Stanford NLP2
Lesson 7:Neural Machine Translation
gradient vanishing
根据chain rule,如果前三个都很小,gradient vanish

Consider the gradient of the loss J ( i ) ( θ ) J^{(i)}(\theta) J(i)(θ) on step i,with respect to the hidden state h ( j ) h^{(j)} h(j) at step j
∂ J ( i ) ( θ ) ∂ h ( j ) = ∂ J ( i ) ( θ ) ∂ h ( i ) ∏ j ≤ t ≤ i ∂ h ( t ) ( θ ) ∂ h ( t − 1 ) = ∂ J ( i ) ( θ ) ∂ h ( i ) W h i − j ∏ j ≤ t ≤ i d i a g ( σ ′ ( W h h ( h − 1 ) + W x x ( t ) + b 1 ) ) \begin{aligned} \frac{\partial{J^{(i)}(\theta)}}{\partial{h^{(j)}}}&=\frac{\partial{J^{(i)}(\theta)}}{\partial{h^{(i)}}}\prod_{j\le{t}\le{i}}{\frac{\partial{h^{(t)}(\theta)}}{\partial{h^{(t-1)}}}}\\ &=\frac{\partial{J^{(i)}(\theta)}}{\partial{h^{(i)}}}W_{h}^{i-j}\prod_{j\le{t}\le{i}}diag(\sigma'(W_hh^{(h-1)}+W_xx^{(t)}+b_1))\\ \end{aligned} ∂h(j)∂J(i)(θ)=∂h(i)∂J(i)(θ)j≤t≤i∏∂h(t−1)∂h(t)(θ)=∂h(i)∂J(i)(θ)Whi−jj≤t≤i∏diag(σ′(Whh(h−1)+Wxx(t)+b1))
- diag()里面的是每个hidden state内部算法
- W h ( i − j ) W_h^{(i-j)} Wh(i−j)是自己乘自己(i-j)次,如果W自己本身很小,那么最后结果就会很小,gradient will vanish
- 只要W的largest eigenvalue<1,W就会shrink
- 只要W的largest eigenvalue>1,W就会gradient explode
-
matrix L2 norm ≤ \le ≤上方后面那块连乘
-
缺点
如果梯度消失,这样update的时候,只会有short-term的影响,long-term会被消弭到0

我们可以吧gradient看成past对future的影响
这样time t和time t+n之间就没有dependency,也会选错parameter
比如对于机器来说,之前很早出现了一个词,但是在很后面才需要predict,那么,由于gredient vanish,it is unable to predict similar long-distance dependencies -
EG:
- syntactic recency(correct)
The writer of the books is going to do sth - sequential reccency(incorrect)
The writer of the books are going to do sth
由于gradient vanishing,RNN-LM倾向于学习后面那种错误的(因为真正有关的单词离得远)
- syntactic recency(correct)
gradient explode
θ n e w = θ o l d − α J ′ ( θ ) \theta^{new}=\theta^{old}-\alpha J'(\theta) θnew=θold−αJ′(θ)
这样更新会take a large step and result will become Inf/Nan
Solution:Gradient clipping
如果我们把一个gradient normalization之后,还是>某个threshold,我们就要scale it down before we applying SGD
if g ≥ t h r e s h o l d g\ge threshold g≥threshold
g = t h r e s h o l d ∣ ∣ g ∣ ∣ g g=\frac{threshold}{||g||}g g=∣∣g∣∣thresholdg
方向不变,只不过scale变小

LSTM
h ( t ) = σ W h h ( t − 1 ) + W x x ( t ) + b h^{(t)}=\sigma{W_hh^{(t-1)}}+W_xx^{(t)}+b h(t)=σWhh(t−1)+Wxx(t)+b
我们需要RNN能记住separate memory
- 所以需要long short term memory
- on step t,有一个hidden state h ( t ) h^{(t)} h(t)和cell state c ( t ) c^{(t)} c(t)
- both are n-length
- cell stores long-term info
- LSTM can erase write and read(经由gate来决定,gate也是n-lengh vector)
他们可以是open(1),closed(0),或者是中间的值 - 这些门是dynamic(动态的),由current text compute得

- forget gate
从previous cell gate,决定哪些要被保留,哪些要被forget
f ( t ) = σ ( W f h ( t − 1 ) + U f x ( t ) + b f ) f^{(t)}=\sigma{(W_fh^{(t-1)}+U_fx^{(t)}+b_f)} f(t)=σ(Wfh(t−1)+Ufx(t)+bf) - input get
控制哪部分new cell content要被写入cell
i ( t ) = σ ( W i h ( t − 1 ) + U i x ( t ) + b i ) i^{(t)}=\sigma{(W_ih^{(t-1)}+U_ix^{(t)}+b_i)} i(t)=σ(Wih(t−1)+Uix(t)+bi) - output gate
控制cell哪部分会被输出
o ( t ) = σ ( W o h ( t − 1 ) + U o x ( t ) + b o ) o^{(t)}=\sigma{(W_oh^{(t-1)}+U_ox^{(t)}+b_o)} o(t)=σ(Woh(t−1)+Uox(t)+bo) - new cell content
这是要被写入cell的content,基于previous state和current input
c ^ ( t ) = t a n h ( W c H ( t − 1 ) + U c x ( t ) + b c ) \hat{c}^{(t)}=tanh(W_cH^{(t-1)}+U_cx^{(t)}+b_c) c^(t)=tanh(WcH(t−1)+Ucx(t)+bc)
步骤:
- 选一部分previous的来进行forget,并且把new cell content作为Input,一部分输入
c ( t ) = f ( t ) ∗ c ( t − 1 ) + i ( t ) ∗ c ^ ( t ) c^{(t)}=f^{(t)}*c^{(t-1)}+i^{(t)}*\hat{c}^{(t)} c(t)=f(t)∗c(t−1)+i(t)∗c^(t)
这里是element-wise product, f ( t ) = 0 f^{(t)}=0 f(t)=0,说明全忘 - 最终选择输出
h ( t ) = o ( t ) ∗ t a n h c ( t ) h^{(t)}=o^{(t)}*tanhc^{(t)} h(t)=o(t)∗tanhc(t)

LSTM doesn’t guarantee no gradient vanishing/explode
2019年Transformaters已经become more dominant than LSTM
GRU(Gated Recurrent Units)
another way of LSTM
使得LSTM更simple,因为算起来更简单(fewer parameters),更容易retain info from long-term
on step t,有一个hidden state h ( t ) h^{(t)} h(t)和input x ( t ) x^{(t)} x(t)
- update gate
控制哪部分hidden state会被update/preserved
u ( t ) = σ ( W u h ( t − 1 ) + U u x ( t ) + b u ) u^{(t)}=\sigma{(W_uh^{(t-1)}+U_ux^{(t)}+b_u)} u(t)=σ(Wuh(t−1)+Uux(t)+bu) - reset gate
控制哪部分previous hidden states会被用来计算new content(哪部分是useful)
r ( t ) = σ ( W r h ( t − 1 ) + U r x ( t ) + b u ) r^{(t)}=\sigma{(W_rh^{(t-1)}+U_rx^{(t)}+b_u)} r(t)=σ(Wrh(t−1)+Urx(t)+bu)
步骤
- new hidden state content
reset gate选择prev hidden state的有用部分,用这个和current input一起计算new hidden content
h ^ ( t ) = tanh ( W h ( r ( t ) ∗ h ( t − 1 ) ) + U h x ( t ) + b h ) \hat{h}^{(t)}=\tanh{(W_h(r^{(t)}*h^{(t-1)})+U_hx^{(t)}+b_h)} h^(t)=tanh(Wh(r(t)∗h(t−1))+Uhx(t)+bh) - hidden state
update gate同时控制什么会被从prev hidden state保存下来,并且什么会被更新到new hidden state content
h ( t ) = ( 1 − u ( t ) ) ∗ h ( t − 1 ) + u ( t ) ∗ h ^ ( t ) h^{(t)}=(1-u^{(t)})*h^{(t-1)}+u^{(t)}*\hat h^{(t)} h(t)=(1−u(t))∗h(t−1)+u(t)∗h^(t)
Gradient Vanishing/Explode只是RNN中的问题吗?
实际上对于任何neural architecture,尤其是deep ones,这都是一个问题
- Solution:Skip connections
- 直接加direct connections,跳过一些层(比如Residual connections,ResNet)
- identity connection,参数保持不变
- Dense Connections(DenseNet)

- Highway connections
control balance between x and f(x),比如 o u t p u t = ( 1 − g a t e ) ∗ x + g a t e 8 ∗ f ( x ) output=(1-gate)*x+gate8*f(x) output=(1−gate)∗x+gate8∗f(x)

有时候会发现shallow layers已经表现很好,deeper反而使得performance become worse,那么我们到浅层其实就可以停止了
RNN是个特别unstable的结构,原因在于repeated multiplication by the same matrix
Bidirectional RNNs
EG:This movie is terribly exciting
以terribly为界,如果只看左边,那么会判断sentiment is bad
但是看右边,则会判断sentiment is good
所以需要我们双向来看(正序和倒序)
- 结构
我们有两个RNN,一个是从左到右forward RNN,一个是从右到左backward RNN,都是将句子encode

然后把他们的hidden state合并起来,这样terribly就同时拥有了两个方向的Info
on timestep t- Forward RNN
h ( t ) = R N N F W ( h ( t − 1 ) ( t ) , x ( t ) ) h(t)=RNN_{FW}(h^{(t-1)}(t),x^{(t)}) h(t)=RNNFW(h(t−1)(t),x(t)) - Backward RNN
h ( t ) = R N N F W ( h ( t + 1 ) ( t ) , x ( t ) ) h(t)=RNN_{FW}(h^{(t+1)}(t),x^{(t)}) h(t)=RNNFW(h(t+1)(t),x(t)) - Concatenated hidden state
h ( t ) = [ h f w ( t ) , h b w ( t ) ] h(t)=[h^{fw}(t),h^{bw}(t)] h(t)=[hfw(t),hbw(t)]
- Forward RNN
只有当我们access to entire sequence,我们才能用;像LM就不行,因为我们只能接触到left part
bidirectionality is powerful,should use it by default
BERT(Bidirectional Encoder Representations from Transformers)
ptr-trained contextual model,built on bidirectionality
Multi-layer RNNs(Stacked RNNs)
- Intuition:
Lower RNNs should compute lower-level features,high RNNs should compute higher-level features

只要我们可以access to whole sequence,我们也可以用bidirection
在Pytorch中,总是先把layer 1算完,再算layer 2,然后一层层上去;也因为如此,不能parallel,very expensive to compute
Google的论文中,对于Neural Machine Translation,2 to 4 layers is good for encoder RNN;4 layers is best for decoder RNN
但是如果加了skip-connections/dense-connections,需要加深,比如8层
但是对于BERT(Transformer-based),可能会需要24层
Lesson 8
- Machine Translation(MT)
translate a sentence x in source language to a sentence y in target language
Statistical Machine Translation
learn a probabilistic model from data
want to find best English sentence y given French sentence y
arg max y P ( y ∣ x ) \argmax_y{P(y|x)} yargmaxP(y∣x)
利用Bayes Rules 来分解为两部分
= arg max y P ( x ∣ y ) P ( y ) =\argmax_y{P(x|y)P(y)} =yargmaxP(x∣y)P(y)
前半部分是Translation model,展示how words/phrases should be translated(fidelity);
后半部分是Language model,展示how to write good English(fluency)
How to train
我们需要大量parallel data,比如Rousetta Stone,同时用三种语言写
- 但是怎么学P(x|y)?
再分解: P ( x , a ∣ y ) P(x,a|y) P(x,a∣y),a是alignment,一个word-level correspondence between two languages- 可以是多对一
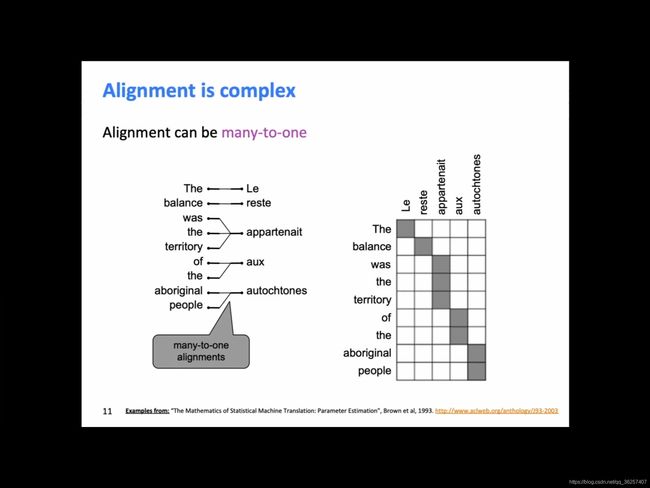
- 也可以是一对多

那种一个词对应多个词的,我们称之为fertile word,因为它有很多children
- 可以是多对一
- 还可以是多对多

所以我们学的P(x,a|y)是有多种可能性的
- prob of particular words aligning(一对一),
- 这两个词how often aligned?比如right翻译成“对”比翻译成“右”的概率更大
- 也和position in the sentence有关,如果两个词都出现在句子末尾,那么align的可能性就更大;但一个在开头,一个在结尾,align的概率就会小很多
- prob pf particular words have particular fertility(对多个单词)
- prob of particular fertility have particular fertility(多对多)
怎么计算
how to compute this argmax
= arg max y P ( x ∣ y ) P ( y ) =\argmax_y{P(x|y)P(y)} =yargmaxP(x∣y)P(y)
- Brute method:
Enumerate every possible y(包括任意长度,会设一个上限)但too expensive - Solution:
Use a heuristic search algorithm to search for the best translation,然后回discard hypotheses with 过低的prob,这样达到了prune tree(剪枝)效果
我们称之为decoder
我们会把所有词可以翻译的align列出来,然后每次选择的时候,排除概率最小的来进行选择

总之,SMT需要很多东西
1. feature engineering
2. extra resources
3. human effort
Neural Translation Machine
do machine translation with a single neural network
neural network is called sequence-to-sequence(seq2seq),包含two RNNs
Encoder RNN
the encoding of the source sentence is going to be the final hidden state of this encoder RNN,然后我们把这个encoding of the source sentence传给Decoder RNN
1. Decoder RNN是个conditional language model(根据input来决定output,而且是predict next word of the former sentence)
2. 我们需要French和English两种语言的word vector
这种sequence to sequence不止可以用来翻译
- Summarization(long text to short text)
- Dialogue(previous utterances to next utterance)
- Parsing(input text to output pare as sequence)
- Code generation(natural languae to Python code)
- 在test time时(training time时不一样)
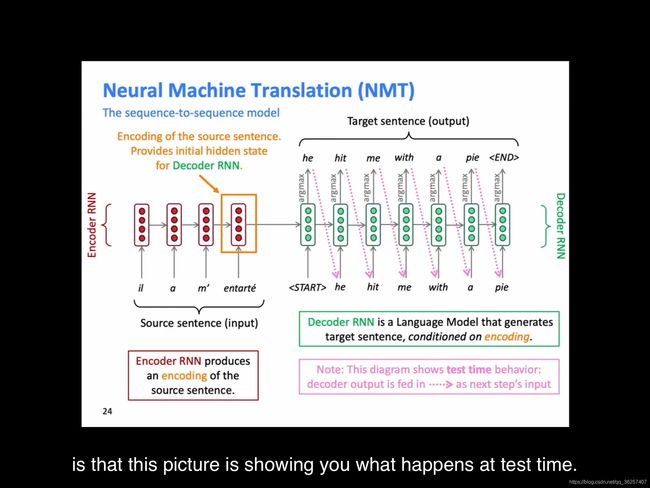
- NMT calculates p(y|x)
P ( y ∣ x ) = P ( y 1 ∣ x ) P ( y 2 ∣ y 1 , x ) P ( y 3 ∣ y 1 , y 2 , x ) . . . P ( y T ∣ y 1 , . . . , y T − 1 , x ) P(y|x)=P(y_1|x)P(y_2|y_1,x)P(y_3|y_1,y_2,x)...P(y_T|y_1,...,y_{T-1},x) P(y∣x)=P(y1∣x)P(y2∣y1,x)P(y3∣y1,y2,x)...P(yT∣y1,...,yT−1,x)
最后一个概率是probability of next target word,given target words so far and source sentence x
how to train
我们需要大量parallel corpus
- 把source sentence feed进encoder RNN,把target sentence feed进decoder RNN
- decoder RNN的每一步,都要produce the probability distribution of what comes next
- 这样我们就能计算Loss,Loss和unconditional LM一致(cross entropy/negative likelihood of true word)
- 求total loss平均数

这是个end-to-end system,原因在于backpropagation中,loss发生在一个end端,然后我们要把它传给beginning of the encoder RNN,那是另一个end。即loss flow过了整个system
-
training和test的区别
在test time,我们是把生成的下一个词输入给decoder,来生成下一个
在training time,我们把target sentence输入给decoder,所以不存在END字符输入给decoder导致无法计算loss -
在实际corpus中,input和output的长度是not fixed,是会有多种变化的。
In pracitical,我们会把short sentence pad to some predefined maximum length(补零)
maximum length可能是length of maximum example -
train them separately
比如训练English encoder,再训练另几门语言的decoder,这样就可以将他们匹配,而不是训练end-to-end
目前有人在research这种idea -
Word vector和corpus的对应关系
我们的word vector不一定要和corpus一致(即word vector不是通过这些corpus训练出来的),可以利用别人的;当然,Initialize word vector close to 0,然后开始训练也是可以的
Greedy decoding
在每次generate target sentence时,只选argmax on each step of the decoder
- 缺点
这种选法只是选择了关于这个词的argmax,而不是关于这个句子的argmax
比如he hit me with a pie,如果用greedy decoding的话,会翻译成he hit a,这样我们就没法翻了,也没法往回走来修改
- Solution
- Exhaustive search decoding
搜索所有翻译中最好的那个翻译,a translation can maximize p(y|x)
在each step of the decoder,我们需要track vocab-size possible partial translation
too expensive - Beam search decoding
在decoder的each step,track k个most probable partial translations(hypotheses),这里可以是high score, s c o r e = log p r o b score=\log{prob} score=logprob
s c o r e ( y 1 , . . . , y t ) = log P L M ( y 1 , . . . , y t ∣ x ) = ∑ i = 1 t log P L M ( y i ∣ y 1 , . . . y i − 1 , x ) score(y_1,...,y_t)=\log{P_{LM}(y_1,...,y_t|x)}=\sum_{i=1}^{t}{\log{P_{LM}(y_i|y_1,...y_{i-1},x)}} score(y1,...,yt)=logPLM(y1,...,yt∣x)=∑i=1tlogPLM(yi∣y1,...yi−1,x)
但all score are negative,higher score is better
只考虑最有可能的k个(k是beam size,一般是5-10之间)
beam search不保证可以找到optimal solution,比起exhaustive search更efficient


