光学计算机的工作原理,使用光学计算机的人工智能超分辨率
在本文中,我们将讨论超分辨率,这是一种使用深度神经网络来提高图像和视频分辨率的人工智能技术。

除了最开明的人之外,上述事情会导致所有人无法控制地嗤之以鼻的日子已经一去不复返了。今天,我们真的可以利用深度学习的力量来增强和提升低分辨率数据。
然而,更有前途的是,傅立叶光学计算可以通过将卷积运算的二次计算复杂度从O(n²)降低到线性:O(N)(其中n是输入大小)来加速此AI处理。
文章内容
什么是超分辨率?
超分辨率的工作原理
用于超分辨率的CNNs:上采样技术
超分辨率的PyTorch实现
不同损失函数下的实验
什么是超分辨率?
简单地说,超分辨率使图形效果更好。超分辨率神经网络能够获取低分辨率图像(或低分辨率视频帧),并输出看起来不错的高分辨率数据。比双线性或双三次插值更好。对肉眼更好。
这看起来几乎像是魔术,而且有很好的理由:不知何故,这些网络能够接受颗粒化、像素化的输入,并将它们转换成高分辨率、好看的图像。
所有这些都可以在不显式使用任何传统的计算机图形技术(如反走样、平滑和插值)的情况下实现。我们用超分辨率看到的是基于深度学习的计算机视觉(CV)的魔力。神经网络能够通过使用先验知识和从示例中学习的模式来推断像素化图像描述的是什么。
超分辨率的工作原理
AI超分辨率通常利用针对CV进行优化的深层神经网络。卷积神经网络(CNN)几十年来一直是CV的中流砥柱,通常用于图像分类等事情,早期的一个例子是Yann LeCun如何使用CNN学习如何对手写数字进行分类,从而允许支票自动兑现。how to classify handwritten digits
背景:用于分类的CNN
分类CNN通常具有如下结构:
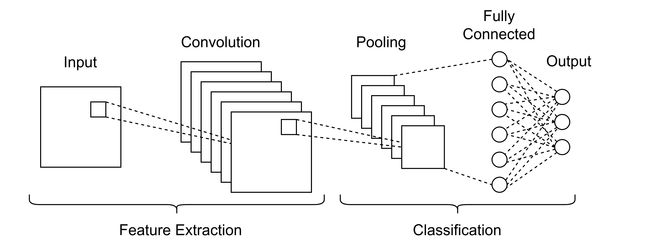
通常,图像被送入网络并与多个滤波器卷积,滤波后的图像被组合以构成“多通道卷积”层的输出。层输出通常与输入大小相同。
随后的卷积层输出通常通过诸如最大合用的操作来减小大小。一旦将数据汇集到合理的大小(有时小到单个像素),就可以将其送入密集或完全连接的层中进行分类。
背景:用于其他系统的CNN
更现代的CNN应用包括自动驾驶、机器人手术和医疗筛查(这些应用超越了图像分类,进入了系统控制和语义分割)。像Faceswap这样的应用程序是当代简历的一个很好的例子,CNN的输入和输出都是图像。这样的系统能够处理一对图像,非侵入性地将一个人的脸移植到另一个人的头上。
一个faceswap风格的CNN可能会有这样的结构:
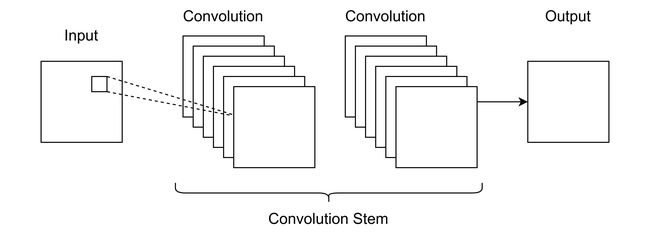
或者像这样:
用于超分辨率的CNNs
以类似的方式,超分辨率网络获取一幅图像并输出另一幅图像。与上述架构的唯一区别是输入图像和输出图像的大小不同。相反,输出的分辨率应该更高,同时仍能忠实地描绘原始场景。
