基于深度学习的场景分割算法研究综述
基于深度学习的场景分割算法研究综述
人工智能技术与咨询

来自《计算机研究与发展》 ,作者张 蕊等
摘 要 场景分割的目标是判断场景图像中每个像素的类别.场景分割是计算机视觉领域重要的基本问题之一,对场景图像的分析和理解具有重要意义,同时在自动驾驶、视频监控、增强现实等诸多领域具有广泛的应用价值.近年来,基于深度学习的场景分割技术取得了突破性进展,与传统场景分割算法相比获得分割精度的大幅度提升.首先分析和描述场景分割问题面临的3个主要难点:分割粒度细、尺度变化多样、空间相关性强;其次着重介绍了目前大部分基于深度学习的场景分割算法采用的“卷积-反卷积”结构;在此基础上,对近年来出现的基于深度学习的场景分割算法进行梳理,介绍针对场景分割问题的3个主要难点,分别提出基于高分辨率语义特征图、基于多尺度信息和基于空间上下文等场景分割算法;简要介绍常用的场景分割公开数据集;最后对基于深度学习的场景分割算法的研究前景进行总结和展望.
关键词 场景分割;图像分割;深度学习;神经网络;全卷积网络
场景分割[1]是计算机视觉领域一个基本而重要的问题.相比一般的图像分割,场景分割针对场景图像.场景图像[2]是指面向某个空间的图像,通常具有一定的透视形变,且其中包含的视觉要素数量较多.场景分割算法的目标是对于场景图像中的每个像素判断其所属类别,如图1所示:

Fig. 1 Illustration of scene parsing
图1 场景分割问题
场景分割算法对于图像分析和场景理解具有极大的帮助.场景分割算法可以综合完成场景图像中视觉要素的识别、检测和分割,提高图像理解的效率和准确率.同时由于场景分割结果精确到像素级,相比图像分类和目标检测[3],场景分割结果可以提供更加丰富的关于图像局部和细节的信息.此外,场景分割算法具有广泛的应用价值和长远的发展前景.例如在自动驾驶技术中,场景分割算法可以通过对道路、车辆和行人的分割辅助自动驾驶系统判断道路情况;在视频监控技术中,场景分割算法可以通过对监控目标的分割协助进行目标的分析和跟踪;在增强现实技术中,场景分割算法可以通过分割场景中的前景和背景辅助实现多种增强现实效果.
作为计算机视觉领域的一个经典任务,场景分割极具挑战性.如图2所示,场景分割的难点可概括为3个方面:1)分割粒度细.场景分割结果需要精确到像素级别,且需要预测精确的分割边界.2)尺度变化多样.由于场景图像中通常包含多种类别的视觉要素,不同类别的视觉要素往往存在尺度差异,同时由于场景图像存在透视形变,相同类别的视觉要素也会呈现出不同尺度.3)空间相关性强.场景图像中的视觉要素存在复杂而紧密的空间相关关系,这些空间相关关系对视觉要素的识别和分割具有极大帮助.

Fig. 2 Difficulties in scene parsing
图2 场景分割的难点
场景分割问题是传统图像分割问题的子问题,近年来受到越来越多国内外研究人员的关注.在研究初期,研究人员使用传统的图像分割算法解决场景分割问题,包括基于阈值[4]、基于区域提取[5-6]、基于边缘检测[7]、基于概率图模型[8-10]和基于像素或超像素分类[11]的分割算法.这些传统分割算法通常使用人工设计的图像特征[12],与语义概念之间存在着语义鸿沟,因此制约了传统图像分割算法的性能.
近年来,深度学习的快速发展为场景分割带来了新的解决思路.深度学习算法通过构建多层神经网络,利用多层变换模仿人脑的机制来分析和理解图像.深度学习算法可以从大规模数据中学习逐渐抽象的层次化特征,从而建立场景图像到语义类别的映射.深度学习是近年来机器学习领域最令人瞩目的方向之一,在语音识别、计算机视觉、自然语言处理等多个领域均获得了突破性进展[13].基于深度学习的场景分割算法同样取得了巨大突破.这些算法主要基于“卷积-反卷积”结构,包括全卷积网络[14]和反卷积网络[15-16]两大类.“卷积-反卷积”结构可以建立从原始图像到分割结果的映射,并且可以进行端到端的训练.相比传统图像分割算法,基于深度学习的场景分割算法实现了分割精度的大幅度提升.在此基础上,研究人员针对场景分割问题的难点和挑战,提出了多种基于深度学习的场景分割算法并不断提高算法性能.其中,针对分割粒度细的问题,研究人员提出了基于高分辨率语义特征图的场景分割算法,通过提高特征图的分辨率获得更高精度的分割结果;针对尺度变化多样的问题,研究人员提出了基于多尺度信息的场景分割算法,通过捕捉场景图像中的多尺度信息提升算法的分割精度;针对空间相关性强的问题,研究人员提出了基于空间上下文信息的场景分割算法,通过捕捉场景图像中的空间上下文和相关关系提升算法的分割精度.
在国内外的研究成果中有许多对图像分割进行综述的文献,可以分为两大类:1)概述传统图像分割算法的综述[17-23],介绍了基于阈值、区域提取、边缘检测等利用图像特征的传统图像分割算法.2)侧重介绍基于深度学习的图像分割算法的综述[24-27].例如文献[24]侧重介绍不同图像分割算法使用的深度神经网络结构;文献[25]将上百种基于深度学习的图像分割算法分为10个大类进行概述;文献[26-27]以图像标注的粒度作为分类标准,分别介绍了全监督和弱监督的图像分割算法.但这些文献都是对通用的图像分割算法进行综述,目前并没有针对场景分割的算法综述.与这些综述不同,本文介绍的算法针对图像分割中的场景分割子问题,且主要介绍基于深度学习的算法.本文以算法针对的场景分割问题的3个难点作为分类依据,梳理近年来出现的基于深度学习的场景分割算法.
