人体姿态估计综述(Monocular Human Pose Estimation: A Survey of Deep Learning-based Methods)
1. 总述
1.1 应用
- 电影和动画
- 虚拟现实
- 人机交互
- 视频监控
- 医疗救助
- 自动驾驶
- 运动动作分析
1.2 挑战
人体姿势估计所面临的挑战主要体现在三个方面:
-
灵活的身体构造表示复杂的关节间关节和高自由度肢体,这可能会导致自我闭塞或罕见/复杂的姿势。
-
身体外观包括不同的衣服和彼此相似的部分。
-
复杂的环境可能会导致前景遮挡,附近人遮挡或类似的部分,各种视角以及相机视图中的截断。
1.3 已有的方法
- 根据是否使用设计的人体模型,可以将这些方法分为生成方法(基于模型)和判别方法(无模型)。
- 根据从哪个级别(高级抽象或低级像素)开始处理,它们可以分为自上而下(top-down)的方法和自下而上(bottom-up)的方法。
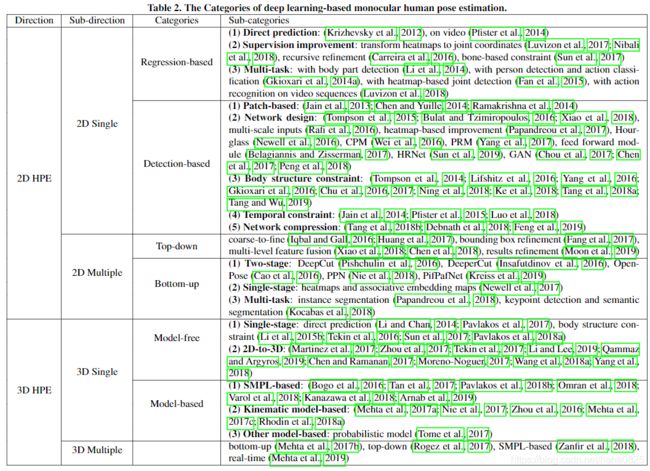
(1)生成方法 VS 判别方法
生成方法和判别方法之间的主要区别是方法是否使用人体模型。根据人体模型的不同表示,可以以不同的方式处理生成方法,例如关于人体模型结构的先验知识,从不同视图到2D或3D空间的几何投影,高维参数化空间回归方式的优化。
判别方法直接学习从输入源到人体姿势空间的映射(基于学习)或搜索不存在的示例(基于示例),而无需使用人体模型。 判别方法通常比生成方法要快,但对于从未受过训练的姿势而言,判别方法的鲁棒性较差。
(2)自上而下 VS 自下而上
对于多人姿势估计,根据预测的起点,人体姿态估计方法通常可以分为自上而下和自下而上的方法:高级抽象或低级像素。
自上而下的方法从高级抽象开始,首先是检测人,然后在边界框中生成人的位置,然后对每个人进行姿势估计。
相反,自下而上的方法首先在输入图像中预测每个人的所有身体部位,然后通过人体模型拟合或其他算法对它们进行分组。根据不同的方法,身体部位可能是关节,四肢或小的模板块(template patches)。
随着图像中人数的增加,自上而下方法的计算成本显著增加,而自下而上方法则保持稳定。 但是,如果有些人重叠很大,则自下而上的方法面临着将相应的身体部位分组的挑战。
(3)基于回归 VS 基于检测
基于不同问题的表述,基于深度学习的人体姿态估计方法可以分为基于回归或基于检测的方法。
基于回归的方法将输入图像直接映射到人体关节的坐标或人体模型的参数。 基于检测的方法基于两种广泛使用的表示将身体部位作为检测目标:图像块(image patches)和关节位置的热图。
从图像到关节坐标的直接映射非常困难,因为它是一个高度非线性的问题,而小区域表示则提供了具有更强鲁棒性的密集像素信息。 与原始图像尺寸相比,小区域表示的检测结果限制了最终关节坐标的准确性。
(4)单阶段 VS 多阶段
基于深度学习的一阶段方法旨在通过使用端到端网络将输入图像映射到人体姿势,而多阶段方法通常在多个阶段中预测人体姿势,并伴有中间监督。 例如,一些多人姿势估计方法首先检测人的位置,然后为每个检测到的人估计人的姿势。其他3D人姿势估计方法则首先在2D平面中预测关节位置,然后将其扩展到3D空间。
单阶段方法的训练比多阶段方法更容易,但中间约束更少。
1.4 人体模型
人体建模是人体姿态估计的关键组成部分。 人体是一个灵活而复杂的非刚性物体,具有运动结构,身体形状,表面纹理,身体部位或身体关节的位置等许多特定特征。成熟的人体模型不是必须包含所有人体属性,而是应满足构建和描述人体姿势的特定任务的要求。
基于不同级别的表示和应用场景,如下图所示,人体姿态估计中共有三种常用的人体模型:基于骨骼的模型,基于轮廓的模型和基于体积的模型。

对于人体模型的更详细描述,有两篇很好的论文:[Liu, Z., Zhu, J., Bu, J., Chen, C., 2015. A survey of human pose estimation: the body parts parsing based methods] 和 [Gong, W., Zhang, X., Gonz`alez, J., Sobral, A., Bouwmans, T., Tu, C., Zahzah,E.h., 2016. Human pose estimation from monocular images: A comprehensive survey]。
(1) 基于骨架