如果我们希望CNN的输出具有比输入更高的分辨率,那么我们需要某种形式的非标准CNN层,这与分类CNN中的典型卷积⇨池挡路相反。这称为上采样层。
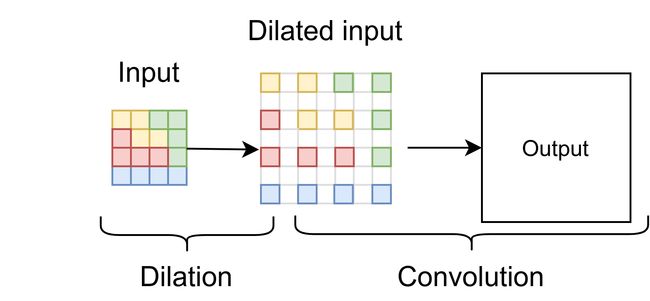
膨胀上采样(也称为超像素卷积)
使用的一种技术是扩大输入图像,有效地从原始图像生成高度和宽度都是其两倍大小的稀疏矩阵。该稀疏矩阵用作标准卷积层的输入。膨胀上采样是实现超分辨率的一种简单而自然的解决方案。这种方法的缺点是CNN滤波器将总是覆盖零值像素的区域,从而有效地浪费计算。
多通道整形上采样(也称为调整卷积大小)
通道上采样采用多通道图像(如卷积图层的输出),并将数据重塑为较少的通道,但具有较大的高度和宽度。
在分类CNN中,通常有顺序的池化层,旨在减少内部数据表示的大小,从而降低计算复杂度。为了确保不可恢复的信息不被破坏,卷积层或块通常增加信道计数。例如,可以将32通道16×16输入转换成64通道8×8输出。
上采样需要进行相反的操作。图像分辨率应该提高,因此也应该减少通道数。这可以通过重塑来实现。例如,可以将16通道100×100输入整形为4通道200×200输出。与扩展卷积相比,这与解决方案(具有相同的网络参数计数)一样富有表现力,而没有计算损失。
考虑这一点的一种方法是取前4个输出通道的左上角像素,当它们排列成2×2栅格时,将构成单个输出通道的左上角2×2象限。则可以针对所有像素位置和通道荒谬地重复这一点。
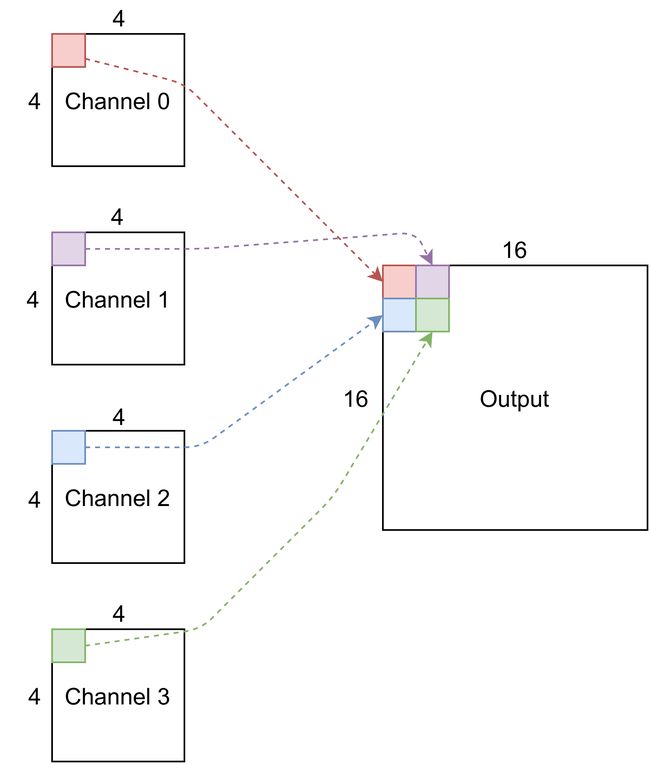
当然,我们可以天真地重塑输出张量,但是这可能会带来问题,因为CNN保留了其输入的空间信息,因此将像素放在同一空间位置是有意义的。

何时向上采样
最后一个要考虑的问题是什么时候应该进行上采样。没有“正确”的解决方案,只有几个不同的想法,结果各不相同。
最后一层中的上采样。这是最简单的想法;然而,“图像超分辨率的深度学习:调查”一书的作者指出,对于较大的上采样因子(如x8),这种方法并不是最好的。
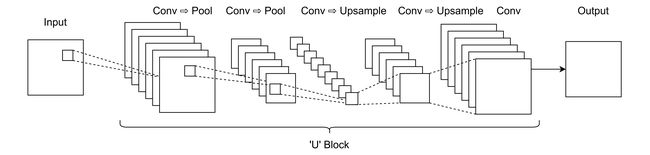
在整个网络中逐渐上采样,类似于在整个分类CNN中的顺序汇集。
在整个网络中进行上采样和下采样,例如U-NET架构。
超分辨率的PyTorch实现
数据和硬件
超分辨实验的数据是丰富的。图像不需要以任何方式分类或标记,唯一的前提是训练图像至少应该与我们希望的上采样分辨率一样大。
我们使用了一个python网络刮取器,当输入像‘lion’这样的关键字时,它会下载谷歌图片搜索返回的图片:
下载了足够大的图像,裁剪成正方形,并调整到我们的目标放大分辨率:256²。重复这个过程,直到我们有了大约14,000张图像的独特数据集。图像被分成70%的训练子集和30%的验证子集。PyTorch数据加载器用于加载数据集。
培训设置
在训练和验证过程中,数据集中的3通道、256²大小的图像被用作地面真实值。网络的输入是通过使用最近邻算法将地面实况图像缩小到3通道32²来创建的。电子培训在NVIDIA Quadro P6000上进行。
