PiT:Rethinking Spatial Dimensions of Vision Transformers
文章目录
- Rethinking Spatial Dimensions of Vision Transformers
- 一、Pooling layer of PiT architecture
-
- 1.代码
- 二、Attention analysis
Rethinking Spatial Dimensions of Vision Transformers
image recognition backbone
将ResNet中的spatial reduction应用到ViT中
3个stage,stage之间加一个pooling层,Spatial tokens和Class token分别进行pooling
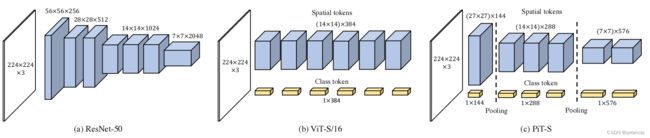
一、Pooling layer of PiT architecture
对特征图进行下采样,降低空间尺寸
Spatial tokens和ClassToken分开进行pooling
Reshape操作在Transformer中进行
transformer的输出是2维的,要先将2维的Spatial tokens变换为3维,对其进行Depth-wise Convolution,将其HW降低,通道加深,再reshape回2维,传入transformer
用作分类的ClassToken需要分离出来,通过一个线性层进行pooling,再cat回去
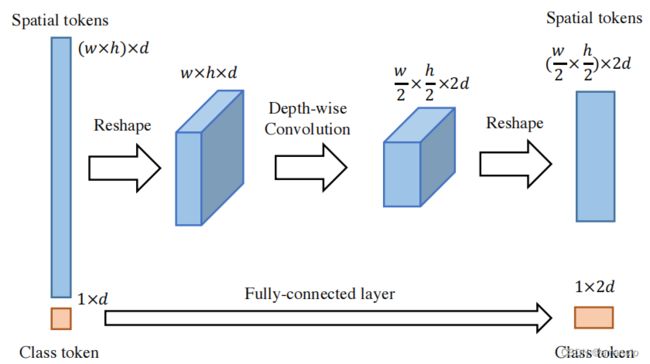
Depth-wise Convolution:先逐通道卷积改变HW,再普通卷积改变C
1.代码
conv_head_pooling
class conv_head_pooling(nn.Module):
def __init__(self, in_feature, out_feature, stride,
padding_mode='zeros'):
super(conv_head_pooling, self).__init__()
self.conv = nn.Conv2d(in_feature, out_feature, kernel_size=stride + 1,
padding=stride // 2, stride=stride,
padding_mode=padding_mode, groups=in_feature)
self.fc = nn.Linear(in_feature, out_feature)
def forward(self, x, cls_token):
x = self.conv(x) # Depth-wise Convolution (Pooling layer of PiT architecture)
cls_token = self.fc(cls_token) # vit里面的class_token,不将其和Spatial tokens在一起pooling,单独用线性层pooling adjust the channel size to match the spatial tokens (Pooling layer of PiT architecture)
return x, cls_token
Transformer
class Transformer(nn.Module):
def __init__(self, base_dim, depth, heads, mlp_ratio,
drop_rate=.0, attn_drop_rate=.0, drop_path_prob=None):
super(Transformer, self).__init__()
self.layers = nn.ModuleList([])
embed_dim = base_dim * heads
if drop_path_prob is None:
drop_path_prob = [0.0 for _ in range(depth)]
self.blocks = nn.ModuleList([
transformer_block(
dim=embed_dim,
num_heads=heads,
mlp_ratio=mlp_ratio,
qkv_bias=True,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=drop_path_prob[i],
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
for i in range(depth)])
def forward(self, x, cls_tokens):
h, w = x.shape[2:4]
x = rearrange(x, 'b c h w -> b (h w) c') # Reshape conv_head_pooling 的输出为三维 (Pooling layer of PiT architecture)
token_length = cls_tokens.shape[1]
x = torch.cat((cls_tokens, x), dim=1)
for blk in self.blocks:
x = blk(x)
cls_tokens = x[:, :token_length]
x = x[:, token_length:]
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) # Reshape conv_head_pooling 的输入为三维 (Pooling layer of PiT architecture)
return x, cls_tokens
conv_embedding(patch embedding)
class conv_embedding(nn.Module):
def __init__(self, in_channels, out_channels, patch_size,
stride, padding):
super(conv_embedding, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=patch_size,
stride=stride, padding=padding, bias=True)
def forward(self, x):
x = self.conv(x)
return x
PoolingTransformer(PiT)
class PoolingTransformer(nn.Module):
def __init__(self, image_size, patch_size, stride, base_dims, depth, heads,