1 深度学习发展概述
深度学习算法近年来在机器学习领域取得了巨大的进展,其中,基于深度卷积神经网络的算法在计算机视觉领域取得了令人瞩目的成就.深度卷积神经网络是以传统的神经网络为基础,不断发展演变而来.早在1998年“LeNet”网络[28]就已具备现在深度卷积神经网络的完整结构,包括卷积层、非线性变换层、池化层、全连接层等深度卷积神经网络的基本单元.因此,“LeNet”网络可以被视为当前深度卷积神经网络的雏形.然而,计算能力和数据集规模的限制阻碍了深度卷积神经网络的发展.
近年来,随着硬件设备的不断发展和计算能力的不断提高,计算机的运算速度和效率得到了极大提升.尤其是图像并行处理单元(graphics processing unit, GPU)的广泛使用提高了大规模并行计算的能力.此外,随着互联网的兴起和大数据技术的发展,多种大规模图像数据集相继出现,为训练深度卷积神经网络提供数据支持.得益于并行计算能力和大规模数据集,深度卷积神经网络在以图像识别为代表的计算机视觉领域相关任务中取得了惊人的突破.在2012年的“ImageNet大规模视觉识别挑战赛”[29]中,卷积神经网络模型AlexNet[30]将ImageNet分类数据集[31]的Top-5识别错误率从传统算法的26%降低到16.4%,取得了令人振奋的进步.这一工作也掀起了深度卷积神经网络的研究热潮.
此后,越来越多的研究人员投身到对深度卷积神经网络的研究中.以图像识别任务为切入点,研究人员不断提出更深更精巧的网络结构和非线性激活函数提高神经网络的特征表达能力,先后提出了VGG[32],GoogLeNet[33],ResNet[34],ResNeXt[35],DenseNet[36]等网络和Maxout[37],PReLU[38],ELU[39]等非线性激活函数.同时,研究人员还通过设计合理的网络初始化方法[38,40]和特征归一化方法[41-44]促进神经网络的优化过程.深度卷积神经网络可以从大规模数据中自动学习到逐渐抽象的层次化特征,从底层图像特征到高层语义概念的映射.因此,利用在大规模图像识别数据集上预训练的深度卷积神经网络可以学习到合适的图像特征表达,并通过迁移学习的方法被应用于计算机视觉领域的诸多任务中,均取得了极大的成功.例如目标检测算法[45-47]利用深度卷积神经网络同时预测图像中目标的类别和位置;图像语义分割算法[14,48]利用深度卷积神经网络预测图像中每个像素的类别;实例分割算法[49]利用深度卷积神经网络同时预测图像中每个目标的类别、位置和包含像素;图像描述算法[50]利用深度卷积神经网络学习图像特征,并输入到循环神经网络中生成图像的描述.
2 场景分割算法的“卷积
![]()
反卷积”框架
目前基于深度学习的场景分割算法主要利用了一种“卷积-反卷积”框架,包含卷积模块和反卷积模块.首先卷积模块使用若干卷积层和池化层,逐渐从场景图像中学习到抽象的语义特征表达,获得语义特征图.由于使用了若干次池化层,生成的语义特征图分辨率小于原始图像.为获得原始图像的像素级类别预测结果,语义特征图将输入到由多个反卷积层组成的反卷积模块,不断扩大特征图的分辨率,直至与原始场景图像分辨率相同.最终获得的特征图中每个位置对应场景图像中每个像素的类别置信度,从而得到场景图像的分割结果.“卷积-反卷积”框架可以高效地对整幅场景图像进行处理,从原始图像直接获得分割结果.同时,在训练过程中,“卷积-反卷积”框架可以进行端对端的训练,更有益于从场景数据集中学习合适的特征表达,因此其性能优于传统图像分割算法.
常用的“卷积-反卷积”框架主要可分为全卷积网络和反卷积网络两大类.全卷积网络[14](fully convolutional network, FCN)通常以深度图像识别网络作为基础,将其结构全卷积化后作为卷积模块,获得语义特征图,再添加若干反卷积层作为反卷积模块,如图3所示.全卷积化是指将图像识别网络中的全连接层转化为卷积核为1的卷积层,使网络仅由卷积层、非线性激活层和池化层组成.经过全卷积化之后,全卷积网络可以接受任意大小的场景图像作为输入,并通过多个反卷积层获得与原始输入图像相同大小的类别置信度图.利用深度图像识别网络的结构作为卷积模块后,可以利用深度图像识别网络在大规模的图像分类数据集(如ImageNet)上预训练得到的网络参数作为全卷积网络的初始化参数.这种参数迁移的方法有利于全卷积网络参数的优化.由于场景分割需要精确到像素级,构建场景分割的人工标注需要花费大量的人力物力,导致现有的场景分割数据集的样本数量通常较少.而训练深度神经网络通常需要大量有标注的数据,因此如果直接使用样本数量较少的场景分割数据集训练,可能因为样本不够导致模型陷入精度较低的局部极小点,损害模型的精度.而使用大规模图像识别数据集进行预训练后,模型参数可以学习到较为合适的图像特征表达,为后续训练场景分割模型提供较好的初始值,帮助模型收敛到精度较高的局部极小点,从而提升场景分割模型的性能.利用数据集SIFT Flow[51]进行评测,全卷积网络的像素级正确率(pixel accuracy)达到85.2%,相比传统方法[52]的78.6%,取得6.6%的性能提升.在目前常用的场景分割数据集Cityscapes[53]上全卷积网络可以取得平均交并比(mean Intersection-over-Union, mIoU)为65.3%,达到当时的最佳性能.