我们希望我们的卷积层由Optalysys的光学芯片实现,所以我们在实验室中使用PyTorch层与Optalysys的硅光子自由空间傅立叶光学芯片接口。原型网络以电子方式运行,一旦选择了合适的超参数,就可以通过在初始化时向我们的模型传递‘OPTIME=TRUE’来调用光网络。
我们的上采样技术
我们编写了定义不同信道深度和卷积层数的上采样挡路的代码。然后,可以将挡路参数化到整个网络中,在末端具有单个上采样,或者可以将多个块堆叠在一起以创建更大的端到端网络上采样因子。挡路还可以与Conv→池型块结合使用,形成U-Net超分辨率架构。
避免跳棋
上采样通常会受到“棋盘格”的影响,在下图中清晰可见:

本文对此进行了深入的探讨,并提出了一种原则性的规避方法。当我们使用所谓的“调整卷积大小”上采样方法时,对棋盘格规定的修正是将对相同输出象限有贡献的卷积核的权重和偏差初始化为相同的值。This paper
填充
上采样CNN的另一个一般性问题可能发生在输出图像的边界。在CNN中,通常使用填充来保持层输入和输出的高度和宽度一致。零填充是传统的选择,然而这实际上意味着我们用黑色边框包围了每个图像,这将导致在放大的图像中出现视觉瑕疵。出于这个原因,我们使用了“复制”类型的填充,这样边框将由合理的值组成。
上采样挡路火炬代码
以下是上采样挡路的代码:
在我们的实验中,我们从输入到输出分别使用了3个深度为4、长度为4、2和1的上采样块(内部多通道卷积层的数量)。我们定义了一个端到端模型,该模型由具有3×3大小的滤波器的单个卷积层、具有3×3大小的滤波器的多个未采样块以及末端用于信道减少的1×1卷积层组成。
以下是该模型的代码:
对于培训,我们发现4个批次的大小对我们的实验很有效。我们用步进式学习率从0.01开始训练模型,伽马系数为0.8,持续了大约15个纪元。
损失函数的选择-1)像素损失均方误差
最初,我们使用网络输出和原始256²图像尝试了一个简单的均方误差(MSE)损失项,效果相当好,但结果不是很好:
CNN的输出可以说比插值的图像看起来更好,像素人工制品更少,但它并不奇妙。CNN图像的问题包括模糊和轻微的颜色问题。使用直方图匹配来尝试恢复丢失的颜色,这在一定程度上是成功的。Histogram matching
上面的图像很好地说明了神经网络超分辨率在验证集上的一般功效。这些结果是不错的,但是可以做些什么来改善它们呢?也许是不同的损失函数…
2)平均梯度误差
为了减少细胞神经网络输出的模糊性,人们提出了平均梯度误差的方法,其思想是在预测图像和目标图像上使用一条水平和垂直边缘过滤,取两对滤波图像之间的均方误差。这一损失条款应该会对做出模糊预测的网络造成沉重的惩罚,从而提高产出。
这里是相同的图像,由用MSE+MGE的组合损失项训练的网络推断,其中MSE项和MGE项的比例都被设置为1。