基于骨骼的模型(也称为“棍子模型”或“运动学”模型)表示一组关节(通常在10到30之间)位置以及遵循人体骨骼结构的相应肢体方向。基于骨骼的模型也可以描述为一幅图,其中顶点指示骨骼结构中关节的约束和边缘编码约束或关节的先验连接(prior connections )。这种人体拓扑结构非常简单灵活,在2D和3D人体姿态估计和人体姿态数据集中得到了广泛应用。虽然具有表现简单灵活的明显优点,但还存在很多不足,例如缺乏纹理信息,因而导致缺乏人体宽度和轮廓信息。
(2)基于轮廓的模型
基于轮廓的模型在早期的人体姿态估计方法中得到了广泛的应用,它包含了肢体和躯干的粗略宽度和轮廓信息。人体部位大约用矩形或人物轮廓的边界表示。广泛使用的基于轮廓的模型包括硬纸板模型(cardboard model)和活动形状模型(Active Shape Models (ASMs) )。
(3)基于体积的模型
3D人体形状和姿势通常由基于体积的几何形状或网格模型表示。较早的用于建模身体部位的几何形状包括圆柱体,圆锥形等。基于体积的现代模型以网格形式表示,通常通过3D扫描捕获。广泛使用的基于体积的模型包括人的形状完成和动画(Shape Completion and Animation of People,SCAPE),蒙皮多人线性模型(Skinned Multi-Person Linear model, SMPL)和统一的变形模型(unified deformation model)。
2. 2D人体姿态估计
2D人体姿势估计可根据单目图像或视频来计算人体关节的位置。在深度学习对基于视觉的人体姿势估计产生巨大影响之前,传统的2D人体姿态估计算法采用手工特征提取和复杂的人体模型来获取局部表示和全局姿势结构。
2.1 2D 单人姿态估计
2D单人姿势估计是在输入图像中定位单人的身体关节位置。对于具有更多人的图像,需要进行预处理以裁剪原始图像,以使输入图像中只有一个人,例如使用上身检测器或全身检测器,然后根据带注释的人的中心和身体比例从原始图像中裁剪。
将深度学习引入人体姿势估计的早期工作主要是通过简单地用神经网络替换框架的某些组件来扩展传统的人体姿态估计方法。根据人类姿势估计任务的不同表述,使用CNN提出的方法可分为两类:基于回归的方法和基于检测的方法。基于回归的方法尝试通过端到端框架学习从图像到运动身体关节坐标的映射,并且通常直接产生关节坐标。基于检测的方法旨在预测身体部位的大概位置或关节,通常由一系列矩形窗口(每个包括特定的身体部位)或热图(每个图都通过以关节位置为中心的2D高斯分布来指示一个关节位置)进行监督。
这两种方法中的每一种都有其优点和缺点。 仅是一个点的直接回归学习是一个难题,因为它是一个高度非线性的问题,并且缺乏鲁棒性,而热映射学习则由密集的像素信息监督,从而获得了更好的鲁棒性。与原始图像尺寸相比,由于CNN中的池化操作,热图表示的分辨率要低得多,这限制了联合坐标估计的准确性。 从热图获得联合坐标通常是不可微的过程,会阻塞要端到端训练的网络。
表3总结了2D单人姿势估计的最新代表性工作,最后一列是MPII测试集上[email protected]得分的比较。

2.1.1 基于回归的模型
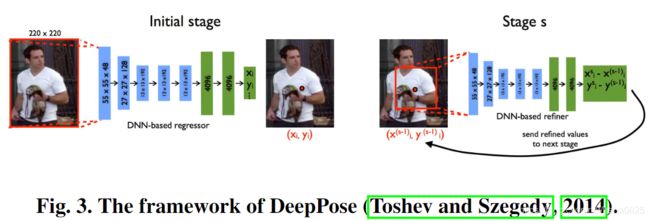
AlexNet是基于深度学习的人体姿态估计方法的早期网络之一,因为其结构简单且性能强大。 DeepPose首先尝试训练类似AlexNet的深度神经网络,以非常简单的方式从完整图像中学习关节坐标,而无需使用任何人体模型或部位检测器,如图3所示。此外,级联架构细化回归器用于细化上一阶段的裁剪图像从而获进一步提升结果。 [Deep convolutional neural networks for efficient pose estimation in gesture video]还使用了一个类似于AlexNet的网络,使用一系列连接的帧作为输入来预测视频中的人体姿势。
仅使用没有周围信息的关节缺乏鲁棒性。 将热图监控转换为数字联合监控可以保留两种表示的优点。
- [Luvizon, D.C., Tabia, H., Picard, D., 2017. Human pose regression by combining indirect part detection and contextual information]提出了一个Soft-argmax函数,将热图转换为联合坐标,从而可以将基于检测的网络转换为基于微分的可回归网络。
- [Nibali, A., He, Z., Morgan, S., Prendergast, L., 2018. Numerical coordinate regression with convolutional neural networks.]设计了一个可微分的空间数值转换(DSNT)层,以根据热图计算联合坐标,该坐标与低分辨率热图配合使用效果很好。
