YOLOX训练代码分析3-损失函数
yolox构建模型时,是通过yolox_base.py中的get_model函数获取,其中分成两部分YOLOXPAFPN与YOLOXHead两个类,由YOLOX加载封装整个网络。
if getattr(self, "model", None) is None: # 该对象中是否存在model属性,默认值为None,设置成模型
in_channels = [256, 512, 1024]
backbone = YOLOPAFPN(self.depth, self.width, in_channels=in_channels) #主干网络
head = YOLOXHead(self.num_classes, self.width, in_channels=in_channels) #网络头
self.model = YOLOX(backbone, head)1. YOLOXHead网络结构分析
yolox通过yolox/models/yolox.py中forward函数返回各项损失,其主要是通过YOLOXHead计算训练过程各项损失。
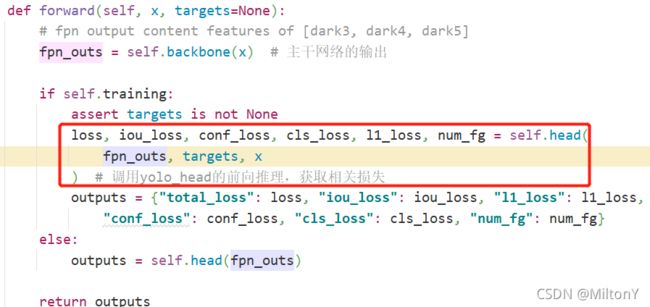
yolox的头部使用yolox提出的解耦头(Decoupled Head)思想。YOLOXHead类中构建了网络头的卷积层,代码如下
(1) 构造器中的各个卷积网络的构建
self.cls_convs = nn.ModuleList() # 解耦头部分的cls、reg卷积、batchNorm、SiLu
self.reg_convs = nn.ModuleList()
self.cls_preds = nn.ModuleList() # 类别、bbox、置信度预测前的卷积
self.reg_preds = nn.ModuleList()
self.obj_preds = nn.ModuleList()
self.stems = nn.ModuleList()
Conv = DWConv if depthwise else BaseConv
for i in range(len(in_channels)): # 表示三个尺度主干网络的输出
self.stems.append(
BaseConv(in_channels=int(in_channels[i] * width), out_channels=int(256 * width), ksize=1, stride=1, act=act)
)
# cls_convs与reg_convs网络层相同
self.cls_convs.append(
nn.Sequential(
*[Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
]
)
)
self.reg_convs.append(
nn.Sequential(
*[Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
Conv(in_channels=int(256 * width), out_channels=int(256 * width), ksize=3, stride=1, act=act),
]
)
)
self.cls_preds.append( #类别预测
nn.Conv2d(in_channels=int(256 * width), out_channels=self.n_anchors * self.num_classes, kernel_size=1, stride=1, padding=0)
)
self.reg_preds.append( #bbox预测
nn.Conv2d(in_channels=int(256 * width), out_channels=4, kernel_size=1, stride=1, padding=0,)
)
self.obj_preds.append( #置信度预测
nn.Conv2d(in_channels=int(256 * width), out_channels=self.n_anchors * 1, kernel_size=1, stride=1, padding=0,)
)
self.use_l1 = False
self.l1_loss = nn.L1Loss(reduction="none") #L1损失
self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none") #二值交叉熵损失
self.iou_loss = IOUloss(reduction="none") #边界框损失
self.strides = strides
self.grids = [torch.zeros(1)] * len(in_channels) # 输出的网格大小
self.expanded_strides = [None] * len(in_channels)(2) 各个网络层之间的连接
前向推理 yolox/models/yolo_head.py类YOLOXHead中的forward方法
# k=[0,1,2]
for k, (cls_conv, reg_conv, stride_this_level, x) in enumerate(
zip(self.cls_convs, self.reg_convs, self.strides, xin)):