Fig. 3 FCN is transferred from an image recognition network
图3 全卷积网络由图像识别网络全卷积化形成
相比之下,反卷积网络[15-16]的卷积模块与全卷积网络类似,也是由多个卷积层和池化层堆叠而成.通常其反卷积模块完全采用其卷积模块的镜像结构,同时设计了反池化层作为池化层的镜像操作.反卷积网络不使用预训练参数,而是直接从随机参数开始训练网络,因此时常难以优化,算法性能也会低于全卷积网络,如SegNet[16]在Cityscapes数据集上的mIoU为57.0%.目前,大部分基于深度学习的场景分割算法都采用了全卷积网络的结构,同时利用深度图像识别网络的预训练参数作为初始化.
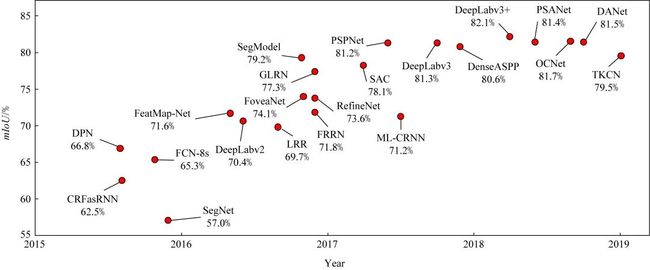
Fig. 4 Results of scene parsing algorithms based on deep learning on Cityscapes dataset
图4 基于深度学习的场景分割算法在Cityscapes数据集上的性能
全卷积网络虽然在场景分割问题上取得了极大的突破,但其本身依赖于大规模图像识别网络结构,存在着一定的局限性.首先,全卷积网络所使用的图像识别网络模型通常包含多次池化等下采样操作,因此丢失了许多细节信息.而场景分割问题具有分割粒度细的特点,因此直接使用图像识别网络会极大损害最终的分割精度.针对这一问题,研究人员提出了基于高分辨率语义特征图的场景分割算法提高分割精度.其次,场景分割问题存在视觉要素尺度变化多样的问题,但全卷积网络对整幅图像使用相同的卷积操作,未考虑视觉要素的多尺度问题,损害了场景图像中较大尺度和较小尺度的视觉要素的分割精度.因此,研究人员提出了基于多尺度的场景分割算法.最后,全卷积网络所使用的图像识别网络未考虑空间上下文信息,而场景分割问题存在空间相关性强的特点,场景图像中的空间相关关系对提升分割精度有极大帮助.为了有效捕捉场景图像中的空间上下文和相关关系,研究人员提出了基于空间上下文的场景分割算法.接下来我们将对这些方法进行梳理和详细介绍.其中一些代表性方法在City-scapes数据集测试集上的性能对比如图4所示:
3 基于高分辨率语义特征图的场景分割算法
全卷积网络中使用图像识别网络的结构学习场景图像的特征表达.而在图像识别网络中,为了能有效捕捉图像的全局语义特征,排除图像中视觉要素的空间变换对特征学习的干扰,图像识别网络通常包含若干个步长大于1的池化层.池化层可以融合池化区域的特征,扩大感受野,同时保持感受野中视觉要素的平移不变形.但同时,池化操作会缩小特征图的分辨率,从而丢失空间位置信息和许多细节信息.例如在目前常用的图像识别网络中,通常使用5个步长为2的池化层,使最后的语义特征图分辨率下降为原始输入图像的1/32.因此,当图像识别网络被迁移到全卷积网络中后,语义特征图的分辨率过小和丢失过多细节信息导致分割边界不准确,从而影响了全卷积网络的分割精度.针对该问题,研究人员提出了诸多基于高分辨率语义特征图的算法,包括利用跨层结构、膨胀卷积和基于全分辨率的算法.

Fig. 5 Illustration of atrous convolution
图5 膨胀卷积
3.1 跨层结构算法
基于跨层结构的算法[14,54-56]通过融合较浅层的特征图提高语义特征图的分辨率.在前向传播过程中,卷积神经网络的特征图分辨率逐渐变小,每经过一个池化层,特征图的边长会减小为原来的1/2.因此较浅层的特征图分辨率较大,保留了更多的细节.基于跨层结构的算法其基本思路为通过融合较浅层的分辨率较大的特征图,提高语义特征图的分辨率,捕捉更多的细节信息,从而提高分割精度.这些基于跨层结构的算法通常在反卷积模块中融合较浅层的特征图,通过使用反卷积层将语义特征图的分辨率扩大后,与网络浅层特征图的分辨率恰好相等,然后进行融合,之后进行后续的反卷积操作.例如FCN-8s[14]通过融合分辨率为原始图像大小的1/16和1/8的浅层特征图,将Cityscapes数据集的mIoU性能从61.3%提高到65.3%;U-Net[54]将从1/16到原始图像大小的特征图均进行了融合;LRR[55]借鉴了拉普拉斯金字塔结构,通过利用多个浅层的不同分辨率特征图对细节进行重建获取高分辨率的语义特征图,在Cityscapes数据集上取得69.7%的mIoU;RefineNet[56]设计了一种递归的多路修正网络结构,利用浅层高分辨特征图中的信息对深层低分辨率的特征图进行修正,从而生成高分辨的语义特征图,在Cityscapes数据集上将mIoU提高到73.6%.基于跨层结构的算法通过在反卷积模块中利用浅层特征图恢复卷积模块中丢失的细节信息,但是由于这些细节信息难以被完美恢复,这限制了跨层结构算法的分割性能.
3.2 膨胀卷积算法
基于跨层结构的算法主要在“卷积-反卷积”结构的反卷积模块提升语义特征图的分辨率,但在卷积模块中语义特征图的分辨率依然会下降到非常低,如原始输入大小的1/32.而基于膨胀卷积的算法[48,57-59]着眼于在卷积模块中保持语义特征图的分辨率,如保持在原始输入大小的1/8,这样就可以在卷积模块中保留更多的细节信息.
