TFJS for JavaScript-PART2 chapter3
1.什么是非线性,神经网络隐藏层的非线性如何增强网络的容量,并导致更好的预测精度
2.什么是超参数和方法。 通过输出层的非线性
3.二进制分类对它们进行调优,并结合网络钓鱼-Website检测示例
4.多类分类以及它与二进制类的区别 化,介绍了虹膜花的例子
1.非线性研究
首先,研究多一层隐藏层:
export function
multiLayerPerceptronRegressionModel1Hidden(){
const model=tf.sequential();
model.add(tf.layers.dense({
inputShape:[bostonData.numFeatures],
uints;50,//中间隐藏层 输出为50
activation:'sigmoid',
kernerlInitializer:'leCunNormal'
}));
model.add(tf.layers.dense({
units:1 //输出层为1层
}));
model.summary();//打印模型拓扑的文本摘要 局部变化下的不变性
retunrn model;
}模型为两层网络。 第一层为密实层,50个单元。 它还被配置为具有自定义激活和内核初始化器,我们将在后面的内容中讨论。这一层是一个隐藏层,因为它的输出没有从模型之外直接看到。 第二层是具有默认激活(线性激活)的密集层,结构上我们在第二章的纯线性模型中使用的同一层。 这一层是一个输出层,因为它的输出是模型的最终输出,是模型的predict()方法所返回的。 它是一个多层感知器(MLP)模型-1层隐藏层。 这是一个经常使用的术语,它描述了神经网络,1)有一个简单的拓扑结构,没有循环(被称为前馈神经网络),2)至少有一个隐藏层。 所有的一切 您将在本章中看到符合此定义的模型。如图:

解释:
层的名称和类型(第一栏)
每一层的输出形状(第二列)。 这些形状几乎总是包含一个空维作为第一(批处理)维,表示未确定和可变的批处理大小
每层重量参数的个数(第三列)… 这是构成该层权重的所有单个数字的计数。 对于一个以上重量的层,这是一个和宏所有的重量。 例如,本例中的第一密理层包含两个权重:形状的核[12,50]和形状的偏差[50],导致12×50=650参数。
模型的权重参数的总数(在摘要的底部),然后细分有多少参数是可训练的,有多少是不可训练的。 我们的模特 甚至到目前为止只包含可训练的参数,这些参数属于在调用()时更新tf.Model.fit模型权重。 当我们谈论转移学习时,我们将讨论不可训练的权重 第五章中的g和模型微调。
然而,考虑一个常用的非线性激活函数:relu:

级联线性函数始终会导致线性函数,尽管具有新的斜率和截距。 级联的非线性函数(如本例中的relu)导致具有新颖形状的非线性函数,如本例中的“下移”函数。 这说明了为什么非线性激活及其在神经网络中的级联会导致增强的表示能力(即容量)。机器学习模型能够学习的输入输出关系的范围通常称为模型的能力。从关于非线性的先前讨论中,我们可以看到,与线性回归器相比,具有隐藏层和非线性激活函数的神经网络具有更大的容量。这就解释了为什么我们的两层网络与线性回归模型相比具有更高的测试集精度。
const model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [bostonData.numFeatures],
units: 50,
activation: 'sigmoid',
kernelInitializer: 'leCunNormal'
}));
model.add(tf.layers.dense({
units:50,
activation:'sigmoid',
kerneiInitializer:'leCunNormal'
}))
model.add(tf.layers.dense({units: 1}));
model.summary();
return model;
};两层隐藏层的模型。重复多次模型训练,我们可以大致了解三层网络的最终测试集(即评估)MSE的范围:大约10.8-13.4。 这对应于$ 3,280– $ 3,660的错误估计,超过了两层网络($ 3,700– $ 3,900)的估计。因此,我们再次提高了通过添加非线性隐藏层从而增强其容量来建立我们的模型。
了解非线性激活对于改进的波士顿住房模型的重要性的另一种方法是将其从模型中删除:
export function multiLayerPerceptronRegressionModel1Hidden() {
const model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [bostonData.numFeatures],
units: 50,
// activation: 'sigmoid',
kernelInitializer: 'leCunNormal'
}));
model.add(tf.layers.dense({units: 1}));
model.summary();
return model;
};换句话说,没有乙状结肠激活的两层模型的性能与一层线性回归器大致相同。这证实了我们关于级联线性函数的推理。 通过消除第一层的非线性激活,我们最终得到一个模型,该模型是两个线性函数的级联。 正如我们之前所演示的,结果是另一个线性函数,而模型的容量没有任何增加。这在构建多层神经网络中带来了一个常见的“陷阱”:请确保在隐藏层中包括非线性激活。否则,将浪费计算资源和时间,并可能增加数值的不稳定性(请注意图3.4中B面板的摆动损失曲线)。 稍后,我们将看到,这不仅适用于密集层,还适用于其他层类型,例如卷积层。
获得权值:
model.layers[0].getWeights()[0].print();此行打印第一层(即隐藏层)内核的值。 这是模型中的四个权重张量之一,其他三个是隐藏层的偏置和输出层的核和偏置。 打印输出有一点值得注意,那就是它比我们在打印线性模型的内核时看到的内核有更大的尺寸:

这些都是高维空间的维度,这样模型就可以在其中学习(自动发现)非线性关系。 在这种高维空间中,人类的思维不太善于追踪非线性关系。 一般来说,很难用外行的术语写下几句话来描述每个隐藏层的单元所做的事情,或者解释它如何有助于对深度神经网络的最终预测。 当有多个隐藏层堆叠在彼此的顶部时,这种关系变得更加模糊和难以描述(如清单3.2中定义的模型中的情况)。 尽管有研究试图找到更好的方法来解释深层神经网络隐藏层的含义,但对于某些类型的模型来说,这是公平的 与浅层神经网络和某些类型的非神经网络机器学习模型(如决策树)相比,深层神经网络更难解释。 通过选择深模型而不是浅模型,我们实际上是在交换一些可解释性,以获得更大的模型容量。
超参数和超参数优化:
‘leCunNormal’ 是根据输入的大小生成进入内核初始值的随机数的一种特殊方法。 它不同于默认的内核初始化器(“glorot Normal”),它使用输入和输出的大小。 这些选择是为了通过反复尝试各种参数组合来确保最佳或接近最佳的良好模型质量。 参数,如单元数、核初始化器和激活是模型的超参数。 名称“超参数”表示这些参数不同于模型的权重参数,这些参数在训练过程中通过反向传播自动更新(即, 模型。适合()电话)。 超参数已被选择为模型,它们在训练过程中不会改变。 它们通常确定权重参数的数量和大小(例如,考虑密集层的单位字段),权重参数的初始值(考虑内核Itigiz)。 以及在培训期间如何更新它们(考虑传递给Model.compile()的优化器字段)。因此,它们处于高于权重参数的水平。 因此命名为“超参数”。 除了图层的大小和权重初始化器的类型外,还有许多其他类型的模型及其训练的超参数,例如: 模型中的密集层数、 是否使用任何权重正则化(见第8.1节),如果使用,则使用正则化因子、 是否包括任何辍学层(例如,见第4.3.2节),如果是,辍学率、 优化器的学习率.、优化器的学习率是否应随着训练的进展而逐渐降低,如果是,以什么速度降低、 培训的批次大小。 它们是模型训练过程的配置。 然而,它们影响训练的结果,因此被视为超参数。 因此,很清楚为什么即使是一个简单的深度学习模型也可能有几十个可调谐的超参数。 选择好的超参数值的过程称为超参数优化或超参数调优. 不幸的是,目前还没有确定的算法可以确定给定数据集的最佳超参数和所涉及的机器学习任务. 困难在于许多超参数是离散的,因此验证损失值相对于它们是不可微的。例如,密层中的单位数和模型中的密层数是整数.
由于缺乏用于超参数优化的标准、开箱即用的方法或工具,深度学习实践者通常使用以下三种方法:
- 首先,如果手头的问题类似于一个研究得很好的问题(例如,你可以在这本书中找到任何例子),你可以从在你的问题上应用类似的模型开始,并“继承”这个模型 超参数。 稍后,您可以在起点周围的一个相对较小的超参数空间中搜索;
- 第二,有足够经验的从业者可能有直觉和受过教育的猜测,什么可能是合理的好的超参数对给定的问题。 即使是这样的主观选择 从来不是最优的-它们形成了良好的起点,并可以促进随后的微调;
- 第三,对于只有少量的超参数来优化的情况(例如,少于四个),我们可以使用网格搜索-也就是说,对一些超参数进行详尽的迭代 安培组合,为每个模型训练一个模型,记录验证损失,并采取产生最低验证损失的超参数组合。 例如,唯一要调整的两个超参数是1)密集层中的单元数和2)学习速率;您可以选择一组单元({10,20,50,100,200})和一组学习速率({1e)。 -5、1e-4、1e-3、1e-2})并执行两个集合的交叉,导致总共5*4=20个超参数组合搜索结束。 如果你要自己实现网格搜索,pseu 做代码可能看起来像下面的例子:
function hyperparameterGridSearch():
for units of [10, 20, 50, 100, 200]:
for learningRate of [1e-5, 1e-4, 1e-3, 1e-2]:
Create a model using whose dense layer consists of `units` units
Train the model with an optimizer with `learningRate`
Calculate final validation loss as validationLoss
if validationLoss < minValidationLoss
minValidationLoss := validationLoss
bestUnits := units
bestLearningRate := learningRate
return [bestUnits, bestLearningRate]如何选择这些超参数的范围? 嗯,还有一个地方深度学习不能提供正式的答案。 这些范围通常是基于深度学习练习者的经验和直觉。 它们也可能受到计算资源的限制。 例如,单元过多的密集层可能导致模型在推理过程中训练或运行太慢。 在这种情况下,您应该使用比网格搜索更复杂的方法,例如随机搜索5和贝叶斯6方法。
输出非线性:分类模型
到目前为止,我们看到的两个例子都是回归任务,我们试图预测一个数值(如下载时间或平均房价)。 科技界充斥着这类问题,包括: 给定的电子邮件是否是垃圾邮件、给定的信用卡交易是否合法或欺诈、给定的一秒长的音频样本是否包含特定的口头语、是否 两个指纹图像相互匹配(来自同一个人的同一个手指)。
另一类分类问题是多类分类任务,其中的例子也很多: 一篇新闻文章是否涉及体育、天气、游戏、政治或其他一般话题、 图片是否是猫,狗,铲子等等、 给定电子手写笔的笔画数据,确定手写字符是什么、 在使用机器学习玩一个简单的类似Atari的电子游戏的场景中,确定四个可能的方向(上、下、左、右)中的哪一个是游戏角色下一个,g 即使游戏的当前状态。 什么是二元分类??
任务是,给出一组关于网页及其URL的特性,预测网页是否被用于钓鱼(伪装成另一个网站,目的是窃取用户的敏感信息) 信息)。
HAVING_IP_ADDRESS-是否使用IP地址作为域名的替代(二进制值:{-1,1});
SHORTENING_SERVICE-它是否使用URL缩短服务(二进制值:{1,-1});
SSLFINAL_STATE-如果1)URL使用HTTPS,并且发行人是可信的,2)它使用HTTPS,但发行人不可信,或者3)不使用HTTPS(三元值:{-1,0,1})
这只是最容易处理的数据集类型-数据中的特性已经在一个一致的范围内,因此没有必要像我们那样规范它们的均值和标准差 波士顿住房数据集。
const model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [data.numFeatures],
units: 100,
activation: 'sigmoid'
}));
model.add(tf.layers.dense({units: 100, activation: 'sigmoid'}));
model.add(tf.layers.dense({units: 1, activation: 'sigmoid'}));
model.compile({
optimizer: 'adam',
loss: 'binaryCrossentropy',
metrics: ['accuracy']
});然而,这里的一个关键区别是,我们的网络钓鱼检测模型的最后一层有一个乙状结肠激活,而不是默认的线性激活,就像波士顿住房模型中的那样。 这是我 我们的模型被限制在只输出0到1之间的数字,这与波士顿住房模型不同,后者可能输出任何浮动数。 通过模型总是输出估计的概率值,我们得到了两个好处:
1.设定阈值判断最终结果;
2.方便建立损失函数。
神经网络的最后一层,通常是一个密集层,用它的输入执行矩阵乘法(matMul)和偏置加法(偏置加法)操作。 在MatMul和偏置Add的结果中加入像Sigmoid这样的挤压非线性是实现[0,1]范围的自然方法。
清单3.5中代码的另一个新方面是优化器类型:“adam”,它不同于以前示例中使用的“gd”优化器.原来的sgd可能会受学习速率和损失函数的影响而导致损失收敛较慢。 adam优化器的目的是通过使用一个随梯度的历史变化的乘法因子(从早期的训练迭代)来解决sgd的这些缺点。 此外,它对不同的模型权重参数使用不同的乘法因子。 因此,与sgd相比,adam在一系列深度学习模型类型上通常会导致更好的收敛性和更少的对学习率选择的依赖。(我们可以不必花太多精力在选择学习率上面)。TensorFlow.js库提供了许多其他优化器类型,其中一些也很受欢迎(如rmsprop)。 信息框3.1中的表格简要概述了它们:

sgd:随机梯度下降法, 最简单的优化器,总是使用学习速率作为梯度的乘数.
momentum: 积累过去的梯度的方式,使更新到一个权重参数变得更快,当过去的梯度更多地在同一方向排列,并变得更慢,当他们的恰恰 朝不同方向走了很多.
rmsprop: 通过跟踪每个权重梯度的根均值的最近历史,对模型的不同权重参数的乘法因子进行不同的标度;因此它的nam英语字母表的第5个字母.(支持均方根)
adadelta:与rmsprop方法类似。
adam: 可以理解为AdaDelta的自适应学习速率方法和动量方法(momentum)的结合。
adamx: 类似于ADAM,但使用稍微不同的算法跟踪梯度的大小.
一个明显的问题是,考虑到您正在处理的机器学习问题和模型,您应该使用哪个优化器。 不幸的是,在深度学习领域还没有达成共识( 为什么TensorFlow.js提供了上表中列出的所有优化器!)。 在实践中,你应该从流行的开始,包括adam和rmsprop。 给定足够的时间和计算时间 来源,您还可以将优化器视为超参数,并通过超参数调谐找到给您最佳训练结果的选择。
测量二元分类器的质量:精度、召回、精度和ROC曲线
当我们的网络进行猜测时,它要么是对的,要么是错的,因此我们有四种可能的场景,用于输入示例的实际标签和网络的输出,如表3.1所示:

真阳性(T PS)和真阴性(T NS)是模型预测正确答案的地方;假阳性(FPs)和假阴性(FNS)是模型错误的地方。 如果我们填写 有计数的四个单元格,我们得到了一个混淆矩阵;表3.2显示了我们钓鱼检测问题的假设矩阵:

在我们的假设结果从我们的钓鱼例子,我们看到,我们正确地识别了四个钓鱼网页,错过了两个,并有一个错误的警报。 现在让我们来看看不同的通用度量 这是为了表达这种表现。
准确性是最简单的度量。 它量化了正确分类实例的百分比:
Accuracy = (#TP + #TN) / #examples = (#TP + #TN) / (#TP + #TN + #FP + #FN)
In our particular example,
Accuracy = (4 + 93) / 100 = 97%。
下一对度量试图捕捉在准确性、精确性和召回性方面缺失的微妙之处:
- 精度是模型所做的实际为正的正预测的比率:
- 精度是模型所做的实际正预测的比率:精度=#TP/(#TP#FP)与我们从混淆矩阵中得到的数字,我们将计算精度=4/(4 + 1) = 80%
- 在现实世界的二元分类问题中,往往很难同时获得良好的精确性和回忆性。
- 因此,我们可以看到,在精确性和回忆性之间存在着权衡,这种权衡很难用我们到目前为止讨论过的任何一个指标来量化。 幸运的是,雷西亚的丰富历史 进入二元分类的RCH给了我们更好的方法来量化和可视化这种权衡关系。 接下来我们将讨论的ROC曲线是这类常用工具。
ROC曲线:显示二元分类的权衡
[医]接收器工作特性(曲线)

