NLP经典论文:TextCNN 笔记
NLP经典论文:TextCNN 笔记
- 论文
- 介绍
- 模型结构
-
- 整体模型
-
- 输入
- 输出
- 整体流程
- 流程维度
- 输入层
-
- 输入
- 输出
- 卷积层和ReLu激活
-
- 输入
- 输出
- 过程
- max pooling池化层
-
- 输入
- 输出
- 全连接dropout层与softmax层
-
- 输入
- 输出
- 过程
-
- 训练过程
-
- 优化目标
- 预测过程
- 文章部分翻译
-
- Abstract
- 2 Model
-
- 2.1 Regularization
- 3 Datasets and Experimental Setup
-
- 3.1 Hyperparameters and Training
- 3.2 Pre-trainedWord Vectors
- 3.3 Model Variations
- 相关的笔记
- 相关代码
-
- pytorch
- tensorflow
-
- keras
论文
NLP论文笔记合集(持续更新)
原论文:《Convolutional Neural Networks for Sentence Classification》
TextCNN调参指导:《A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification》
介绍
2014/08/25发表的文章,使用卷积神经网络(CNN)在单词向量上进行训练,单词向量由静态的预训练向量和动态的应用于特定任务的向量组成,用于句子级分类任务。
模型结构
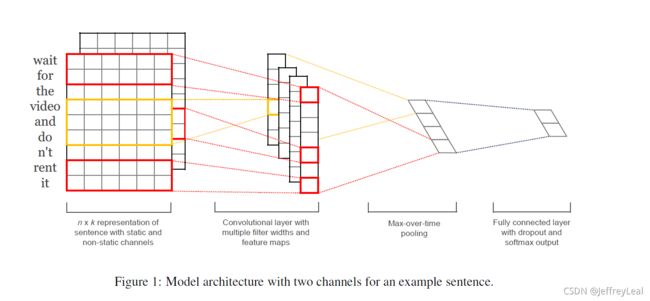
整体模型
输入
n个词 w 1 , w 2 , w 3 , . . . , w n w_1, w_2, w_3, ..., w_n w1,w2,w3,...,wn
输出
label,预测的类别
整体流程
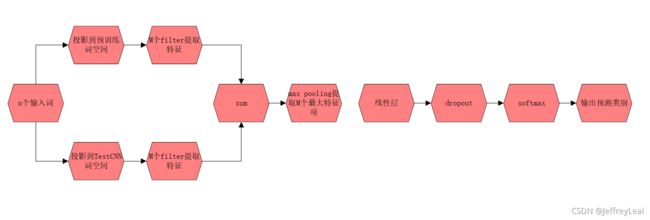
流程维度
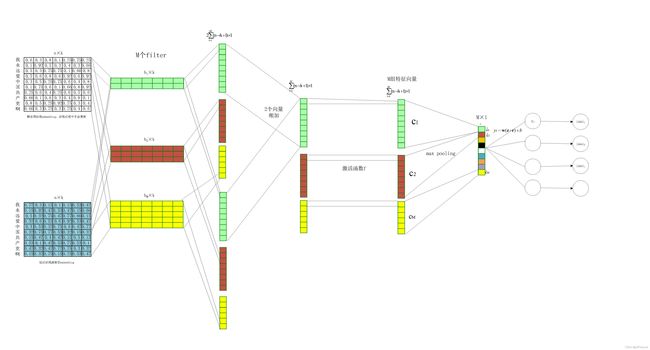
输入层

输入
w 1 , w 2 , w 3 , . . . , w n w_1, w_2, w_3, ..., w_n w1,w2,w3,...,wn为n个词,one-hot表示, w ∈ R V × 1 w \in R^{V \times 1} w∈RV×1,V为字典大小,包含词的总数。
输出
( x 1 , x 2 , x 3 , . . . , x n ) (\boldsymbol{x}_1, \boldsymbol{x}_2 , \boldsymbol{x}_3,..., \boldsymbol{x}_n) (x1,x2,x3,...,xn)和 ( x 1 ′ , x 2 ′ , x 3 ′ , . . . , x n ′ ) (\boldsymbol{x}_1\prime, \boldsymbol{x}_2\prime , \boldsymbol{x}_3\prime,..., \boldsymbol{x}_n\prime) (x1′,x2′,x3′,...,xn′), x 、 x ′ ∈ R k × 1 , x ∈ W , x ′ ∈ W ′ , W 、 W ′ ∈ R k × V \boldsymbol{x} 、\boldsymbol{x}\prime\in R^{k\times 1}, \boldsymbol{x} \in \boldsymbol{W}, \boldsymbol{x}\prime \in \boldsymbol{W}\prime, \boldsymbol{W}、\boldsymbol{W}\prime \in R^{k\times V} x、x′∈Rk×1,x∈W,x′∈W′,W、W′∈Rk×V
分别为动态训练字典 W \boldsymbol{W} W和静态预训练字典 W ′ \boldsymbol{W}\prime W′对应的embedding vector,将词映射到低维的稠密空间。
卷积层和ReLu激活

输入
( x 1 , x 2 , x 3 , . . . , x n ) (\boldsymbol{x}_1, \boldsymbol{x}_2 , \boldsymbol{x}_3,..., \boldsymbol{x}_n) (x1,x2,x3,...,xn)和 ( x 1 ′ , x 2 ′ , x 3 ′ , . . . , x n ′ ) (\boldsymbol{x}_1\prime, \boldsymbol{x}_2\prime , \boldsymbol{x}_3\prime,..., \boldsymbol{x}_n\prime) (x1′,x2′,x3′,...,xn′)
输出