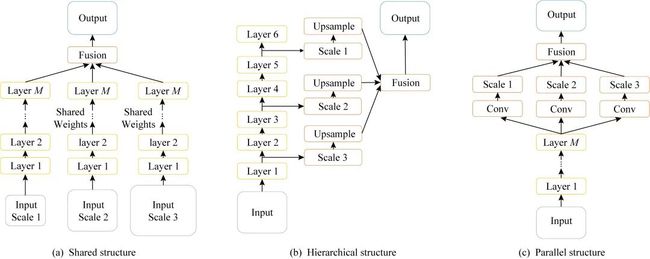
Fig. 6 Multi-scale scene parsing algrithms based shared structure, hierarchical structure and parallel structure
图6 基于共享结构、层级结构、并行结构的多尺度场景分割算法
图像识别网络中,特征图分辨率的下降是由步长为2的池化操作引起的,即每2步的计算中丢弃1个结果.如果将池化操作的步长从2改为1,则可以保持特征图的分辨率,即保留了上述被丢弃的结果.但在后续的卷积操作中,特征图中原来相邻的特征向量间插入了本应被丢弃的特征向量,与卷积核直接相乘时会造成错位,导致错误的卷积结果.为解决该问题,DeepLab系列算法[48,57-59]使用了膨胀卷积操作代替标准卷积.如图5所示,膨胀卷积会在卷积核向量中插入一个0,将卷积核边长“膨胀”为原来的2倍.膨胀后的卷积核与修改池化操作步长后得到的特征图进行卷积,可以有效解决相乘错位的问题.原来被丢弃的特征向量会恰好与插入的0相乘,并不影响最终的卷积结果.因此,膨胀卷积可以保证将池化操作的步长从2改为1后,后面的卷积层依然可以得到正确的卷积结果.值得注意的是,若某一个池化层的步长从2改为1,其后的所有卷积层均需使用膨胀系数为2的膨胀卷积.如果后面又出现了将池化层的步长从2改为1的修改,则在之后的所有卷积层的膨胀系数需要再乘2,即使用膨胀系数为4的膨胀卷积,以此类推.例如,将图像识别网络的第4和第5阶段的池化层步长从2改为1,并对其后的卷积层分别使用膨胀系数为2和4的膨胀卷积,将卷积模块的语义特征图分辨率从原始图像大小的1/32提高到1/8.使用膨胀卷积可以在“卷积-反卷积”结构的卷积模块中保持较高分辨率的语义特征图,从而保留更多的细节信息,提高分割的精度,例如DeepLabv2[48]在Cityscapes数据集上取得mIoU为70.4%.膨胀卷积算法由于其方便有效的特点,被广泛应用于场景分割算法的卷积模块中.
3.3 全分辨率算法
基于膨胀卷积的算法只对语义特征图进行一定程度的扩大,从原始图像的1/32扩大为1/8,依然丢失了部分细节信息,对分割边界的确定造成一定影响.相比之下,全分辨率残差网络(FRRN)[60]则提出了一种基于全分辨率特征图的算法,将特征图分辨率始终保持在原始图像大小.该算法借鉴了残差学习的思想,包含2个信息流:残差流和池化流.其中残差流不包含任何池化和下采样操作,将该流的特征图始终保持在与原始图像相同的分辨率大小;而池化流则包含若干步长为2的池化操作,特征图的分辨率先减小后增大.残差流侧重于捕捉细节信息,主要用于确定精确的分割边界;而池化流则侧重于学习语义特征,主要用于识别视觉要素的类别.残差流和池化流在网络的前向传播过程中不断进行交互,从而使全分辨率残差网络可以同时学习语义特征和捕捉细节信息,因此可以获得更加精确的分割结果.FRRN在Cityscapes数据集取得的mIoU为71.8%.但全分辨率残差网络也有其局限性.由于残差流始终保持在原始图像的分辨率,因此其维度较高,会占用大量的显存空间.同时,残差流和池化流的交互操作也会产生大量的空间消耗.这都制约了全分辨率残差网络在高分辨率场景图像中的使用.
4 基于多尺度的场景分割算法
由于场景图像中存在一定的透视畸变,且包含多种类别的视觉要素,因此场景图像中视觉要素的尺度是多样的.而卷积神经网络的感受野大小是固定的.对于图像中尺度较大的视觉要素,感受野只能覆盖其局部区域,容易造成错误的识别结果;而对于图像中尺度较小的视觉要素,感受野会覆盖过多的背景区域,导致误判为背景类别.针对上述问题,研究人员提出了基于多尺度的场景分割算法,通过获取多尺度信息学习不同尺度视觉要素的特征表达,以提高场景分割的精度.大部分基于多尺度的算法通过设计不同的网络结构获取多尺度特征,可分为共享结构、层级结构、并行结构3类,如图6所示.这些算法所采用的尺度通常通过人工设计,与网络的结构紧密相关.获取多尺度信息之后再通过多种方法融合多尺度特征.另外一些算法则利用自适应学习而非人工设计的方法获取多尺度特征.
4.1 共享结构算法
基于共享结构的算法[61-62]主要在卷积模块中利用一个参数共享的卷积神经网络.通过将输入图像缩放为不同的尺度(通常使用2~3种),均输入到共享网络中,从而获取不同尺度的语义特征图.之后通过上下采样将不同尺度的语义特征图插值到相同的分辨率,再进行特征融合.这种算法并没有改变卷积神经网络的结构,即没有改变网络的感受野大小,而是通过调整输入图像的尺度获取多尺度特征.同时通过将输入图像进行缩放,使共享网络获得处理多尺度视觉要素的能力.利用共享结构,FeatMap-Net[62]在Cityscapes数据集上达到mIoU为71.6%.基于共享结构的算法需要将同一幅输入图像利用不同尺度计算若干次,因此会使卷积模块的计算量成倍增加,降低分割速度.
4.2 层级结构算法
基于层级结构的算法[63-65]通过卷积神经网络不同阶段的特征图获取多尺度信息.卷积神经网络在前向传播过程中,随着卷积和池化操作,感受野不断增大.较浅层的特征图对应的感受野较小,特征的尺度也较小;而较深层的特征图对应的感受野较大,特征的尺度也较大.因此,通过融合卷积神经网络不同阶段的特征图即可获取多尺度信息.
利用层级结构,ML-CRNN[65]在Cityscapes数据集的mIoU达到71.2%.由于不同阶段特征图的分辨率不同,融合前需要利用上下采样等方法将特征图插值到相同的分辨率再进行融合.基于层级结构的算法不会引起过多的计算量,但卷积神经网络的较浅层通常更偏重学习图像的视觉特征,而较深层更偏重学习图像的语义特征.将浅层与深层特征进行融合时会对最终的语义特征图引入一定的噪声,损害语义表达的精确度.
4.3 并行结构算法
基于并行结构的算法在卷积模块获得的语义特征图之后连接多个感受野不同的并行分支,形成一种并行的结构,以捕捉不同尺度的特征.其中,PSPNet[66]使用空间金字塔池化,利用不同系数的池化层生成对应多个尺度的分支,再利用不同的上采样系数在特征图上采样到相同的分辨率,在Cityscapes数据集上获得mIoU为81.2%.而DeepLab系列算法[48,58-59]则使用多尺度膨胀卷积的思想,建立ASPP(atrous spatial pyramid pooling)模块,利用不同系数的膨胀卷积层生成对应多个尺度的分支.ASPP模块中不同分支的特征图分辨率相同,融合前不需要进行上采样.其中,在Cityscapes数据集上DeepLabv3[58]的mIoU为81.2%,而DeepLabv3+[59]则将mIoU提升至82.1%.TKCN[67]将多个并行分支建立为树型结构,提高了多尺度融合的效率,在Cityscapes数据集上的mIoU达到79.5%.Dense ASPP[68]将并行的ASPP模块内部加入全连接,从而高效地扩增了ASPP模块能够捕捉的尺度,并在Cityscapes数据集上DeepLabv3的mIoU达到80.6%.基于并行结构的算法仅需在语义特征图之后加入几个新的分支,因此增加的计算量远远小于基于共享结构的算法.同时由于这些并行分支都是从卷积模块获得的语义特征图计算得到,相比基于层级结构的算法更加适合于进行语义特征的学习.
4.4 多尺度特征融合
利用4.1~4.3节所述的结构获取多尺度特征后,还需要将特征融合起来以预测分割结果.目前主流的特征融合算法包括特征连接、加权融合或基于注意力机制.基于特征连接的算法[63-64]将不同尺度的特征直接按通道进行拼接,后面连接一个卷积层或全连接层进行融合.因此这个卷积层的参数可以被视为是多尺度特征的融合系数.基于加权融合的算法[48]则对每个尺度的特征使用不同的融合系数,这些融合系数通常是人工预设的.基于注意力机制的融合算法[61,65]则通过学习不同尺度、不同位置最合适的注意力参数进行融合.这3种融合算法的最大区别是其需要的融合系数数量不同.其中特征连接算法使用的融合系数数量最多,特征图的每个尺度、每个位置、每个通道的值都需要学习不同的融合系数;而加权融合算法使用的融合系数数量最少,仅需要与尺度数量相同的融合系数,这是因为相同的尺度特征在不同的位置和通道的值均使用相同的系数;而使用注意力机制的算法需要的融合系数数量介于特征连接和加权融合算法之间,其思想为在每个空间位置学习最合适的尺度融合系数.因此虽然不同尺度、不同位置需要利用注意力思想学习不同的融合系数,但同一通道内会共享融合系数.在实际应用中,特征连接算法参数量较大,加权融合算法相对简单便捷,但需要人工设定合适的融合系数.而由于场景图像中不同空间位置的视觉要素尺度不同,使用注意力机制对不同空间位置学习不同的融合系数常常可以有效提高特征融合的效果,从而获得较高的分割精度.

Fig. 7 Different structures of RNN in scene parsing
图7 场景分割中循环神经网络的不同结构
4.5 自适应学习算法
4.4节所述的基于多尺度融合的算法所捕捉的尺度通常是人工预设的,且受限于计算复杂度一般仅使用3~5种尺度.这些人工设计的尺度无法涵盖场景图像中的视觉要素可能出现的所有尺度,会出现遗漏和偏差.视觉要素的尺度可能会较大或较小,超出人工预设尺度的范围;而尺度在人工预设范围内的视觉要素也不一定会恰好符合某个预设尺度,而是更可能介于2个预设尺度之间.针对以上问题,文献[69-72]提出了基于自适应学习的多尺度变换算法.其中SAC[69]通过自适应学习卷积核的缩放系数调整卷积的感受野大小,从而对场景图像的不同空间位置学习多种尺度的特征,在Cityscapes数据集上的mIoU达到78.1%.而DeformableNet[71]则通过学习卷积核中卷积向量的偏移对卷积的感受野产生形变,也可以实现学习多种尺度特征的目的,并在Cityscapes数据集上获得的mIoU为75.2%.FoveaNet[72]借鉴目标检测的思想,先自适应检测场景图像中视觉要素尺度较小的区域,然后将该区域放大进行特征学习,最后融合2种尺度的结果,在Cityscapes数据集上的mIoU为74.1%.相比人工预设尺度,基于自适应学习的算法更加灵活,学习到的尺度更加贴合场景图像中视觉要素的实际尺度.
