033[0m"%(total_step, wanted_step, wanted_epoch))
#------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以加快训练速度
# 也可以在训练初期防止权值被破坏。
# Init_Epoch为起始世代
# Freeze_Epoch为冻结训练的世代
# UnFreeze_Epoch总训练世代
# 提示OOM或者显存不足请调小Batch_size
#------------------------------------------------------#
if True:
UnFreeze_flag = False
if Freeze_Train:
freeze_layers = {'vgg' : 17, 'resnet50' : 141}[backbone]
for i in range(freeze_layers):
if type(model_all.layers[i]) != tf.keras.layers.BatchNormalization:
model_all.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(freeze_layers, len(model_all.layers)))
#-------------------------------------------------------------------#
# 如果不冻结训练的话,直接设置batch_size为Unfreeze_batch_size
#-------------------------------------------------------------------#
batch_size = Freeze_batch_size if Freeze_Train else Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 16
lr_limit_max = 1e-4 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
optimizer = {
'adam' : Adam(lr = Init_lr_fit, beta_1 = momentum),
'sgd' : SGD(lr = Init_lr_fit, momentum = momentum, nesterov=True)
}[optimizer_type]
if ngpus_per_node > 1:
with strategy.scope(): # 同步式训练
model_rpn.compile(
loss = {'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1()}, optimizer = optimizer
)
model_all.compile(
loss = {
'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1(),
'dense_class_{}'.format(num_classes) : classifier_cls_loss(), 'dense_regress_{}'.format(num_classes) : classifier_smooth_l1(num_classes - 1)
}, optimizer = optimizer
)
else:
model_rpn.compile(
loss = {'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1()}, optimizer = optimizer
)
model_all.compile(
loss = {
'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1(),
'dense_class_{}'.format(num_classes) : classifier_cls_loss(), 'dense_regress_{}'.format(num_classes) : classifier_smooth_l1(num_classes - 1)
}, optimizer = optimizer
)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError('数据集过小,无法进行训练,请扩充数据集。')
train_dataloader = FRCNNDatasets(train_lines, input_shape, anchors, batch_size, num_classes, train = True)
val_dataloader = FRCNNDatasets(val_lines, input_shape, anchors, batch_size, num_classes, train = False)
#---------------------------------------#
# 训练时的评估数据集
#---------------------------------------#
eval_callback = EvalCallback(model_rpn, model_all, backbone, input_shape, anchors_size, class_names, num_classes, val_lines, log_dir, \
eval_flag=eval_flag, period=eval_period)
#---------------------------------------#
# 构建多线程数据加载器
#---------------------------------------#
gen_enqueuer = OrderedEnqueuer(train_dataloader, use_multiprocessing=True if num_workers > 1 else False, shuffle=True)
gen_val_enqueuer = OrderedEnqueuer(val_dataloader, use_multiprocessing=True if num_workers > 1 else False, shuffle=True)
gen_enqueuer.start(workers=num_workers, max_queue_size=10)
gen_val_enqueuer.start(workers=num_workers, max_queue_size=10)
gen = gen_enqueuer.get()
gen_val = gen_val_enqueuer.get()
for epoch in range(Init_Epoch, UnFreeze_Epoch):
#---------------------------------------#
# 如果模型有冻结学习部分
# 则解冻,并设置参数
#---------------------------------------#
if epoch >= Freeze_Epoch and not UnFreeze_flag and Freeze_Train:
batch_size = Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 16
lr_limit_max = 1e-4 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 1e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
for i in range(freeze_layers):
if type(model_all.layers[i]) != tf.keras.layers.BatchNormalization:
model_all.layers[i].trainable = True
if ngpus_per_node > 1:
with strategy.scope():
model_rpn.compile(
loss = {'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1()}, optimizer = optimizer
)
model_all.compile(
loss = {
'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1(),
'dense_class_{}'.format(num_classes) : classifier_cls_loss(), 'dense_regress_{}'.format(num_classes) : classifier_smooth_l1(num_classes - 1)
}, optimizer = optimizer
)
else:
model_rpn.compile(
loss = {'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1()}, optimizer = optimizer
)
model_all.compile(
loss = {
'classification' : rpn_cls_loss(), 'regression' : rpn_smooth_l1(),
'dense_class_{}'.format(num_classes) : classifier_cls_loss(), 'dense_regress_{}'.format(num_classes) : classifier_smooth_l1(num_classes - 1)
}, optimizer = optimizer
)
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")
train_dataloader.batch_size = batch_size
