目标检测算法汇总:RCNN系列、YOLO系列、SSD系列
常见的目标检测算法
- 1、传统的目标检测方法
- 2、two-stage方法
-
- 2.1 RCNN
- 2.2 fast RCNN
- 2.3 faster RCNN
- 3、one-stage方法
-
- 3.1 YOLO系列
-
- (1)YOLO V1
- (2)YOLO V2
- (3)YOLO V3
- (4)YOLO V4
- (5)YOLO V5
- 3.2 SSD系列
-
- (1)SSD
- (2)FSSD
- (3)DSSD
目前,常见的目标检测(object detection)算法分为3类:
1、传统的目标检测方法:特征提取+分类器
2、two-stage方法:候选框+分类,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN
3、one-stage方法:直接回归,如YOLO系列、SSD系列
1、传统的目标检测方法
传统的目标检测流程:
Step1:图像预处理:图像灰度化、滤波、二值化、形态学处理、边缘检测等操作,增强图片质量;
Step2:区域选择:图像分割,选择区域;
Step3:特征提取:包括形状特征、颜色特征和纹理特征等。常用的特征提取方法:
形状特征:边界特征法(如Hough)、傅里叶形状描述符(Fourier shape deors)、几何参数(如面积、周长、圆度、偏心率等)、形状不变矩、有限元法(FEM)、旋转函数(Turning)和小波描述符(Wavelet Deor)等。
颜色特征:颜色集、颜色矩、颜色聚合向量、颜色相关图等。
纹理特征:灰度差分统计法、局部二进制模式( LBP)、灰度共生矩阵(GLCM)、灰度-梯度共生矩阵(G-GLCM)等。
还有常见的尺度不变特征变换(SIFT)、SURF特征描述算子、ORB特征描述算子、方向梯度直方图(HOG)和哈尔特征(Harr)、方向梯度直方图(HOG)等。
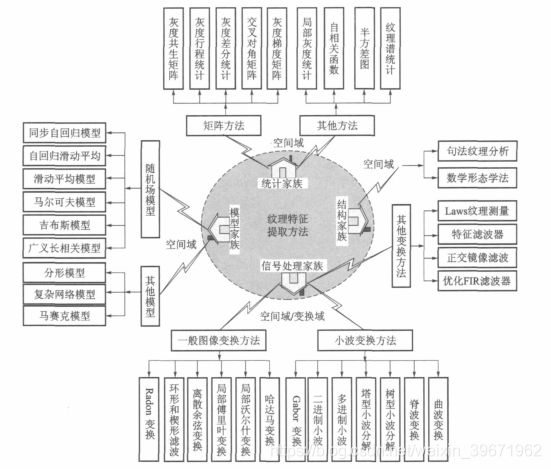
Step4:分类器。常见的分类器包括K-近邻法(K-NN)、支持向量机(SVM)、决策树、集成学习(如Adaboost)、随机森林、朴素贝叶斯法、隐马尔可夫模型、高斯混合模型。
2、two-stage方法
| RCNN | Fast RCNN | Faster RCNN | |
|---|---|---|---|
| 效果 | 53.3mAP,47s | 66mAP,0.3s | 67mAP,0.2s |
| 过程 | Selective Search + CNN + SVM | Selective Search + CNN + RoI | RPN + CNN + RoI |
2.1 RCNN
2014 CVPR,Rich feature hierarchies for accurate object detection and semantic segmentation
在VOC2012中,RCNN获得53.3mAP。(速度慢,一张图要47s)
RCNN的流程:selective search +CNN +L-svm
(1)输入图像;
(2)用选择性搜索selective search代替传统的滑动窗口,从上到下提取出2000个候选区域region proposals(生成候选区域的方法有很多,比如:objectness, selective search ,category-independent object proposals , constrained,parametric min-cuts (CPMC) , multi-scale combinatorial
grouping, Ciresan等,作者选择了selective search)
(3)对于每个候选区域,使用AlexNet提取特征,得到4096维的特征。由于AlextNet的输入图像是227×227,但selective search产生的候选区域大小不一,因此,统一将候选框的尺寸变换到227×227
(4)使用L-SVM进行分类(类别+1背景),计算IOU,采用非极大值抑制NMS选取效果好的区域。

2.2 fast RCNN
2015 ICCV,Fast R-CNN
在VOC2012,fast RCNN获得66mAP,一张图需要0.3s
fast RCNN的流程:
(1)用选择性搜索selective search提取出2000个候选区域region proposals;
(2)使用CNN提取特征,得到feature map
(3)根据RoI框选出对应的区域,利用RoI pooling层固定维度;
(4)softmax分类,多任务损失函数回归BBox并进行位置调整

RCNN与fast RCNN在结构上主要有几点不同:
(1)fast RCNN:一张完整的图片=>CNN=>每个候选框的特征=>分类+回归;RCNN:候选框(2k)=>CNN=>每个候选框的特征=>分类+回归
(2)fast RCNN使用RoI框选出感兴趣的区域后,利用RoI pooling来固定维度;RCNN暴力变维
(3)fast RCNN使用softmax进行分类;RCNN用L-SVM;
(4)fast RCNN损失函数使用了多任务损失函数(multi-task loss),将边框回归Bounding Box Regression直接加入到CNN网络中训练;
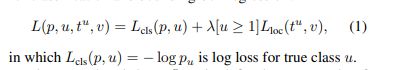
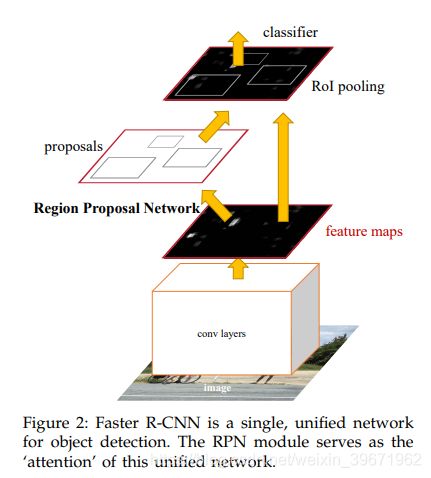
2.3 faster RCNN
2015 NIPS,Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
在VOC2007test,faster RCNN获得69.9mAP,在VOC2012test,faster RCNN获得67mAP,一张图需要198ms
faster RCNN的流程:RPN提取候选框+fast RCNN检测
(1)用RPN提取候选区域;
(2)使用CNN提取特征,得到feature map
(3)利用RoI pooling层固定维度;
(4)softmax分类,多任务损失函数回归BBox并进行位置调整
3、one-stage方法
3.1 YOLO系列
R-CNN系列将检测过程分为两步:候选框提取+分类,而YOLO只需要一步,使用了回归的思想,将图片作为输入,直接在输出层对BBox的位置和类别进行回归。
(1)YOLO V1
2016年,YOLOV1:You Only Look Once:Unified, Real-Time Object Detection
在PASCAL VOC2007中,YOLO v1获得63.4mAP,45FPS
YOLO V1的步骤:
1、输入图像,将图像划分为S*S的网格(grid cell),object的中心落在哪个网格,哪个网格就负责预测该object;(这里S=7)
2、每个网格需要预测B个BBox的位置信息(x,y,w,h)和置信度confidence信息(这里B=2)
![]()
Pr(classi|object):类别;
Pr(object):有object落在网格gride cell里,Pr(object)=1,否则Pr(object)=0。
IOU:预测的bounding box和实际的groundtruth之间的IOU值。
Pr(object)*IOU:置信度
即:输入图像,将图像划分为7×7个网格,每个网格预测2个边框,由于PSSCAL VOC有20个类别标签,则可预测出7×7×(2×5+20)个目标窗口,然后根据设定的阈值,滤除分数低的边框,再利用NMS去除冗余边框。