( c 1 , c 2 , c 3 , . . . , c i , . . . , c m ) (\boldsymbol{c}_1, \boldsymbol{c}_2 , \boldsymbol{c}_3, ..., \boldsymbol{c}_i,..., \boldsymbol{c}_m) (c1,c2,c3,...,ci,...,cm),m为滤波器个数
过程
x 1 : n = x 1 ⊕ x 2 ⊕ . . . ⊕ x n \boldsymbol{x}_{1:n} = \boldsymbol{x}_1 \oplus \boldsymbol{x}_2 \oplus . . . \oplus \boldsymbol{x}_n x1:n=x1⊕x2⊕...⊕xn, ⊕ \oplus ⊕为拼接操作
x 1 : n ′ = x 1 ′ ⊕ x 2 ′ ⊕ . . . ⊕ x n ′ \boldsymbol{x}_{1:n}\prime = \boldsymbol{x}_1\prime \oplus \boldsymbol{x}_2\prime \oplus . . . \oplus \boldsymbol{x}_n\prime x1:n′=x1′⊕x2′⊕...⊕xn′
有M个滤波器,每个滤波器的窗口长度可以不一样,一个窗口长度为h的滤波器经过滑动可以将句子 x 1 : n \boldsymbol{x}_{1:n} x1:n和 x 1 : n ′ \boldsymbol{x}_{1:n}\prime x1:n′分为 { x 1 : h , x 2 : h + 1 , . . . , x i : i + h − 1 , … , x n − h + 1 : n } \{\boldsymbol{x}_{1:h}, \boldsymbol{x}_{2:h+1}, ..., \boldsymbol{x}_{i:i+h-1}, …, \boldsymbol{x}_{n-h+1:n}\} {x1:h,x2:h+1,...,xi:i+h−1,…,xn−h+1:n}和 { x 1 : h ′ , x 2 : h + 1 ′ , . . . , x i : i + h − 1 ′ , … , x n − h + 1 : n ′ } \{\boldsymbol{x}_{1:h}\prime, \boldsymbol{x}_{2:h+1}\prime, ..., \boldsymbol{x}_{i:i+h-1}\prime, …, \boldsymbol{x}_{n-h+1:n}\prime\} {x1:h′,x2:h+1′,...,xi:i+h−1′,…,xn−h+1:n′},对其中的窗口 x i : i + h − 1 \boldsymbol{x}_{i:i+h-1} xi:i+h−1和 x i : i + h − 1 ′ \boldsymbol{x}_{i:i+h-1}\prime xi:i+h−1′卷积再激活,可以得到
c i = f ( w ⋅ x i : i + h − 1 + w ⋅ x i : i + h − 1 ′ + b ) c_i =f(\boldsymbol{w} \cdot \boldsymbol{x}_{i:i+h-1} +\boldsymbol{w} \cdot \boldsymbol{x}_{i:i+h-1}\prime+ b) ci=f(w⋅xi:i+h−1+w⋅xi:i+h−1′+b)
滑动卷积窗口再激活,可以得到
c i = [ c 1 , c 2 , . . . , c i , . . . , c n − h + 1 ] \boldsymbol{c}_i= [c_1, c_2, ..., c_i,. . . , c_{n−h+1}] ci=[c1,c2,...,ci,...,cn−h+1]
这是一个滤波器的feature mapping,m个滤波器则有:
( c 1 , c 2 , c 3 , . . . , c i , . . . , c m ) (\boldsymbol{c}_1, \boldsymbol{c}_2 , \boldsymbol{c}_3, ..., \boldsymbol{c}_i,..., \boldsymbol{c}_m) (c1,c2,c3,...,ci,...,cm)
max pooling池化层

输入
( c 1 , c 2 , c 3 , . . . , c i , . . . , c m ) (\boldsymbol{c}_1, \boldsymbol{c}_2 , \boldsymbol{c}_3, ..., \boldsymbol{c}_i,..., \boldsymbol{c}_m) (c1,c2,c3,...,ci,...,cm),m为滤波器个数
输出