val_dataloader.batch_size = batch_size
gen_enqueuer.stop()
gen_val_enqueuer.stop()
# ---------------------------------------#
# 构建多线程数据加载器
#---------------------------------------#
gen_enqueuer = OrderedEnqueuer(train_dataloader, use_multiprocessing=True if num_workers > 1 else False, shuffle=True)
gen_val_enqueuer = OrderedEnqueuer(val_dataloader, use_multiprocessing=True if num_workers > 1 else False, shuffle=True)
gen_enqueuer.start(workers=num_workers, max_queue_size=10)
gen_val_enqueuer.start(workers=num_workers, max_queue_size=10)
gen = gen_enqueuer.get()
gen_val = gen_val_enqueuer.get()
UnFreeze_flag = True
lr = lr_scheduler_func(epoch)
K.set_value(optimizer.lr, lr)
fit_one_epoch(model_rpn, model_all, loss_history, eval_callback, callback, epoch, epoch_step, epoch_step_val, gen, gen_val, UnFreeze_Epoch,
anchors, bbox_util, roi_helper, save_period, save_dir)
5.1 损失函数的实现
faster_rcnn损失函数如下所示,损失包含分类损失和回归损失: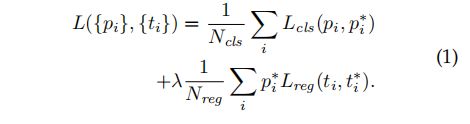
其中,分类损失采用交叉熵损失: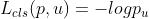
回归损失为:二元交叉熵损失值
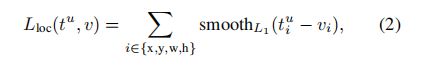
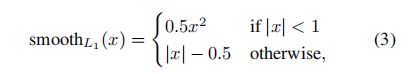
def rpn_cls_loss():
def _rpn_cls_loss(y_true, y_pred):
#---------------------------------------------------#
# y_true [batch_size, num_anchor, 1]
# y_pred [batch_size, num_anchor, 1]
#---------------------------------------------------#
labels = y_true
classification = y_pred
#---------------------------------------------------#
# -1 是需要忽略的, 0 是背景, 1 是存在目标
#---------------------------------------------------#
anchor_state = y_true
#---------------------------------------------------#
# 获得无需忽略的所有样本
#---------------------------------------------------#
indices_for_no_ignore = tf.where(keras.backend.not_equal(anchor_state, -1))
labels_for_no_ignore = tf.gather_nd(labels, indices_for_no_ignore)
classification_for_no_ignore = tf.gather_nd(classification, indices_for_no_ignore)
cls_loss_for_no_ignore = keras.backend.binary_crossentropy(labels_for_no_ignore, classification_for_no_ignore)
cls_loss_for_no_ignore = keras.backend.sum(cls_loss_for_no_ignore)
#---------------------------------------------------#
# 进行标准化
#---------------------------------------------------#
normalizer_no_ignore = tf.where(keras.backend.not_equal(anchor_state, -1))
normalizer_no_ignore = keras.backend.cast(keras.backend.shape(normalizer_no_ignore)[0], keras.backend.floatx())
normalizer_no_ignore = keras.backend.maximum(keras.backend.cast_to_floatx(1.0), normalizer_no_ignore)
#---------------------------------------------------#
# 总的loss
#---------------------------------------------------#
loss = cls_loss_for_no_ignore / normalizer_no_ignore
return loss
return _rpn_cls_loss
def rpn_smooth_l1(sigma = 1.0):
sigma_squared = sigma ** 2
def _rpn_smooth_l1(y_true, y_pred):
#---------------------------------------------------#
# y_true [batch_size, num_anchor, 4 + 1]
# y_pred [batch_size, num_anchor, 4]
#---------------------------------------------------#
regression = y_pred
regression_target = y_true[:, :, :-1]
#---------------------------------------------------#
# -1 是需要忽略的, 0 是背景, 1 是存在目标
#---------------------------------------------------#
anchor_state = y_true[:, :, -1]
#---------------------------------------------------#
# 找到正样本
#---------------------------------------------------#
indices = tf.where(keras.backend.equal(anchor_state, 1))
regression = tf.gather_nd(regression, indices)
regression_target = tf.gather_nd(regression_target, indices)
#---------------------------------------------------#
# 计算smooth L1损失
#---------------------------------------------------#
regression_diff = regression - regression_target
regression_diff = keras.backend.abs(regression_diff)
regression_loss = tf.where(
keras.backend.less(regression_diff, 1.0 / sigma_squared),
0.5 * sigma_squared * keras.backend.pow(regression_diff, 2),
regression_diff - 0.5 / sigma_squared
)
#---------------------------------------------------#
# 将所获得的loss除上正样本的数量
#---------------------------------------------------#
normalizer = keras.backend.maximum(1, keras.backend.shape(indices)[0])
normalizer = keras.backend.cast(normalizer, dtype=keras.backend.floatx())
regression_loss = keras.backend.sum(regression_loss) / normalizer
return regression_loss
return _rpn_smooth_l1
def classifier_cls_loss():
def _classifier_cls_loss(y_true, y_pred):
return K.mean(K.categorical_crossentropy(y_true, y_pred))
return _classifier_cls_loss
