详细介绍NLP中文分词原理及分词工具
基于词表的分词方法
正向最大匹配算法FMM
从左到右扫描文本,得到词的最大匹配。

案例分析:
用正向最大匹配法对“秦皇岛今天晴空万里”进行中文分词,见下表。
词典 :“秦皇岛”“岛”“今天”“天晴”“晴空万里”“万里”……
根据当前词典,单词扫描的最大长度 max=4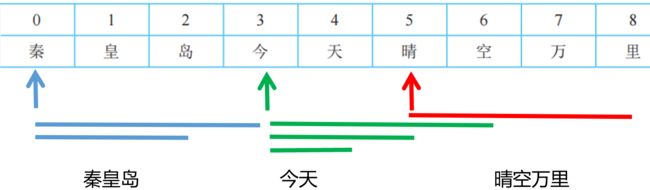
正向最大匹配函数:
def FMM(dict, sentence): # 正向最大匹配算法FMM函数,参数dict: 词典 ,参数sentence: 句子
fmmresult = []
max_len = max([len(item) for item in dict])# max_len定义为词典中最长词长度
start = 0
while start != len(sentence): # FMM 为正向,start 从初始位置开始,指向结尾即为结束
index = start + max_len # index 的初始值为 start 的索引 + 词典中元素的最大长度或句子末尾
if index > len(sentence):
index = len(sentence)
for i in range(max_len):
# 当分词在字典中时或分到最后一个字时,将其加入到结果列表中
if (sentence[start:index] in dict) or (len(sentence[start:index]) == 1):
# print(sentence[start:index], end='/')
fmmresult.append(sentence[start:index])
start = index# 分出一个词,start 设置到 index 处
break
index += -1# 如果匹配失败,则去掉最后一个字符
return fmmresult
逆向最大匹配算法RMM
从右到左扫描文本,得到词的最大匹配。

在中文中,由于偏正结构较多,所以从后向前进行匹配会提高精确度,因此,逆向最大匹配算法比正向最大匹配算法的误差要小。
逆向最大匹配函数:
def RMM(dict, sentence): # 逆向最大匹配算法RMM函数,参数dict: 词典 ,参数sentence: 句子
rmmresult = []
max_len = max([len(item) for item in dict])# max_len定义为词典中最长词长度
start = len(sentence)
while start != 0: # RMM 为逆向,start 从末尾位置开始,指向开头位置即为结束
index = start - max_len # 逆向时 index 的初始值为 start 的索引 - 词典中元素的最大长度或句子开头
if index < 0:
index = 0
for i in range(max_len):
# 当分词在字典中时或分到最后一个字时,将其加入到结果列表中
if (sentence[index:start] in dict) or (len(sentence[index:start]) == 1):
# print(sentence[index:start], end='/')
rmmresult.insert(0, sentence[index:start])
start = index# 分出一个词,start 设置到 index 处
break
index += 1 # 如果匹配失败,则去掉最前面一个字符
return rmmresult
双向最大匹配算法FMM
把正向最大匹配与逆向最大匹配都实施一遍,比较后选择最优结果。

双向最大匹配函数:
def BM(dict, sentence):# 双向最大匹配(BM),参数dict: 词典 ,参数sentence: 句子
res1 = FMM(dict, sentence) # res1 为 FMM 结果
res2 = RMM(dict, sentence) # res2 为 RMM 结果
if len(res1) == len(res2): # 若分词数相同,则分情况讨论
if res1 == res2: # 若FMM 与 RMM 的结果相同,则可取任意一个
return res1
else: # res1_sn 和 res2_sn 为两个分词结果的单字数量,若二者不同,则返回单字较少的
res1_sn = len([i for i in res1 if len(i) == 1])
res2_sn = len([i for i in res2 if len(i) == 1])
return res1 if res1_sn < res2_sn else res2
else: # 若分词数不同,则取分出词较少的
return res1 if len(res1) < len(res2) else res2
调用函数举例:
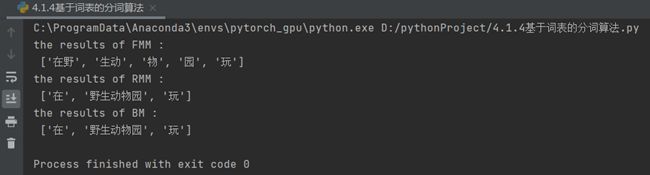
dict = [' 今日 ', ' 阳光明媚 ', ' 光明 ', ' 明媚 ', ' 阳光 ', ' 我们 ', ' 在 ', ' 在野 ', ' 生动 ', ' 野生 ', ' 动物园 ', ' 野生动物园 ', ' 物 ', ' 园 ', ' 玩 ']
sentence = ' 在野生动物园玩 '
print("the results of FMM :\n", FMM(dict, sentence), end="\n") # 调用FMM函数,输出FMM分词结果
print("the results of RMM :\n", RMM(dict, sentence), end="\n") # 调用RMM函数,输出RMM分词结果
print("the results of BM :\n", BM(dict, sentence)) # 调用BM函数,输出BM分词结果
缺点: 基于词表的分词算法虽然简单快速,但对于未登录词以及切分歧义的情况无法处理。
基于N-gram的分词方法
N-gram 模型称为 N 元模型,它是一种语言模型,该语言模型是一个基于概率的判别模型,其输入是一句话(词的顺序序列),输出是这句话的概率, 即这句话里所有词的联合概率。 N-gram 模型可应用在文化研究、分词应用、语音识别、输入法、词性标注、垃圾短信分类、机器翻译、语音识别、模糊匹配等领域。
N-gram分词思想
此算法假设每个词的出现只与它之前的 N-1 个词相关,通过大量的语料统计便可以得知句子中每个词的出现概率,继而计算出整个句子的出现概率。如果一个句子的出现概率越大,则越符合自然语言的规律。
通常 N 可以取 1、2、3、4, 其中 N 取 1、2、3 时分别称为 unigram(一元分词)、bigram(二元分词)、trigram(三元分词), 最常用的是 bigram 和 trigram。理论上,N 越大则 N-gram 模型越准确,也越复杂,所需计算量和训练语料数据量也越大。
词出现的概率可以直接从语料中统计 N 个词同时出现的次数得到。对于一个句子W,
假设 W 是由词序列 W1,W2,W3,…… ,Wn 组成的,那么概率可按如下公式计算。
P(W) =P(W1W2W3…Wn) =P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
当N=2时,当前词只依赖它前面的词(bigram):
P(W) =P(W1W2W3…Wn) =P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
N-gram分词步骤:
①建立 N-gram 统计语言模型。
②对句子进行单词划分,找出所有可能的分词情况。
③对分词的划分结果进行概率计算,找出出现可能性最大的分词序列。
案例分析: 基于 N-gram 模型算法对“我喜欢观赏日出”进行中文分词。

