GEO数据库数据下载方法总结
GEO数据下载
GEO是生信分析经常用到的数据库。经常需要从中获取表达矩阵,平台信息,meta信息等,本博文总结了几种下载GEO数据的方法,各有优劣,实际应用过程中自行选择适合自己的。
方法一:直接从浏览器中下载,手动
以数据集GSE1001为例,
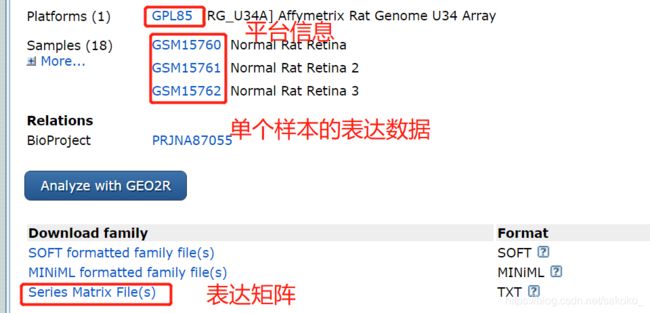
可以直接点击“Series Matrix Files”获取该样本txt格式的表达谱数据,一般我们认为这种处理过的表达谱数据是没有问题的,当然,具体情况具体分析。
打开下载的文件可以看到许多“#”开头的行,这些是注释信息,一般关注这些注释信息中的“data processing”,这行中可以看到数据是如何归一化和标准化的,以及是否已经经过log转化等。
之后我们需要下载平台数据以注释表达谱中的探针,点击“GPL85”,点击下图中的红框,

之后可以用R进行表达谱和平台数据的合并。
注意!到这里我们获得的只是初步的表达数据,还没有经过预处理,需要用R处理多个探针对应一个表达值,无对应symbol,以及合并多个探针对应一个symbol的情况后才可进行后续分析。
优缺点:
优点:该方法的优点是下载较快,数据也比较完整。
缺点:无法直接得到metadata,需要手动通过GEO2R获取,或在表达谱的注释信息中寻找。
方法二:代码下载,自动化
常用的R包有GEOquery,直接copy了“生信技能树”的代码,以下代码直接将表达谱封装成expression set对象,这有一个非常显著的优点即可以直接导入limma进行差异分析。
downGSE <- function(studyID = "GSE1009", destdir = ".") {
library(GEOquery)
eSet <- getGEO(studyID, destdir = destdir, getGPL = F)
exprSet = exprs(eSet[[1]])
pdata = pData(eSet[[1]])#表型信息,里面包含了需要的分组信息
write.csv(exprSet, paste0(studyID, "_exprSet.csv"))
write.csv(pdata, paste0(studyID, "_metadata.csv"))
return(eSet)
}
#导入limma包进行分析
library(limma)
design=model.matrix(~factor(sCLLex$Disease))
fit=lmFit(eSet,design)
fit=eBayes(fit)
options(digits = 4)
topTable(fit,coef=2,adjust='BH')
关于原始芯片数据的处理可参考以下文章link of original microarray
如果自己手头上已经有了表达谱数据和分组信息,也可以手动构造expression set对象:
metadata <- data.frame(labelDescription=c('SampleID', 'Disease'),
row.names=c('SampleID', 'Disease'))
phenoData <- new("AnnotatedDataFrame",data=meta,varMetadata=metadata)
myExpressionSet <- ExpressionSet(assayData=exprMatrix,
phenoData=phenoData,
annotation="hgu95av2")
> myExpressionSet
ExpressionSet (storageMode: lockedEnvironment)
assayData: 12625 features, 22 samples
element names: exprs
protocolData: none
phenoData
sampleNames: CLL11.CEL CLL12.CEL ... CLL9.CEL (22 total)
varLabels: SampleID Disease
varMetadata: labelDescription
featureData: none`在这里插入代码片`
experimentData: use 'experimentData(object)'
Annotation: hgu95av2
>
如果只是想获得某一GSE的metadata,可以通过GEOmetadb包获取:
library(GEOmetadb)
if(!file.exists('GEOmetadb.sqlite')) getSQLiteFile()
## 取决于网速哦
file.info('/path/GEOmetadb.sqlite')
con <- dbConnect(SQLite(),'/path/GEOmetadb.sqlite'))
#dbListTables(con2)
#dbListFields(con2,'gse')
GeoList = read.table("diabetes.GEO.list")
query = paste("select + from gsm where series_id in
( ' ", gsub(", ", " ', ' ", paste(Geolist[,1], collapse=",")," ')", seq=" ")
query
tmp = dbGetQuery(con2, query)
write.csv(tmp, "diabetes.GEO.meta.csv")
优缺点:
优点:自动化
缺点:取决于网速,下载慢