def classifier_smooth_l1(num_classes, sigma = 1.0):
epsilon = 1e-4
sigma_squared = sigma ** 2
def class_loss_regr_fixed_num(y_true, y_pred):
regression = y_pred
regression_target = y_true[:, :, 4 * num_classes:]
regression_diff = regression_target - regression
regression_diff = keras.backend.abs(regression_diff)
regression_loss = 4 * K.sum(y_true[:, :, :4*num_classes] * tf.where(
keras.backend.less(regression_diff, 1.0 / sigma_squared),
0.5 * sigma_squared * keras.backend.pow(regression_diff, 2),
regression_diff - 0.5 / sigma_squared
)
)
normalizer = K.sum(epsilon + y_true[:, :, :4*num_classes])
regression_loss = keras.backend.sum(regression_loss) / normalizer
# x_bool = K.cast(K.less_equal(regression_diff, 1.0), 'float32')
# regression_loss = 4 * K.sum(y_true[:, :, :4*num_classes] * (x_bool * (0.5 * regression_diff * regression_diff) + (1 - x_bool) * (regression_diff - 0.5))) / K.sum(epsilon + y_true[:, :, :4*num_classes])
return regression_loss
return class_loss_regr_fixed_num5.2 数据预处理
(1)图像增强
在数据被训练之前,需要进行数据的预处理,训练数据需进行随机的图像增强包括长宽变换以及翻转等,并调整到图片输入大小,在进行图像增强时,真实框也需要做必要的调整。然后,对真实框做归一化处理。
(2)先验框的处理
首先,计算每一个真实框和每一个先验框的IOU并选取,IOU>0.7作为正样本,IOU<0.3作为负样本,最后,对于正样本,求出并取得每一个先验框重合度最大的真实框的偏移程度,
(3)正负样本均衡
尽量保持正负样本为1:1,如果正样本数不够,则用负样本填充,最终代码如下:
class FRCNNDatasets(keras.utils.Sequence):
def __init__(self, annotation_lines, input_shape, anchors, batch_size, num_classes, train, n_sample = 256, ignore_threshold = 0.3, overlap_threshold = 0.7):
"""
Args:
annotation_lines: 训练集/验证集图片地址
input_shape: 输入大小
anchors: 先验框
batch_size: 批次大小
num_classes: 类比数
train: 是否训练
n_sample: 每一批次的先验框数量
ignore_threshold:
overlap_threshold:
"""
self.annotation_lines = annotation_lines
self.length = len(self.annotation_lines) # 训练集长度
self.input_shape = input_shape
self.anchors = anchors
self.num_anchors = len(anchors)
self.batch_size = batch_size
self.num_classes = num_classes
self.train = train
self.n_sample = n_sample
self.ignore_threshold = ignore_threshold
self.overlap_threshold = overlap_threshold
def __len__(self):
return math.ceil(len(self.annotation_lines) / float(self.batch_size))
def __getitem__(self, index):
image_data = []
classifications = []
regressions = []
targets = []
for i in range(index * self.batch_size, (index + 1) * self.batch_size):
i = i % self.length
#---------------------------------------------------#
# 训练时进行数据的随机增强
# 验证时不进行数据的随机增强
#---------------------------------------------------#
image, box = self.get_random_data(self.annotation_lines[i], self.input_shape, random = self.train)
if len(box)!=0:
boxes = np.array(box[:, :4] , dtype=np.float32)
boxes[:, [0, 2]] = boxes[:,[0, 2]] / self.input_shape[1]
boxes[:, [1, 3]] = boxes[:,[1, 3]] / self.input_shape[0]
box = np.concatenate([boxes, box[:, -1:]], axis=-1)
assignment = self.assign_boxes(box)
classification = assignment[:, 4]
regression = assignment[:, :]
#---------------------------------------------------#
# 对正样本与负样本进行筛选,训练样本总和为256
#---------------------------------------------------#
pos_index = np.where(classification > 0)[0]
if len(pos_index) > self.n_sample / 2:
disable_index = np.random.choice(pos_index, size=(len(pos_index) - self.n_sample // 2), replace=False)
classification[disable_index] = -1
regression[disable_index, -1] = -1
# ----------------------------------------------------- #
# 平衡正负样本,保持总数量为256
# ----------------------------------------------------- #
n_neg = self.n_sample - np.sum(classification > 0)
neg_index = np.where(classification == 0)[0]
if len(neg_index) > n_neg:
disable_index = np.random.choice(neg_index, size=(len(neg_index) - n_neg), replace=False)
classification[disable_index] = -1
regression[disable_index, -1] = -1
image_data.append(preprocess_input(np.array(image, np.float32)))
classifications.append(np.expand_dims(classification, -1))
regressions.append(regression)
targets.append(box)
return np.array(image_data), [np.array(classifications,dtype=np.float32), np.array(regressions,dtype=np.float32)], targets
def generate(self):
i = 0
while True:
image_data = []
classifications = []
regressions = []
targets = []
for b in range(self.batch_size):
if i==0:
np.random.shuffle(self.annotation_lines)
#---------------------------------------------------#
# 训练时进行数据的随机增强
# 验证时不进行数据的随机增强
#---------------------------------------------------#
image, box = self.get_random_data(self.annotation_lines[i], self.input_shape, random = self.train)
if len(box)!=0:
boxes = np.array(box[:, :4] , dtype=np.float32)
