PyTorch源码学习系列 - 1.初识
本系列文章会优先发布于微信公众号和知乎,欢迎大家关注
微信公众号:小飞怪兽屋
知乎: PyTorch源码学习系列 - 1.初识 - 知乎 (zhihu.com)
目录
本系列的目的
PyTorch是什么?
我理解的PyTorch架构
PyTorch目录结构
第一次动手编译
如何调试程序
本系列的目的
平时工作中经常会用到PyTorch, 但由于工作性质,往往只停留在PyTorch的应用层面。某天突发奇想想研究学习下PyTorch的架构以及底层源码,毕竟做为一名算法工程师,算法能力和工程能力相辅相成,缺少工程能力的算法能力如空中楼阁,华而不实。无意中发现网上关于PyTorch源码的相关介绍非常少,很多都浅尝辄止,有的也仅仅介绍了部分Python源码。于是就创建了这一系列来记录自己的学习过程,同时也鞭策自己可以将这个系列一直写下去。哈哈~ 磨刀不误砍柴工,学习的目的也是为了更多的工作产出。
PyTorch是什么?
PyTorch是当下最流行的开源深度学习框架之一。由于其简单易用性,深受广大科研工作者的喜爱。其前身是一个以Lua语言为主的Torch项目。在2016年,Meta(原Facebook)公司基于Torch开发了基于Python的PyTorch框架,并于2017年1月将其开源。在2022年9月12日,Meta公司宣布将PyTorch项目归入Linux基金会旗下的PyTorch基金会管理。
PyTorch本身是一个Python扩展包,按照官方说法它主要具有以下两种特色:
-
支持GPU加速的张量(Tensor)计算
-
在一个类似磁带(前向和反向)的梯度自动计算(Autograd)系统上搭建深度神经网络
Tensor其实本质上就是一个多维数组。在数学上单个数据我们称之为标量,一维数据我们称之为向量,二维数据我们称之为矩阵。GPU就是图形处理单元,也就是我们平时说的显卡。它的优势在于它比CPU具有更快的浮点数运算能力,在游戏,科学计算,深度学习领域都有广泛的应用场景。
如果PyTorch仅是支持GPU加速的Tensor计算框架,那它也就是NumPy的替代品而已。其最核心的功能就是Autograd系统,目前深度学习就是基于梯度反向传播理论来达到网络的自我训练。PyTorch的Autograd系统是创建了一个动态的计算图,用户只需要关注前向计算网络搭建,PyTorch会自动根据动态计算图去反向计算梯度并更新网络权重。
在设计之初PyTorch并没打算仅成为一个绑定C++框架的Python包,它紧密地将C++框架集成到python中。你可以在使用PyTorch的同时也结合使用NumPy/SciPy/scikit-learn这些优秀的科学计算包,同时你也可以用Python编写你自己的神经网络层(PyTorch神经网络相关的代码基本上都是Python编写)。
基于以上特性,你可以很容易地通过PyTorch来快速实现自己的深度学习网络,并且PyTorch的代码调试也非常直观。正如前面所说,PyTorch的计算图是动态的,当你写下一行Python代码的时候你就可以直接运行得到结果。对用户来说,PyTorch的世界就是一个简单的单线程同步非阻塞世界,你可以得到实时反馈,这对于刚开始接触深度学习的新手来说是非常贴心的功能,可以帮忙新手快速入门。
我理解的PyTorch架构
根据自己的理解简单画了下PyTorch的架构图,隐藏了部分细节。本系列也将主要围绕着这张架构图去学习PyTorch的具体实现。
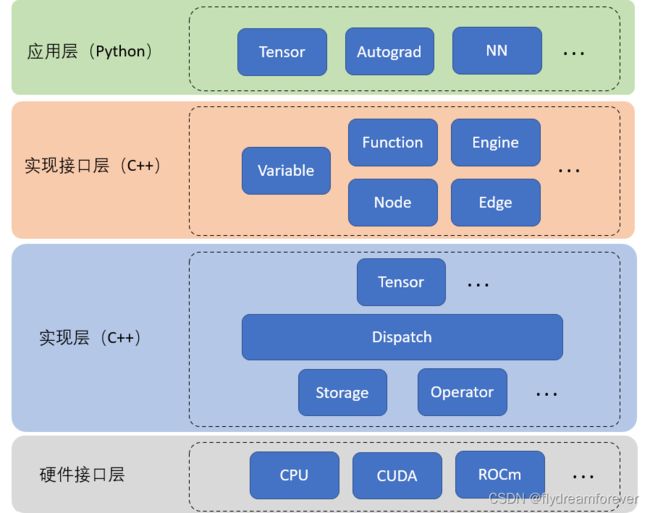
架构图
一共将PyTorch分成了四层,分别是
-
应用层(Python)。这应该是大家最熟悉的层,主要涉及到张量,Autograd以及神经网络。该层所有的源码都是由Python编写,这也符合前面所说的PyTorch设计思想-——将C++框架集成到Python里
-
实现接口层(C++)。该层的主要功能我认为有两个:
-
Python 扩展。通过Python提供的C API将Python应用层与C++实现层绑定起来,使用户在享受Python语言提供的便捷优势时也可以同时享受到C++语言提供的性能优势
-
Autograd系统实现。 PyTorch并没有在实现层中实现Autograd系统。在此层中PyTorch定义了动态有向图的基本组件Node和Edge,以及在此基础上封装了Function类和Engine类来实现Autograd
-
-
实现层(C++)。该层是PyTorch的核心层,定义了PyTorch运行过程中的核心库, 包括Tensor的具体实现,算子实现(前向与后向运算)以及动态调度系统(Tensor的布局,硬件设备,数据类型)。Storage类主要是针对不同硬件数据存储的一种抽象。
-
硬件接口层。该层主要是硬件厂商基于自家硬件推出的运算接口。
PyTorch目录结构
PyTorch的源码托管于GitHub平台,其目前的代码量已经非常巨大。新手第一次接触的时候往往会因此被劝退,但其实里面很多文件和我们学习PyTorch源码并没有太多的直接关系,所以我们第一步就是要理清目录结构,专注于我们需要学习的内容。
-
torch:我们“import torch”后最熟悉的PyTorch库。所有非csrc文件夹下的内容都是标准的Python模块,对应我们架构图中的应用层
-
csrc:该目录下都是C++源码,Python绑定C++的相关code都在这个目录里面,同时也包含了对PyTorch核心库的一些封装,对应我们架构图中的实现接口层
-
csrc/autograd:梯度自动计算系统的C++实现
-
autograd:梯度自动计算系统的Python前端源码,包含torch中支持的所有自动求导算子
-
nn:建立在autograd系统上的神经网络库,包含了深度学习中常用的一些基础神经网络层。
-
optim:机器学习中用到的优化算法库
-
-
aten:“a tensor library”的缩写,对应我们结构图中的实现层。从名字上也能知道,这个库设计之初主要是为Tensor服务。因为在实现接口层下面,所以这里的Tensor并不支持autograd
-
src/Aten/core:aten的核心基础库。目前这个库里面的代码正在逐渐地迁移到c10目录下面
-
src/Aten/native:PyTorch的算子库,这个目录下面的算子都是CPU的算子。对于一些专门CPU指令优化的算子会在子目录里面
-
src/Aten/native/cuda:cuda算子实现
-
-
c10:“caffe2 aten”的缩写,PyTorch的核心库,支持服务端和移动端。
-
tools:PyTorch中很多相似源码都是脚本通过模板自动生成的,这个文件夹下面就放着自动生成代码的脚本
第一次动手编译
学习一个新的开源项目的时候,第一件要做的事情永远都是编译源码。只有源码编译成功后,你才有机会一步一步的debug源码,了解每一行源码的具体功能。目前PyTorch很多源码都是通过脚本自动生成的,无法在GitHub上直接查看,只有编译成功后才能在相关目录里看到。推荐新手第一次编译的时候选择Linux系统,可以大大简化编译过程。与此同时,我们可以只编译CPU算子,忽略部分当前不需要的模块(如cuda算子,ROCm算子,test模块),这样可以最大程度地帮助我们减少源码编译时间,让我们更加专注于我们需要学习的部分。虽然GPU支持才是深度学习框架最核心的特色,但是我们学习源码最开始主要是需要弄懂整个框架的架构以及设计思想。GPU支持已经被隐藏在整个框架的最底层,当你学会了CPU算子是如何实现的时候,你就可以很容易地切换到GPU算子。麻雀虽小,五脏俱全,专注于CPU版本可以让我们更加快速的掌握整个框架,何乐而不为?
由于PyTorch迭代很快,可以参考GitHub README.md了解当前版本编译需要的Python版本和C++编译器版本。我直接安装了一个Ubuntu 20.04.4 LTS虚拟机和最新的Anaconda,如果你不想在环境上消耗太多时间,直接无脑选择最新版本就对了。
安装好工具后就需要开始准备编译源码了
步骤一,安装依赖。主要就是在conda环境里面安装编译需要用到的工具包
conda install astunparse numpy ninja pyyaml setuptools cmake cffi typing_extensions future six requests dataclasses步骤二,下载源码
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursive --jobs 0步骤三,在shell命令行里面修改编译环境变量。这里修改主要就是只编译CPU的Debug版本,这样我们后面就可以用GDB去调试PyTorch。
DEBUG=1 USE_DISTRIBUTED=0 USE_MKLDNN=0 USE_CUDA=0 BUILD_TEST=0 USE_FBGEMM=0 USE_NNPACK=0 USE_QNNPACK=0 USE_XNNPACK=0步骤四,编译安装PyTorch。这里使用develop命令可以让你的Python解释器将PyTorch包直接链接到源码位置,你对Python源码的所有修改可以直接立马在Python解释器中体现。
python setup.py develop当shell提示成功之后,我们可以打开torch/__init__.py,在里面输入下面两行code
print("FileName: " + __file__ + '\n')
print("Welcome To PyTorch Source Code World\n')保存后打开自己的python导入torch包,你会得到下面的提示
>>> import torch
FileName: /data/Project/pytorch/torch/__init__.py
Welcome To PyTorch Source Code World如果你在编译过程中遇到“fatal error: ld terminated with signal 9 [Killed]”的错误提示,这是因为你的机器内存不够,你可以增加内存或者swap空间,一般DEBUG版本的编译会比RELEASE需要更多的内存,推荐内存12GB+
如何调试程序
当你编译时候设置了DEBUG=1,你就可以按照以下步骤使用GDB去调试PyTorch。
步骤一:进入到PyTorch源码根目录,使用GDB运行python
$ gdb python步骤二:设置断点,比如我们想debug下aten库里面add算子,输入以下break指令。这里会提示你找不到add这个符号是因为PyTorch的c++代码都编译成了动态链接库,不是直接静态编译到python里面,直接忽略,选择Y就行
(gdb) break at::Tensor::add
Function "at::Tensor::add" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (at::Tensor::add) pending.步骤三:run 简单的Python测试脚本
(gdb) run
>>> import torch
FileName: /data/Project/pytorch/torch/__init__.py
Welcome PyTorch Source Code World
>>> a= torch.Tensor([1,2])
>>> b= torch.Tensor([1,2])
>>> a + b这个时候你就会得到gdb的提示发现断点
Breakpoint 1, 0x00007fffef0d8690 in at::Tensor::add(at::Tensor const&, c10::Scalar const&) const@plt ()
from /data/Project/pytorch/torch/lib/libtorch_python.so然后你就可以用gdb的命令开始debug程序,理解程序的功能。PyTorch还提供了一个“torch-tensor-repr”命令可以输出可读性比较好的Tensor表示,类似python中Tensor的输出。
(gdb) n
Single stepping until exit from function _ZNK2at6Tensor3addERKS0_RKN3c106ScalarE@plt,
which has no line number information.
Breakpoint 1, at::Tensor::add (this=0x7f00f786b878, other=..., alpha=...) at aten/src/ATen/core/TensorBody.h:1595
1595 inline at::Tensor Tensor::add(const at::Tensor & other, const at::Scalar & alpha) const {
(gdb) n
1596 return at::_ops::add_Tensor::call(const_cast(*this), other, alpha);
(gdb) p *this
$2 = { = {impl_ = {target_ = 0x555558572ad0}}, }
(gdb) torch-tensor-repr *this
Python-level repr of *this:
tensor([1., 2.]) 