Keras入门教程 5.使用LSTM RNN 进行时间序列预测
Keras 入门教程
- 1.线性回归建模(快速入门)
- 2.线性模型的优化
- 3.波士顿房价回归 (MPL)
- 4.卷积神经网络(CNN)
- 5.使用LSTM RNN 进行时间序列预测
- 6.Keras 预训练模型应用
Keras 使用 LSTM RNN 进行时间序列预测
为了不破坏文章的结棍,特在本文附录中详细介绍关于IMDB数据集结构以及如何还原文本
在本章中,让我们编写一个简单的基于长短期记忆 (LSTM) 的 循环神经网络 (RNN) 来进行序列分析。序列是一组值,其中每个值对应于特定的时间实例。让我们考虑一个阅读句子的简单示例。阅读和理解句子包括按照给定的顺序阅读单词并尝试理解给定上下文中的每个单词及其含义,最终以积极或消极的情绪理解句子。
这里把单词当作值,第一个值对应第一个单词,第二个值对应第二个单词,以此类推,并且顺序会严格保持。序列分析在自然语言处理中经常使用,以找到给定文本的情感分析。
让我们创建一个 LSTM 模型来分析 IMDB 电影评论并找出其正面/负面情绪。
序列分析的模型可以表示如下:
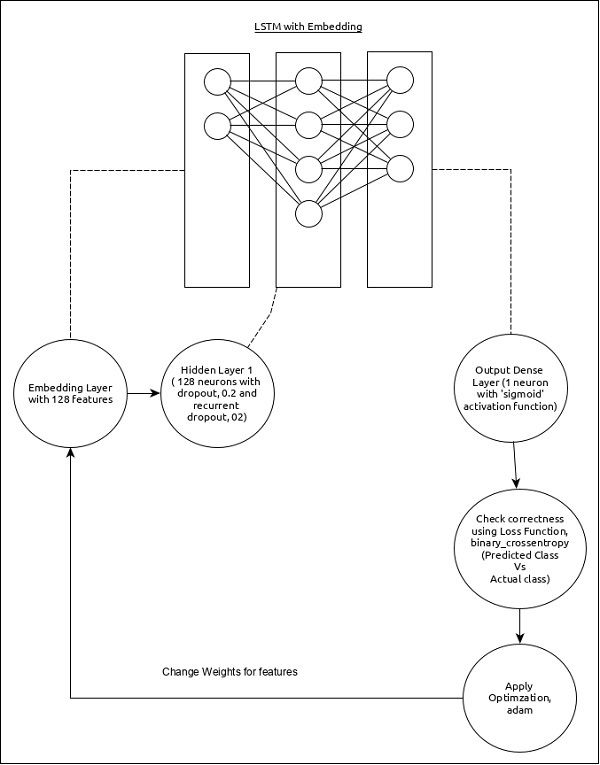
该模型的核心特征如下 :
- 使用具有 128 个特征的嵌入层的输入层。
- 第一层,Dense 由 128 个单元组成,正常 dropout 和 recurrent dropout 设置为 0.2。
- 输出层,Dense由 1 个单元和
sigmoid激活函数组成。 - 使用
binary_crossentropy作为损失函数。 - 使用
adam作为优化器。 - 使用
accuracy作为指标。 - 使用 32 作为批量大小。
- 使用 15 作为纪元。
- 使用 80 作为单词的最大长度。
- 使用 2000 作为给定句子中的最大单词数。
第 1 步:导入模块
导入必要的模块。
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
第 2 步:加载数据
导入 imdb 数据集。
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)
imdb是 Keras 提供的数据集。它代表了一系列电影及其评论。num_words表示评论中的最大单词数。
第 3 步:处理数据
根据我们的模型更改数据集,以便将其输入到我们的模型中。可以使用以下代码更改数据:
x_train = sequence.pad_sequences(x_train, maxlen=80)
x_test = sequence.pad_sequences(x_test, maxlen=80)
sequence.pad_sequences 将具有形状**(data)的输入数据列表转换为形状(data, timesteps)** 的二维 NumPy 数组。基本上,它将时间步长概念添加到给定数据中。它生成长度为 maxlen 的时间步长。
第 4 步:创建模型
创建实际模型。
model = Sequential()
model.add(Embedding(2000, 128))
model.add(LSTM(128, dropout = 0.2, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))
我们使用嵌入层作为输入层,然后添加了 LSTM 层。最后,一个密集层用作输出层。
第 5 步:编译模型
使用选定的损失函数、优化器和指标来编译模型。
model.compile(loss = 'binary_crossentropy',
optimizer = 'adam', metrics = ['accuracy'])
第 6 步:查看模型
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 128) 256000
lstm (LSTM) (None, 128) 131584
dense (Dense) (None, 1) 129
=================================================================
Total params: 387,713
Trainable params: 387,713
Non-trainable params: 0
_________________________________________________________________
第 7 步:训练模型
使用fit()方法训练模型。
history=model.fit(
x_train, y_train,
batch_size = 32,
epochs = 15,
validation_data = (x_test, y_test)
)
执行应用程序将输出以下信息:
Epoch 1/15
782/782 [==============================] - 120s 141ms/step - loss: 0.4562 - accuracy: 0.7768 - val_loss: 0.3785 - val_accuracy: 0.8300
Epoch 2/15
782/782 [==============================] - 115s 147ms/step - loss: 0.3561 - accuracy: 0.8414 - val_loss: 0.3698 - val_accuracy: 0.8348
Epoch 3/15
782/782 [==============================] - 107s 137ms/step - loss: 0.3176 - accuracy: 0.8610 - val_loss: 0.3705 - val_accuracy: 0.8329
Epoch 4/15
782/782 [==============================] - 105s 134ms/step - loss: 0.2896 - accuracy: 0.8748 - val_loss: 0.3638 - val_accuracy: 0.8378