boxes[:, [0, 2]] = boxes[:,[0, 2]] / self.input_shape[1]
boxes[:, [1, 3]] = boxes[:,[1, 3]] / self.input_shape[0]
box = np.concatenate([boxes, box[:, -1:]], axis=-1)
assignment = self.assign_boxes(box) # 无真实框的处理
classification = assignment[:, 4]
regression = assignment[:, :]
#---------------------------------------------------#
# 对正样本与负样本进行筛选,训练样本总和为256
#---------------------------------------------------#
pos_index = np.where(classification > 0)[0]
if len(pos_index) > self.n_sample / 2:
disable_index = np.random.choice(pos_index, size=(len(pos_index) - self.n_sample // 2), replace=False)
classification[disable_index] = -1
regression[disable_index, -1] = -1
# ----------------------------------------------------- #
# 平衡正负样本,保持总数量为256
# ----------------------------------------------------- #
n_neg = self.n_sample - np.sum(classification > 0)
neg_index = np.where(classification == 0)[0]
if len(neg_index) > n_neg:
disable_index = np.random.choice(neg_index, size=(len(neg_index) - n_neg), replace=False)
classification[disable_index] = -1
regression[disable_index, -1] = -1
i = (i+1) % self.length
image_data.append(preprocess_input(np.array(image, np.float32)))
classifications.append(np.expand_dims(classification, -1))
regressions.append(regression)
targets.append(box)
yield np.array(image_data), [np.array(classifications,dtype=np.float32), np.array(regressions,dtype=np.float32)], targets
def on_epoch_end(self):
shuffle(self.annotation_lines)
def rand(self, a=0, b=1):
return np.random.rand()*(b-a) + a
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=0.7, val=0.4, random=True):
line = annotation_line.split()
#------------------------------#
# 读取图像并转换成RGB图像
#------------------------------#
image = Image.open(line[0])
image = cvtColor(image)
#------------------------------#
# 获得图像的高宽与目标高宽
#------------------------------#
iw, ih = image.size
h, w = input_shape
#------------------------------#
# 获得预测框
#------------------------------#
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
if not random:
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
dx = (w-nw)//2
dy = (h-nh)//2
#---------------------------------#
# 将图像多余的部分加上灰条
#---------------------------------#
image = image.resize((nw,nh), Image.BICUBIC) # 双三次差值
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image, np.float32)
#---------------------------------#
# 对真实框进行调整
#---------------------------------#
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid box
return image_data, box
#------------------------------------------#
# 对图像进行缩放并且进行长和宽的扭曲
#------------------------------------------#
new_ar = iw/ih * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
#------------------------------------------#
# 将图像多余的部分加上灰条
#------------------------------------------#
dx = int(self.rand(0, w-nw))
dy = int(self.rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
#------------------------------------------#
# 翻转图像
#------------------------------------------#
flip = self.rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
image_data = np.array(image, np.uint8)
#---------------------------------#
# 对图像进行色域变换
# 计算色域变换的参数
#---------------------------------#
r = np.random.uniform(-1, 1, 3) * [hue, sat, val] + 1
#---------------------------------#
# 将图像转到HSV上
#---------------------------------#
hue, sat, val = cv2.split(cv2.cvtColor(image_data, cv2.COLOR_RGB2HSV))
dtype = image_data.dtype
#---------------------------------#
# 应用变换
#---------------------------------#
x = np.arange(0, 256, dtype=r.dtype)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
image_data = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val)))
image_data = cv2.cvtColor(image_data, cv2.COLOR_HSV2RGB)
#---------------------------------#
# 对真实框进行调整
#---------------------------------#
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
if flip: box[:, [0,2]] = w - box[:, [2,0]]
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)]
return image_data, box
def iou(self, box):
#---------------------------------------------#
# 计算出每个真实框与所有的先验框的iou
# 判断真实框与先验框的重合情况
#---------------------------------------------#
inter_upleft = np.maximum(self.anchors[:, :2], box[:2])
inter_botright = np.minimum(self.anchors[:, 2:4], box[2:])
inter_wh = inter_botright - inter_upleft
inter_wh = np.maximum(inter_wh, 0)
inter = inter_wh[:, 0] * inter_wh[:, 1]
#---------------------------------------------#
# 真实框的面积
#---------------------------------------------#