x = self.stems[k](x) #stems中的3个BaseConv
cls_x = x
reg_x = x
cls_feat = cls_conv(cls_x)
cls_output = self.cls_preds[k](cls_feat)
reg_feat = reg_conv(reg_x)
reg_output = self.reg_preds[k](reg_feat)
obj_output = self.obj_preds[k](reg_feat)通过代码分析,三个尺度的头部结构相同,yolox头部的网络构成可以用以下图表示
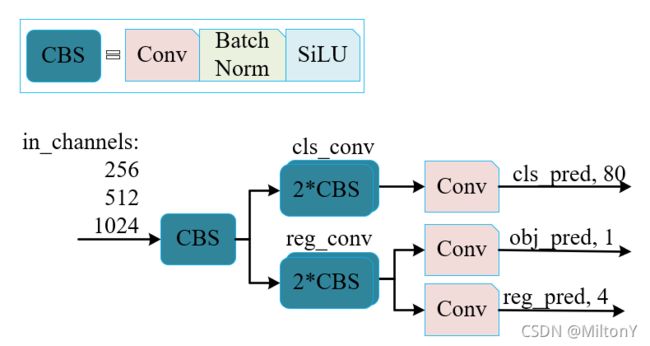
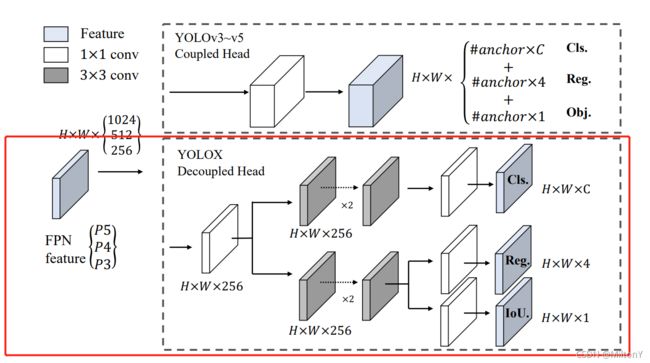
其中输入的尺度包括256、512、1024。论文中的解耦头结构与未解耦情况的对比如下图所示
(3) 数据合并与特征图网络坐标计算
通过YOLOHead进行解耦Cls、Reg与IoU,然后做合并处理,计算特征图上各个网格的坐标。其中以batch_size=8,图像输入大小为[640,640]为例,三个尺度的解耦输出合并size分别为[8,85,80,80]、[8,85,40,40]、[8,85,20,20],代码如下
output = torch.cat([reg_output, obj_output, cls_output], 1) #合并边界框输出、置信度输出、类别概率输出然后创建特征图网络坐标点,并把神经网络前向推理的bbox投影输入图像的尺寸上
output, grid = self.get_output_and_grid(output, k, stride_this_level, xin[0].type()) #创建特征图网格的坐标,预测bbox投影到输入图像
###### 函数get_output_and_grid ######
# yolox存在3个尺度的输出.output为某个尺度的输出
def get_output_and_grid(self, output, k, stride, dtype):
grid = self.grids[k]
batch_size = output.shape[0]
n_ch = 5 + self.num_classes
hsize, wsize = output.shape[-2:]
if grid.shape[2:4] != output.shape[2:4]:
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)]) #xy方向gird坐标构建
grid = torch.stack((xv, yv), 2).view(1, 1, hsize, wsize, 2).type(dtype)
self.grids[k] = grid
output = output.view(batch_size, self.n_anchors, n_ch, hsize, wsize) #size:[8,1,85,80,80]
output = (output.permute(0, 1, 3, 4, 2).reshape(batch_size, self.n_anchors * hsize * wsize, -1)) #size:[8,6400,85]
grid = grid.view(1, -1, 2) #size:[1,6400,2]
output[..., :2] = (output[..., :2] + grid) * stride #(bbox_xy + 偏移)*stride,xy投影到输入图像
output[..., 2:4] = torch.exp(output[..., 2:4]) * stride #exp(bbox_wh)*stride, wh投影到输入图像
return output, grid #output:[8,6400,85], grid:[1,6400,2]2. 损失计算
损失函数的计算是forward方法中调用了get_losses方法,具体代码如下:
# 如果是训练,则调用get_losses函数,返回各项损失
# imgs:一个batch的图像,x_shifts、y_shifts: 特征图每个网格grid的xy坐标,
# expanded_strides: 不同尺寸的特征输出与输入图像之间缩小的倍数
# labels: ground_truth的类别号与bbox(一个batch图像中的人工标注框与类别)
# torch.cat(outputs,1): 对三个尺度的输出进行合并
if self.training:
return self.get_losses(imgs, x_shifts, y_shifts, expanded_strides, labels,
torch.cat(outputs, 1), origin_preds, dtype=xin[0].dtype)在计算损失时,yolox需要做标签分配,这是yolox的重要思想。其中涉及的函数为