Epoch 5/15
782/782 [==============================] - 108s 139ms/step - loss: 0.2589 - accuracy: 0.8903 - val_loss: 0.4005 - val_accuracy: 0.8199
Epoch 6/15
782/782 [==============================] - 100s 128ms/step - loss: 0.2340 - accuracy: 0.9040 - val_loss: 0.3888 - val_accuracy: 0.8358
Epoch 7/15
782/782 [==============================] - 102s 130ms/step - loss: 0.2129 - accuracy: 0.9134 - val_loss: 0.4438 - val_accuracy: 0.8348
Epoch 8/15
782/782 [==============================] - 119s 152ms/step - loss: 0.1884 - accuracy: 0.9252 - val_loss: 0.5068 - val_accuracy: 0.8246
Epoch 9/15
782/782 [==============================] - 111s 141ms/step - loss: 0.1713 - accuracy: 0.9336 - val_loss: 0.4790 - val_accuracy: 0.8280
Epoch 10/15
782/782 [==============================] - 102s 130ms/step - loss: 0.1558 - accuracy: 0.9386 - val_loss: 0.5173 - val_accuracy: 0.8289
Epoch 11/15
782/782 [==============================] - 110s 141ms/step - loss: 0.1368 - accuracy: 0.9485 - val_loss: 0.5224 - val_accuracy: 0.8210
Epoch 12/15
782/782 [==============================] - 101s 129ms/step - loss: 0.1243 - accuracy: 0.9524 - val_loss: 0.5999 - val_accuracy: 0.8236
Epoch 13/15
782/782 [==============================] - 98s 125ms/step - loss: 0.1146 - accuracy: 0.9585 - val_loss: 0.6276 - val_accuracy: 0.8146
Epoch 14/15
782/782 [==============================] - 100s 128ms/step - loss: 0.0983 - accuracy: 0.9644 - val_loss: 0.7039 - val_accuracy: 0.8218
Epoch 15/15
782/782 [==============================] - 102s 130ms/step - loss: 0.0826 - accuracy: 0.9706 - val_loss: 0.6836 - val_accuracy: 0.8130
第 8 步 - 查看训练曲线
plt.plot(history.epoch,history.history.get('loss'),label="loss")
plt.plot(history.epoch,history.history.get('val_loss'),label="val_loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()

plt.plot(history.epoch,history.history.get('accuracy'),label="accuracy")
plt.plot(history.epoch,history.history.get('val_accuracy'),label="val_accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()
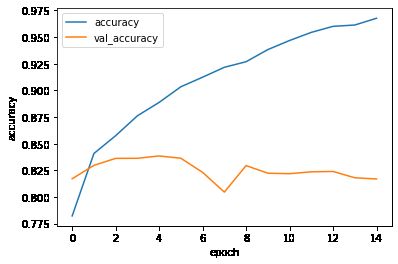
从上两图看,多次训练后,验证数据效果并非有很大的提升
第 9 步 - 评估模型
使用测试数据评估模型。
score, acc = model.evaluate(x_test, y_test, batch_size = 32)
print('Test score:', score)
print('Test accuracy:', acc)
执行上述代码将输出以下信息 :
782/782 [==============================] - 14s 17ms/step - loss: 0.7736 - accuracy: 0.8170
Test score: 0.7735747694969177
Test accuracy: 0.8169999718666077
附录
IMDB 电影评论情感分类数据集
数据集来自 IMDB 的 25,000 条电影评论,以情绪(正面/负面)标记。评论已经过预处理,并编码为词索引(整数)的序列表示。为了方便起见,将词按数据集中出现的频率进行索引,例如整数 3 编码数据中第三个最频繁的词。这允许快速筛选操作,例如:「只考虑前 10,000 个最常用的词,但排除前 20 个最常见的词」。