area_true = (box[2] - box[0]) * (box[3] - box[1])
#---------------------------------------------#
# 先验框的面积
#---------------------------------------------#
area_gt = (self.anchors[:, 2] - self.anchors[:, 0])*(self.anchors[:, 3] - self.anchors[:, 1])
#---------------------------------------------#
# 计算iou
#---------------------------------------------#
union = area_true + area_gt - inter
iou = inter / union
return iou
def encode_ignore_box(self, box, return_iou=True, variances = [0.25, 0.25, 0.25, 0.25]):
#---------------------------------------------#
# 计算当前真实框和先验框的重合情况
#---------------------------------------------#
iou = self.iou(box)
ignored_box = np.zeros((self.num_anchors, 1))
#---------------------------------------------------#
# 找到处于忽略门限值范围内的先验框
#---------------------------------------------------#
assign_mask_ignore = (iou > self.ignore_threshold) & (iou < self.overlap_threshold)
ignored_box[:, 0][assign_mask_ignore] = iou[assign_mask_ignore]
encoded_box = np.zeros((self.num_anchors, 4 + return_iou))
#---------------------------------------------------#
# 找到每一个真实框,重合程度较高的先验框
#---------------------------------------------------#
assign_mask = iou > self.overlap_threshold
#---------------------------------------------#
# 如果没有一个先验框重合度大于self.overlap_threshold
# 则选择重合度最大的为正样本
#---------------------------------------------#
if not assign_mask.any():
assign_mask[iou.argmax()] = True
#---------------------------------------------#
# 利用iou进行赋值
#---------------------------------------------#
if return_iou:
encoded_box[:, -1][assign_mask] = iou[assign_mask]
#---------------------------------------------#
# 找到对应的先验框
#---------------------------------------------#
assigned_anchors = self.anchors[assign_mask]
#---------------------------------------------#
# 逆向编码,将真实框转化为FRCNN预测结果的格式
# 先计算真实框的中心与长宽
#---------------------------------------------#
box_center = 0.5 * (box[:2] + box[2:])
box_wh = box[2:] - box[:2]
#---------------------------------------------#
# 再计算重合度较高的先验框的中心与长宽
#---------------------------------------------#
assigned_anchors_center = 0.5 * (assigned_anchors[:, :2] + assigned_anchors[:, 2:4])
assigned_anchors_wh = assigned_anchors[:, 2:4] - assigned_anchors[:, :2]
# 逆向求取FasterRCNN应该有的预测结果
encoded_box[:, :2][assign_mask] = box_center - assigned_anchors_center
encoded_box[:, :2][assign_mask] /= assigned_anchors_wh
encoded_box[:, :2][assign_mask] /= np.array(variances)[:2]
encoded_box[:, 2:4][assign_mask] = np.log(box_wh / assigned_anchors_wh)
encoded_box[:, 2:4][assign_mask] /= np.array(variances)[2:4]
return encoded_box.ravel(), ignored_box.ravel()
def assign_boxes(self, boxes):
#---------------------------------------------------#
# assignment分为2个部分
# :4 的内容为网络应该有的回归预测结果
# 4 的内容为先验框是否包含物体,默认为背景
#---------------------------------------------------#
assignment = np.zeros((self.num_anchors, 4 + 1))
assignment[:, 4] = 0.0
if len(boxes) == 0:
return assignment
#---------------------------------------------------#
# 对每一个真实框都进行iou计算
#---------------------------------------------------#
apply_along_axis_boxes = np.apply_along_axis(self.encode_ignore_box, 1, boxes[:, :4])
encoded_boxes = np.array([apply_along_axis_boxes[i, 0] for i in range(len(apply_along_axis_boxes))])
ingored_boxes = np.array([apply_along_axis_boxes[i, 1] for i in range(len(apply_along_axis_boxes))])
#---------------------------------------------------#
# 在reshape后,获得的ingored_boxes的shape为:
# [num_true_box, num_anchors, 1] 其中1为iou
#---------------------------------------------------#
ingored_boxes = ingored_boxes.reshape(-1, self.num_anchors, 1)
ignore_iou = ingored_boxes[:, :, 0].max(axis=0)
ignore_iou_mask = ignore_iou > 0
assignment[:, 4][ignore_iou_mask] = -1
#---------------------------------------------------#
# 在reshape后,获得的encoded_boxes的shape为:
# [num_true_box, num_anchors, 4+1]
# 4是编码后的结果,1为iou
#---------------------------------------------------#
encoded_boxes = encoded_boxes.reshape(-1, self.num_anchors, 5)
#---------------------------------------------------#
# [num_anchors]求取每一个先验框重合度最大的真实框
#---------------------------------------------------#
best_iou = encoded_boxes[:, :, -1].max(axis=0)
best_iou_idx = encoded_boxes[:, :, -1].argmax(axis=0)
best_iou_mask = best_iou > 0
best_iou_idx = best_iou_idx[best_iou_mask]
#---------------------------------------------------#
# 计算一共有多少先验框满足需求
#---------------------------------------------------#
assign_num = len(best_iou_idx)
# 将编码后的真实框取出
encoded_boxes = encoded_boxes[:, best_iou_mask, :]
assignment[:, :4][best_iou_mask] = encoded_boxes[best_iou_idx,np.arange(assign_num), :4]
#----------------------------------------------------------#
# 4代表为背景的概率,设定为0,因为这些先验框有对应的物体
#----------------------------------------------------------#
assignment[:, 4][best_iou_mask] = 1
# 通过assign_boxes我们就获得了,输入进来的这张图片,应该有的预测结果是什么样子的
return assignment
5.3 学习率调度
学习率调度采用指数调度或余弦退火,
余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
当执行完  个epoch之后就会开始热重启(warm restart),而下标i就是指的第几次restart,其中重启并不是重头开始,而是通过增加学习率来模拟,并且重启之后使用旧的
个epoch之后就会开始热重启(warm restart),而下标i就是指的第几次restart,其中重启并不是重头开始,而是通过增加学习率来模拟,并且重启之后使用旧的 作为初始解,这里的 就是通过梯度下降求解loss函数的解,也就是神经网络中的权重,因为重启就是为了通过增大学习率来跳过局部最优,所以需要将置为旧值。
作为初始解,这里的 就是通过梯度下降求解loss函数的解,也就是神经网络中的权重,因为重启就是为了通过增大学习率来跳过局部最优,所以需要将置为旧值。
代码中只进行了一次余弦退火,余弦退火( cosine annealing )的原理如下:
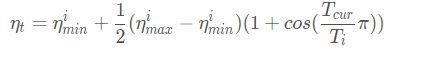
warm_up:由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较
大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoch或者一些step内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后在选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
def get_lr_scheduler(lr_decay_type, lr, min_lr, total_iters, warmup_iters_ratio = 0.05, warmup_lr_ratio = 0.1, no_aug_iter_ratio = 0.05, step_num = 10):
"""
Args:
lr_decay_type: 学习率衰减类型
lr:
min_lr:最小学习率
total_iters: 总迭代次数
warmup_iters_ratio: warm_up迭代次数比例
warmup_lr_ratio: warm_up初始学习率比例
no_aug_iter_ratio: 余弦退火后学习率保持不变的迭代次数比例
step_num: 指数衰减总衰减步长
Returns:
"""
def yolox_warm_cos_lr(lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter, iters):
"""
Args:
lr:学习率
min_lr: 学习率的最小值
total_iters:总迭代次数
warmup_total_iters:warm_up需要迭代的次数
warmup_lr_start:warm开始时的学习率
no_aug_iter:余弦退火后学习率保持不变的迭代次数
iters:迭代次数
Returns:
"""
if iters <= warmup_total_iters:
# lr = (lr - warmup_lr_start) * iters / float(warmup_total_iters) + warmup_lr_start
lr = (lr - warmup_lr_start) * pow(iters / float(warmup_total_iters), 2
) + warmup_lr_start
elif iters >= total_iters - no_aug_iter:
lr = min_lr
else:
lr = min_lr + 0.5 * (lr - min_lr) * (
1.0
+ math.cos(
math.pi
* (iters - warmup_total_iters)
/ (total_iters - warmup_total_iters - no_aug_iter)
)
)
return lr
def step_lr(lr, decay_rate, step_size, iters):
if step_size < 1:
raise ValueError("step_size must above 1.")
n = iters // step_size
out_lr = lr * decay_rate ** n
return out_lr
if lr_decay_type == "cos":
warmup_total_iters = min(max(warmup_iters_ratio * total_iters, 1), 3)
warmup_lr_start = max(warmup_lr_ratio * lr, 1e-6)
no_aug_iter = min(max(no_aug_iter_ratio * total_iters, 1), 15)
func = partial(yolox_warm_cos_lr ,lr, min_lr, total_iters, warmup_total_iters, warmup_lr_start, no_aug_iter)
else:
decay_rate = (min_lr / lr) ** (1 / (step_num - 1))
step_size = total_iters / step_num
func = partial(step_lr, lr, decay_rate, step_size)
return func5.4 回调函数
回调函数主要为训练日志的构建、验证结果写入文件、map的计算
class EvalCallback(keras.callbacks.Callback):
def __init__(self, model_rpn, model_all, backbone, input_shape, anchors_size, class_names, num_classes, val_lines, log_dir, \
map_out_path=".temp_map_out", max_boxes=100, confidence=0.05, nms_iou=0.5, letterbox_image=True, MINOVERLAP=0.5, eval_flag=True, period=1):
super(EvalCallback, self).__init__()
self.model_rpn = model_rpn
self.model_all = model_all
self.backbone = backbone
self.input_shape = input_shape
self.anchors_size = anchors_size
self.class_names = class_names
self.num_classes = num_classes
self.val_lines = val_lines
self.log_dir = log_dir
self.map_out_path = map_out_path
self.max_boxes = max_boxes
self.confidence = confidence
self.nms_iou = nms_iou
self.letterbox_image = letterbox_image
self.MINOVERLAP = MINOVERLAP
self.eval_flag = eval_flag
self.period = period
#---------------------------------------------------#
# 创建一个工具箱,用于进行解码
# 最大使用min_k个建议框,默认为150
#---------------------------------------------------#
self.bbox_util = BBoxUtility(self.num_classes, nms_iou = self.nms_iou, min_k = 150)
self.maps = [0]
self.epoches = [0]
if self.eval_flag: # 对验证集进行评估
with open(os.path.join(self.log_dir, "epoch_map.txt"), 'a') as f:
f.write(str(0))
f.write("\n")
def get_map_txt(self, image_id, image, class_names, map_out_path):
f = open(os.path.join(map_out_path, "detection-results/"+image_id+".txt"),"w")
#---------------------------------------------------#
# 计算输入图片的高和宽
#---------------------------------------------------#
image_shape = np.array(np.shape(image)[0:2])
input_shape = get_new_img_size(image_shape[0], image_shape[1])
#---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
#---------------------------------------------------------#
image = cvtColor(image)
#---------------------------------------------------------#
# 给原图像进行resize,resize到短边为600的大小上
#---------------------------------------------------------#
image_data = resize_image(image, [input_shape[1], input_shape[0]])
#---------------------------------------------------------#
# 添加上batch_size维度
#---------------------------------------------------------#
image_data = np.expand_dims(preprocess_input(np.array(image_data, dtype='float32')), 0)
#---------------------------------------------------------#
# 获得rpn网络预测结果和base_layer
#---------------------------------------------------------#
rpn_pred = self.model_rpn(image_data)
rpn_pred = [x.numpy() for x in rpn_pred]
#---------------------------------------------------------#
# 生成先验框并解码
#---------------------------------------------------------#
anchors = get_anchors(input_shape, self.backbone, self.anchors_size)
rpn_results = self.bbox_util.detection_out_rpn(rpn_pred, anchors)
#-------------------------------------------------------------#
# 利用建议框获得classifier网络预测结果
#-------------------------------------------------------------#
classifier_pred = self.model_all([image_data, rpn_results[:, :, [1, 0, 3, 2]]])[-2:]
classifier_pred = [x.numpy() for x in classifier_pred]
#-------------------------------------------------------------#
# 利用classifier的预测结果对建议框进行解码,获得预测框
#-------------------------------------------------------------#
results = self.bbox_util.detection_out_classifier(classifier_pred, rpn_results, image_shape, input_shape, self.confidence)
#--------------------------------------#
# 如果没有检测到物体,则返回原图
#--------------------------------------#
if len(results[0])<=0:
return
top_label = np.array(results[0][:, 5], dtype = 'int32')
top_conf = results[0][:, 4]
top_boxes = results[0][:, :4]
top_100 = np.argsort(top_label)[::-1][:self.max_boxes]
top_boxes = top_boxes[top_100]
top_conf = top_conf[top_100]
top_label = top_label[top_100]
for i, c in list(enumerate(top_label)):
predicted_class = self.class_names[int(c)]
box = top_boxes[i]
score = str(top_conf[i])
top, left, bottom, right = box
if predicted_class not in class_names:
continue
f.write("%s %s %s %s %s %s\n" % (predicted_class, score[:6], str(int(left)), str(int(top)), str(int(right)),str(int(bottom))))
f.close()
return
def on_epoch_end(self, epoch, logs=None):
temp_epoch = epoch + 1
if temp_epoch % self.period == 0 and self.eval_flag:
if not os.path.exists(self.map_out_path):
os.makedirs(self.map_out_path)
if not os.path.exists(os.path.join(self.map_out_path, "ground-truth")):
os.makedirs(os.path.join(self.map_out_path, "ground-truth"))
if not os.path.exists(os.path.join(self.map_out_path, "detection-results")):
os.makedirs(os.path.join(self.map_out_path, "detection-results"))
print("Get map.")
for annotation_line in tqdm(self.val_lines):
line = annotation_line.split()
image_id = os.path.basename(line[0]).split('.')[0]
#------------------------------#
# 读取图像并转换成RGB图像
#------------------------------#
image = Image.open(line[0])
#------------------------------#
# 获得预测框
#------------------------------#
gt_boxes = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
#------------------------------#
# 获得预测txt
#------------------------------#
self.get_map_txt(image_id, image, self.class_names, self.map_out_path)
#------------------------------#
# 获得真实框txt
#------------------------------#
with open(os.path.join(self.map_out_path, "ground-truth/"+image_id+".txt"), "w") as new_f:
for box in gt_boxes:
left, top, right, bottom, obj = box
obj_name = self.class_names[obj]
new_f.write("%s %s %s %s %s\n" % (obj_name, left, top, right, bottom))
print("Calculate Map.")
try:
temp_map = get_coco_map(class_names = self.class_names, path = self.map_out_path)[1]
except:
temp_map = get_map(self.MINOVERLAP, False, path = self.map_out_path)
self.maps.append(temp_map)
self.epoches.append(temp_epoch)
with open(os.path.join(self.log_dir, "epoch_map.txt"), 'a') as f:
f.write(str(temp_map))
f.write("\n")
plt.figure()
plt.plot(self.epoches, self.maps, 'red', linewidth = 2, label='train map')
plt.grid(True)
plt.xlabel('Epoch')
plt.ylabel('Map %s'%str(self.MINOVERLAP))
plt.title('A Map Curve')
plt.legend(loc="upper right")
plt.savefig(os.path.join(self.log_dir, "epoch_map.png"))
plt.cla()
plt.close("all")
print("Get map done.")