5 基于空间上下文的场景分割算法
场景图像存在着复杂的空间相关关系,可以用于区分视觉上较为相似的类别,对于视觉要素的识别具有重要的帮助作用.而目前基于“卷积-反卷积”结构的场景分割算法所得到的语义特征图是通过卷积的滑动窗口操作计算所得,特征向量之间并没有交互,即并没有考虑场景图像的空间相关关系.针对上述问题,研究人员提出了基于空间上下文的场景分割算法,通过捕捉场景图像的空间上下文信息和相关关系辅助视觉要素的识别,进一步提升分割精度.基于空间上下文的算法主要分为基于多维循环神经网络、基于概率图模型和基于注意力机制的算法.
5.1 基于多维循环神经网络
多维循环神经网络[73]具有循环的结构,适用于序列数据的编码和特征学习.在循环的过程中,多维循环神经网络可以不断存储序列中的有用信息而丢弃无关信息,同时捕捉序列前后节点之间的相关关系.因此,可以利用多维循环神经网络捕捉场景图像中的空间上下文信息和相关关系.为缩短循环神经网络的序列长度、降低计算复杂度,文献[74-76]将循环神经网络连接于卷积模块得到的低分辨率语义特征图之后,对语义特征图的特征向量进行编码.另一些算法[65,77-78]则在深度神经网络不同层的特征图之间利用循环神经网络进行编码,从不同层的特征图中捕捉空间上下文信息.针对语义特征图的结构特点,研究人员将循环神经网络设计为对角结构、八邻域结构、图结构等不同的拓扑结构,如图7所示.对角结构算法[65,74]从语义特征图的某个角点(如左上角点)出发,向对角方向进行编码.在每一步的编码过程中,均使用水平(如从左到右)、垂直(如从上到下)、对角(如从左上到右下)3个方向的特征作为序列的输入.为兼顾不同方向的空间上下文信息,可以将语义特征图的4个角点均作为出发点,将得到的4个方向编码结果进行融合,从而获取整幅图像的空间上下文信息.基于八邻域结构的算法[75]则以语义特征图中的每个特征向量作为出发点,向周围的8个方向进行辐射和传播,逐渐扩大到整幅图像,因此语义特征图中的每个位置都会聚合整幅图像的空间上下文信息.对角结构和八邻域结构算法都将语义特征图中的每个特征向量作为序列单元.与之不同的是,图结构算法[76-77]结合了图像的低层特征,使用图像的超像素对应的特征向量作为序列单元.同时通过超像素的邻接关系构建图结构,然后建立序列对超像素对应的节点进行特征编码.利用多维循环神经网络,ML-CRNN[65]使用对角结构对不同层特征图进行编码捕捉空间上下文,在Cityscapes数据集上取得的mIoU为71.2%.
5.2 基于概率图模型
概率图模型具有很强的概率推理能力,通过最大化特征的概率分布获得类别预测结果.概率图模型也被应用于场景分割中捕捉场景图像的空间上下文信息和相关关系.为有效减少概率图模型的计算复杂度,通常在卷积模块获得的低分辨率语义特征图之后建立概率图模型,并以语义特征图的特征向量作为概率图模型的节点.概率图模型通常被建模为某种特殊的层插入到卷积神经网络的整个结构中,实现端对端的训练和优化.其中最常用的是Markov随机场和条件随机场.Markov随机场基于Markov模型和贝叶斯理论,可以根据计算统计最优准则确定分割问题的目标函数,通过求解满足目标函数的分布将分割问题转化为最优化问题.DPN[79]将深度卷积神经网络与Markov随机场结合,设计同时性卷积层近似Mean-field算法对Markov随机场进行求解,在Cityscapes数据集上的mIoU达到66.8%.条件随机场模型则是基于无向图的概率模型,计算条件随机场模型的能量函数中的势函数,通过最大化类别标签的条件概率来得到无向图中节点的预测类别.CRFasRNN[80]将条件随机场利用循环神经网络进行建模,连接在深度卷积神经网络之后进行端对端的训练,在Cityscapes数据集上的mIoU达到62.5%.FeatMap-Net[62]在多尺度融合得到的语义特征图之后建立条件随机场模型学习“块与块”和“块与背景”的相关关系捕捉空间上下文,在Cityscapes数据集上取得的mIoU为71.6%.SegModel[81]利用条件随机场同时捕捉特征图和人工标注见的空间上下文,从而提高分割精度,在Cityscapes数据集上获得的mIoU为79.2%.
5.3 基于注意力机制
基于注意力机制的算法[82-85]通过融合局部区域内的特征向量捕捉场景图像中的空间上下文信息和相关关系.在使用注意力机制时,需要添加额外的层学习注意力系数,之后利用该系数对局部区域内的特征向量进行加权聚合.由于注意力系数的学习和局部特征的聚合过程都是可导的,注意力机制可以灵活被插入在神经网络的不同位置,并进行端对端的学习.由于注意力系数对局部区域内的不同位置会学习到不同的参数,因此在聚合时可以提高局部区域内相关信息的影响,并抑制局部区域内的无关信息的影响.同时,特征图中的不同位置可以通过模型训练学习到最适合的注意力系数,从而有效捕捉空间上下文信息和相关关系.GLRN[82]通过学习注意力参数学习局部聚合系数捕捉局部上下文,对分割结果的边界进行修正,在Cityscapes数据集上的mIoU达到77.3%.PSANet[83]利用注意力机制学习双向自适应聚合参数捕捉局部上下文,在Cityscapes数据集上取得的mIoU为81.4%.DANet[84]设计了2个注意力分支,分别学习针对位置和通道的注意力参数,用于捕捉局部和全局空间上下文,在Cityscapes数据集上的mIoU达到81.5%.OCNet[85]利用注意力机制学习针对相同视觉类别的空间上下文,在Cityscapes数据集上取得的mIoU为81.7%.
