神经网络--搭建小实战和Seq的使用
搭建神经网络演示下图处理过程
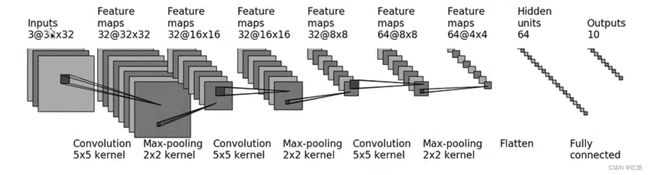
计算padding需要使用的公式

import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear
from torch.nn.modules.flatten import Flatten
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
# 新建一个卷积层 Inputs 3@32×32 inchannel:3 outchaanel: 32 kernel:5×5
# Convolution 5×5 kernel
#32*2*padding-4-1 = 27+2*padding = 31 --> padding = 2
self.conv1 = Conv2d(3, 32, 5, padding=2)
#最大池化
#Max-pooling 2×2 kernel
self.maxpool1 = MaxPool2d(2)
#卷积
#Convolution 5×5 kernel
self.conv2 = Conv2d(32, 32, 5, padding=2)
#最大池化
#Max-pooling 2×2 kernel
self.maxpool2 = MaxPool2d(2)
# 卷积
# Convolution 5×5 kernel
self.conv3 = Conv2d(32, 64, 5, padding=2)
#最大池化
#Max-pooling 2×2 kernel
self.maxpool3 = MaxPool2d(2)
#flatten展平
#Feature maps 64@4×4
#64×4×4 = 1024
self.flatten = Flatten()
#线性层:每个神经元与上一层所有神经元相连
#hidden units 64
self.linear1 = Linear(1024, 64)
#Outputs 10
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
test1 = Test()
#输入一个一维图像
#torch.ones()输入的都是1
#batch_size:64 3通道 32×32
input = torch.ones((64, 3, 32, 32))
output = test1(input)
print(output.shape)
结果:
torch.Size([64, 10])
Sequential 是一个时序容器。Modules 会以他们传入的顺序被添加到容器中。在神经网络搭建的过程中如果使用 Sequential,代码更简洁。
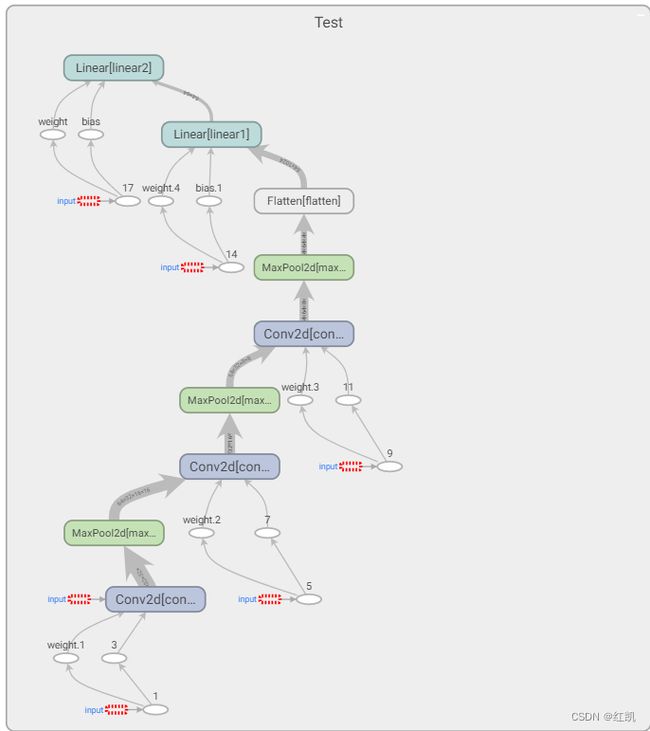
tensorboard显示计算图的具体信息
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Linear, Sequential
from torch.nn.modules import Flatten
from torch.utils.tensorboard import SummaryWriter
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
test1 = Test()
input = torch.ones((64, 3, 32, 32))
output = test1(input)
writer = SummaryWriter("logs_seq")
writer.add_graph(test1, input)
writer.close()
terminal中输入
tensorboard --logdir="logs_seq" --port=6007
结果:
Test(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
torch.Size([64, 10])