mlp_ratio, num_classes=1000, in_chans=3,
attn_drop_rate=.0, drop_rate=.0, drop_path_rate=.0):
super(PoolingTransformer, self).__init__()
total_block = sum(depth) # 13 [3, 6, 4]
padding = 0
block_idx = 0
width = math.floor(
(image_size + 2 * padding - patch_size) / stride + 1)
self.base_dims = base_dims
self.heads = heads
self.num_classes = num_classes
self.patch_size = patch_size
self.pos_embed = nn.Parameter(
torch.randn(1, base_dims[0] * heads[0], width, width),
requires_grad=True
)
self.patch_embed = conv_embedding(in_chans, base_dims[0] * heads[0], # x=[B,H,W,C] -> x=[B,N(H*W),embed_dim] embed_dim之后会分出head维用作多头atten
patch_size, stride, padding)
self.cls_token = nn.Parameter(
torch.randn(1, 1, base_dims[0] * heads[0]),
requires_grad=True
)
self.pos_drop = nn.Dropout(p=drop_rate)
self.transformers = nn.ModuleList([])
self.pools = nn.ModuleList([])
for stage in range(len(depth)): # stage: [0, 1, 2] depth: [3, 6, 4]
drop_path_prob = [drop_path_rate * i / total_block # drop_path_prob:[r*0/13,r*1/13,...,r*12/13] 层数越深,drop_path_prob越高 i:[0,1,2.....,12]
for i in range(block_idx, block_idx + depth[stage])]
block_idx += depth[stage] # block_idx:[3, 9, 13]
self.transformers.append(
Transformer(base_dims[stage], depth[stage], heads[stage], # base_dims=[64, 64, 64] heads:[4, 8, 16] depth: [3, 6, 4] (每个stage中blk的数量)
mlp_ratio,
drop_rate, attn_drop_rate, drop_path_prob)
)
if stage < len(heads) - 1: # heads:[4, 8, 16] 最后一个stage不加pooling
self.pools.append(
conv_head_pooling(base_dims[stage] * heads[stage], # in_feature (h*w)*d
base_dims[stage + 1] * heads[stage + 1], # out_feature (h*w)*d
stride=2
)
)
self.norm = nn.LayerNorm(base_dims[-1] * heads[-1], eps=1e-6)
self.embed_dim = base_dims[-1] * heads[-1]
# Classifier head
if num_classes > 0:
self.head = nn.Linear(base_dims[-1] * heads[-1], num_classes)
else:
self.head = nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
if num_classes > 0:
self.head = nn.Linear(self.embed_dim, num_classes)
else:
self.head = nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
pos_embed = self.pos_embed
x = self.pos_drop(x + pos_embed)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
for stage in range(len(self.pools)):
x, cls_tokens = self.transformers[stage](x, cls_tokens) # Transformer
x, cls_tokens = self.pools[stage](x, cls_tokens) # conv_head_pooling
x, cls_tokens = self.transformers[-1](x, cls_tokens)
cls_tokens = self.norm(cls_tokens)
return cls_tokens
def forward(self, x):
cls_token = self.forward_features(x)
cls_token = self.head(cls_token[:, 0])
return cls_token
二、Attention analysis
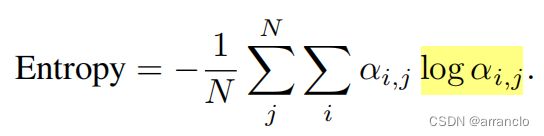
Entropy:attention matrix A 经过soft-max后权重αi,j的总和为1,Entropy是A权重的聚集和分散程度
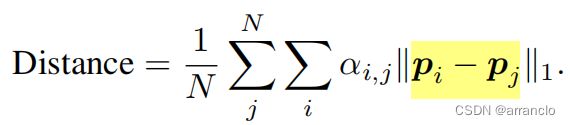
Distance: A中的αi,j 乘上其对应两点之间的距离,表明关注远距离还是近距离之间的atten
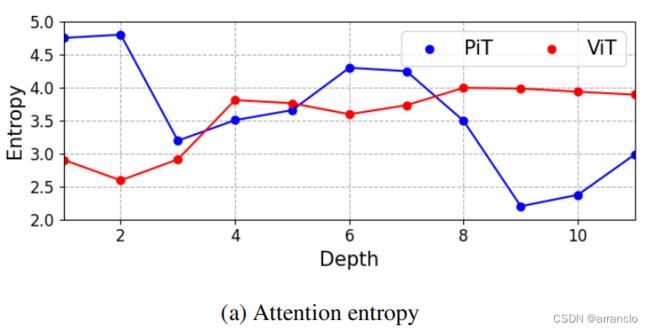
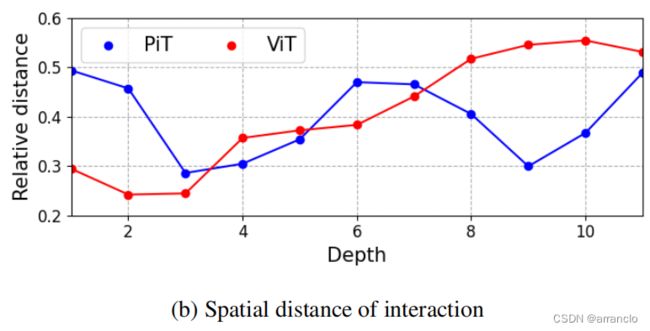
ViT会使自注意力中的联系从局部扩展到全局,而pooling会使得自注意力中的联系重新聚焦于局部