当最后找到分数最高的,backtrack原来整句话
- beam search stop criterion
在greedy searching中,一般是keep decoding until model生成一个END token
但beam search decoding,不同的假设是在不同timestamp生成END token。
所以实际中,当一个假设生成END,我们就认为这个假设在翻译完了,把它放到一个collection中,继续去beam search别的可能性
两种结束方法:
1. 设定在timestamp T,这个T是predefined
2. 当至少有N个已经completed的beam search句子
- Exhaustive search decoding
现在我们有一列completed句子,现在如何选?
每个句子都有一个score,而根据得分体系,全是Log,全是负的,那么最后只会选择最短
所以我们需要normalize by length
1 t ∑ log P L M ( y i ∣ y 1 , . . . , y i − 1 , x ) \frac{1}{t}\sum{\log{P_{LM}(y_i|y_1,...,y_{i-1},x)}} t1∑logPLM(yi∣y1,...,yi−1,x)
- 我们train的时候是要用END token,而不是单纯把句子Input
- 我们在beam search的时候,每次都是比较长度相同的句子,所以不用length normalization
NMT的优点
- 表现更好
- 更流畅
- 对于context的利用更好
- 更能找到句子的phrase similarity,这样便于翻译它们
- single neural network可以end-to-end optimize
- 没有sub-components需要单独被优化
- 需要更少的human engineering effort
- 不需要feature engineering
- 对于所有language pairs,都是采用同样的方法
NMT的缺点
- less interpretable(更难被人理解)
- hard to debug
- difficult to control
- 我们没法specify some rules for the network to follow
- 安全考虑,我们没法控制它们不说bad words
How to evaluate Machine Translation
- Biligual Evaluation Understudy(BLEU) useful but imperfect
会拿机器翻译的结果去和一个/多个人工翻译的结果去比较,得到一个similarity score based on- n-gram precision(1,2,3,4-grams)
- 对于果断的机翻结果,加一个penalty(因为n-grams不会punish)
不完美在于翻译一个句子有很多方法,所以一个好的翻译会得到一个很低的BLEU score只是因为它有很低的n-grams overlap with human translation
但翻译的问题还没解决:
- 比如要翻译的词没遇到过(out-of-vocab)
- Domain mismatch between tran and tst data(拿维基百科的数据来训练,但是来翻译人们的聊天)
- Maintain context over longer text
比如要要翻译长文,会希望之前出现过的东西在下次翻译中能被用到/引用 - Low-resource language pairs(网上的数据太少)
- 对于一些语言,有时候语言只有Bible,所以翻译的就会很奇怪
- 比如马来语中‘他’不分性别,但是英语中会分,如果训练集中有大量的female nurses,那么翻译就会自动把马来语中的他翻译成she
Attention
由于句子压缩为一个vector,所以必定会有一部分信息丢失
核心思想:在decoder的每一步,都有一个direct connections to the encoder,这样可以关注source sentence的特定一部分
- decoder的第一个hidden state和encoder里的每一个hidden state进行dot product,得到一个atttention score(是score不是scale)
- 然后我们对他们进行softmax,得到prob distribution

- 我们会发现He的得分很高,是因为在target sentence里,第一个词就应该翻译为he(相当于一个mask,盖住了其余不重要的部分)
- 我们会得到一个weighted sum,weight就是softmax之后的attention distribution,这样分配了对于每个hidden state,我们应该给多少attention

- 然后我们会用attention output来影响我们next word的prediction,attention output和decoder hidden state合并,得到一个关于下一个词的prob distribution

- 然后我们可以从总sample出一个词,然后接着,我们用第二个decoder hidden state来和之前的乘,继续得到attention output,继续来产生下一个

Attention Equation
- encoder hidden states h 1 h_1 h1, h 2 h_2 h2, h n h_n hn
- on timestamp t, decoder hidden state s t s_t st
- attention score e t e^{t} et for this step
e t = [ s t T h 1 , . . . , s t T h n ] e^t=[s_t^Th_1,...,s_t^Th_n] et=[stTh1,...,stThn] - 用osftmax来得到attention distribution α t = s o f t m a x ( e t ) \alpha^{t}=softmax(e^t) αt=softmax(et)
- 用 α t \alpha^{t} αt来计算weighted sum of encoder hidden states to get attention output α t \alpha_t αt
α t = ∑ t = 1 N α i t h i \alpha_t=\sum^{N}_{t=1}\alpha_i^{t}h_i αt=t=1∑Nαithi - 最后把attention output α t \alpha_t αt和decoder hidden state s t s_t st concatenate起来,并且proceed in the non-attention seq2seq model [ α t ; s t ] [\alpha_t;s_t] [αt;st]
Attention优点
- improve NMT performance
- allow decoder to focus on certain part of the source
- attention solve the bottleneck problem
- 可以让info穿过去,不至于因为压缩而有所损失
- help with vanishing gradient problem
- provide shortcut to faraway states
- 提供了interpretability
- 可以看出decoder在关注什么部分

- get some soft alignment for free,我们这里没有告诉他们alignment该如何利用loss来改善alignment,network learn the alignment by itself
- 可以看出decoder在关注什么部分
attention可以被广泛应用于deep learning中
attention的更广泛定义:
给一列values,给一个query vector,我们可以计算他们的weighted sum(selective summary of the information contained in the values)。关键:每个值我们的关注度是不同的
attention可以得到fixed-size representation of an arbitrary set of representations(the value),dependent on some other representation
attention variants
区别在于multiple ways to compute attention score e e e
- Basic dot-product(假设values和query的size要一样, d 1 = d 2 d_1=d_2 d1=d2)
e i = s T h i e_i=s^Th_i ei=sThi - multiplication attention(W是weifht matrix,我们要学到这个W)
e i = s T W h i e_i=s^TWh_i ei=sTWhi - Additive attenion
W 1 W_1 W1 [ d 3 ∗ d 1 ] [d_3*d_1] [d3∗d1]和 W 2 W_2 W2 [ d 3 ∗ d 2 ] [d_3*d_2] [d3∗d2]是weight matrices,v是weight vector, d 3 d_3 d3是超参数attention dimensionality
括号内得到两个single score
e i = v T tanh W 1 h i + W 2 s e_i=v^T\tanh{W_1h_i+W_2s} ei=vTtanhW1hi+W2s
Lesson 9
Some tips on project
对于一些NLP model,除了human evalutaion,我们还需要一些automatic evalutaion metric,比如loss/score,然后用backprop来改善
要找machine translation的parallel corpus:https://universaldependencies.org
Gated Recurrent Unit
adaptive shortcit connection
- 用一个跨度更大的connection来做链接
- Candidate Update
h t ^ = tanh ( W [ x t ] + U h t − 1 + b ) \hat{h_t}=\tanh{(W[x_t]+Uh_{t-1}+b)} ht^=tanh(W[xt]+Uht−1+b) - Update Gate
u t = σ ( W u [ x t ] + U u h t − 1 + b u ) u_t=\sigma(W_u[x_t]+U_uh_{t-1}+b_u) ut=σ(Wu[xt]+Uuht−1+bu)
f ( h t − 1 , x t ) = u t ∗ h t ^ + ( 1 − u t ) ∗ h t − 1 f(h_{t-1},x_t)=u_t*\hat{h_t}+(1-u_t)*h_{t-1} f(ht−1,xt)=ut∗ht^+(1−ut)∗ht−1

- Candidate Update
- 但有时候我们想要get rid of some part,所以我们还需要一个排除用的gate
- Reset Gate
r t = σ ( W r [ x t ] + U r h t − 1 + b r ) r_t=\sigma(W_r[x_t]+U_rh_{t-1}+b_r) rt=σ(Wr[xt]+Urht−1+br) - Candidate Update(变为)
h t ^ = tanh ( W [ x t ] + U ( r t ∗ h t − 1 ) + b ) \hat{h_t}=\tanh{(W[x_t]+U(r_t*h_{t-1})+b)} ht^=tanh(W[xt]+U(rt∗ht−1)+b)
- Reset Gate
-
对比
在之前,我们需要读所有的register h,然后update所有register
现在,选a subset of registers,设为r,然后reset gate对他们control,ignore others;
再选a subset of registers,设为u,只update他们,其余的设为不变; -
LSTM和GRU对比
LSTM是 c t c_t ct由 f t f_t ft和 i t i_t it两扇gate控制的,GRU则是只由 u t u_t ut一扇gate控制

这里的相加则是LSTM没有gradient vanishing的原因

-
计算中的实际问题

每一个hidden state都要和每一row去进行点乘,已获得softmax。
如果词特别多,计算就特别慢,62.5%的算力都会花费在计算softmax上 -
word generation solution
限制词量,50k的词一般就可以cover大多数的词了,而不是全部计算
对于没有见过的词,统一给他们一个称谓——UNK,然后给它们一个new word vector,但这样翻译的结果也是一堆UNKs
- Solution
- hierarchical softmax:tree-structured vocabulary
- Noise-contrastive estimation:binary classification
训练起来更快 - Train on a subset of the vocab at a time,test on the set of possible translations
- 利用attention to work how 你在翻译什么,比如用dictionary look up

关于模型训练
我们一般都是训练一次,得到一个分数,好,留着,不好,丢了
但有时候得分只是碰巧高,如果我们顺着一次‘碰巧’去不断迭代,最后只会overfit
- solution:
设置两个development set,在第一个测试完之后,再到第二个上测试,如果变好了,那才是真变好了
test data只有在最后算score的时候才用(test data只用来作evaluate)
就比如kaggle的数据集,最后会有一个secret dataset,我们都不会在它上面train,但它是用来评分的
- 模型总归是从简单开始训练,慢慢变复杂
- 拿少量数据来训练,比如甚至8 examples就可以
Lesson 10 Question Answering
搜索引擎的返回a list of document已经不能满足人们的搜索需求了
人们需要search engine能直接返回提问结果
分成两步:
- 找到documents that might contain an answer
- 找到这个答案,答案可能在文章里,也可能就是一篇文章
Reading Comprehension
- MCTest
最早的模型: p a s s a g e ( P ) + q u e s t i o n ( Q ) → a n s w e r ( A ) passage(P)+question(Q)\rightarrow answer(A) passage(P)+question(Q)→answer(A)

Document Processing可以提取出哪个paragraph更可能contain answers,然后有ranking func来排他们的可能性
Name Entity Recognition可以判别出paragraph中间的entity,然后system match entity with the question type
人们喜欢用Factoid Answer Processing来处理answer is a named entity
- 以SQuAD的数据为例
answer is always a subsequence of words from the passage(段子中的某一段词),所谓的extractive question answering-
但取多长的句子是合适的?
这边给了三个human answer,只要答案在其中一个,就算对 -
how to evaluate?
- 如果答案在correct的三个内,就得1分,否则0分,最后算正确率
- F1-metric(比第一种更好)
把所有paragraph&三种答案认为是bag of words
计算 p r e c i s i o n = s y s t e m s p a n 三 种 g o l d e n s p a n precision=\frac{system \, span}{三种golden \, span} precision=三种goldenspansystemspan, r e c a l l = 三 种 g o l d e n s p a n s y s t e m s p a n recall=\frac{三种golden \, span}{system \, span} recall=systemspan三种goldenspan
harmonic mean F1= 2 P R P + R \frac{2PR}{P+R} P+R2PR
F1 is more reliable taken as primary,有效避免了artifact对于答案长短的影响
两种metric都会ignore标点和(a,an,the)
-
SQuAD 2.0
最初的版本是所有的question都有答案,这个答案在paragraph里
在2.0版本里, 1 3 \frac{1}{3} 31的question没有answer, 1 2 \frac{1}{2} 21的dev/test questions没有答案
如果no answer,你也回答no answer,那么你会得1分
SQuAD的优缺点
- limitation
- answers are a span from the passage,这也限制了提问的种类。比如你不能拿yes-no question来提问,也不能拿implicit question来提问
- 构成dataset的时候,组织者要求提一些看似relate to paragraph,但实际并不能被回答的question,这样人们总归会以和paragraph有关的句子来提问。这就导致了overlap,比如词有重叠,structure有重叠
但现实中人们在浏览器中搜索时,输入单词时的思考模式和这个不同,人们会输一些distinct words - 实际上是在找sentence match questions,但实际上最难的事multiple sentences combined together
- advantages
- well-targeted,clean,well-structed
Stanford Attentive Reader
- 先把question转化为word vector
- run a LSTM forward,再run a LSTM backward(bi-LSTM可以让句子发现前后关联)
- grab the end states of both LSTMs,concatenate them into a vector of dimension 2D,这个就代表了question

- 对于处理Passage也是一样,也是bi-LSTM

- 但是我们需要用question representation,这就需要我们利用attention机制,attention equation还是一样,我们需要计算每个单词的 bi-LSTM representation 和 question 之间的attention score
- 然后我们要根据softmax来把answer的start/end 全都Predict出来

尽管可能整个答案中,最中间才是正确答案,但是bilinear matrix会把答案长度推向两边,推向extreme以获得最长的句子
Stanford Attentive Reader++
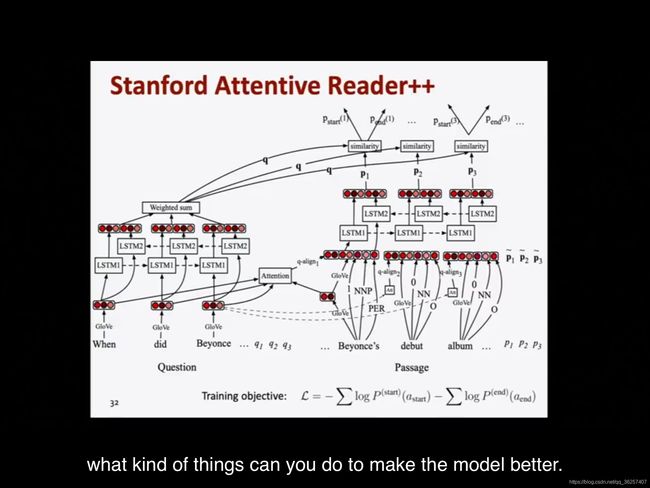
主要有两点改动
- 还是bi-LSTM,但是我们可以利用all states in LSTM by using weighted sum
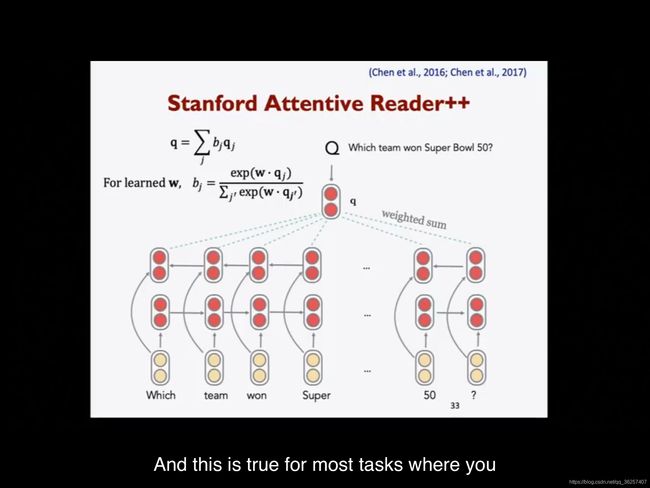
- 在passage representation有所改变,word vector由以下几部分构成
- word vector(源于GloVe 300d)
- named entity recognizer & speech tagger(POS&NER tags),由于这些值都比较小,所以我们将其one-hot encoded
- Word frequency(unigram probability)
- Exact match:这个词是否出现在question,用1bit表示三种匹配情况(exact match/uncased match,/emma match,lemma match是指drive和driving的区别)
- Aligned question embedding(利用word vector similarity来计算question和answer的similarity)
f a l i g n ( p i ) = ∑ j a i , j E ( q j ) f_{align}(p_i)=\sum_ja_{i,j}E(q_j) falign(pi)=j∑ai,jE(qj) q i , j = exp ( α ( E ( p i ) ) ∗ α ( E ( q j ) ) ) ∑ j ′ exp ( α ( E ( p i ) ) ∗ α ( E ( q j ′ ) ) ) q_{i,j}=\frac{\exp({\alpha(E(p_i))*\alpha(E(q_j)))}}{\sum_{j'}\exp({\alpha(E(p_i))*\alpha(E(q'_j)))}} qi,j=∑j′exp(α(E(pi))∗α(E(qj′)))exp(α(E(pi))∗α(E(qj)))
这里的 α \alpha α是simple one layer FFNN
BiDAF

- central idea
The Attention Flow layer - idea
attention should flow both ways(from the question to the context,from the context to the question) - make similarity matrix(with w of dimension 6d,这个w是习得的)
对于每个passage word,question word,我想算出一个similarity score,这是一个很好地找question-paragraph pair的机会
S i j = w s i m T [ c i ; q j : c i ∗ q j ] S_{ij}=w^T_{sim}[c_i;q_j:c_i*q_j] Sij=wsimT[ci;qj:ci∗qj]
最后那个是Hadamard product - Context-to-Question attention:query words are most relevant to each context word
α i = s o f t m a x ( S i , : ) \alpha^{i}=softmax(S_i,:) αi=softmax(Si,:)
a i = ∑ j = 1 M α j i q j a_i=\sum^M_{j=1}\alpha_j^iq_j ai=j=1∑Mαjiqj - 然后再从reverse direction开始做
- Question-to-Context(Q2C) attention:
m i = max j S i j m_i=\max_jS_{ij} mi=jmaxSij
β = s o f t m a x ( m ) \beta=softmax(m) β=softmax(m)
c ′ = ∑ i = 1 N β i c i c'=\sum^N_{i=1}\beta_{i}c_i c′=i=1∑Nβici - For each passage position,output of BiDAF is
b i = [ c i ; a i ; c i ∗ a i ; c i ∗ c ′ ] b_i=[c_i;a_i;c_i*a_i;c_i*c'] bi=[ci;ai;ci∗ai;ci∗c′]
然后是一个modeling layer:Another 2-layer BiLSTM over the passage
FusionNet
- Attention func
MLP(additive) form:
s i j = s T tanh ( W 1 c i + W 2 q j ) s_{ij}=s^T\tanh{(W_1c_i+W_2q_j)} sij=sTtanh(W1ci+W2qj)
Bilinear(Product) form:
s i j = c i T W q j s_{ij}=c_i^TWq_j sij=ciTWqj
然后我们可以把W分解成两个low rank的matrices( U T V U^TV UTV)来降低complexity,然后一路分,分解到diagonal
s i j = c i T U T V q j s_{ij}=c_i^TU^TVq_j sij=ciTUTVqj
s i j = c i T W T D W q j s_{ij}=c_i^TW^TDWq_j sij=ciTWTDWqj
s i j = R e l u ( c i T W T ) D R e l u ( W q j ) s_{ij}=Relu(c_i^TW^T)DRelu(Wq_j) sij=Relu(ciTWT)DRelu(Wqj)

Lesson 11 Convolutional Networks for NLP
1D convolution for text
sentence size shrunk(原来长度7,现在长度5),不同的filter有不同的过滤效果,比如sentence是否polite

为了避免size shrink,所以要加0 padding(上下各+1个)

同理,三个kernel就能使维度变为3

Max pooling
输出每列最大值。
很多时候max pooling更好,因为很多时候word vector是sparse matrix(大多数的词都没有特别大的用处)

Average pooling

batch_size=16
word_embed_size=4
seq_len=7
input=torch.randn()batch_size,word_embed,seq_len)
conv1=Conv1d(in_channels=word_embed_size,
out_channels=3,
kernel_size=3,
padding=1) #构建layer参数
hidden1=conv1(input)
hidden2=torch.max(hidden1,dim2) #第二层选择max pooling
还有选择stride=2
k-max pooling
有的时候发现句子不止一次被激发了,那么就要把几次最大值都记录下来
然后最后的顺序不是他们的值从大到小的顺序,而是他们的位置顺序
dilation convolution
跳过一些行来进行Matrix计算,比如dilation=2,那就选1,3,5来进行计算,然后是2,4,6
可以保证参数没有变多的情况下,see more at once

Single Layer CNN for sentence Classification:Yoon
pos/neg sentiment of sentence classification
- start with word vector k-length(句子是把这些k-length的句子concatenate起来),选词从 x i x_i xi到 x i + j x_{i+j} xi+j
- Convolution Layer 是个vector,因为word vector是1维(filter size =2/3/4)

这个filter被应用在所有window上 - 为了用filter computer feature(one channel)
c i = f ( w T x i : i + h − 1 + b ) c_i=f(w^Tx_{i:i+h-1}+b) ci=f(wTxi:i+h−1+b)

- 右边padding h-1个
- max pooling layer(capture most important activation)
- different kernel size have different output
- 在实际中
- 他copy了word vector:一组freeze,一组随着training,word vector也在变
- 对两组都先加上 c i c_i ci,用了size为3、4、5,每个size里有100个feature
- 再做了Max pooling,每个channel得到一个value(这样就会有300个vector聚集在一个max点)
- 最后一层Layer用softmax: y = s o f t m a x ( W ( S ) z + b ) y=softmax(W^(S)z+b) y=softmax(W(S)z+b)

Regularization
- Dropout
有了dropout,可以避免过拟合,或者对于一些特定数据过于匹配
y = s o f t m a x ( W S ( r ∗ z ) + b ) y=softmax(W^{S}(r*z)+b) y=softmax(WS(r∗z)+b) - L2 norm
对于each class(row in softmax weight W),采取了L2 norm,constrain to a fixed number s(hyperparameter)
如果weight太大( ∣ ∣ W c ( S ) ∣ ∣ ||W_c^{(S)}|| ∣∣Wc(S)∣∣>s),就要rescale it as to ∣ ∣ W c ( S ) ∣ ∣ ||W_c^{(S)}|| ∣∣Wc(S)∣∣=s
- hyperparameter

gate units unsed vertically(垂直应用)
-
Residual layer
跳过一层/几层,会需要padding,因为需要the same size
中间被跳过的是 δ \delta δ,研究如果我们什么都不做,可以得到怎样的deviation

-
Highway layer
move an identity to skip non-linear unit(跳过激活层)
F ( x ) T ( x ) + x C ( x ) F(x)T(x)+xC(x) F(x)T(x)+xC(x) -
Batch Normalization
类似Z-score,把mean变为0,variance变为 σ \sigma σ
1*1 convolutions
- kernel size=1
- give us a fully connected linear layer across channels(不像fully connected layers,它加few oarameters)
- 可以用来map from many channels to fewer channels
Application
- Translation
用CNN for encoding,RNN for decoding

- Learning character-level representations (learn word vector)

- Deep CNN for Text Classifcation
dominant model(LSTMs/CNN/Attention) are not deep,所以提出了这个VD-CNN

图片中都是几百*几百的像素,这里对于text,也用了1k characters来进行计算
然后传入了下一层convolutional block
人们在图像中,总是shrink image size,extend channels,这里对于text也一样
Convolutional Block

有时候做选择是,要深度一致才好比较
针对不同的数据,不同的pooling layer会有不同的表现,比如选AG时Convolution pooling layer好,但Amazon的数据时K-Max Pooling好
Quasi-Recurrent Neural Network
因为RNN很慢,而且parallelize badly,所以我们想把两者结合起来

把RNN中 t − 1 {t-1} t−1和 t t t放入max pooling layer
我们不可能get true recurrent without penalty,这里做了一个pseudo recurrent
这种东西也可以用在别的deep network里
Lesson 12
linguistics fundamental
最基本的是phonetics,我们假定有一些distinctive,categorical units:phonemes(音素)/distinctive features
人的嘴巴可以发出无数种声音,但是人的语言不是这样的,它们只占其中的一小部分,非常distinguished;最简单的例子就是语言,人们把不同的声音归入不同的语言
The differences within a category shrink,between categories expand
英语中,发p这个音,人们通过voice spectrum上2个consonant(辅音)可以将p这个音认出来,而泰语中会需要3个
而有的词,比如cot和caught,则因为vowel(元音)相同,很难区分
part of word
然而p,b这些词并没有意义,所以我们要将他们组合,变成高一级的part of word
- un-fortun-ate:可以分解为几个部分,每个部分都有自己的意义
- un代表否定
- fortune代表好运
- ate是将其adj化
有想出将词变成tree状结构,结果建起来too hard

character n-grams
用来学习动词的parse tense(过去式),有的regular加ed即可,有个Irregular则要重复尾字母再加或者直接变形
这里用了sequence model(character trigram)
Words in writing system
- No word segmentation(比如中文,古希腊文)
- 分开的词也有不同
比如法语:Je vous ai apporte 虽然分开来写,但是是一个词
比如阿拉伯语,有的东西看的连在一起,但是是四个词
比如德语,如果几个词组成一个名词,那它会把它连起来写,中间没有空格,Lebensversicherungsgesellschaftsangestellter
Model below the word level
因为要处理large,open vocabulary,但很多语言都很复杂,很难处理
- 比如名字翻译,你需要根据新的语言系统,rewrite someone’s sound
- 比如随着互联网发展,很多拼写方法不follow canonical(传统) words,比如GOOOOOOOOOD!!!
- 或者缩写,I don’t care写为idc
- solution
- 文中还是有word的,建立一个system that word over words。但我们需要建立word representation for any character sequence(这就需要能够recognize character sequence that look familiar)
利用similiar spelling 去猜测有similar word vector - 直接在character sequence进行建模
writing system
分为多种
- Phonemic
靠拼就能直接发出来的音 - Fossilized phonemic(Eng)
发音基本上已经被固化 - Syllabic(音节的)/moraic:韩语
- Ideographic:中文
- 以上几种的混合:日语
Purely character-level NMT models
Czech语是个很好的实验体,因为有很多big horrible words
但是如果你把character放入LSTM内训练,训练很慢,最后生成结果也很慢
比如11-year-old,在Czech语中有专门的的词,但是如果不知道,那么翻译时就会变成
Fully Character-level Neural Network
Encoder:convolution 3/4/5 characters
Max Pooling:Stride=5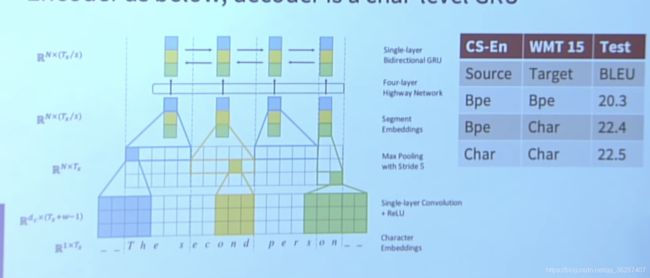
经过测试得,用word vector来训练,slope不陡;用character vector来训练,上升很快
Sub-word models
目前有两大trends
- 我们仍然用word model的那类模型,只不过用smaller units(word piece)
BPE(Byte pair encoding) - 用hybrid models,主要还是用word来构建模型,但是也会混杂入一些characters来一起构建representation
Byte Pair Encoding
这只是一个compresssion algorithm,不是neural network
infinitive effective vocabulary while working with a finite vocobulary
找Most frequent sequence of two bytes,把找到的值加入possiblt value dictionary中,这样就可以shrink the length of the sequence
这样我们就可以不那么严格的用bytes来代替characters/characters n-grams
这种方法有点像unicode,但对于中文来说,可能需要20k的unicode。这种时候用UTF-8,三个byte代表一个字,然后,只用利用common常见的sequence即可
- 那么most frequence ngram怎么选?
bottom-up开始构建- unigram vocabulary:全是一个字母的
- 找most frequent pairs(2个字母的,3个字母的)
总之优先找频率高的,然后再找慢慢变长的


- 然后等找了很多之后,再来确定要多大的vocabulary size(比如8k)来训练模型
当然,这里面可能会有很多a the之类的 - Do deterministic longest piece segmentation of words,我们像用word做machine translation一样把这些东西run through他们
- 在output端,我们再把他们根据需要,concatenate back
第四、五步构成了Automatic word system,不再是用word这种conventional的方式
Wordpiece/Sentencepiece model
Google NMT用的方法
没有用char n-gram count,而是用了a greedy approximation to maximize language model log likelihood to choose the pieces,这个能reduce perplexity of language model
他们用了两种方法
- wordpiece
类似BPE,tokenize word - sentencepiece
我们不用把word tokenize,因为语言很多,每个都有tokenizer,这个工程量太大了
也许我们可以保留whitespace,并把它作为一个special token,这样build word pieces时,就会某以边就会带上whitespace
- BERT就用了wordpiece的一个变种,当然它用了large vocabulary
比如hyptia=h ##yp ##ati ##a
有时候,word的word vector和它的四个word piece的关系可以是简单的average,有的时候会是max pooling/LSTM
Character-level to build word-level
work with characters,这样我么你才能应对Infinite vocabulary,这样我们就需要把小的组成大的。
do a convolution over the character to generate word vector,然后可以在higher level model用这些word vector
这是个fixed window model

Character-based LSTM to build word representations
把word representation放入higher level LSTM,这样就可以work along with a sequence of words

前面得到character vector,后面生成word vector
Goal: Minimize the perplexity of the higer level LSTM
Characgter-aware Neural Language Models

character embeddings build into a convolutional network 然后向上走
- 最底层做2/3/4-gram filter
- 然后做max-pooling

- output representation是character n-grams

- 这个output representation再输入一个LSTM network,这个LSTM是一个word-level LSTM,然后我们要minimize perplexity of neural networks
结果证明,higher layer可以很好地capture meanings
- 它最重要的优点:
当没有遇到的词出现时,word-level对其无能为力,但character-level model仍然表现不差(比如对于加prefix和suffix的影响)
Hybrid NMT
同时又word-level和character-level
- Translate mostly at word level
- Only go to the character level when needed
跑一个标准的seq2seq的attention LSTM Machine Translation Model
- 对于not in the vocabulary的word,我们用character level LSTM 来represent them
- 当我们要generate words时,我们会有一个softmax with 16000 vocabulary
- 当我们生成了一个UNK symbol时,我们就feed the hidden representation in the starting hidden character-level LSTM,generate a character sequence(直到生成stop symbol,这个sequence才算结束)

如果input不在vocab中,跑下面的(word-level),如果output不在vocab中,跑上面的;不然就哪个都不会跑
back prop
一般情况更新都是要算loss的,这里有两个Loss:上方的word-level loss
比如我们希望生成UNK的prob=1,但是softmax给了你0.2;比如你希望生成a particular sequence但是你没生成
Word-level beam search
consider different possibilities before deciding the highest prob of one sequence of word

当generate UNK,word level system would use attention to trace back the source,然后会有两个strategies
- 对maximally put attention on的那个词do unigram translation
- 对maximally put attention on的那个词进行copy
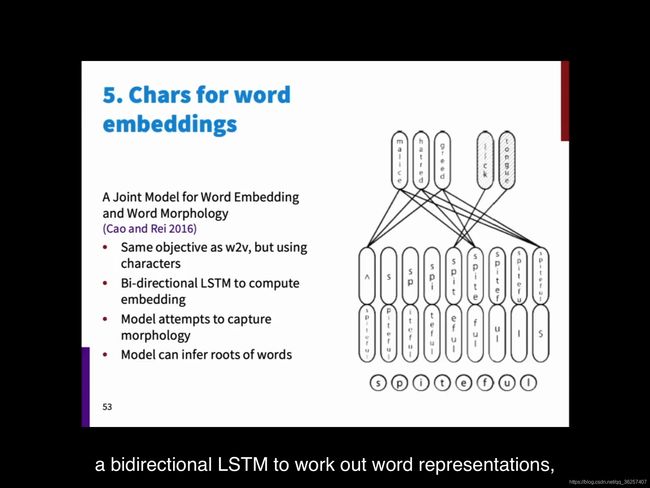
Chars for word embedding
训练word2vec,用word2vec的Loss func,但是start with character sequence,并且run bidirection LSTM
FastText Embedding
为了研究新一代的word2vec,但是对于那些rare words 和有很多morphology(变形词)的word的表现更好

关键在于,你知道每个word的开头,从何处开始,这样每个词可以被拆成有限个来进行计算
然后和center word以及context word的方法一样,进行计算,这里的center word就是用整个单词