直接从很少受约束的输入图像中预测关节坐标非常困难,因此,通过改进或人体模型结构引入了功能更强大的网络。
- [Carreira, J., Agrawal, P., Fragkiadaki, K., Malik, J., 2016. Human pose estimation with iterative error feedback]提出了一个基于GoogleNet的迭代错误反馈网络(Iterative Error Feedback network),该网络递归处理输入图像和输出结果的组合。 最后的姿势比迭代后的初始平均姿势有所改善。
- [Sun, X., Shang, J., Liang, S.,Wei, Y., 2017. Compositional human pose regression]提出了一种基于ResNet-50的结构感知回归方法。代替使用关节来表示姿势,而是通过涉及身体结构信息来设计基于骨骼的表示,以实现比仅使用关节位置更稳定的结果。
基于骨骼的表示也可以在3D人体姿态估计上工作。
处理与人体密切相关的多个任务的网络可能会学习各种特征,以改善关节坐标的预测。
- [Li, S., Liu, Z.Q., Chan, A.B., 2014. Heterogeneous multi-task learning for human pose estimation with deep convolutional neural network]采用了类似AlexNet的多任务框架,以回归方式处理来自完整图像的联合坐标预测任务,并使用滑动窗口获得的图像块进行身体部位检测任务。
- [Gkioxari, G., Hariharan, B., Girshick, R., Malik, J., 2014a. R-cnns for pose estimation and action detection]使用R-CNN架构来同步进行检测人,估计姿势以及对动作进行分类。
- [Fan, X., Zheng, K., Lin, Y., Wang, S., 2015. Combining local appearance and holistic view: Dual-source deep neural networks for human pose estimation]提出了一种双源(dual-source)CNN,其以图像块和全图像作为输入,输出的热图代表滑动窗口的联合检测结果以及坐标代表的联合定位结果。从两个结果的组合中获得最终的姿势估计。
- [Luvizon, D.C., Picard, D., Tabia, H., 2018. 2d/3d pose estimation and action recognition using multi-task deep learning]设计了一个网络,可以共同处理视频序列中的2D / 3D姿势估计和动作识别。 网络中间估计的姿势可以用作动作识别的参考。
2.1.2 基于检测的模型
基于检测的方法是从身体部位检测方法发展而来的。 在传统的基于零件的人体姿态估计方法中,首先从候选图像块中检测出身体部位,然后进行组合以适合人体模型。 在早期工作中检测到的身体部位相对较大,通常以矩形滑动窗口或小块表示。 某些方法使用神经网络作为身体部位检测器来区分候选块是否是特定的身体部位,在预定义模板中对候选块进行分类或预测属于多个类别的置信度。 身体部位检测方法通常对复杂的背景和身体遮挡敏感。 因此,仅具有局部外观的独立图像块可能无法很好的区分人体部位。为了提供比关节坐标更多的监督信息并促进CNN的训练,最近的工作采用热图来指示关节的真实值。
如图4所示,每个关节占据一个热图通道,其二维高斯分布以目标关节位置为中心。 此外,[Papandreou, G., Zhu, T., Kanazawa, N., Toshev, A., Tompson, J., Bregler, C.,Murphy, K., 2017. Towards accurate multi-person pose estimation in the wild]提出了一种改进的关节位置表示方法,该方法将二进制激活热图和相应的偏移量结合在一起,由于热图表示比坐标表示更健壮,因此最近的大部分研究都基于热图表示。