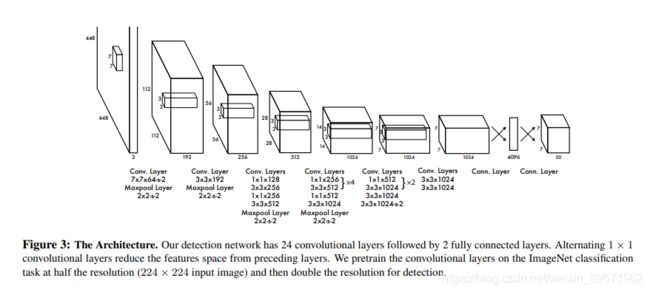
3、网络框架:24个Conv+2FC
4、损失函数:

(2)YOLO V2
2016年,YOLO V2:YOLO9000: Better, Faster, Stronger
在PASCAL VOC2007中,在67 FPS的情况下,YOLOv2获得76.8mAP;在40 FPS的情况下,获得78.6mAP。
YOLOv2相对v1版本,预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)。
1、预测更准确(Better)
(1)批量归一化Batch Normalization:提高收敛性,Conv+ReLu+BN,达到了正则化的效果(YOLOv2不使用dropout)==>>mAP提升2.4%
(2)高分辨率图像分类器High Resolution Classifier:采用224×224图像预训练后,再采用448×448进行微调。(YOLO v1预训练中224×224图像输入,测试中采用448×448)= = >>mAP提升3.7%
(3)使用先验框Convolutional With Anchor Boxes:YOLO v2采用了先验框,在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度。YOLO v2去掉了全连接层,使用Anchor Boxes来预测 Bounding Boxes;去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率。(YOLOV1包含有全连接层,从而能直接预测Bounding Boxes的坐标值。 Faster R-CNN的用卷积层与Region Proposal Network(RPN)来预测Anchor Box的偏移值与置信度,而不是直接预测坐标值。)= = >>召回率提升了7%,mAP降低了0.2%(不使用Anchor Boxes:召回率81%,69.5mAP;使用Anchor Boxes:召回率88%,69.3mAP)
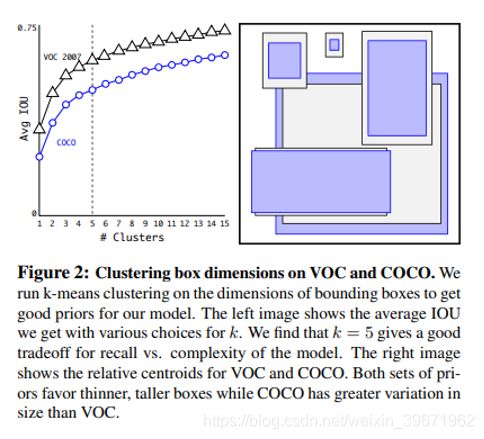
(4)聚类提取先验框的尺度信息Dimension Clusters:YOLO v2采用欧氏距离的K-mean对标注的边框进行聚类分析,以自动找到尽可能匹配样本的边框尺寸。(以前的Anchor Boxes的尺寸是手动选择的)

centroid是聚类时被选作中心的边框,box是其它边框,d就是两者间的“距离”。IOU越大,“距离”越近。选择聚类分类数K=5。
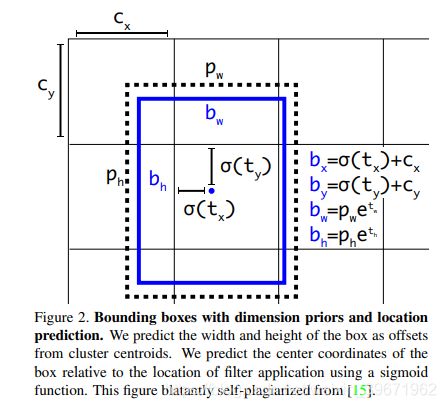
(5)约束预测边框位置Direct location prediction:由于之前的tx,ty取值没有约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLO v2调整了预测公式,将预测边框的中心约束在特定gird网格内,计算如下:

因为使用了限制让数值变得参数化,也让网络更容易学习、更稳定。= = >>预测边框中心位置提高5%
(6)细粒度特征Fine-Grained Features:YOLO v2中输入416416经过卷积网络下采样最后输出是1313,这对于大型物体的检测已经足够了,为了更好的检测出一些小物体,添加一个 passthrough 层,通过将相邻要素堆叠到不同的通道而不是空间位置中,从而将高分辨率要素与低分辨率要素连接起来。= = >>mAP提升1%

