CVPR 2020:AAnet理论及实践学习笔记(以及RTX 3090环境配置)
文章目录
- 0 引言
- 1 深度学习环境配置
-
- 1.1 N卡驱动安装
- 1.2 cuda & cudnn安装
- 1.4 anaconda安装配置
- 2 aanet测试
-
- 2.1 准备数据、下载预训练模型、踩坑测试demo
- 2.2 aanet的思想是什么?可以给什么启迪?
0 引言
最近新入手了3090,目的是从事基于深度学习的三维重建方法,尤其是立体匹配,深度估计等方面的相关研究。为了配合深度学习的环境,将台式机装了ubuntu18.04的系统。
以下将首先介绍配置深度学习环境,然后主要搭配着aanet进行了实践学习。
1 深度学习环境配置
1.1 N卡驱动安装
-
首先是下载驱动,可以去nvidia的官网下载对应显卡的驱动程序,我这里下载了一份适用于ubuntu18.04,3090的驱动,放在了网盘里,链接及密码为:
链接: https://pan.baidu.com/s/1duGLEL8PW_47KEyvosxOvw 密码: i28s -
下载完驱动后,进入到驱动所在的位置,对驱动程序添加可执行的权限:
sudo chmod a+x NVIDIA-Linux-x86_64-460.39.run -
禁用ubutnu自带的驱动
ubuntu系统本身的交互性相对于centos等系统要好,究其原因或源于其自带的图形驱动,因此,它对于nvidia这些的支持并不那么友善,我们需要首先禁用其自带的驱动(nouveau)后,再安装我们已经下载好的驱动。具体的禁用ubuntu驱动的方式为:- 利用自己习惯的文字编辑器编辑配置文件,比如vim,gedit,vscode等。
sudo code /etc/modprobe.d/blacklist.conf - 跳转到最后一行(如果用的是vim,直接按G即可),并添加以下代码:
blacklist nouveau
保存。并执行sudo update-initramfs -u - 重启电脑:
reboot
- 利用自己习惯的文字编辑器编辑配置文件,比如vim,gedit,vscode等。
-
重启,并利用命令行登录ubutnu系统
重启后,要登陆的时候,不要直接输入自己的密码就登录了,这个时候按住ctrl+alt+F1,其实F2,F3,F4这三个也可以,相当于是多开了几个terminal。 -
禁用图形界面服务。
命令行登录后,输入lsmod | grep nouveau,如果这个时候什么都没有输出,就说明上一步骤禁用nouveau成功了。此时,禁用图形界面服务:
sudo service lightdm stop -
安装驱动
如果之前安装过其他nvidia的驱动,需要先卸载:sudo apt-get purge --remove nvidia*
安装驱动:
sudo ./NVIDIA-Linux-x86_64-430.50.run –no-x-check –no-nouveau-check –no-opengl-files
注意到在安装驱动的时候,命令后缀带了三个参数,分别是:1. -no-x-check, 即,安装驱动的时候关闭X服务。2. -no-nouveau-check,即,安装驱动时禁用nouveau。3. -no-opengl-files,即,只安装驱动,不安装其他opengl等文件。 -
安装完毕后,打开X图形界面服务:
sudo service lightdm start
这个时候进入图形界面。 -
测试是否安装驱动成功。
测试命令:nvidia-smi。如果显示出了gpu的型号信息之类的,则说明安装成功。
注:如果之后需要卸载这个驱动,执行的命令为:sudo ./NVIDIA-Linux-x86_64-430.50.run --uninstall
1.2 cuda & cudnn安装
其实我本来是不想要安装cuda的,觉得在虚拟环境或者docker里就可以了,为什么要大费周章安装cuda.但是在我想要试试aanet的时候,发现要用nvcc编译,就还是在本机上安装了cuda…
在安装cuda的时候,首先要确认下cuda与驱动之间的对应关系,如下表所示,避免出现折腾半天,最后版本不对,代码运行不成功的情况. 其实去下载cuda的时候,比如说下载cuda的runfile,其名字就已经表现了所需要的n卡驱动的版本了,比如:cuda_11.0.2_450.51.05_linux.run,意思是下载的是11.0.2版本的cuda,需要的N卡驱动版本至少得是linux下的450.51.05的。

cuda是可以安装多个版本的,安装顺序也不打紧. 反正要跑多个方法代码,不如就用安装多个版本的方式,然后视自己的情况选择需要的版本就可以了。
- 下载cuda
首先也是去官网下载自己需要的cuda版本. - 安装cuda
注意在已经安装了一个版本的驱动以及cuda后,再去安装其他版本的cuda的时候,不要安装driver,把那个写着driver的小叉叉给取消掉,不然会安装不成功的,有可能提示说没有关掉Xserver之类的。
我个人直接在这个步骤中,也把cudnn给装了,
$ sudo cp cuda/include//cudnn*.h /usr/local/cuda/include 把头文件复制到include目录
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64 把库文件复制到lib64目录
$ sudo chmod a+r /usr/local/cuda/include//cudnn*.h /usr/local/cuda/lib64/libcudnn* 修改所有复制后的头文件和库文件的权限
- 修改cuda环境变量.