z = [ c ^ 1 , . . . , c ^ i , … , c ^ m ] \boldsymbol{z}=[\hat{c}_1, ..., \hat{c}_i,…, \hat{c}_m] z=[c^1,...,c^i,…,c^m]
其中, c ^ i = max { c i } , c i \hat{c}_i=\max \{\boldsymbol{c}_i\}, \boldsymbol{c}_i c^i=max{ci},ci为一个滤波器的feature mapping
全连接dropout层与softmax层
输入
z = [ c ^ 1 , . . . , c ^ i , … , c ^ m ] \boldsymbol{z}=[\hat{c}_1, ..., \hat{c}_i,…, \hat{c}_m] z=[c^1,...,c^i,…,c^m]
输出
label,预测的类别
过程
训练过程
伯努利随机变量,以概率为p生成1,否则就是0, r ∈ R m \boldsymbol{r} \in R^m r∈Rm是伯努利随机变量构成的包含(0,1)的“masking”向量,用于对池化层的部分输入进行‘masking’,全连接层的每一个单元的输出为:
y i = w i ⋅ ( z ∘ r ) + b y_i=\boldsymbol{w}_i \cdot (\boldsymbol{z} \circ \boldsymbol{r})+ b yi=wi⋅(z∘r)+b
y i y_i yi为 l a b e l i label_i labeli对应的预测分值, w i \boldsymbol{w_i} wi为全连接层的权重, y i y_i yi经过softmax层后
p ( l a b e l i ∣ w 1 , w 2 , . . . , w n ) = e x p ( y i ) ∑ l a b e l j ∈ l a b e l e x p ( y j ) p(label_i|w_1, w_2, ..., w_n)=\frac{exp(y_i)}{\sum\limits_{label_j \in label}exp(y_j)} p(labeli∣w1,w2,...,wn)=labelj∈label∑exp(yj)exp(yi)
权重向量使用 l 2 l_2 l2范数进行约束,在梯度下降步骤后, ∥ w ∥ 2 > s \parallel \boldsymbol{w}\parallel_2 >s ∥w∥2>s时,重新缩放 w \boldsymbol{w} w使 ∥ w ∥ 2 = s \parallel \boldsymbol{w}\parallel_2 =s ∥w∥2=s来约束权重向量的 l 2 l_2 l2范数。
优化目标
对于一个文本为 w 1 , w 2 , w 3 , . . . , w n w_1, w_2, w_3, ..., w_n w1,w2,w3,...,wn,标签值为label的样本来说:
l o s s = − log p ( l a b e l ∣ w 1 , w 2 , . . . , w n ) loss=-\log p(label|w_1, w_2, ..., w_n) loss=−logp(label∣w1,w2,...,wn)
预测过程
不再对池化层的部分输入进行‘masking’,全连接层的每一个单元的输出为:
y i = p w i ⋅ z + b y_i = p\boldsymbol{w}_i \cdot \boldsymbol{z} + b yi=pwi⋅z+b
其中p为dropout率, y i y_i yi经过softmax层后
p ( l a b e l i ∣ w 1 , w 2 , . . . , w n ) = e x p ( y i ) ∑ l a b e l j ∈ l a b e l e x p ( y j ) p(label_i|w_1, w_2, ..., w_n)=\frac{exp(y_i)}{\sum\limits_{label_j \in label}exp(y_j)} p(labeli∣w1,w2,...,wn)=labelj∈label∑exp(yj)exp(yi)
文章部分翻译
Abstract
我们报告了一系列的实验,使用卷积神经网络(CNN)在预先训练的单词向量上进行训练,用于句子级分类任务。我们证明了一个简单的CNN,具有很少的超参数调整和静态向量,在多个基准测试中取得了很好的结果。通过微调学习特定于任务的向量可以进一步提高性能。此外,我们还建议对体系结构进行简单的修改,以允许使用应用于特定任务的向量和静态向量。本文讨论的CNN模型改进了7项任务中的4项,包括情绪分析和问题分类。
2 Model
图1所示的模型架构是Collobert等人(2011年)CNN架构的一个轻微变体。设 x i ∈ R k \boldsymbol{x}_i \in R^k xi∈Rk为k维单词向量,对应于句子中的第i个单词。长度为n的句子(必要时填充)表示为