6 场景分割相关数据集
场景分割数据集对验证场景分割算法的有效性有重要意义.同时,带标注的大规模数据集可以有效提升深度学习模型的性能.由于场景分割需要对场景中的每个像素进行类别识别,场景分割数据集的人工标注也需要精确到像素级别,因此场景分割数据集的标注工作十分费时费力.近年来,公开的场景分割数据集数量越来越多,规模越来越大,为场景分割问题的发展起到极大的推动作用.本节将从数据集规模等方面介绍常用的场景分割数据集,并分析其特点.这些数据集的基本信息如表1所示,部分示例如图8所示.
Table 1 Common Scene Parsing Datasets
表1 常用的场景分割数据集
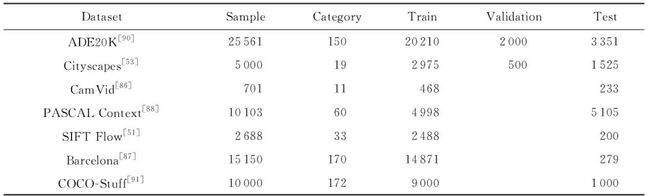

Fig. 8 Samples of common scene parsing datasets
图8 常用的场景分割数据集示例
6.1 SIFT Flow
SIFT Flow数据集[51]中的图像由8种典型的户外场景组成.该数据集共包含2 688个图像样本,其中2 488个训练样本、200个测试样本,每个图像的分辨率为256×256.同时数据集中包含33个语义类别的像素级人工标注.SIFT Flow数据集的图像分辨率较小,场景比较简单,类别数和图像数量较少.
6.2 CamVid
CamVid数据集[86]中的图像均采集于街景,包括701个街景图像,其中包括468个训练图像和233个测试图像.每个图像样本的分辨率为960×720,并且包含11个语义类别的像素级人工标记.CamVid数据集的类别数和图像数量较少,但图像分辨率相对较大,场景针对于街景,对自动驾驶相关技术具有极大意义.
6.3 Barcelona
Barcelona数据集[87]由14 871个训练图像样本和279个测试图像样本组成.其中训练图像采集于室内和室外场景,而测试图像均采集于巴塞罗那的街道场景.该数据集中不同图像样本的分辨率不同,并且包含170个语义类别的像素级人工标记.
6.4 PASCAL Context
PASCAL Context数据集[88]是以PASCAL VOC数据集[89]为基础建立的.原始PASCAL VOC数据集仅标注了前景视觉要素的类别,而PASCAL Context数据集还提供了背景视觉要素的类别,因此更加适合于场景分割算法.PASCAL Context数据集包括4 998个训练图像样本和5 105个测试图像样本,每个图像样本的分辨率不超过500×500,并被标记为59个类别和1个其他类.相比原始PASCAL VOC数据集,PASCAL Context数据集包含的图像样本和类别数量更多,难度也更大.
6.5 Cityscapes
Cityscapes数据集[53]中的图像是利用车载摄像头采集的欧洲城市的街景.该数据集包含共5 000个图像样本,划分为2 975个训练图像样本、500个验证图像样本和1 525个测试图像样本.数据集中包含19个类别的像素级的人工标注,其中每个图像样本的分辨率为2048×1024.Cityscapes数据集针对于街道场景,包含的图像样本数量和类别数较少,但图像的分辨率较大,这就需要在设计算法时同时兼顾算法速度和性能,对自动驾驶相关技术具有重大的意义,是目前评测深度学习场景分割算法常用的数据集之一.
6.6 ADE20K
ADE20K数据集[90]取材于Places场景分类数据集.该数据集包含20 210个训练图像样本、2 000个验证图像样本和3 351个测试图像样本,同时包含150个语义类别的像素级人工标注.数据集中图像样本的分辨率不同且差距较大,最小的图像边长约200像素,最大的图像边长超过2 000像素.ADE20K数据集包含的场景类别较多,有会议室、卧室等室内场景,也有沙滩、街道等室外场景,且数据集中包含的样本数量和类别数也较多,图像的分辨率差距较大,因此ADE20K数据集的难度较高,对场景分割算法提出了更大的挑战,也催生了一部分优秀的研究成果,是目前评测深度学习场景分割算法常用的数据集之一.
6.7 COCO-Stuff
COCO-Stuff数据集[91]是在COCO数据集[92]的基础上对标注进行扩展得到的.与PASCAL Context数据集和PASCAL VOC数据集的关系类似,原始COCO数据集仅标注了前景视觉要素的类别,而COCO-Stuff数据集还提供了背景视觉要素的类别,因此更加适合于场景分割算法.COCO-Stuff数据集共包含10 000个图像样本,其中9 000个训练图像样本和1 000个测试图像样本.同时包含172个类别的像素级标注,其中80个前景类别、91个背景类别和1个无标注类别.COCO-Stuff数据集包含的场景种类、语义类别和图像样本数量均较多,因此难度较高,对场景分割算法提出了更大的挑战,是目前评测深度学习场景分割算法常用的数据集之一.此外,COCO-Stuff数据集还可作为预训练数据集,从而提升深度学习场景分割模型在其他场景分割数据集上的性能.