这些输出在某些方面看起来确实更好,它们比MSE网络的输出更锐利,尽管差别并不明显。在图像边界也出现了一个新的问题。这个网络比MSE好吗?这当然很难量化。不过,似乎CNN的输出是渲染场景的一种相当现实的尝试,如果它被观看时稍微模糊了一点。可以说,这些输出看起来比插值图像更“逼真”,可能对某些应用很有用。
用不同的权重尝试了MSE和MGE损失项的各种组合,但结果仍然不是很理想。理论上,MGE应该会带来更清晰的产出,但在现实中,结果仍然相当不集中。
3)功能丢失
似乎,基于像素的直观损失函数的问题在于,它导致的结果一般。我们真正想使用的是类似于人类感知的损失函数,即如果图像看起来与原始全尺寸图像相似,那么这是好的,即使有许多像素个别不准确。
Johnson等人的研究成果。勾勒出实现感知损失功能的思路,用于其作品的超分辨率和风格转换。想法很简单:their work for super resolution and style transfer
以预先训练好的CNN为例,比如VGG-16,它在ImageNet数据集上进行了训练。
通过预先训练好的模型、地面真实图像和超分辨率CNN输出。
对于两个输入,从预先训练的VGG模型中的特征提取层获取输出张量。
使用两个特征张量之间的归一化平方欧几里得距离作为损失项。
反向传播时,冻结预先训练的VGG模型的权重。
下面是一个代码片段,它显示了这是如何工作的,取自VGG-16层relu2_2的输出:
上面的代码需要一个Loss_model对象,可以从这样的类实例化该对象(该示例还具有Johnson等人提到的Style Lost功能,但不建议将Style Lost用于超分辨率):
这个损失函数评估的是:生成的图像看起来像原始图像吗?接受ImageNet培训的网络(如VGG-16)是否在映像中看到与ImageNet映像类定义的映像内容相关的相同功能?考虑到我们的数据集中的图像不一定包含与ImageNet相同的主题,这似乎是一个相当鲁莽的问题,但是这不是问题。
ImageNet是一个非常大的数据集,包含许多不同的异构对象。为了很好地对它们进行分类,神经网络需要识别诸如边缘、纹理和形状等一般特征。由于这种在ImageNet上训练的网络具有良好的一般特征提取能力,以至于它们可以被重新利用,以便在使用转移学习的最少训练的情况下处理ImageNet数据集的统计分布之外的数据。因此,在ImageNet上使用预先训练好的VGG-16架构是感知损失鉴别器的明智选择。
我们使用完全相同的网络结构和超参数,但使用特征损失(FL)损失函数来训练特征损失网络,结果如下:
对我们来说,这些图像看起来比插值的要好。不幸的是,它们看起来仍然有点模糊,所以我们尝试在特征损失中添加一个加权的MGE损失项。
不同损失函数的进一步比较:
我们尝试了FL和MGE项的不同组合,分别加权为(1,0)、(1,1)、(1,2)和(1,3):