特点: 基于 N-gram 模型的分词算法是在原有中文算法基础上进行了改进,设计并且实现了新的中文分词系统,既实现了文本的快速分词,又提高了中文分词的准确性,但其计算开销比较大,并且仍然存在未登录词难以处理的问题。
基于序列标注的分词方法
基于隐马尔可夫模型的分词方法
隐马尔可夫模型(Hidden Markov Model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测(或称为隐状态)的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。
隐藏的马尔可夫链随机生成的状态的序列, 称为状态序列 ;每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列。 序列的每一个位置可以看作是一个时刻。基于序列标注的分词算法除了有基于隐马尔可夫模型,还有基于 CRF、基于 LSTM 等多种分词算法。
隐马尔可夫模型常应用于序列标注的问题。它用于标注时,状态对应着标记,标注问题是给定观测序列预测其对应的标记序列。
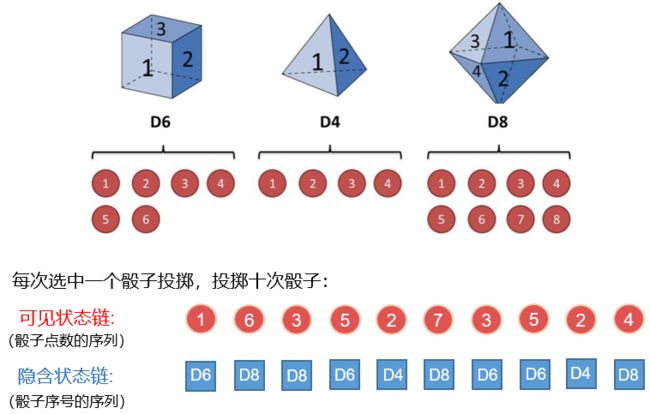
隐马尔可夫模型有两个基本假设 :马尔可夫假设和观测独立性假设。
(1)马尔可夫假设 :即假设隐藏的马尔可夫链在任意时刻 t 的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 t 无关。
![]()
(2)观测独立性假设 :即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态, 与其他观测及状态无关。
![]()
基于隐马尔可夫模型进行中文分词的基本原理: HMM 模型把分词问题转化为序列标注问题, 也就是给定一个句子作为输入,以“BEMS”组成的序列串作为输出,然后再进行分词,从而得到输入句子的划分。其中:
• B(Begin)代表词的起始位置,
• M(Middle) 代表词的中间位置,
• E(End)表示词的结束位置,
• S(Single)代表单字成词。
设观测状态集合(输入句子序列)为O={o1, o2, ⋯, on},隐藏状态集合(“BMES”序列)I={i1, i2, ⋯, in},中文分词就是对给定的观测序列,求解对应的最有可能的隐藏状态序列,即求解最大条件概率maxP(i1, ⋯, in | o1,⋯, on),利用贝叶斯公式可得:
![]()
案例分析: 其中观测序列也就是可见序列,状态序列也就是隐含序列。
基于条件随机场(CRF)的分词算法
基于条件随机场(Conditional Random Field,CRF)的分词算法是一种判别式的无向图模型,它试图对多个变量在给定观测值后的条件概率进行建模,常用于序列标注问题。 在 CRF 的假设中,每个状态不仅仅与它前面的状态有关,还与它后面的状态有关。与隐马尔可夫模型相比,CRF考虑的影响范围更大,顾及更多数量的特征函数以及相应权重。 因此该算法的精度也更高,当然计算代价也偏高。
基于循环神经网络模型的分词算法
深度学习中的循环神经网络也适用于序列标注问题,可以采用 CNN、LSTM 等深度学习模型,结合 CRF 等分类算法,从而实现中文分词。
分词工具
常见的中文分词工具:
HanLP 分词器、Jieba(结巴)分词、哈工大的语言技术平台 LTP 及其语言云 LTP-Cloud、清华大学的中文词法分析工具包 THULAC、北京大学的中文分词工具包 pkuseg、斯坦福分词器、 基于深度学习的分词系统 KCWS、新加坡科技设计大学的中文分词器 ZPar、IKAnalyzer、 Jcseg、复旦大学的 FudanNLP、中文文本处理库SnowNLP、ansj 分词器、自然语言处理工 具包 NLTK、玻森中文语义开放平台 BosonNLP、简易中文分词系统 SCWS、IKAnalyzer、 庖丁解牛、中科院计算所 NLPIR 分词系统、腾讯文智、百度 NLP、阿里云 NLP、新浪云、 搜狗分词、盘古分词等等。
Jieba 分词
Jieba 分词是一个 Python 中文分词组件。
功能:可以对中文文本进行分词、词性标注、关键词抽取等,并且支持自定义词典。
原理:算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图,再采用动态规划查找最大概率路径,从而找出基于词频的最大切分组合。对于未登录词,它采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
特点:在词典文件添加自定义词典速度快,适用于词典数量大于五千万。但是其自定义词典时,带空格的词并不支持。
安装:
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过pycharm安装
模式:
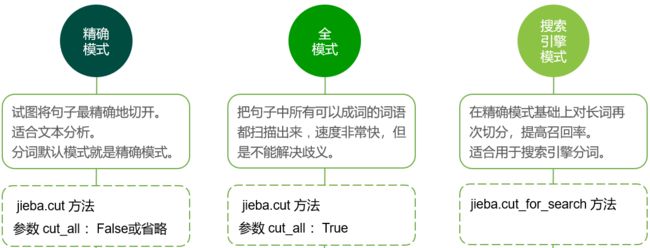
基本应用:

案例分析:
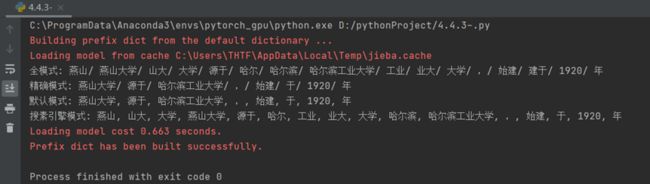
对“燕山大学源于哈尔滨工业大学,始建于 1920 年”这句中文文本,使用 Jieba 分词工具进行分词。
import jieba
# 全模式
seg_list = jieba.cut(" 燕山大学源于哈尔滨工业大学,始建于 1920 年 ",cut_all=True)
print(" 全模式 :", "/ ".join(seg_list))
# 精确模式
seg_list = jieba.cut(" 燕山大学源于哈尔滨工业大学,始建于 1920 年 ",cut_all=False)
print(" 精确模式 :", "/ ".join(seg_list))
# 默认是精确模式
seg_list = jieba.cut(" 燕山大学源于哈尔滨工业大学,始建于 1920 年 ")
print(" 默认模式 :",", ".join(seg_list))
# 搜索引擎模式
seg_list = jieba.cut_for_search(" 燕山大学源于哈尔滨工业大学,始建于 1920 年 ")
print(" 搜素引擎模式 :",", ".join(seg_list))