神经网络架构对于更好地利用输入信息非常重要。一些方法主要基于经过适当改进的经典网络,例如具有多尺度输入的基于GoogLeNet的网络,具有反卷积层的基于ResNet的网络。在迭代细化方面,一些工作以多阶段样式设计了网络,以通过端到端学习来细化粗略的预测结果。这样的网络通常使用中间监督来解决梯度消失。
- [Newell, A., Yang, K., Deng, J., 2016. Stacked hourglass networks for human pose estimation]提出了使用残差模块作为组件单元的叠层式沙漏架构。
- [Yang, W., Li, S., Ouyang, W., Li, H., Wang, X., 2017. Learning feature pyramids for human pose estimation]设计了一个金字塔残差模块(PRM)来替换沙漏网络的残差模块,以通过学习各种尺度的特征来增强深度CNN各个尺度之间的不变性。
- [Belagiannis, V., Zisserman, A., 2017. Recurrent human pose estimation]将7层前馈模块与递归模块组合在一起以迭代地优化结果。该模型学习预测关节和肢体的定位热图。 此外,他们还分析了具有不平衡的GT分布的关键点可见性。为了在整个网络中保持高分辨率的特征表示。
- [Sun, K., Xiao, B., Liu, D., Wang, J., 2019. Deep high-resolution representation learning for human pose estimation]提出了一种新颖的具有多尺度特征融合的高分辨率网络(HRNet)。
与早期的尝试将检测到的身体部位拟合到人体模型中的工作不同,一些最新的工作试图将人体结构信息编码为网络。
- [Tompson, J.J., Jain, A., LeCun, Y., Bregler, C., 2014. Joint training of a convolutional network and a graphical model for human pose estimation]共同训练了一个具有类似于MRF的空间模型的网络,以学习关节之间的典型空间关系。
- [Lifshitz, I., Fetaya, E., Ullman, S., 2016. Human pose estimation using deep consensus voting]将图像离散化为以每个关节为中心的对数极坐标箱(log-polar bins),并使用基于VGG的网络来预测对每个成对关节(二项)有置信度的关节类别。通过所有相对置信度得分,每个关节的最终热图都可以通过反卷积网络生成。
- [Yang, W., Ouyang, W., Li, H., Wang, X., 2016. End-to-end learning of deformable mixture of parts and deep convolutional neural networks for human pose estimation]设计了一个两阶段的网络。 第一阶段是卷积神经网络,以预测热图表示中的关节位置。第二阶段是根据人体结构手动连接的消息传递模型,以最大和算法找到最佳的关节位置。
- [Gkioxari, G., Toshev, A., Jaitly, N., 2016. Chained predictions using convolutional neural networks]提出了卷积递归神经网络,按照链模型一个接一个地输出关节位置。每个步骤的输出取决于输入图像和先前预测的输出。网络可以处理具有不同连接策略的图像和视频。
- [Chu, X., Ouyang, W., Li, H., Wang, X., 2016. Structured feature learning for pose estimation]提出了通过双向树对内核进行变换,以在树体模型(tree body model)中的相应关节之间传递信息。
- [Chu, X., Yang, W., Ouyang, W., Ma, C., Yuille, A.L., Wang, X., 2017.Multi-context attention for human pose estimation]用更复杂的模块替换了Hourglass网络的残差模块。 条件随机场(CRF)用于注意力图,作为学习人体结构信息的中间监督。
- [Ning, G., Zhang, Z., He, Z., 2018. Knowledge-guided deep fractal neural networks for human pose estimation]设计了一个分形网络以施加身体先验知识来指导网络。通过使用学习的投影矩阵,将外部知识的视觉特征编码到基本网络中。
- [Ke, L., Chang, M.C., Qi, H., Lyu, S., 2018. Multi-scale structure-aware network for human pose estimation]提出了一种基于Hourglass网络的多尺度结构感知网络,该网络具有多尺度监督,多尺度特征组合,结构感知损失和关节掩码数据增强。
- 关于Hourglass网络的基本框架,[Tang, W., Yu, P., Wu, Y., 2018a. Deeply learned compositional models for human pose estimation]设计了用于中间监督的身体部位的分层表示形式,以替换每个关节的热图。因此,网络学习自下而上/自上而下的身体结构,而不是仅学习分散的关节。
- [Tang, W., Wu, Y., 2019. Does learning specific features for related parts help human pose estimation]提出了一种基于零件的分支网络(PBN),以学习每个零件组的特定表示,而不是预测一个分支的所有联合热图。 然后,通过计算关节的相互信息来分割数据驱动的零件组。
生成对抗网络(GAN)被用于为学习身体结构或网络训练提供对抗监督。
- [Zhou, X., Huang, Q., Sun, X., Xue, X., Wei, Y., 2017. Towards 3d human pose estimation in the wild: a weakly-supervised approach]引入了对抗学习,分别使用两个相同的Hourglass网络作为生成器和鉴别器。 生成器预测每个关节的热图位置,而鉴别器则将GT热图与生成的热图区分开。
- [Chen, Y., Shen, C., Wei, X.S., Liu, L., Yang, J., 2017. Adversarial posenet: A structure-aware convolutional network for human pose estimation]提出了一种具有结构意识的卷积网络,该网络具有一个生成器和两个鉴别器,以整合人体结构的先验知识。 该生成器是从沙漏网络设计的,可预测关节热图和闭遮挡热图。 姿势鉴别器可以将不合理的身体构造与不合理的身体构造区别开。置信度鉴别器显示预测的置信度得分。
- [Peng, X., Tang, Z., Yang, F., Feris, R.S., Metaxas, D., 2018. Jointly optimize data augmentation and network training: Adversarial data augmentation in human pose estimation]研究了如何在不寻找更多数据的情况下共同优化数据增强和网络训练。当网络从生成的数据增强中学习时,他们使用增强来增加网络损失,而不是使用随机数据增强。
时间信息的利用对于估计单目视频序列中的2D人体姿势也非常重要。
- [Jain, A., Tompson, J., LeCun, Y., Bregler, C., 2014. Modeep: A deep learning framework using motion features for human pose estimation]设计了一个框架,该框架包含两个分支的CNN,采用多尺度RGB帧和光流图作为输入,提取的特征在最后的卷积层之前串联在一起。
- [Pfister, T., Charles, J., Zisserman, A., 2015. Flowing convnets for human pose estimation in videos]使用光流图作为指导,根据视频的时间上下文对齐来自相邻帧的预测热图。
- [Luo, Y., Ren, J., Wang, Z., Sun, W., Pan, J., Liu, J., Pang, J., Lin, L., 2018. Lstm pose machines]通过使用CSTM重新设计的递归神经网络,通过更改具有LSTM结构的多阶段架构来利用时间信息。
为了在低容量设备上进行人体姿势估计,可以在保持竞争性能的同时减少网络参数。
- [Tang, Z., Peng, X., Geng, S., Wu, L., Zhang, S., Metaxas, D., 2018b. Quantized densely connected u-nets for efficient landmark localization]致力于通过提出密集连接的U-Net和有效利用内存来改善网络结构。 该网络类似于Hourglass网络的概念,但它利用U-Net作为每个组件,在每个阶段具有更优化的全局连接,从而减少了参数并减小了模型尺寸。
- [Debnath, B., O’Brien, M., Yamaguchi, M., Behera, A., 2018. Adapting mobilenets for mobile based upper body pose estimation]通过在MobileNets的最后两层设计分离流架构,将MobileNets进行了姿态估计。
- [Feng, Z., Xiatian, Z., Mao, Y., 2019. Fast human pose estimation]设计了一个沙漏网络的轻量级变体,并通过快速姿势蒸馏(Fast Pose Distillation)训练策略对完整的老师沙漏网络进行训练。
总而言之,与基于检测的坐标表示相比,热图表示更适合于网络训练深度学习的2D单人姿势估计方法。
2.2 2D 多人姿态估计
与单人姿势估计不同,多人姿势估计需要处理检测任务和定位任务,因为在输入图像中没有提示有多少人。 根据从哪个级别(高级抽象或低级像素)开始计算,人为估计方法可以分为自上而下的方法和自下而上的方法。自上而下的方法通常使用人检测器在输入图像中获取一组人的边界框,然后直接利用现有的单人姿势估计器来预测人的姿势。预测的姿势严重依赖于人检测的精度。整个系统的运行时间与人数成正比。自下而上的方法直接预测所有人的所有2D关节,然后将它们组装成独立的骨架。在复杂环境中正确组合关节点是一项艰巨的研究任务。表4总结了自上而下和自下而上类别中基于深度学习的2D多人姿势估计方法的最新工作。
下表是主流的多人姿态估计方法,最后一列是COCO测试开发数据集的平均精度(AP)评分。


2.2.1 自上而下方法
自上而下的人体姿态估计方法的两个最重要的组成部分是人体区域proposal检测器和一个单人姿态估计器。大多数研究专注于基于现有人体检测器的人体估计,例如Faster R-CNN,Mask R-CNN,FPN。
- [Iqbal, U., Gall, J., 2016. Multi-person pose estimation with local joint-to-person associations]利用基于卷积姿态机的姿势估计器来生成初始姿势。 然后应用整数线性规划(integer linear programming)以获得最终姿势。
- [Fang, H., Xie, S., Tai, Y.W., Lu, C., 2017. Rmpe: Regional multi-person pose estimation]采用了spatial transformer network,非最大抑制(NMS)和沙漏网络来促进姿势估计的准确性。
- [Huang, S., Gong, M., Tao, D., 2017. A coarse-fine network for keypoint localization]开发了以Inception-v2网络为骨干的粗精细网络(coarse-fine network)。 该网络在多个级别进行监督,以学习粗略和精细预测。
- [Xiao, B., Wu, H., Wei, Y., 2018. Simple baselines for human pose estimation and tracking]在ResNet的最后一个卷积层上添加了几个反卷积层,以根据深层和低分辨率特征生成热图。
- [Chen, Y., Wang, Z., Peng, Y., Zhang, Z., Yu, G., Sun, J., 2018. Cascaded pyramid network for multi-person pose estimation]提出了一种级联金字塔网络(cascade pyramid network),它利用来自不同层的多尺度特征图来从局部和全局特征中获取更多推论,难的节点则具有在线难关键点挖掘损失。
- 基于不同人体姿态估计方法的相似姿态误差分布,[Moon, G., Chang, J.Y., Lee, K.M., 2019. Posefix: Model-agnostic general