(7)多尺度图像训练Multi-Scale Training:YOLO v2在不同尺度的图像上都能达到一个比较好的预测效果。如下图,输入图片尺寸越小,速度越快,但精度越差。
2、速度更快(Faster)
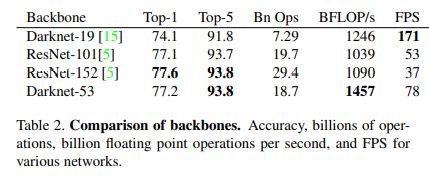
(1)Darknet-19:backbone网络采用Darknet-19(19个Conv+5个Maxpooling),去除了FC层,采用全局平均池化Global Avgpool进行预测。= = >>Darknet-19仅需要55.8亿次操作即可处理图像,但在ImageNet上达到72.9%的top-1精度和91.2%的top-5精度。(比VGG-16快,但准确性不如VGG-16)

(2)分类训练Training for classification:在ImageNet 1000 个分类标签的数据集上训练,采用随机梯度下降法stochastic gradient descent, epochs=160,初始学习率 starting learning rate= 0.1,多项式率衰减的幂polynomial rate decay with a power of
4,权重衰减weight decay=0.0005,动量momentum=0.9,网络框架采用Darknet,使用数据增强(包括 random 剪裁crops, 旋转rotations, and 色度hue, 饱和度saturation, and 曝光exposure shifts.)= = >>top-1精度76.5%、top-5精度93.3%
(3)检测训练Training for detection:删除最后一个Conv,加上3个3×3的Conv(每个Conv有1024个filters),每个Conv层接着一个1×1的Conv层。对于VOC,每个网格预测5个Bounding Boxes,每个Bounding Boxes预测5个坐标和20类,总共125个Filters。从最后的3×3×512层到倒数第二个卷积层添加了一个Passthough,以便使用细粒度特征。 epochs=160,初始学习率 starting learning rate= 0.001,在60-90个epochs时将其除以10,权重衰减weight decay=0.0005,动量momentum=0.9。
3、识别对象更多(Stronger)
(1)分层分类Hierarchical classification
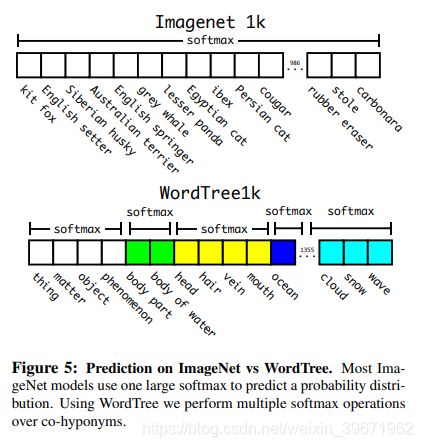
(2)Dataset combination with WordTree:
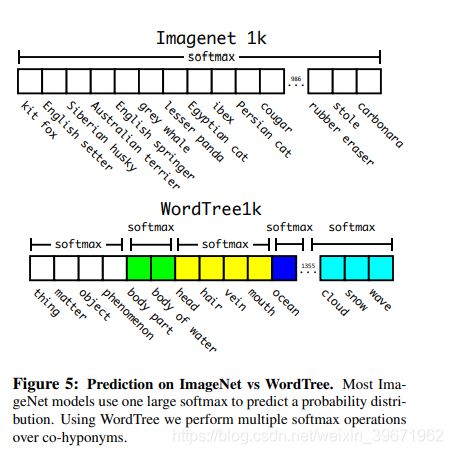
(3)Joint classification and detection.
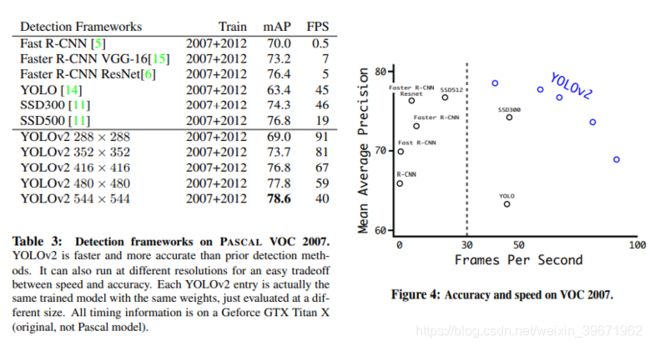
(3)YOLO V3
YOLOv3: An Incremental Improvement
输入图像为320×320,YOLO v3达到了28.2mAP,22ms,与SSD的精度一样,但是速度提高了3倍。
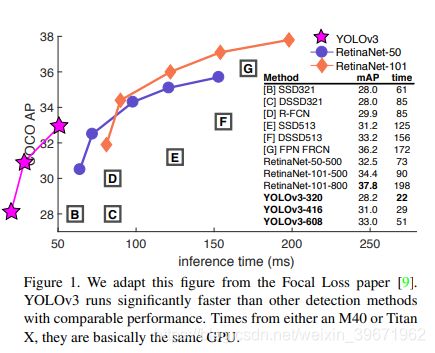
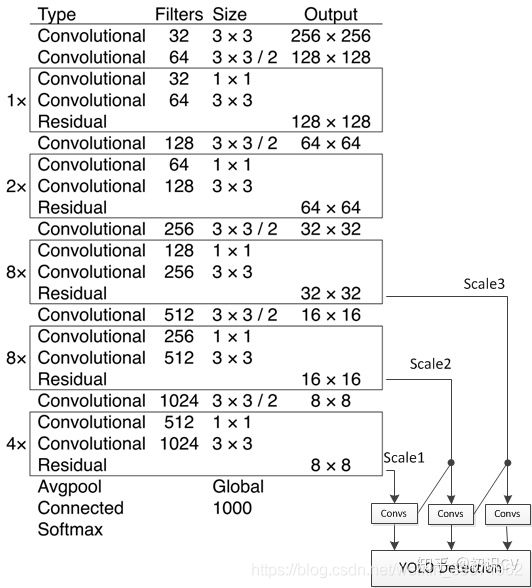
1、基础网络Darknet-53:

(1)采用Darknet-53(YOLO v2采用Darknet-19)
(2)用s=2的Conv层代替池化层(YOLO v2有5个Maxpooling)达到下采样的效果
2、边框回归:
YOLOV3思想理论是将输入图像分成SxS个格子,若某个物体Ground truth的中心位置的坐标落入到某个格子,那么这个格子就负责检测中心落在该栅格中的物体。
YOLOV3进行3次检测,分别52x52, 26x26, 13x13的feature map上,即S分别为52,26,13。32倍降采样的感受野最大(13x13),适合检测大的目标,每个cell的三个anchor boxes为(116 ,90),(156 ,198),(373 ,326)。16倍(26x26)适合一般大小的物体,anchor boxes为(30,61), (62,45),(59,119)。8倍的感受野最小(52x52),适合检测小目标,因此anchor boxes为(10,13),(16,30),(33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal boxes。
3、多尺度预测:FPN网络
YOLOV3采用FPN结构来进行多尺度预测。

YOLOV3每种尺度预测3个box,有3种尺度(52x52, 26x26, 13x13),anchor的设计方式仍然使用聚类,得到9个聚类中心。
尺度1:使用8×8的特征图,在基础网络之后添加一些卷积层再输出box信息。= =>>降采样32倍,用于大目标的检测。
尺度2:使用16×16的特征图,从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍.= =>>降采样16倍,用于一般大小的目标检测。
尺度3:使用了32x32大小的特征图,与尺度2的过程类似。= =>>降采样8倍,用于小的目标检测。
通常,一幅图像包含各种不同的物体,有大有小,因此,网络必须具备能够“看到”不同大小的物体的能力。并且网络越深,特征图就会越小,所以越往后小的物体也就越难检测出来。随着网络深度的加深,浅层的feature map中主要包含低级的信息(物体边缘,颜色,初级位置信息等),深层的feature map中包含高等信息(例如物体的语义信息:狗,猫,汽车等等)。
4、YOLOV3采用了类似ResNet残差结构,更好地获取物体特征。

5、替换softmax层:对应多重label分类
(1)Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。
(2)Softmax层被替换为一个1x1的卷积层+logistic激活函数的结构,且准确率不会下降。
6、分类损失采用binary cross-entropy loss
(4)YOLO V4
2020年4月,Alexey Bochkovskiy发表了YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv4在MS COCO数据集上获得了: 43.5%AP (65.7% AP50) ,65 FPS ,比YOLO V3提高了10%(AP)和12%(FPS)。
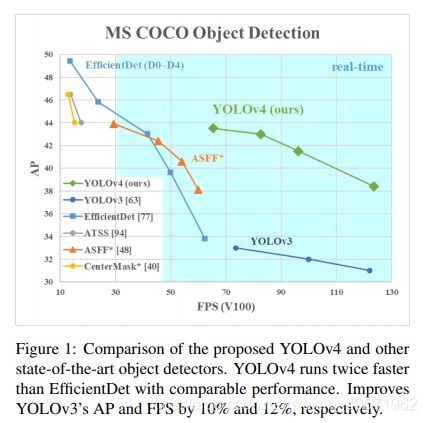
YOLO V4像是目标检测Tricks的文献综述,列举了目标检测中的Backbone、Neck和Heads的一些常用方法:

1、Bag of freebies(BoF):提高精度而不增加推断时间
(1)数据增广data augmentation:增加训练样本的多样性,使得检测模型具有高的鲁棒性。
1)像素级别pixel-wise:几何增强 geometric distortions和色彩增强 photometric distortions。
几何增强 geometric distortions:缩放scale、裁剪crop,翻转flip、旋转rotation
色彩增强 photometric distortions:对比度contrast,亮度brightness,色度hue,饱和度saturation,图片加噪noise of an image
2)解决目标遮挡及不足的问题occlucion:
在图像中随机裁剪多个矩形区域:hide-and-seek, grid mask
在图像中随机裁剪矩形区域,并用0来填充:random erase,CutOut
在heatmap上裁剪并填充:DropOut,DropConnect, DropBlock
3)使用多张图像using multiple image:
两图像相加/乘,使用叠加系数调整标签:MixUp
剪裁后的图像覆盖到其他图像的矩形区域,根据混合区域大小调整标签:CutMix
4) style transfer GAN:有效地减少纹理偏差
(2)解决数据不平衡的问题(背景和目标之间的不平衡;类别不平衡等)
1)在二阶目标检测 two-stage object detector,常用hard negative example mining 和online hard example mining解决
2)focal loss==>>解决不同类别之间数据不均衡的问题
3)label smothing==>>One-hot编码之后label没有关联,将hard label转换成soft label
4)知识蒸馏 knowledge distillation
(3)设计BBox回归的目标函数
1)传统的目标检测方法使用均方根误差Mean Square Error (MSE)直接对BBox的中心坐标、宽、高进行回归,即 { x_center, y_center, w, h },或者对左上角和右下角进行回归,即{ x_top-left, y_top-right,x_bottom-left,y_bottom-right }
**2)基于锚点的方法 anchor-based method:**估计偏移量,如{ x_center-offset,y_center-offset,w_offset,h_offset}和 {x_top-left-offset,y_top-left-offset,x_bottom-right-offset,y_bottom-right-offset}。
==>>1)和2)预测Bbox每个点的坐标值是将这些点作为独立的变量,但是实际上并没有将目标物体当成一个整体进行预测,因此3)
**3)IoU 损失函数:**将Bbox区域和ground truth的BBox区域的作为整体进行考虑。IoU损失函数需要计算BBox四个坐标点以及ground truth的IoU。(IoU具有尺度不变性,它可以解决传统算法比如l_1}和 l_2范数计算 {x,y,w,h}存在的问题,这个损失函数会随着尺度的变化而发生变化。)。如:GIoU loss除了包含覆盖区域外,还包含对象的形状和方向,DIoU loss考虑了物体中心的距离;CIoU loss同时考虑了重叠面积、中心点之间的距离和纵横比
2、Bag of specials(Bos):增加少许的计算量cost提高精度
(1)扩大感受野enhance receptive field:SPP、ASSP、RFB