# 标签分配
# 输入:
# batch_idx: 批图像的索引;num_gt: 一幅图像存在的目标数目;
# total_num_anchors: 总的anchor数目,yolox提取的最后特征,每个方格表示一个anchor
# gt_bboxes_per_image: 一幅图像人工标注的框box坐标; gt_classes: 一幅图像的标注框类别编号
# bboxes_preds_per_image: 一幅图像预测的bbox(8400个);
# expanded_strides: 三个尺度的每个特征方格相对于输入图的缩放像素[8,..],[16,...],[32,...]
# x_shifts,y_shifts: 每个特征方格位置偏移量组成的向量(一个batch)
# cls_preds: 类别预测概率,一个batch数据。[batch_num,anchors_all,num_cls], 如[8,8400,80]
# bbox_preds:目标框的预测,如[8,8400,4];obj_preds: 目标置信度概率,如[8,8400,1]
# labels: yolo人工标注框,一个batch数据。每行存储形式:[cls_num,cx,cy,w,h]
# imgs: 一个batch的图像数据
# 输出:
# gt_matched_classes: 标签分配后,每列候选框预测目标的编号
# fg_mask: 初步筛选中,in_boxes与in_center的并集[8400]
# pred_ious_this_matching: 由标签分配的mask, 筛选真实框与预测框构成的IoU矩阵对应的IoU值
# matched_gt_inds: matrix_matching矩阵,存在候选框的位置idx
# num_fg_img: 标签分配完成后,总共存在的候选框个数(matrix_matching每列保证一个候选框)
gt_matched_classes, fg_mask, pred_ious_this_matching, matched_gt_inds, num_fg_img =
self.get_assignments(batch_idx, num_gt, total_num_anchors, gt_bboxes_per_image,
gt_classes, bboxes_preds_per_image, expanded_strides, x_shifts,
y_shifts, cls_preds, bbox_preds, obj_preds, labels, imgs)其中get_assignments函数包括两个步骤, (1) 正样本anchor的初步筛选,(2) 利用SimOTA进行anchor的精细化筛选。
(1) 初步筛选
初步筛选分成两种方式:根据中心点与目标框判断。
目标框:anchor box的中心点落在人工标注框(Ground Truth Boxes)的矩形范围中的所有anchor;
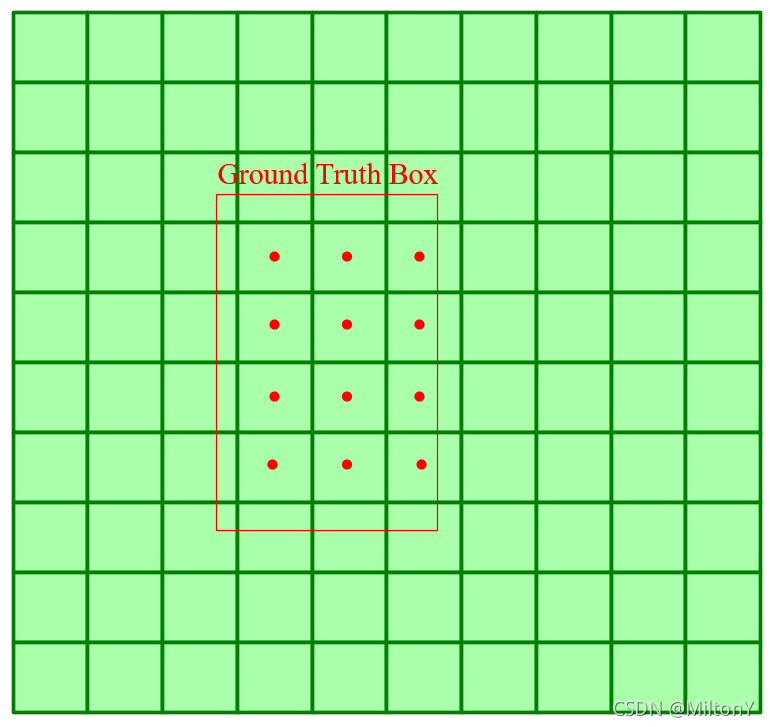
图中绿色框为yolox网络提取的特征方格,在yolox中每个方格表示一个anchor,红色方框表示真实框,则红色点落在真实框中的小方格(锚点框anchor box)可能用于预测正样本。
中心点:以Ground Truth Boxes中心点为基准,四周向外扩展2.5倍stride,构成边长为5倍stride的正方形,挑选anchor box中心点落在正方形内的所有锚框。

图中以箭头扩大2.5倍的正方形为边界,anchor box中心点落在正方形中的anchor box,可能作为正样本的预测。
正样本锚框的初步筛选代码:
# 锚点框的初步筛选:根据真实框中心点、目标框来判断
def get_in_boxes_info(self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt):
# gt_bboxes_per_image: 每幅图像的真实框,expanded_strides: 三个尺度每个方格缩放倍数
# x_shifts,y_shifts: 每个方格的xy偏移量,size:[1,8400],
# total_num_anchors: 所有anchor数,num_gt: 某幅图像的目标框个数
expanded_strides_per_image = expanded_strides[0]
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image # 输入图像方格坐标
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
# [n_anchor] -> [n_gt, n_anchor] 输入图像中每个方格的中心点坐标计算
x_centers_per_image = ((x_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1))
y_centers_per_image = ((y_shifts_per_image + 0.5 * expanded_strides_per_image).unsqueeze(0).repeat(num_gt, 1))
# 计算真实框左上角与右下角坐标
gt_bboxes_per_image_l = ((gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors))
gt_bboxes_per_image_r = ((gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2]).unsqueeze(1).repeat(1, total_num_anchors))