human pose refinement network]设计了PoseFix网络以从任何方法中细化估计姿势。
通过将现有的检测网络和单个人体姿态估计网络结合起来,可以轻松实现自顶向下的人体姿态估计方法,但是,这种方法的性能会受到人检测结果的影响,并且操作速度通常不是实时的。
2.2.2 自下而上的方法
自下而上的人体姿态估计方法的主要组成部分包括人体关节检测和候选关节分组。 大多数算法分别处理这两个组件。
- Deep-Cut(Pishchulin et al。,2016)使用基于 Faster R-CNN的身体部位检测器首先检测所有身体部位proposal,然后将每个部位标记为其对应的部位类别,然后用整数线性规划组合这些零件来构成完整的骨架。
- DeeperCut(Insafutdinov等,2016)通过使用基于ResNet的更强大的零件检测器和探索联合候选对象之间的几何形状和外观约束的更好的增量优化策略改进DeepCut。
- OpenPose(Cao等,2016)使用CPM来预测具有部分亲和力字段(Part Affinity Fields)的所有身体关节。 提出的PAF可以对肢体的位置和方向进行编码,以将估计的关节组装成不同的人的姿势。
- [Nie, X., Feng, J., Xing, J., Yan, S., 2018. Pose partition networks for multi-person pose estimation]提出了一个姿势分割网络(Pose Partition Network)来进行关节检测和密集回归,以实现关节分割,然后PPN对具有关节分割的关节配置进行局部推断。
- 与OpenPose相似,[Kreiss, S., Bertoni, L., Alahi, A., 2019. Pifpaf: Composite fields for human pose estimation]设计了一个PifPaf网络以预测代表身体关节位置和身体关节关联的零件强度场(PIF)和零件关联场(PAF)。 由于PAF的细粒度和Laplace loss的使用,它在低分辨率图像上效果很好。
以上方法都是将联合检测和联合分组分开的方法。 最近,一些方法可以在一个阶段进行预测。
- [Newell, A., Huang, Z., Deng, J., 2017. Associative embedding: End-to-end learning for joint detection and grouping]引入了单阶段深度网络架构,以同时执行检测和分组。 该网络可以为每个关节生成检测热图,以及包含每个关节的分组标签的关联嵌入图。
一些方法采用多任务结构。
- [Papandreou, G., Zhu, T., Chen, L.C., Gidaris, S., Tompson, J., Murphy,K., 2018. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model]提出了一种无盒多任务网络,用于姿势估计和实例分割。 基于ResNet的网络可以同步预测每个人所有关键点的联合热图及其相对位移。 然后,该分组从最可靠的检测开始,该检测基于树状运动学图的贪婪解码过程。
- [Kocabas, M., Karagoz, S., Akbas, E., 2018. Multiposenet: Fast multi-person pose estimation using pose residual network]结合了具有新颖分配方法的多任务模型,可完全处理人类关键点估计,检测和语义分段任务。 它的骨干网是共享关键点特征的ResNet和FPN的组合以及人检测子网。 人体检测结果被用来限制人的空间位置。
abas, M., Karagoz, S., Akbas, E., 2018. Multiposenet: Fast multi-person pose estimation using pose residual network]结合了具有新颖分配方法的多任务模型,可完全处理人类关键点估计,检测和语义分段任务。 它的骨干网是共享关键点特征的ResNet和FPN的组合以及人检测子网。 人体检测结果被用来限制人的空间位置。
目前,自下而上方法的处理速度非常快,有些方法可以实时运行。 但是,性能可能会受到复杂背景和人为遮挡的很大影响。 自上而下的方法在几乎所有基准数据集中都实现了最先进的性能,而处理速度受到检测到的人员数量的限制。