7 算法泛化能力分析
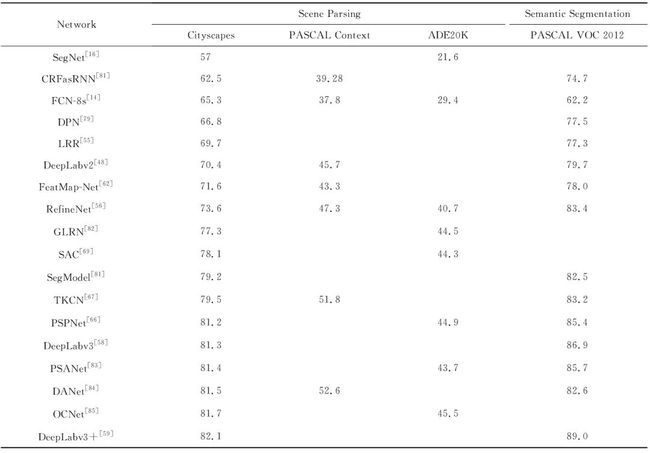
算法泛化能力对算法的实际应用具有重要意义.我们从2个方面分析基于深度学习的场景分割算法的泛化能力:1)算法在不同数据集的泛化能力;2)算法在不同任务的泛化能力.表2展示了目前流行的基于深度学习的场景分割算法在不同场景分割数据集的分割精度,包括Cityscapes[53],PASCAL Context[88]和ADE20K[90]这3个数据集.同时列举了部分算法在语义分割数据集PASCAL VOC 2012[89]的分割精度.语义分割不需要对背景类别进行分割,与场景分割相比更加关注前景的类别,因此场景分割与语义分割是不同的图像分割子任务.首先,我们对比表2中现有基于深度学习的场景分割算法在场景分割不同数据集上的结果.由于不同数据集存在着类别差异,导致同一算法在不同数据集的精度值会有一定差异.但总体看来,在其中某个场景分割数据集上分割精度较高的算法在另外2个场景分割数据集的精度也相对较高,这说明现有算法在场景分割的不同数据集上具有较好的泛化能力.其次,我们对比表2中算法在场景分割和语义分割数据集上的结果.总体而言,在场景分割数据集上分割精度越高的算法在语义分割数据集上也可以得到越高的分割精度,这说明现有场景分割算法在不同的分割子任务上也具有较好的泛化能力.
Table 2 Generalization Ability of Scene Parsing Algorithms Based on Deep Learning
表2 基于深度学习的场景分割算法的泛化能力
8 总结与展望
本文通过对近年来出现的基于深度学习的场景分割算法进行梳理和介绍,得到3个结论:
1) 目前基于深度学习的场景分割算法主要使用了全卷积网络框架,该框架利用在大规模的图像分类数据集上预训练得到的图像识别网络,全卷积化后迁移到场景分割数据集上进行重新训练.全卷积网络的分割性能优于传统基于图像特征的场景分割方法,将SIFT Flow数据集[51]的像素级正确率从传统方法[52]的78.6%提升至85.2%.
2) 针对场景分割中面临的分割粒度细、尺度变化多样、空间相关性强3个主要难点和挑战,在全卷积网络的基础上,研究人员提出诸多基于深度学习的场景分割算法.其中针对分割粒度细的问题,研究人员提出了基于高分辨率语义特征图的算法,包括利用跨层结构、膨胀卷积、全分辨率语义特征图的算法;针对尺度变化多样的问题,研究人员提出了基于多尺度信息的算法,包括利用共享结构、层级结构、并行结构再进行多尺度特征融合和利用自适应学习多尺度特征的算法;针对空间相关性强的问题,研究人员提出了基于空间上下文的算法,包括利用多维循环神经网络、概率图模型和注意力机制的算法.
3) 近年来基于深度学习的场景分割算法的性能取得了极大的提升,例如在Cityscapes数据集[53]上的mIoU从57.0%[16]提升至82.1%[57].
基于深度学习的算法虽然已经成为场景分割的主流方法,但仍然面临着诸多困难和挑战.除上述场景分割问题本身带来的困难和挑战外,还存在4个更具挑战性的场景分割问题:
1) 基于快速和轻量级模型的场景分割.为达到较高的分割精度,目前的场景分割算法倾向于使用较大较深的神经网络结构,导致计算复杂度高、分割速度慢.同时较大较深的神经网络包含较多的参数,增加了场景分割模型的存储开销.计算复杂度高的问题限制了场景分割算法在自动驾驶、视频监控等场景中的应用,而存储开销大的问题限制了场景分割算法在移动平台的使用.因此,设计快速且轻量级的场景分割模型具有极大的实际应用价值.如何对场景分割算法进行模型压缩、优化和加速具有重要的研究意义且极具挑战性.
2) 基于弱监督的场景分割.由于场景分割问题需要对场景图像中的每个像素判断类别,全监督的场景分割算法需要依赖大量像素级的人工标注,因此场景分割数据集的建立需要大量的人力物力.同时,现有的场景分割数据集的图像和类别数目有限,制约了场景分割算法的进一步发展.因此,如果利用图像的弱标签信息,如目标框级别、图像级别的标注训练场景分割模型,可以大大降低人工标注的成本.但利用弱监督信息会大幅度降低场景分割模型的精度.因此,基于弱监督的场景分割具有重要的研究意义,也更加具有挑战性.
3) 基于深度信息的场景分割.现有的大部分场景分割算法主要利用了场景图像的RGB信息.但在数据采集时,可以通过Kinect等基于红外的设备获同时取场景的深度信息,并利用RGBD信息设计场景分割算法.场景的深度信息相比图像信息具有较大差异,并在分割空间距离较大的视觉要素时具有独特的优势,例如可以更好地对前景和背景的边缘进行分割.因此可以利用深度信息对图像信息进行补充,对提高场景分割精度具有重要帮助.
4) 基于时序上下文信息的场景分割.现有的大部分场景分割算法主要利用了静态的场景图像.而在视频监控、自动驾驶等实际应用场景中,可以获取场景图像的时序上下文信息.可以通过挖掘时序上下文信息中的时序连续性提升场景分割精度.同时时序上连续的场景图像也可以增加场景分割数据集的规模.因此,基于时序上下文信息的场景分割在实际应用中具有重要的研究价值.

我们的服务类型
公开课程
人工智能、大数据、嵌入式
内训课程
普通内训、定制内训
项目咨询
技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别)