x 1 : n = x 1 ⊕ x 2 ⊕ . . . ⊕ x n , \boldsymbol{x}_{1:n} = \boldsymbol{x}_1 \oplus \boldsymbol{x}_2 \oplus . . . \oplus \boldsymbol{x}_n, x1:n=x1⊕x2⊕...⊕xn,
其中 ⊕ \oplus ⊕是拼接运算符。通常,让 x i : i + j \boldsymbol{x}_{i:i+j} xi:i+j表示词串 x i , x i + 1 , . . . x i + j \boldsymbol{x}_i, \boldsymbol{x}_{i+1}, . . . \boldsymbol{x}_{i+j} xi,xi+1,...xi+j的向量拼接。卷积运算使用一个滤波器 w ∈ R h k \boldsymbol{w} \in R^{hk} w∈Rhk,它使用一个长为h的词窗口来产生一个新的特征。例如,特征 c i c_i ci是词窗口 x i : i + j \boldsymbol{x}_{i:i+j} xi:i+j通过下式生成的:
c i = f ( w ⋅ x i : i + h − 1 + b ) . ( 2 ) c_i = f(\boldsymbol{w} \cdot \boldsymbol{x}_{i:i+h-1} + b). \quad\quad\quad\quad\quad (2) ci=f(w⋅xi:i+h−1+b).(2)
这里是 b ∈ R b\in R b∈R是一个偏差项, f f f是一个非线性函数,如双曲正切。该过滤器应用于句子 { x 1 : h , x 2 : h + 1 , … , x n − h + 1 : n } \{\boldsymbol{x}_{1:h}, \boldsymbol{x}_{2:h+1}, …, \boldsymbol{x}_{n-h+1:n}\} {x1:h,x2:h+1,…,xn−h+1:n}中的每个可能的词窗口,以生成特征映射
c = [ c 1 , c 2 , . . . , c n − h + 1 ] , \boldsymbol{c}= [c_1, c_2, . . . , c_{n−h+1}], c=[c1,c2,...,cn−h+1],
其中 c ∈ R n − h + 1 \boldsymbol{c} \in R^{n-h+1} c∈Rn−h+1。然后,我们在特征映射上应用max-over-time-pooling操作(Collobert et al., 2011) ,并将最大值 c ^ = max { c } \hat{c}=\max\{\boldsymbol{c}\} c^=max{c}作为与该特定过滤器对应的特征。其思想是捕获最重要的特征——拥有最大特征值的特征——对于每一个特征映射。这种合并方案自然处理可变的句子长度。
我们描述了从一个滤波器中提取一个特征的过程。该模型使用多个过滤器(具有不同的窗口大小)来获取多个特征。这些特征形成倒数第二层,并传递给完全连接的softmax层,该层的输出是标签上的概率分布。
在其中一个模型变体中,我们尝试使用两个词向量“通道”,一个在整个训练过程中保持静态,另一个通过反向传播进行微调(第3.2节)。在图1所示的多通道结构中,每个滤波器应用于两个通道,并将结果相加以计算等式(2)中的 c i c_i ci。该模型在其他方面等同于单通道体系结构。
2.1 Regularization
对于正则化,我们在倒数第二层上使用dropout,并对权重向量 w \boldsymbol{w} w的 l 2 l_2 l2范数进行约束(Hinton等人,2012)。在正向反向传播过程中,通过随机dropout一定比例p——例如,设置为零——的隐藏单元,dropout可防止隐藏单元的协同适应。也就是说,给定倒数第二层 z = [ c ^ 1 , … , c ^ m ] \boldsymbol{z}=[\hat{c}_1,…,\hat{c}_m] z=[c^1,…,c^m](注意,这里我们有m个滤波器),不将
y = w ⋅ z + b y = \boldsymbol{w} \cdot \boldsymbol{z} + b y=w⋅z+b
应用于正向传播中输出单元y,dropout使用
y = w ⋅ ( z ∘ r ) + b , y=\boldsymbol{w} \cdot (\boldsymbol{z} \circ \boldsymbol{r})+ b, y=w⋅(z∘r)+b,