神经网络的结果都非常相似,但是从FL专栏开始,我们确实看到图像的清晰度略有增加,这可以用MGE项的影响增加来解释。我们个人最喜欢FLE+MGE专栏,尽管它还有待商榷。
光学计算机上的超分辨率
背景资料:Optalysys方法
在Optalysys,我们开发由硅光电子驱动的光学芯片。我们的下一代高速芯片将利用精密自由空间光学技术,以远远超过最好的电子傅里叶变换内核的速度和效率执行光学傅里叶变换运算。目前,我们在实验室里有一个概念验证的热驱动演示系统。Optalysys
可以使用傅立叶变换(通过卷积定理)将卷积运算的计算复杂度从二次降为线性。因此,如果我们能够将数据转换成其频率表示,我们就可以用更少的操作来推断和训练CNN。下表描述了操作(通常是乘法和累加或MAC操作)的减少:convolution theorem
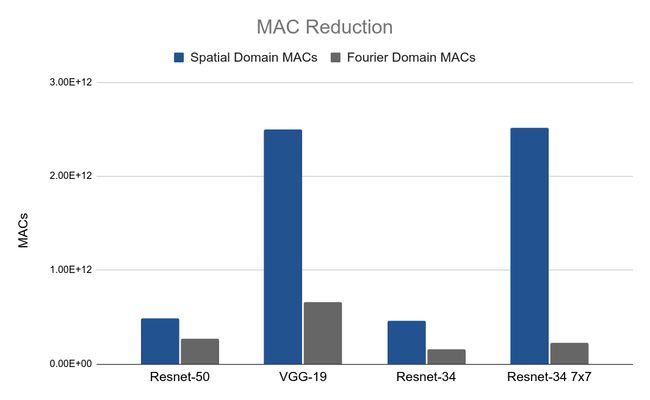
在本文中,我们还将更详细地描述这一思想。this article
光学计算机上的超分辨率实验
我们实验室中的硬件可以通过PyTorch接口寻址。因此,在我们的光学芯片上运行上面原型的超分辨率模型来评估其性能是不费力的。我们在实例化PyTorch模型时通过传递‘optic=True’以光学方式运行上面讨论的模型,并将其与电子版进行比较:
我们看到,一般来说,光学CNN的性能至少和电子网络一样好。在某些方面,它更好;当近距离观看图像时,颜色更准确,人工制品更少。
超越256²
端到端CNN架构(与具有密集层的变压器和CNN不同)的可怕之处在于,它们可以为任何大小的输入工作。无论输入的高度和宽度如何,卷积层的工作方式都是相同的。这意味着我们可以在更大的输入上使用最初经过32²8x扩展培训的相同网络。例如,我们可以将数据集中的256²数据升级到2048²。
由于数据最初是通过抓取Web收集的,因此许多图像中存在与有损JPEG类压缩一致的伪像。CNN可以在提高分辨率的同时恢复图像质量吗?下面是以这种方式使用网络的一些示例;我们对结果感到惊讶。
感谢您的阅读!
电子邮件:[email protected]@optalysys.com
左:双三次上采样-256²→2048²
原始图像有一些有损压缩瑕疵。
右:光学有线电视新闻网-256²→2048²
美国有线电视新闻网接受了32²→256×8上采样的培训。

从谷歌获得的图片,按照合理使用原则使用。如果有任何有关图片的版权问题,请联系我,我会将其删除。fair use
图像来源:
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/01/%e4%bd%bf%e7%94%a8%e5%85%89%e5%ad%a6%e8%ae%a1%e7%ae%97%e6%9c%ba%e7%9a%84%e4%ba%ba%e5%b7%a5%e6%99%ba%e8%83%bd%e8%b6%85%e5%88%86%e8%be%a8%e7%8e%87/