读论文(5)——DETR
前言
我们前面学习了这么多目标检测方面的文章,没有一个方法是完完全全能够实现端到端检测,无任何人为引入、手工设计的先验知识的方法,我们十分渴望能出现一个端到端的方法,且这个方法在性能上是可用的。CV领域的方法似乎已经被我们翻了个底朝天了,那么我们能不能从别的领域找灵感呢?DETR就是一个从NLP领域找到解决思路的方法。
原论文题目为《End-to-End Object Detection with Transformers》,从题目中就可以看出,本文借鉴了Transformer这个方法实现了端到端的目标检测。那么到底是如何借鉴的,Transformer又是何方神圣呢?
Attention机制与Transformer
Transformer来源于一篇大名鼎鼎的论文《Attention Is All You Need》,用来解决机器翻译中的问题。最早的机器翻译使用RNN作为基本方法,因为其能很好的学习到单词序列关系,进而学习出句子意义,但是RNN并不擅长解决输入语言和输出语言单词数量不一致的N-to-M问题。这时人们设计出了Seq2Seq方法,这种方法主要依赖于Encoder和Decoder进行翻译,输入序列先由Encoder转化为句子的原始意义,再由Decoder输出为目标语言的序列。
不过Encoder和Decoder仍然是RNN网络,只不过借助提取的句子意义作为中介,解决了输入输出数量不对应的问题。但是人们发现如果输入的句子太长,提取出来的意义就不会十分精确。为了解决这个问题,人们又找到了注意力机制(Attention)。
Attention是一种简化机制,其可以在很多输入中找出对当前输出最重要的部分。一个典型的Attention包括Q(query)、K(key)和V(value)三部分。首先Q在目标输出中,K和V都在原始输入信息中,通过计算Q与每个K之间的相关性,并乘上对应的V就可以计算出对应的Attention,如下面公式所示:
![]()
详细一点的计算过程如下图所示:

借助Attention机制,我们在生成每个单词时,都有意识的从原始句子中提取出相关的最需要的信息,摆脱了对输入长度的限制。但是这样的计算方式实在太慢了,因为作为Encoder的RNN需要逐个看过句子中的单词,才能给出输出。
进一步,人们又找到了自注意力机制(self-attention)。自注意力机制仅仅关注输入序列元素之间的关系,将输入元素序列转化为QKV然后在内部做Attention计算,这样就能捕捉到输入元素序列的内在联系,然后对其做出再表示。
对于机器翻译问题,可以先提取每个单词的意义,再依据生成顺序选取所需要的信息,这种方法完全摆脱了RNN的体系,称之为Transformer。Transformer整个网络结构由且仅由self-Attenion和Feed Forward Neural Network组成。对于Encoder来说,就是一个self-Attention和FFN直接相连。self-Attention的计算如下公式所示:

FFN这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
![]()