(2)注意力attention 机制:channel-wise attention和point-wise attention。
channel-wise attention: Squeeze-and-Excitation (SE):top-1准确率accuracy提高1%,CPU计算提高2%,GPU计算提高10%==>>适合移动端
point-wise attention:Spatial Attention Module (SAM):top-1准确率accuracy提高0.5%,CPU计算提高0.1%,不影响GPU的推理速度
(3)特征融合feature integration:
早期:底层的物理特征low-level physical feature和高级的语义特征high-level semantic feature融合,如skip connection、 hyper-column。
特征金字塔:SFAM, ASFF和BiFPN
SFAM:使用SE模块对多尺度feature map进行channel-wise
ASFF:采用softmax进行point-wise加权,然后将不同尺度的feature map相加
BiFPN:使用多输入权重残差连接进行scale-wise
**(4)激活函数activation function:**一个好的激活函数能够使得梯度传播的更高效,并且不会增加额外的计算量。
ReLU:解决传统tanh和sigmoid激活函数中经常遇到的梯度消失的问题;
LReLU和PReLU:解决当输出<0时,ReLU梯度为0的问题;
ReLU6和hard-Swish:为量化网络设计的;
SELU:神经网络自归一化;
Swish和Mish:连续可导
(5)后处理 post-processing :
NMS:过滤效果不好的BBox,保留效果好的BBox;
Girshick:在R-CNN中添加置信度得分作为参考,根据得分从高到底执行 greedy NMS;
soft NMS:在greedy NMS使用时,物体遮挡会导致置信度得分下降
DIoU NMS:在soft NMS上将中心点的距离信息添加到BBox中
【注】anchor-free方法不再后处理。
那么,YOLO v4的结构是什么呢?

在结构上,YOLO v4和YOLO v3的对比,此外,YOLO V4还运用了很多BoF和BoS的技巧。
1、网络结构
在结构上,YOLO v4和YOLO v3的对比:
| YOLO V3 | YOLOV4 | |
|---|---|---|
| Backbone | DarkNet53 | CSPDarkNet53 |
| Neck | FPN | SPP+PAN |
| Head | YOLO V3 | YOLO V3 |
YOLO v4 主干网络Backbone所用的是CSPDarknet53(YOLO v3用的是Darknet53),那么前面加个CSP有什么优点呢。CSPNet源自论文“ CSPNet:A new backbone that can enhance learning capability of cnn”,全称叫“Cross Stage Partial Network(CSPNet)”。CSPNet可以增强CNN的学习能力,通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet可以和Backbone结合,如ResNet、ResNeXt和DenseNet,这不就和Darknet53结合一起成为了YOLO v4 主干网络CSPDarknet53。CSPNet的优点:
1、增强CNN的学习能力,能够在轻量化的同时保持准确性。
2.降低计算瓶颈。
3.降低内存成本。
YOLO v4 的结构如下:
Backbone:CSPDarknet53,提取图像中的浅层特征(low-level),如提取边缘,颜色,纹理等。
Neck:SPP+PAN。SPP:增强感受野,分离出上下文特征,不降低允许速度。PANet:为不同检测器不同的backbone选择参数聚合(YOLO v3是FPN)
不同尺寸的感受野的总结:
等于目标物体的大小时:能够看到整个对象
等于网络的大小:能够看到对象周围的上下文信息
大于网络的大小:增加图像点和最终激活之间连接的数量
Head:YOLO Head,直接得到bbox。
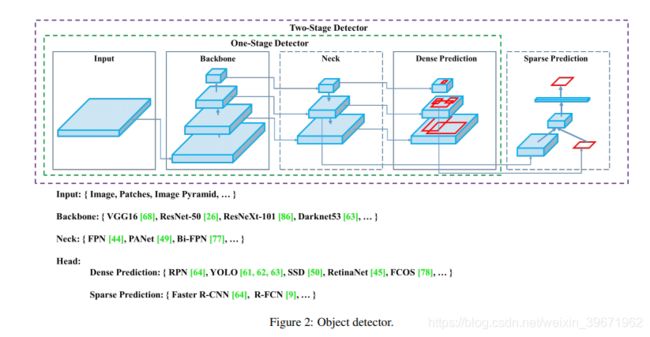
(Object Detection = Backbone + Neck + Head)
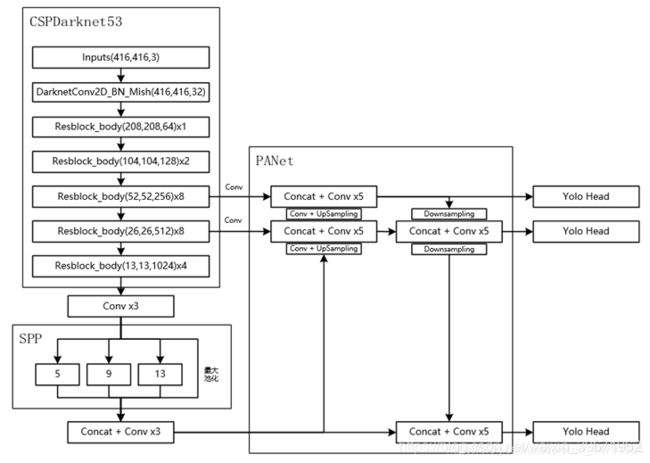
(1)Backbone:CSPDarknet53。
由上图可以看出,CSPDarknet53包含了5个CSP模块,如下图。输入图像是608×608,经过5次CSP模块后,得到特征图大小是608×608。
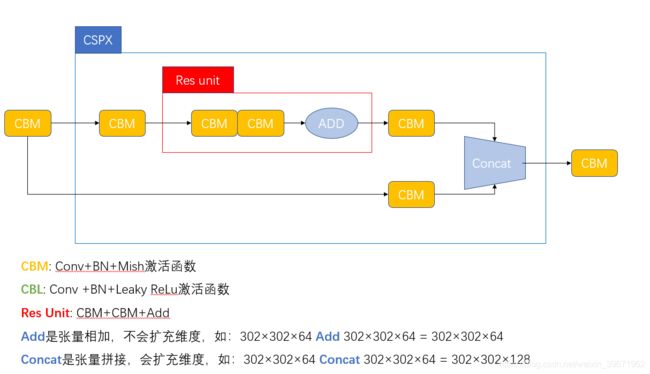
激活函数:Mish。在Backbone中,YOLO V4采用的是Mish激活函数,不过在后面(Neck和Head)中,采用的是Leaky ReLu。
(2)Neck:SPP+PANet
YOLO V4中说了蛤,常用的Neck有:

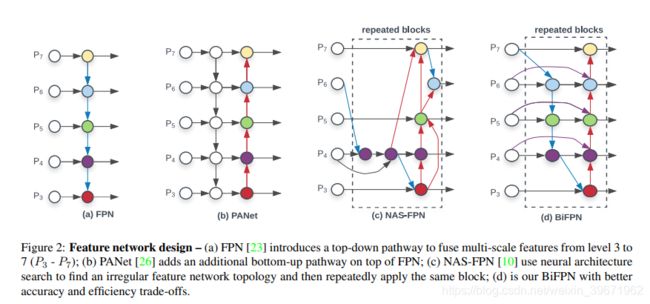
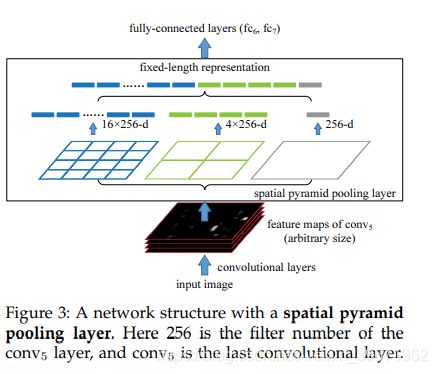
SPP===>>>空间金字塔池化(Spatial Pyramid Pooling,SPP)
SPP源于论文“Spatial pyramid pooling in deep convolutional networks for
visual recognition”
传统的CNN由于全连接层的存在,限制了输入必须固定size和scale,所以在实际使用中往往需要对原图片进行crop(截取固定大小的patch)和warp(缩放固定大小的patch)的操作,crop操作导致物体可能会被截断,warp操作导致物体变形,无论是是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中。因此,引入SPP,通过SPP来一处CNN对固定输入的要求。Spp是一个处理multi-scale和multi-size灵活的方法,增加CNN的鲁棒性,提升分类效果。

PANet===>>>路径聚合网络 (Path Aggregation Network, PANet)
PANet源于论文“Path aggregation network for instance segmentation”
PANet获得COCO2017实例分割第一,目标检测第二。
PANet旨在提升基于侯选区域的实例分割框架内的信息流传播。通过自下向上(bottom-up)的路径增强在较低层(lower layer)中准确的定位信息流,建立底层特征和高层特征之间的信息路径,从而增强整个特征层次架构。
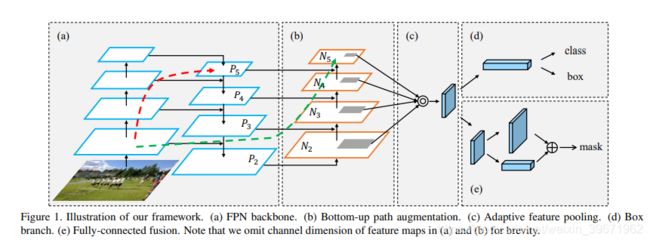
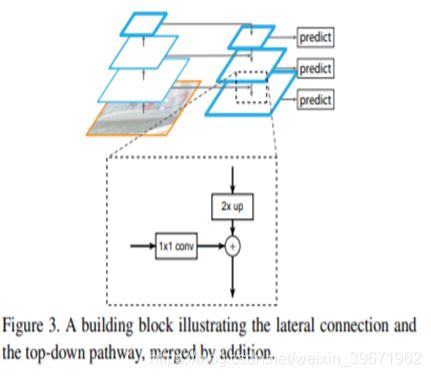
(a)FPN (红线部分):包括一个自底向上(网络的前向过程,这样就能构成特征金字塔)的线路,一个自顶向下(采用上采样upsampling)的线路,横向连接(将上采样的结果和自底向上生成的相同大小的feature map进行融合)。
(b)自下而上(bottom-up)的增强路径(绿线部分):用于缩短信息路径,利用low-level 特征中存储的精确定位信号,提升特征金字塔架构。
(c)自适应特征池化(Adaptive feature pooling):用于恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免任意分配的结果。
此外,YOLO V4还运用了很多BoF和BoS的技巧。

在目标检测训练中,通常对CNN的优化改进方法:
激活函数Activations:ReLU,leaky-ReLU,parameter-ReLU,ReLU6,SELU,Swish或Mish
BBox回归loss函数Bounding box regression loss:MSE,IoU,GIoU,CIoU,DIoU
数据增强Data augmentation:CutOut,MixUp,CutMix,Mosaic
正则化Regularization method:DropOut,DropPath,Spatial DropOut或DropBlock
通过均值和方差对激活函数进行归一化Normalization of the network activations by their mean and variance:Batch Normalization (BN), Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN), or Cross-Iteration Batch Normalization (CBN)
跨连接Skip-connections:Residual connections, Weightedresidual connections, Multi-input weighted residualconnections (MiWRC), or Cross stage partial connections (CSP)