其中 ∘ \circ ∘是与元素等长的乘法运算符, r ∈ R m \boldsymbol{r} \in R^m r∈Rm是伯努利随机变量构成的“masking”向量,伯努利随机变量以概率p为生成1。梯度仅通过“unmasked”单元反向传播。在测试时,经过训练权重向量按比例因子p进行缩放,以使 w ^ = p w \hat{\boldsymbol{w}}=p\boldsymbol{w} w^=pw,并使用 w ^ \hat{\boldsymbol{w}} w^(无dropout)对没见过的句子进行评分。此外,我们还通过在梯度下降步骤后, ∥ w ∥ 2 > s \parallel \boldsymbol{w}\parallel_2 >s ∥w∥2>s时,重新缩放 w \boldsymbol{w} w使 ∥ w ∥ 2 = s \parallel \boldsymbol{w}\parallel_2 =s ∥w∥2=s来约束权重向量的 l 2 l_2 l2范数。
3 Datasets and Experimental Setup
我们在各种基准上测试我们的模型。数据集的汇总统计数据见表1。
•MR:电影评论,每次重映一句话。分类涉及检测积极/消极评论(Pang和Lee,2005)
•SST-1:斯坦福情感树库是MR的一个扩展,但提供了训练/开发/测试拆分和细粒度标签(非常积极、积极、中立、消极、非常消极),由Socher等人(2013)重新标记。4
•SST-2:与SST-1相同,但删除了中性重新视图和二进制标签。
•Subj:主观性数据集,任务是将句子分类为主观性或客观性(Pang和Lee,2004)。
•TREC:TREC问题数据集任务卷,将问题分为6种问题类型(问题是否与人、位置、数字信息等有关)(Li和Roth,2002年)。5
•CR:客户对各种产品(照相机、MP3等)的评论。任务是预测正面/负面评论(胡和刘,2004)
MPQA:MPQA数据集的意见极性检测子任务(Wiebe等人,2005年)。7
3.1 Hyperparameters and Training
对于我们使用的所有数据集:ReLu,过滤窗口(h)为3、4、5,每个窗口有100个特征映射,dropout率(p)为0.5, l 2 l_2 l2约束为3,最小批量大小为50。这些值是通过SST-2验证集上的网格搜索选择的。
除了在开发集上提前停止之外,我们不会执行任何特定于数据集的调优。对于没有标准开发集的数据集,我们随机选择10%的培训数据作为开发集。使用Adadelta更新规则,通过随机梯度下降法对洗牌小批量进行训练(Zeiler,2012)
3.2 Pre-trainedWord Vectors
使用从无监督神经语言模型获得的词向量初始化词向量是在缺乏大型监督训练集的情况下提高性能的常用方法(Collobert et al.,2011;Socher et al.,2011;Iyyer et al.,2014)。我们使用公开可用的word2vec向量,这些向量是根据谷歌新闻1000亿字进行训练的。向量的维数为300,并使用连续词袋结构进行训练(Mikolov等人,2013年)。预先训练的单词集中不存在的单词将随机初始化。
3.3 Model Variations
我们对模型的几个变体进行了实验。
•CNN rand:我们的基线模型,其中所有单词都随机初始化,然后在训练期间进行修改。
•CNN静态:带有word2vec预先训练向量的模型。所有单词,包括初始化运行的未知单词,都保持静态,只学习模型的其他参数。
•CNN非静态:与上述相同,但预训练向量针对每个任务进行微调。
•CNN多频道:具有两组字向量的模型。每组向量被视为一个“通道”,并应用每个滤波器
为了理清上述变化对其他随机因素的影响,我们消除了随机性的其他来源CV折叠分配、未知词向量的初始化、CNN参数的初始化,使它们在每个数据集中保持一致。
相关的笔记
论文《Convolutional Neural Networks for Sentence Classification》总结
Convolutional Neural Networks for Sentence Classification论文解读
深度学习:文本CNN-textcnn
相关代码
pytorch
https://github.com/649453932/Chinese-Text-Classification-Pytorch
https://github.com/Cheneng/TextCNN
tensorflow
https://github.com/brightmart/text_classification
https://github.com/norybaby/sentiment_analysis_textcnn
https://github.com/XqFeng-Josie/TextCNN
keras
https://github.com/yongzhuo/Keras-TextClassification
https://github.com/ShawnyXiao/TextClassification-Keras