这个Z就是上面算出来的Attention。
Encoder和Decoder的结构如下图所示:
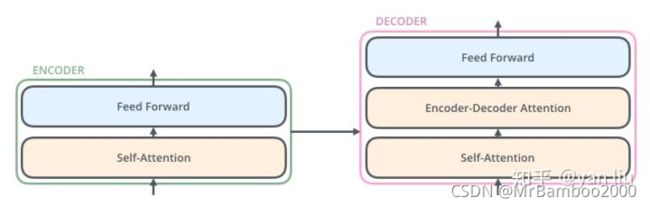
可以看出Decoder还额外多了一个Encoder-Decoder Attention的模块,在Decoder中,Self-Attention表征当前翻译和已经翻译的前文之间的关系,Encoder-Decnoder Attention表征当前翻译和编码的特征向量之间的关系,因此,网络总体结构如下图所示:

Tranformer使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。但是同时,它粗暴的抛弃了RNN+CNN的结构,导致丧失了捕捉局部特征的能力;它在处理的过程中也丢弃了位置信息,这个显然是很重要的。
那么这和目标检测有什么关系呢?应该首先说明的是,Attention这个概念本身,其实是从计算机视觉的研究中首先被提出的,因为由于人眼看世界接受的信息太多,所以只集中精力处理自己需要的的部分就可以,而这个思路又正好与目标检测任务相符合。而且像我们之前了解到的局部特征提取、滑窗法本质上都是Attention思想的一种体现,而Transformer不过是借助了Encoder-Decoder结构的对Attention机制的另一种应用,因此我们推测其用于目标检测是可行的。
说完可行性,下面我们通过原文来看看引入Transformer后的优越性在哪。
设计思路
我们直接通过论文中的一张图来了解DETR的设计思路:
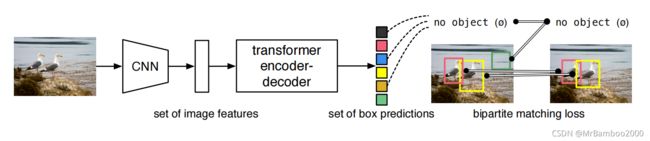
原始图片直接送入CNN提取特征,然后将CNN提取的特征送入到Transformer中,在Transformer中编码之后,送入到解码器,解码器将结果转化为class和box,输出固定个预测结果,最后将检测结果和ground truth进行二分图最佳匹配,计算loss。
这个过程中有两个非常重要的思想,一个是将Transformer引入了目标检测领域,一个是将目标检测问题转化成了Set Prediction(集预测)问题。前者的好处是可以将Transformer的全局计算能力和完美的记忆能力优势发挥出来,并且实现了并行处理,为目标检测提供新思路;后者的好处是Set Prediction能够避免重复的预测,实现“一对一”的预测,这样就能去除掉NMS等后处理手段,实现了端到端的检测,无需人工先验知识的设定。
下面来用另一张图看看具体的设计。
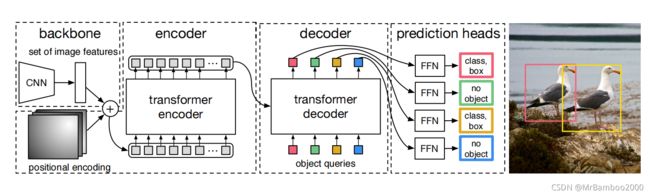
首先来看backbone部分,这个部分还是很常规的使用了CNN去做特征提取,由原始输入的3×H0×W0转化成输出低分辨率的激活图C×H×W,一般C取2048,H取H0/32,W取W0/32。