正如您可能在图3.6中的轴标签中注意到的那样,ROC曲线并不是通过绘制彼此之间的精度和召回度量来精确制作的。 相反,它们基于两个稍微不同的 租金指标。 ROC曲线的水平轴为假阳性率(FPR),定义为:
FPR = #FP / (#FP + #TN)
也就是有多少消极的被误分成了积极的。
ROC曲线的垂直轴是真实正值(TPR),定义为:
TPR = #TP / (#TP + #FN) = recall
也就是有多少比例的真正的积极的样本被成功分类出来了。
分析可知,以上两个系数有正性关系。
然而,FPR是一种新的东西。 它的分母是实例的实际类别为负数的所有情况的计数。
总结在二进制分类问题中您将遇到的最常见的度量:

图3.6中的七条ROC曲线是在七个不同的训练时代开始时,从第一个时代(001时代)到最后一个(400时代)。 它们中的每一个都是基于mod创建的 EL对测试数据的预测(而不是训练数据)。 清单3.6显示了如何使用Model.Fit()API的onEpochBegin回调来完成这项工作的细节。 这种方法允许您执行 在训练调用中对模型进行有趣的分析和可视化,而不需要编写for循环或使用多个Model.fit()调用:
await modle.fit(trainData.data,trainData.target,{batchSize,
validationSplit:0.2,
callbacks{
onEpochBegin:async(epoch)=>{
if((epoch+1)%100===0||
epoch === 0 || epoch === 2 || epoch === 4){
const probs=model.predict(testData.data);
drawROC(testData.target,probs,epoch);
}
},
onEpochEnd:async (epoch,logs)=>{
await
ui.updateStatus(
`Epoch ${epoch + 1} of ${epochs} completed.`);
trainLogs.push(logs);
ui.plotLosses(trainLogs);
ui.plotAccuracies(trianLogs);
}
}
})function drawROC(targets,probs,epoch){
return tf.tidy(()=>{
const thresholds=[
0.0, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45,0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85,0.9, 0.92, 0.94, 0.96, 0.98, 1.0]
const tprs=[];
const fprs=[];
let area=0;
for(let i=0;i<thresholds.length;i++){
const threshold=thresholds[i];
const threshPredictions =
utils.binarize(probs, threshold).as1D(); fpr=falsePositiveRate(targets,threshPredictions).arraySync();//同步获得数组
const tpr=tf.metrics.recall(targets,threshPrecdictions).arraySync();
fprs.push(fpr);
tprs.push(tpr);
if(i>0){
area+=(tprs[i]+tprs[i-1])*
(frs[i - 1] - fprs[i])/2;
}
ui.plotROC(fprs,tprs,epoch);
return area;
});
}当阈值从0逐渐增加到1时,我们从地块的右上角(其中FPR和TPR都是1)移动到地块的左下角(其中FPR和TPR都是0))。 清单3.7中值得指出的一件事是tf.tiddy()的使用… 此函数确保在传递给它的匿名函数中创建的张量被正确地处理 他们不会继续占用WebGL内存。在浏览器中,TensorFlow.js无法管理用户创建的张量的内存,主要原因是Java脚本中缺乏对象的最终确定以及WebGL文本缺乏垃圾收集支持TensorFlow.js张量的URES。 如果这些中间张量没有被正确清理,就会发生WebGL内存泄漏。tidy()用于内存管理,防止内存泄漏。
二元交叉熵:二元分类的损失函数
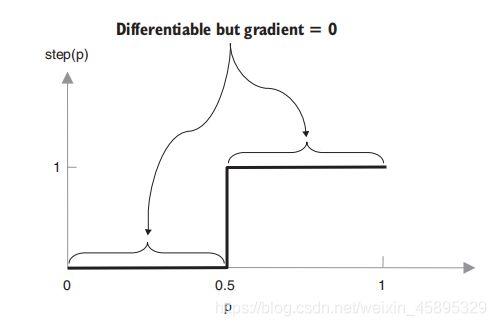