作为惯例,0 不代表特定的单词,而是被用于编码任何未知单词。
用法
from keras.datasets import imdb
(x_train, y_train), (x_test, y_test) = imdb.load_data(path="imdb.npz",
num_words=None,
skip_top=0,
maxlen=None,
seed=113,
start_char=1,
oov_char=2,
index_from=3)
-
返回:
- 2 个元组:
- x_train, x_test: 序列的列表,即词索引的列表。如果指定了
num_words参数,则可能的最大索引值是num_words-1。如果指定了maxlen参数,则可能的最大序列长度为maxlen。 - y_train, y_test: 整数标签列表 (1 或 0)。
-
参数:
- path: 如果你本地没有该数据集 (在
'~/.keras/datasets/' + path),它将被下载到此目录。 - num_words: 整数或 None。要考虑的最常用的词语。任何不太频繁的词将在序列数据中显示为
oov_char值。 - skip_top: 整数。要忽略的最常见的单词(它们将在序列数据中显示为
oov_char值)。 - maxlen: 整数。最大序列长度。 任何更长的序列都将被截断。
- seed: 整数。用于可重现数据混洗的种子。
- start_char: 整数。序列的开始将用这个字符标记。设置为 1,因为 0 通常作为填充字符。
- oov_char: 整数。由于
num_words或skip_top限制而被删除的单词将被替换为此字符。 - index_from: 整数。使用此数以上更高的索引值实际词汇索引的开始。
- path: 如果你本地没有该数据集 (在
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 2000)
##此处2000是为了保留训练数据中前2000个最常出现的单词,并抛弃低频的单词,保证数据不会太大
加载数据
x_train.shape,y_train.shape,x_test.shape,y_test.shape
((25000, 80), (25000,), (25000, 80), (25000,))
查看数据内容
x_train[0]
array([ 15, 256, 4, 2, 7, 2, 5, 723, 36, 71, 43,
530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13,
104, 88, 4, 381, 15, 297, 98, 32, 2, 56, 26,
141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 476,
26, 480, 5, 144, 30, 2, 18, 51, 36, 28, 224,
92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12,
16, 283, 5, 16, 2, 113, 103, 32, 15, 16, 2,
19, 178, 32])
这些内容代表什么呢,现在我们将它还原
还原文本
## 将单词映射为以整数为索引的字典
word_index = imdb.get_word_index()
## 键值颠倒,将索引转为单词
reverse_word_index = dict([(value,key) for (key,value) in word_index.items()])
## 解码函数
def decode_review(text):
return ' '.join([reverse_word_index.get(i-3, '?') for i in text])
decode_review(x_train[0])
"that played the ? of ? and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all ? up are such a big ? for the whole film but these children are amazing and should be ? for what they have done don't you think the whole story was so lovely because it was true and was ? life after all that was ? with us all"
原来是这些内容,感觉读不通,好象内容不完整,接下来分析,可能是截取的单词由原来的2000 修改为10000,再次还原文本
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = 10000)
decode_review(x_train[0])
"? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ? is an amazing actor and now the same being director ? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for ? and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also ? to the two little boy's that played the ? of norman and paul they were just brilliant children are often left out of the ? list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
内容明显完整多了。这就是告诉加载了更多内容,执行的时间会更长,所以,num_words 这个参数,需要根据实际情况综合考,找个一个性价比较高的值。