| Backbone | Neck | Head | |
|---|---|---|---|
| CSPDarknet53 | SPP+PAN | YOLOv3 Head | |
| BoF | CutMix and Mosaic data augmentation, DropBlock regularization,Class label smoothing | - | CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single groundtruth, Cosine annealing scheduler , Optimal hyper parameters, Random training shapes |
| BoS | Mish activation, Cross-stage partial connections (CSP), Multi-input weighted residual connections (MiWRC) | - | Mish activation, SPP-block, SAM-block, PAN path-aggregation block,DIoU-NMS |
| 作用 | 预训练 | 多尺度特征图融合 | 预测 |
(5)YOLO V5
2020年6月,Ultralytics发布了YOLOV5
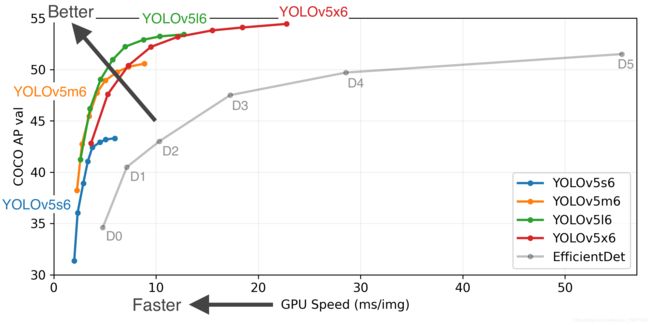
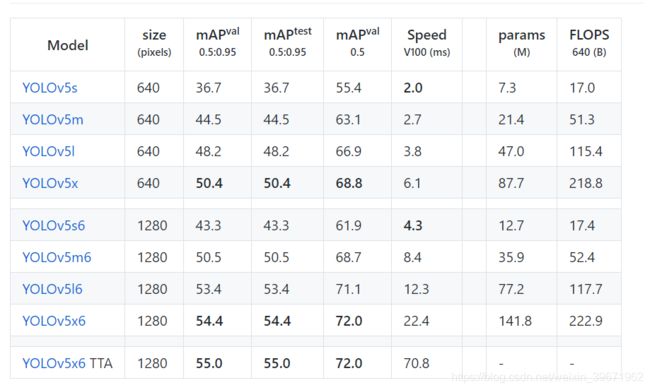
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。YOLOV5相对于YOLOV4来说创新性的地方很少,不过它还是很快的
3.2 SSD系列
(1)SSD
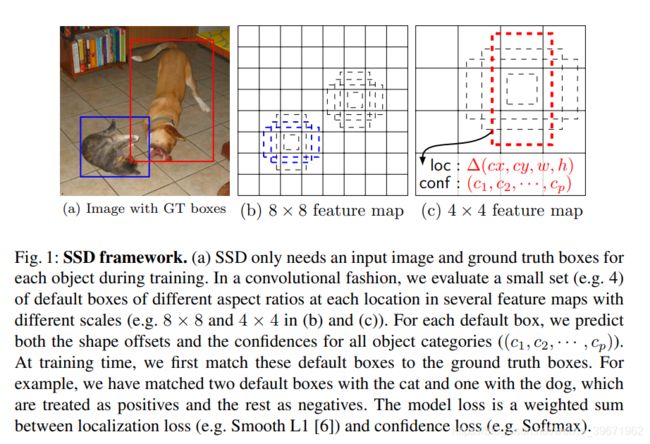
2016年,Single Shot MultiBox Detector
对于300×300的输入,SSD在VOC2007test,可达到74.3%mAP,59FPS;对于512×512的输入,SSD达到了76.9 % mAP
SSD优点:
1、比Faster R-CNN要快,比YOLO要准确(这里指YOLO v1)
2、多尺度特征图预测
3、低分辨率的输入图像上实现简单的端到端训练和高精度
SSD的整体框架:
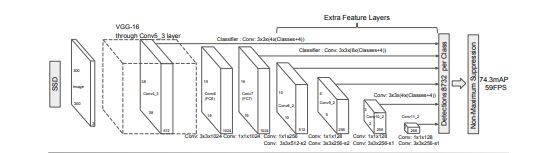
1、SSD的Backbone采用VGG16(把VCC16的FC6和FC7换成了卷积层,FC6==>>Conv6,FC7==>>Conv7),移除dropout层和fc8层
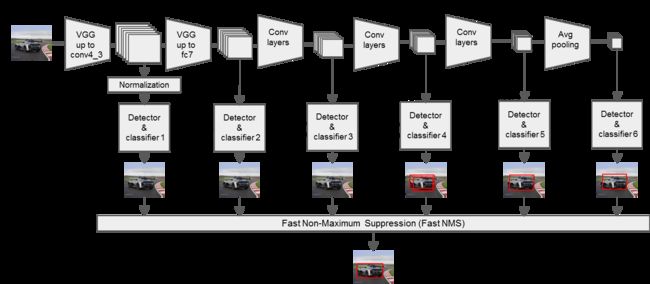
2、多尺度feature map:抽取了Conv3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2共6个feature map构造不同的BBox,大的feature map检测小目标,小的feature map检测大目标(如下图,直观一点)
输入:300×300×3
Conv3:38×38×512==>缩小了8倍
Conv7:19×19×1024==>缩小了16倍
Conv8_2:10×10×512==>缩小了32倍
Conv9_2:5×5×256==>缩小了64倍
Conv10_2:3×3×256==>缩小了128倍
Conv11_2:1×1×256==>缩小了256倍
3、将上述6个feature map获得的BBox结合起来,利用NMS抑制效果不好的BBox,得到最终的结果。
(2)FSSD
2017CVPR,FSSD: Feature Fusion Single Shot Multibox Detector
FSSD在VOC2007test获得82.7mAP,65.8FPS
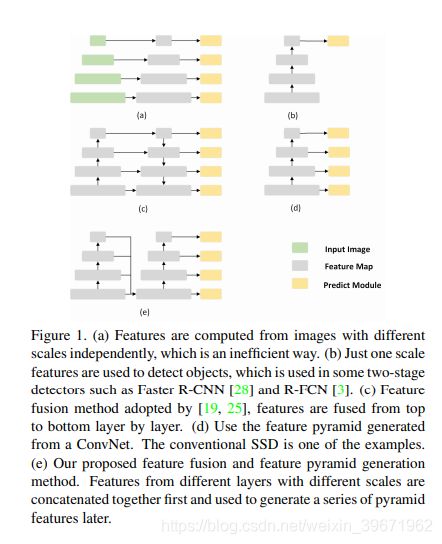
在目标检测中,为了解决多尺度目标检测问题,有如下方案:
图a:图像金字塔Featurized image pyramid:将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法增加了时间成本。
图b:单尺度的特征图single feature map,采用最后一层的特征进行预测,常用于two-stage的检测中,如RCNN系列。该方法在单尺度feature map 固定感受野,很难覆盖到尺度变化的目标。
图c:特征金字塔feature pyramid network(FPN),顶层特征通过上采样和底层特征进行融合。自底向上(网络的前向过程)、自顶向下(采用上采样upsampling)、横向连接(将上采样的结果与自底向上生成的相同的feature map 进行融合)。该方法比较耗时,需要多次做concate、 element-wise等操作。
图d:SSD的多尺度特征融合方式,从网络不同层抽取不同尺度的feature map做预测。但SSD中没用到足够的浅层特征,不利于小目标检测。
图e:FSSD。在SSD上新增了一个轻量型的特征融合模块,通过轻量型的结构来达到融合高低层feature的目的。
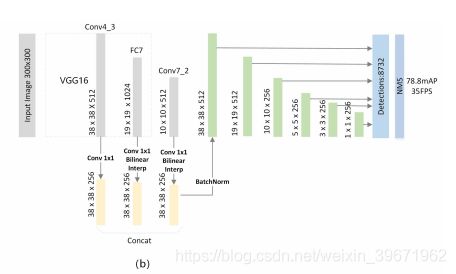
FSSD架构:
(1)Backbone为VGG16,融合了conv4_3、FC7、conv7_2,新增层conv6_2、conv7_2、conv8_2、conv9_2构成目标检测层,feature map的尺度大小分别为:38×38、19×19、10×10、5×5、3×3、1×1,作者认为feature map小于10×10包含的信息太少,因此使用conv3_3、conv4_3、FC7、conv7_2做特征融合(实验中,conv6_2的步长s=1,因此conv7_2也是10×10),但融合conv3_3后性能没有提高。 == >> 融合conv4_3、FC7、conv7_2。
(2)将conv4_3、FC7、conv7_2使用1×1的卷积层降维到256,FC7、conv7_2用双线性插值做上采样,缩放至同一尺寸38×38,然后进行concat融合操作,再加个BN层正则化。
(3)FSSD将融合后的feature map 生成新的特征金字塔,3种特征金字塔的生成方式如下:
(a):fusion feature map也参与了预测 => 78.2mAP
(b):fusion feature map没有参与预测 => 78.8mAP
©:将simple bolok Conv+ReLU替换成了bottleneck block(2个Conv+ReLU) => 78.4mAP