我按照以下命令修改环境变量的时候,后来编译总是会说找不到/usr/local/cuda/bin之类的,究其原因是不知道为什么多了个冒号。我后来直接在需要跑的终端里进行环境变量的设置,就暂时没有报这个错误了。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda
- 版本切换
删除cuda,重新建立软链接即可
sudo rm -rf cuda
sudo ln -s/usr/local/cuda-11.1 /usr/local/cuda
参考链接:https://blog.csdn.net/yinxingtianxia/article/details/80462892
前面几个步骤,在参考链接中里面讲的很清楚了,这里就不赘述了.感谢博主的分享,如有侵权,则立即删.
1.4 anaconda安装配置
以aanet 为例,用的环境是PyTorch 1.2.0, CUDA 10.0 and python 3.7. 这部分环境建议是用anaconda开个虚拟环境.
下载地址为:
虚拟环境的安装直接根据aanet的readme说明进行即可。当然了,会遇到很多坑,下面aanet的测试里会讲。遇到很多坑的原因主要就是,人家aanet用的是cuda10.0,我手上的是30系的显卡,不匹配,cuda10.0不能支持sm_86的架构,之后会有非常非常多的麻烦,所以先不要直接用人家给的.yml搭建环境,搭建了还是要拆的…
2 aanet测试
大概先看了一下论文,打算先测试一下github上提供的预训练模型,然后再结合论文和代码进一步的精读,学习人家的理论思想还有一些实践上面的东西,比如说整体的文件树架构、深度学习框架的使用、cuda的学习、Python的语法知识点等等。
2.1 准备数据、下载预训练模型、踩坑测试demo
在深度学习配置中,已经准备好了aanet运行的环境.现在需要准备数据。在aanet的数据准备中,需要下载KITTI, SceneFlow数据… kitti文件夹下有KITTI-2012以及KITTI-2015。
暂时先不用公开的数据集进行。
由于sceneFlow的数据在网站上一直都下不下来,我就先下载了KITTI(2012和2015)的数据还有一个预先训练的模型作为测试。
之后,就开始用预训练的模型进行测试,在这个过程中报了非常多的错,具体为:
- 找不到’:\usr\local\cuda\bin’
解决:开始没有注意到有什么问题,觉得明明有这个文件夹,后来发现是路径前边儿有个:的原因。修改环境变量中的export CUDA_HOME=$CUDA_HOME:/usr/local/cuda为export CUDA_HOME=/usr/local/cuda之后就可以了。 - 解决问题1后,继续编译deform_conv,报错:
nvcc fatal : Unsupported gpu architecture ‘compute_86’。
这个是因为GPU的算力太高导致的,其实可以通过export TORCH_CUDA_ARCH_LIST="7.5"来暂时的解决,然而,即使编译的时候暂时的编译成功了,暂时的解决了这个问题,之后在跑代码的时候还是会出现这样的问题:CUDA Error: no kernel image is available for execution on device。究其原因,似乎是因为编译的算力和显卡的算力不匹配,所以,决定再安装一个cuda11.0版本,用cuda11.0的nvcc重新编译再试试,发现11.0也不支持sm_86,然后洗心革面,一口气安装了支持sm_86的***CUDA11.2以及配套的cudnn***。还利用conda安装了pytorch1.7.0+cu110的版本。
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
这个时候不再报ninja中’nvcc -v’还有那些找不到.o的错误了,转为了AT_CHECK的error,此时,将.cpp中的所有AT_CHECK替换为
TORCH_CHECK。再编译cudaExtension,终于不再报error了,可以成功生成.so文件,也可以成功在网络中引用和使用。
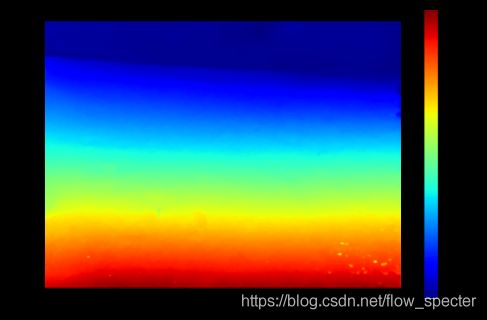
利用aanet里面提供的demo测试代码,测了一下仿照火星场景的立体像对:
CUDA_VISIBLE_DEVICES=0 python predict.py --data_dir demo --pretrained_aanet pretrained/aanet_sceneflow-5aa5a24e.pth --feature_type aanet --feature_pyramid_network --no_intermediate_supervision



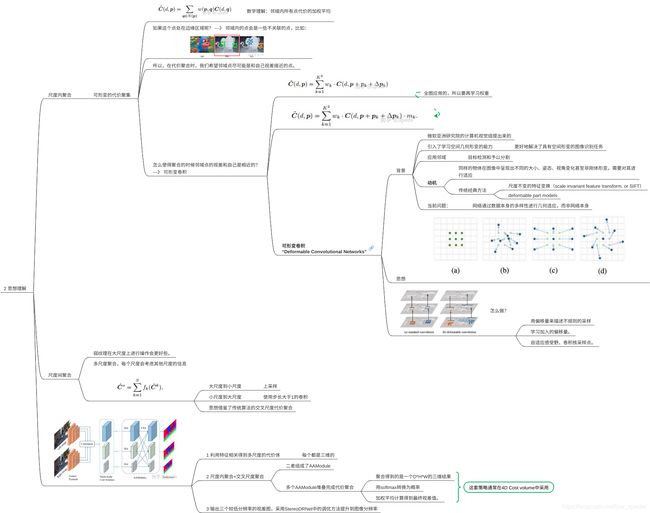
2.2 aanet的思想是什么?可以给什么启迪?
aanet的思想主要在于AAModules,由尺度内代价聚集和尺度间的代价聚集构成。
见以下的导图。
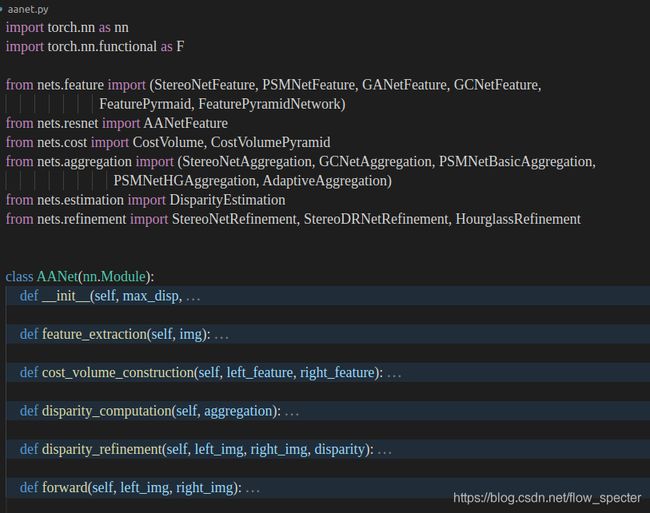
代码结构学习:
AANet类内共有6个函数,作用分别是初始化、特征提取、构建代价空间、视差计算、视差精化、以及forward。