然后是encoder部分,1x1卷积将激活图f的通道维数从C降低到更小的维数d,产生新的d×H×W的特征映射z0。由于encoder需要输入一个序列,那么再把z0改成d×HW的特征。每个编码器由一个多头的自注意模块和FFN网络组成(多头就是用多种方法生成attention然后再综合)。由于Transformer是位置无关,所以为了保持位置信息,需要送入CNN特征的同时,也要送入位置的编码信息,确保整个链路中位置信息不丢失。这个位置信息个人理解就是Transformer原始论文中的positional embedding。
在Transformer原始论文的设计中,positional embedding采用sin和cos来表示位置信息(或者说顺序信息)。具体的计算方式如下图所示:
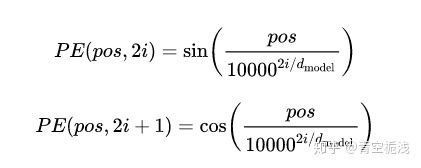
用周期函数保证在一定范围内的编码差异不依赖于序列的长度,这样长序列的相对次序关系不会被稀释;用分母上的函数保证在不同维度上应该用不同的函数操纵位置编码,这样使得高维的表示空间有意义。上图定义方式使得每一维度上都包含了一定的位置信息,而各个位置字符的位置编码又各不相同。
接下来是decoder部分。该部分将encoder编码后的输出(K和V)送入的同时也送入一组object queries(Q),N个对象以及encoder的输入在decoder的综合作用下,获取N个输出,这N个输出在FFN的作用下,产生N个位置(box)以及每个位置对应的类别(class)。与原始Transformer不同的是,decoder每一层都输出结果,即在每个decoder层并行解码N个对象。
那么这个object query是什么呢?object queries是一组可学习的embedding,与当前输入图像的内容无关(不由当前图像内容计算得到)。论文中对不同object query在COCO数据集上输出检测框的位置做了统计(如下图所示),可以看不同object query是具有一定位置倾向性的。我们可以理解为object query是在问问题,在问这个图片的哪个部分有什么。比如下图,第一行左起第一个就是表明在问偏左下的地方有什么。
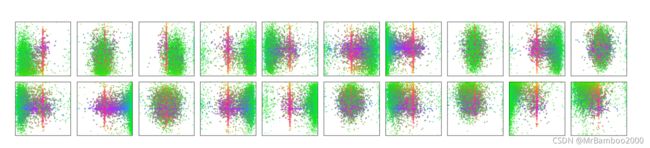
需要说明的是,可以通过预先设定objects queries数目(N)来控制decoder输出检测结果数目,因此为了后面计算loss的时候给每一个ground truth分配到一个预测结果,需要保证N大于单张数据最大ground truth的数量。
至此,模型已具备了目标检测能力,最后就是将N个预测值与真值对应。这里由于采用了直接集预测,因此变成了一个最大二分匹配问题。本文求解方法采用的匈牙利算法。
暂停一下简单介绍一下二分匹配与匈牙利算法。
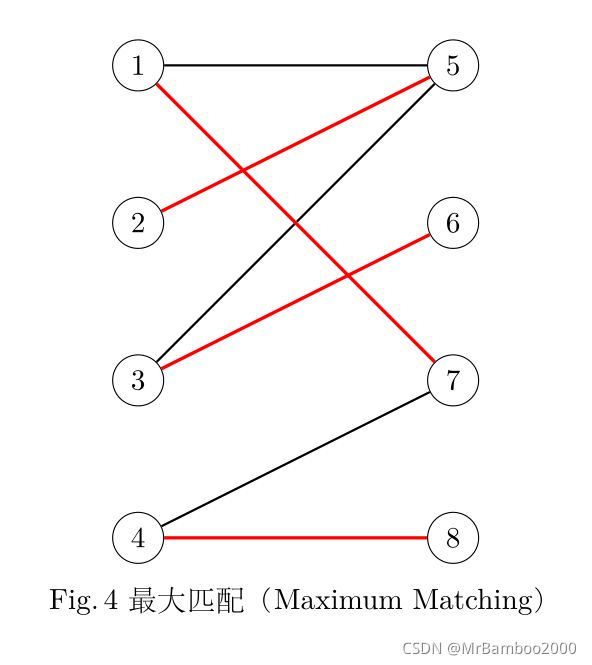
二分图是指顶点可以被分成两个不相交的集合,并且同属一个集合内的点两两不相连的图。匹配则是一个边的集合,满足其中任意两条边不共点。最大匹配则是二分图里的某一个匹配包含的边的数量,在该二分图的所有匹配中最大的哪个匹配。如下图所示:
匈牙利算法则是用来求解最大匹配的一种算法。在二分图的匹配中,如果一条路径的首尾是非匹配点,路径中除此之外(如果有)其他的点均是匹配点,那么这条路径就是一条增广路径。如下图8->4->7->1->5->2 :
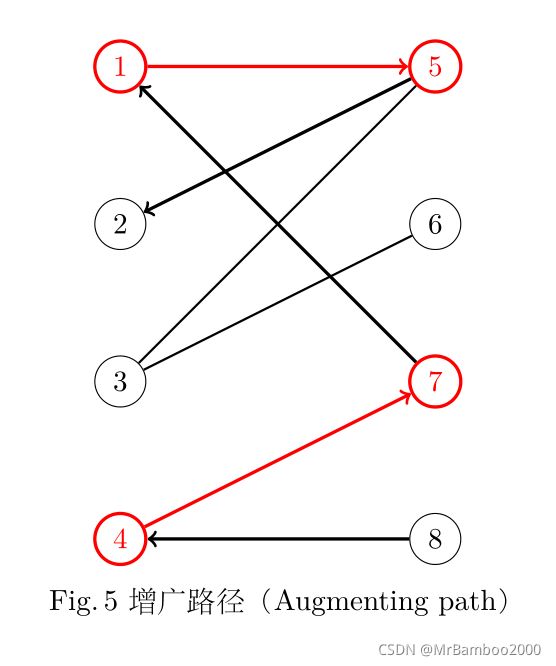
由于增广路径的首尾是非匹配点,增广路径从非匹配边开始,匹配边和非匹配边依次交替,最后由非匹配边结束。这样一来,增广路径中非匹配边的数目会比匹配边大 1。如果我们置换增广路径中的匹配边和非匹配边,增广路径的置换,可以得到比原有匹配更大的匹配,具体来说是匹配边数加1。在任意匹配的基础上,如果我们有办法不断地搜寻出增广路径,直到最终我们找不到新的增广路径为止,我们就有可能得到二分图的一个最大匹配。这就是匈牙利算法的核心思想。我们采用贪心算法就能能求得最大匹配的解。
本文使用匈牙利算法,来为每一个ground truth分配一个预测结果,每一个ground truth都会有且仅有一个与之匹配的预测结果。有了成对的预测值与真值,就可以计算其损失函数来进行优化。
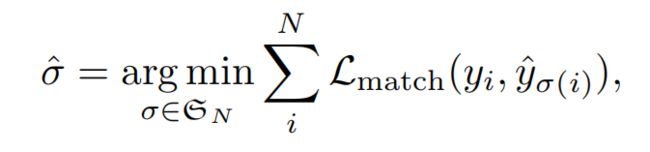
损失函数的具体形式可以写作:
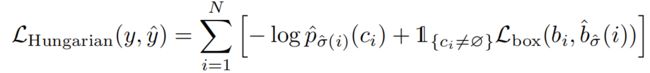
可以看出包括两部分,一部分是类别损失函数,一部分是坐标损失函数。其中类别损失函数的处理方式采用交叉熵,这个我们之前的论文学习中也见过。坐标损失函数则又是有两部分组成:
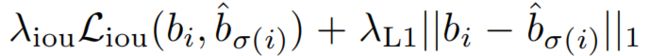
也就是L1损失与IOU损失的加权和。
模型效果
来看看结果咋样:
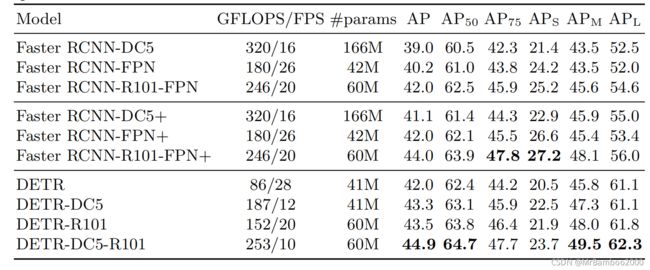
性能已经基本上可以比肩甚至于超过Faster R-CNN这种标杆级的方法了。而且注意这是没有什么额外添加东西的裸模型,如果加上FPN等等一套东西,其效果应该会更好。
但是DETR也有局限性,比如小目标检测上不太好,但是这点估计加上多尺度检测(比如FPN等)就会消除掉;再比如Transformer本身在原理上丢弃位置信息造成的可能在定位精度上稍差、Transformer训练较慢等等,这些还需要多多对Transformer做研究。
总结
这篇文章可以说是推陈出新,可以说是融会贯通,也可以说是返璞归真。推陈出新的点在于直接用Set Prediction这个思路把NMS给剔除掉了,实现了端到端的预测;融会贯通的点在于把Transformer这个方法引入了目标检测领域,并且针对目标检测的任务做了改进和融合;而返璞归真的点在于其实现思路真正符合了人眼对目标进行检测的思路。我们对比之前学习过的目标检测方法,比如YOLO、R-CNN、SSD等等都是先把框给设出来,然后用框去找目标,这就好比直接拿着放大镜在一张大图上找想找的东西;但是DETR不一样,它一开始就是在提取全局信息,也就是先在大图上看,看到觉得可能是目标的地方,再拿放大镜看那个地方有没有我们要找的东西,这就是注意力机制的作用过程,也是符合人眼习惯的过程。所以实际上,这也是一种非常返璞归真的方法。
P.S. CVPR2021出了一篇论文可以不用transformer,只用FCN实现端到端目标检测,题目为《End-to-End Object Detection with Fully Convolutional Network》,也很有意思,感兴趣的可以看一下。