shutil.rmtree(self.map_out_path)5.5 训练部分代码
def fit_one_epoch(model_rpn, model_all, loss_history, eval_callback, callback, epoch, epoch_step, epoch_step_val, gen, gen_val, Epoch, anchors, bbox_util, roi_helper, save_period, save_dir):
total_loss = 0
rpn_loc_loss = 0
rpn_cls_loss = 0
roi_loc_loss = 0
roi_cls_loss = 0
val_loss = 0
with tqdm(total=epoch_step,desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen):
if iteration >= epoch_step:
break
X, Y, boxes = batch[0], batch[1], batch[2]
P_rpn = model_rpn.predict_on_batch(X)
# 候选框的解码
results = bbox_util.detection_out_rpn(P_rpn, anchors)
roi_inputs = []
out_classes = []
out_regrs = []
# ---------------------------------------#
# X2 [n_sample, 4]
# Y1 [n_sample, num_classes]
# Y2 [n_sample, (num_clssees-1) * 8]
# ---------------------------------------#
for i in range(len(X)):
R = results[i]
X2, Y1, Y2 = roi_helper.calc_iou(R, boxes[i])
roi_inputs.append(X2)
out_classes.append(Y1)
out_regrs.append(Y2)
loss_class = model_all.train_on_batch([X, np.array(roi_inputs)], [Y[0], Y[1], np.array(out_classes), np.array(out_regrs)])
write_log(callback, ['total_loss','rpn_cls_loss', 'rpn_reg_loss', 'detection_cls_loss', 'detection_reg_loss'], loss_class, iteration)
rpn_cls_loss += loss_class[1]
rpn_loc_loss += loss_class[2]
roi_cls_loss += loss_class[3]
roi_loc_loss += loss_class[4]
total_loss = rpn_loc_loss + rpn_cls_loss + roi_loc_loss + roi_cls_loss
pbar.set_postfix(**{'total' : total_loss / (iteration + 1),
'rpn_cls' : rpn_cls_loss / (iteration + 1),
'rpn_loc' : rpn_loc_loss / (iteration + 1),
'roi_cls' : roi_cls_loss / (iteration + 1),
'roi_loc' : roi_loc_loss / (iteration + 1),
'lr' : K.get_value(model_rpn.optimizer.lr)})
pbar.update(1)
print('Start Validation')
with tqdm(total=epoch_step_val, desc=f'Epoch {epoch + 1}/{Epoch}',postfix=dict,mininterval=0.3) as pbar:
for iteration, batch in enumerate(gen_val):
if iteration >= epoch_step_val:
break
X, Y, boxes = batch[0], batch[1], batch[2]
P_rpn = model_rpn.predict_on_batch(X)
results = bbox_util.detection_out_rpn(P_rpn, anchors)
roi_inputs = []
out_classes = []
out_regrs = []
for i in range(len(X)):
R = results[i]
X2, Y1, Y2 = roi_helper.calc_iou(R, boxes[i])
roi_inputs.append(X2)
out_classes.append(Y1)
out_regrs.append(Y2)
# Y[0] 有无物体:n_classes,Y[1]建议框相对于真实框的偏移量
loss_class = model_all.test_on_batch([X, np.array(roi_inputs)], [Y[0], Y[1], np.array(out_classes), np.array(out_regrs)])
val_loss += loss_class[0]
pbar.set_postfix(**{'total' : val_loss / (iteration + 1)})
pbar.update(1)
logs = {'loss': total_loss / epoch_step, 'val_loss': val_loss / epoch_step_val}
loss_history.on_epoch_end([], logs)
eval_callback.on_epoch_end(epoch, logs)
print('Epoch:'+ str(epoch+1) + '/' + str(Epoch))
print('Total Loss: %.3f || Val Loss: %.3f ' % (total_loss / epoch_step, val_loss / epoch_step_val))
#-----------------------------------------------#
# 保存权值
#-----------------------------------------------#
if (epoch + 1) % save_period == 0 or epoch + 1 == Epoch:
model_all.save_weights(os.path.join(save_dir, 'ep%03d-loss%.3f-val_loss%.3f.h5' % (epoch + 1, total_loss / epoch_step, val_loss / epoch_step_val)))
if len(loss_history.val_loss) <= 1 or (val_loss / epoch_step_val) <= min(loss_history.val_loss):
print('Save best model to best_epoch_weights.pth')
model_all.save_weights(os.path.join(save_dir, "best_epoch_weights.h5"))
model_all.save_weights(os.path.join(save_dir, "last_epoch_weights.h5"))