(3)DSSD
2017,DSSD : Deconvolutional Single Shot Detector
DSSD在VOC2007test获得81.5%mAP,VOC2012test获得80.0%mAP,COCO获得33.2%mAP
SSD对于小目标物体的检测效果不够理想(虽然浅层的feature map容易定位小目标,但是浅层feature map没有充分的语义信息,因此很难对目标进行准确的分类),为了提高小目标物体检测的精度,提出了DSSD。
DSSD主要做了以下方面的改进:
1、把SSD中使用的Backbone VGG-16换成了Resnet-101,增强特征提取能力;
2、使用反卷积层增加上下文信息
DSSD框架:
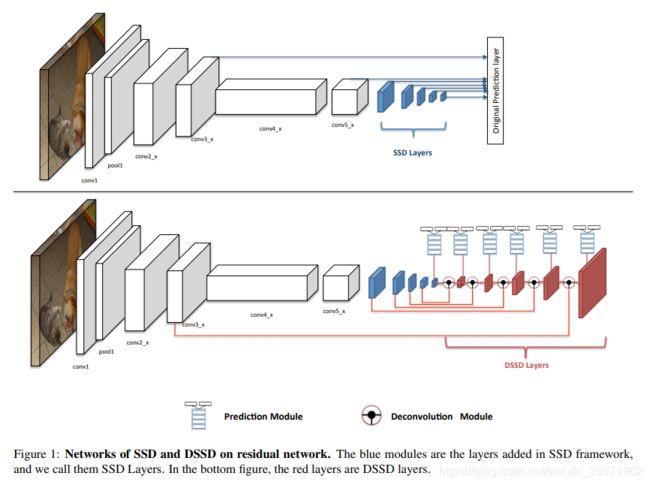
1、backbone:Resnet-101
把SSD中使用的VGG-16换成了Resnet-101,两者对比如下图。(DSSD中,红色的为反卷积层),但Backbone为Resnet-101的SSD的准确率比VGG的低。(Resnet-101的为76.4,VGG为77.5)
2、预测模块prediction module
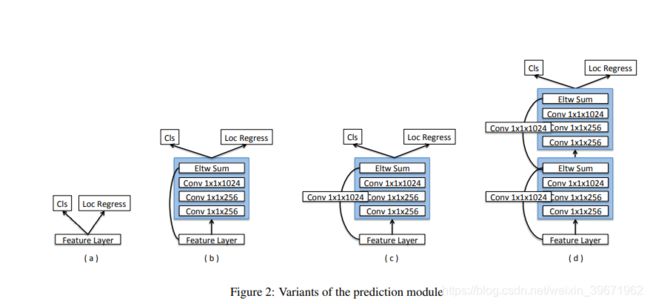
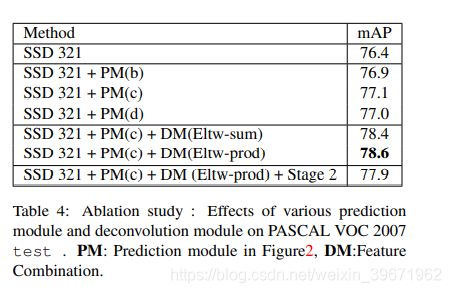
SSD中在feature layer中直接输出Cls(类别)和Loc Regress(坐标),这导致计算量很大,如图a(76.4mAP)。MS-NNS中指出,改进每个任务的子网可以提高准确性。因此,DSSD在每个预测层添加了残差块:图b添加了一个残差块,但是跳过了连接(76.9mAP);图c添加了1个残差块(77.1mAP);图d添加了两个残差块(77.0mAP)。结果表明,增加残差预测模块后,检测准确率比原来的SSD的精度提高了。
3、反卷积模块Deconvolution Module
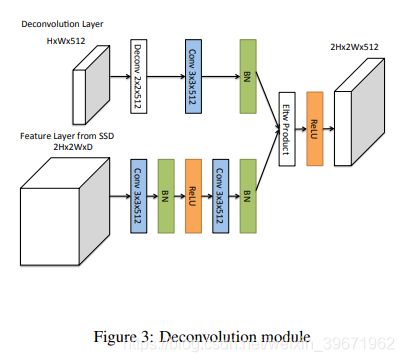
为了整合浅层特征图(Feature Layer from SSD)和反卷积层(Deconvolution Layer)的信息,作者引入反卷积模块,如下图:
(1)每个卷积层后面都添加了BN(Batch Normalization)
(2)反卷积层参与训练,而不是简单的双线性插值
(3)测试了不同的结合方式:元素求和 element-wise sum(78.4mAP)和元素点积element-wise product(78.6mAP),结果表明元素点积element-wise product的效果要好
以后会继续补充阿,尤其是YOLO V4给了那么多Tricks:
1、深度学习中的网络结构backbone汇总;
2、Neck汇总;
3、激活函数汇总;
······
参考:
1、一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
2、纹理特征简介
3、目标检测之YOLO算法:YOLOv1,YOLOv2,YOLOv3,TinyYOLO,YOLOv4,YOLOv5,YOLObile,YOLOF详解
4、实例分割–(PANet)Path Aggregation Network for Instance Segmentation