不能precision, recall, FPR, andAUC作为损失函数,因为他们所用的阈值函数除了分界点外,导数都为0,没法用BP算法更新权值,其他的乘以0还是为0,模型找不到更新权值的方向。所以对于二分类问题,用二元交叉熵作为损失函数,其导数不为0:
function binaryCrossentropy(truthLabel, prob):
if truthLabel is 1:
return -log(prob)
else:
return -log(1 - prob)如图所示的二进制阈值函数不同,这些曲线在每个点都有非零斜率,导致非零梯度。 这就是为什么它适合于基于反向传播的模型训练。 毕竟,MSE是可微的,计算真值标签和概率之间的MSE将产生非零导数,就像二进制交叉熵一样。 答案与事实有关 MSE在边界上有“递减回报”。

这表明二元分类问题不同于回归问题的另一个方面:对于二元分类问题,损失(二元交叉熵)和度量(准确性、预性) 例如,对于回归问题(例如,平均平方误差),它们通常是相同的。也就是不同的问题用到的损失函数各不相同。
多级分类
虹膜花数据集。
到目前为止,我们在这本书中看到的所有机器学习的例子都涉及到更简单的目标表示,例如下载时间预测问题中的单个数字和波士顿-侯中的单个数字 问题,以及网络钓鱼检测问题中二进制目标的0-1表示。

向量的长度等于所有可能类别的数目。 向量中存在单个1值的事实正是这种编码方案被称为“一热”的原因。 这可以从两个不同的角度来理解:
1.one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程。
2.从技术上来讲,one-hot编码把复杂的分类问题分解成了若干个二分类网络,简化了神经网络的建模的复杂度
建立模型:
const model=tf.sequential();
model.add(tf.layers.dense({
units:10,
activation:'sigmoid',
inputShape:[xTrain.shape[1]]}
));
model.add(tf.layers.dense({
units:3,
activation:'softmax'
}));
model.summary();
const optimizer=tf.train.adam(params.learningRate);
model.compile({
opimizer:optimizer,
loss:'categoricalCrossentropy',
metrice:['accuracy'],
});模型结构为:

softmax的数学定义可以写成以下伪码:
softmax([x1, x2, …, xn]) =
[exp(x1) / (exp(x1) + exp(x2) + … + exp(xn)),
exp(x2) / (exp(x1) + exp(x2) + … + exp(xn)),
…,
exp(xn) / (exp(x1) + exp(x2) + … + exp(xn))]
与我们看到的乙状结肠激活函数不同,softmax激活函数不是逐元的,因为输入向量的每个元素都是以依赖于所有其他元素的方式转换的原理。也就是互相关联。大家一起输出一个值。意义为:
- 首先,它确保每个数字都在0到1之间的区间内;
- 第二,保证输出向量的所有元素和为1。
这是一个理想的属性,因为1)输出可以被解释为分配给类的概率分数,2)为了与分类交叉熵损失函数兼容 ,输出必须满足该属性。 - 第三,定义确保输入向量中的较大元素映射到输出向量中的较大元素;
如:const x = tf.tensor1d([-3, 0, -8]);
tf.softmax(x).print();
[0.0474107, 0.9522698, 0.0003195]
可直接看出第二类的可能性最高。代码中可用argMax()来实现:
const predictOut=model.predict(input);
const winner=data.IRIS_CLASSES[predictOut.argMax(-1).dataSync()[0]];参数值-1表示arg Max()应该沿着最后一个维度查找最大值并返回它们的索引.
范畴交叉熵:多类分类的损失函数
model.compile({
optimizer: optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});其中的accuracy作为人们直接观察模型的性能指标是可行的,但是直接作为损失函数是不可行的,其存在零梯度问题。所以提出了categoricalCrossentropy作为多分类模型的损失函数。 它只是将二元交叉熵推广到两类以上的情况。其代码表示为:
function categoricalCrossentropy(oneHotTruth,probs):
for i in(0 to length of oneHotTruth)
retrun -log(probs[i]);
也就是变成了三元交叉熵。以下是实例:

只要代表实际分类的那个分量不变,cce就不会变,而mse却会改变,这正是我们选择cce的原因。同时MSE对概率的刺激作用也没有CCE好。也就是在MSE的范围下,正确的概率能到达的范围很窄。
混淆矩阵:多类分类的细粒度分析

上图分别是损失和精度和混淆矩阵在训练次数为40的结果图。 这反映了一个事实,即虹膜数据集是一个较小的数据集,在特征空间中的类之间具有相对明确的边界。 混淆矩阵根据多类分类器的实际类和模型的预测类分解结果。 它是形状的正方形矩阵[num类,num类]。比如这里是:3*3的矩阵。
因此,混淆矩阵的对角线元素对应于正确分类的示例。 一个完美的多类分类器应该产生一个在对角线之外没有非零元素的混淆矩阵。上图就是一个完美的混淆矩阵。下图就不是了:
 上图仅仅是训练了2个轮次后的混淆矩阵,可以看出有5个错误的分类结果。 然而,混淆矩阵告诉我们的不仅仅是一个数字:它显示了哪些类涉及最多的错误,哪些涉及较少的错误。 因此,您可以看到,在多类分类中,混淆矩阵是一种比简单的准确性更具信息性的度量,就像精度和回忆一起形成了更全面的度量一样 二元分类的测量比精度。 混淆矩阵可以提供信息,帮助与模型和培训过程相关的决策。 例如,犯一些类型的错误可能比混淆其他类对更昂贵。 也许把体育网站误认为是游戏网站比混淆体育网站更麻烦 一个钓鱼骗局。 在这种情况下,您可以调整模型的超参数,以最小化最昂贵的错误。 到目前为止,我们所看到的模型都以一组数字作为输入。 换句话说,每个输入示例都被表示为一个简单的数字列表,其中长度是固定的,只要元素对所有ex都是一致的,元素的排序就不重要 安普斯喂给模型。 。 虽然这种类型的模型涵盖了重要和实际的机器学习问题的一大部分,但它远非唯一的类型。 超参数优化仍然是研究的一个活跃领域… 目前,最常用的方法包括网格搜索、随机搜索和贝叶斯方法。 表3.6总结了迄今为止我们所看到的最常见的机器学习问题(回归、二进制分类和多类分类)的推荐方法:
上图仅仅是训练了2个轮次后的混淆矩阵,可以看出有5个错误的分类结果。 然而,混淆矩阵告诉我们的不仅仅是一个数字:它显示了哪些类涉及最多的错误,哪些涉及较少的错误。 因此,您可以看到,在多类分类中,混淆矩阵是一种比简单的准确性更具信息性的度量,就像精度和回忆一起形成了更全面的度量一样 二元分类的测量比精度。 混淆矩阵可以提供信息,帮助与模型和培训过程相关的决策。 例如,犯一些类型的错误可能比混淆其他类对更昂贵。 也许把体育网站误认为是游戏网站比混淆体育网站更麻烦 一个钓鱼骗局。 在这种情况下,您可以调整模型的超参数,以最小化最昂贵的错误。 到目前为止,我们所看到的模型都以一组数字作为输入。 换句话说,每个输入示例都被表示为一个简单的数字列表,其中长度是固定的,只要元素对所有ex都是一致的,元素的排序就不重要 安普斯喂给模型。 。 虽然这种类型的模型涵盖了重要和实际的机器学习问题的一大部分,但它远非唯一的类型。 超参数优化仍然是研究的一个活跃领域… 目前,最常用的方法包括网格搜索、随机搜索和贝叶斯方法。 表3.6总结了迄今为止我们所看到的最常见的机器学习问题(回归、二进制分类和多类分类)的推荐方法:

下面我们将讨论将图片和语音作为输入来建立神经网络模型。