gt_bboxes_per_image_t = ((gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors))
gt_bboxes_per_image_b = ((gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3]).unsqueeze(1).repeat(1, total_num_anchors))
# 方格中心点与真实框的左、右、上、下的距离,size:[num_gt,8400],每个目标8400个anchor
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # bbox_deltas size:[num_gt,8400,4]
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0 #找出方格中心点落在groundTruth中的anchor,size: [num_gt,8400]
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0 #8400个anchor是否存在目标预测(in ground truth box)
# in fixed center
center_radius = 2.5 # center sampling in FCOS(Multi Positives)
# 计算以真实框中心点向外扩大5倍边长,左上角与右下角的坐标
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) - \
center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(1, total_num_anchors) + \
center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) - \
center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(1, total_num_anchors) + \
center_radius * expanded_strides_per_image.unsqueeze(0)
# 方格中心点与5倍边长正方形左、右、上、下的距离
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0 #找出方格中心点落在5倍边长正方形中的anchor,size: [num_gt,8400]
is_in_centers_all = is_in_centers.sum(dim=0) > 0 #8400个anchor是否存在目标预测(in center box[5 times stride])
# in boxes and in centers
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all # 真实框或5倍边长框
# 既在真实box中,又在5倍边长方框中
is_in_boxes_and_center = (is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor])
return is_in_boxes_anchor, is_in_boxes_and_center(2) 利用SimOTA做精细化筛选
利用SimOTA进行正样本锚点框的精细化筛选的标签分配方法总体分成4个步骤:
1) 初步正样本锚点框筛选;前面已经解读相关代码,在get_assignments中调用get_in_boxes_info函数,获取以中心点和目标框筛选交集与并集mask。
# fg_mask:in_boxes与in_center的并集[8400], is_in_boxes_and_center为交集,为0与1的矩阵
fg_mask, is_in_boxes_and_center = self.get_in_boxes_info(gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts, total_num_anchors, num_gt)
# 单幅图像,根据正样本锚框的初步筛选
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask] # [<=8400,4]
cls_preds_ = cls_preds[batch_idx][fg_mask] #[<=8400,80]
obj_preds_ = obj_preds[batch_idx][fg_mask] #[<=8400,1]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0] # 正样本锚框筛选的个数2) Loss函数计算用于标签分配;这里计算的是bbox的损失与类别损失,计算Loss如下:
边界框损失:
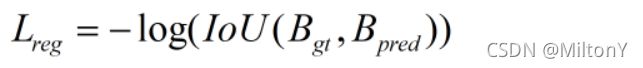
# 所有真实框与候选框之间的IoU
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8) #边界框损失类别损失:
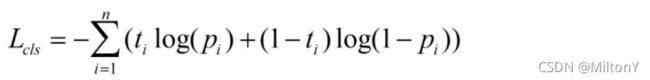
# 真实框在每幅图像的方格中one_hot向量,coco类别为80 size:[num_gt,num_in_boxes_anchor,80]
gt_cls_per_image = (F.one_hot(gt_classes.to(torch.int64), self.num_classes).float() .unsqueeze(1).repeat(1, num_in_boxes_anchor, 1))
# 类别预测的sigmoid*置信度预测的sigmoid=类别分数 size:[num_gt,num_in_boxes_anchor,80]
cls_preds_ = (cls_preds_.float().unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_() * obj_preds_.unsqueeze(0).repeat(num_gt, 1, 1).sigmoid_())
# 二值交叉熵计算类别损失
pair_wise_cls_loss = F.binary_cross_entropy(cls_preds_.sqrt_(), gt_cls_per_image, reduction="none").sum(-1) # 类别损失 size:[num_gt,num_in_boxes_anchor]3) Cost成本计算;
论文中成本计算:
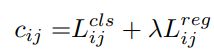
# lambda=3.0, 设置anchor box的中心,不在以中心点构建框与目标框中的cost=100000
cost = (pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000.0 * (~is_in_boxes_and_center)) 4) SimOTA求解。
### SimOTA, 求近似最优解 ###
# 输入:
# cost: 通过回归损失和类别损失计算得到的cost
# pair_wise_ious: size为[num_gt,num_in_boxes_anchor]的IoU计算,即所有真实框与预测框的IoU
# gt_classes: 一幅图像ground truth标注框的类别编号向量
# num_gt: 一幅图像的标注框个数
# fg_mask: 根据中心点与目标框初步筛选并集掩码
# 输出:
# num_fg: 标签分配完成后,总共存在的候选框个数(matrix_matching每列保证一个候选框)
# gt_matched_classes: 标签分配后,每列候选框预测目标的编号
# pred_ious_this_matching: 由标签分配的mask, 筛选真实框与预测框构成的IoU矩阵对应的IoU值
# matched_gt_inds: matrix_matching矩阵,存在候选框的位置idx
(num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds)
= self.dynamic_k_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)第一步:某幅图像真实框,与通过初筛获取的预测框计算IoU,然后通过计算的IoU找出最大top10的数据,尺寸大小为[num_gt, 10]。再由最大top10的数据统计这幅图像每个目标分配的候选框,通过找出cost最小位置分配某个候选框。
matching_matrix = torch.zeros_like(cost) # 设置候选框数量[num_gt, num_in_boxes_anchor]
# pair_wise_ious size: [num_gt, num_in_boxes_anchor]
ious_in_boxes_matrix = pair_wise_ious # 所有真实框与初筛候选框之间的IoU
n_candidate_k = 10
# 取最大top10的数据,[num_gt,10]
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1)
# 通过topk_ious动态选择框
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1) # 统计每个目标分配的候选框数量
for gt_idx in range(num_gt):
# 根据每行分配的候选框数量num=dynamic_ks[gt_idx],由cost找出前num最小cost的位置,
# 作为分配的候选框
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx].item(), largest=False)
matching_matrix[gt_idx][pos_idx] = 1.0 #找到cost最小的位置,然后设置候选框矩阵对应位置为1
del topk_ious, dynamic_ks, pos_idx计算每个目标框分配的候选框个数,假设ious_in_boxes_matrix为[3,13]的矩阵,则得到候选框个数如下:

根据cost分配计算候选框的位置(找出每行中最小的cost),大致流程如下:

第二步:过滤掉共用的候选框,即matching_matrix同列中有多个1的情况,也就是某列候选框被多个真实框关联。
# 过滤掉共用的候选框,同一列中有多个1的情况,即某列候选框被多个真实框关联
anchor_matching_gt = matching_matrix.sum(0) # 列相加
if (anchor_matching_gt > 1).sum() > 0: # 存在同列有多个1
cost_min, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0)
matching_matrix[:, anchor_matching_gt > 1] *= 0.0
# 设置同列多个1的列,最小cost为1,其余为0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1.0
fg_mask_inboxes = matching_matrix.sum(0) > 0.0 # 每列求和并找出大于0的列
num_fg = fg_mask_inboxes.sum().item() # 总共候选框个数通过cost矩阵,找出共用候选框损失函数最小的位置,mask设置为1,其余位置设置为0,具体过程如下:

标签分配完成之后的代码如下:
fg_mask_inboxes = matching_matrix.sum(0) > 0.0 # 每列求和并找出大于0的列
num_fg = fg_mask_inboxes.sum().item() # 总共候选框个数,有多少列存在候选框
fg_mask[fg_mask.clone()] = fg_mask_inboxes # 把通过标签分配处理的mask,赋值给初筛选的mask
# 筛选出有候选框的列,并找出筛选列中最大值索引
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds] # 找出对应的目标编号
# 通过pair_wise_ious与标签分配的mask(fg_mask_inboxes), 筛选存在候选框的IoU
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_indsmatched_gt_inds的查找,如图所示:

pred_ious_this_matching的计算如下所示:

(3) get_loss函数中Loss的计算
通过标签分配之后得到的匹配类别标号(gt_matched_classes),候选框掩码(fg_mask),匹配之后的交并比(pred_ious_this_matching)计算真实的类别概率(cls_target),真实的置信度obj_target(即标签分配后的掩码fg_mask),再由matched_gt_inds筛选目标box,即reg_target。
# one_hot构成size为[num_gt,80]的矩阵, pred_ious_this_matching为num_gt的一维向量,unsqueeze(-1)表示reshape为[num_gt,1]
cls_target = F.one_hot(gt_matched_classes.to(torch.int64), self.num_classes) * pred_ious_this_matching.unsqueeze(-1)
obj_target = fg_mask.unsqueeze(-1) # 目标置信度
reg_target = gt_bboxes_per_image[matched_gt_inds] # 通过匹配索引筛选目标box统计一个batch下,三个损失结果,然后计算一个batch的损失。
for ...
# 一个batch的每幅图像三个损失append
cls_targets.append(cls_target)
reg_targets.append(reg_target)
obj_targets.append(obj_target.to(dtype))
fg_masks.append(fg_mask) # 目标置信度添加
# cat操作
cls_targets = torch.cat(cls_targets, 0)
reg_targets = torch.cat(reg_targets, 0)
obj_targets = torch.cat(obj_targets, 0)
fg_masks = torch.cat(fg_masks, 0)
# 损失计算
num_fg = max(num_fg, 1)
loss_iou = (self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)).sum() / num_fg
loss_obj = (self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)).sum() / num_fg
loss_cls = (self.bcewithlog_loss(cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets)).sum() / num_fg
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls