关系抽取--CASREL
关系抽取–CASREL
关系抽取是自然语言处理中的一个基本任务。关系抽取通常用三元组(subject, relation, object)表示。解决关系抽取的思路有两种:
(1)已知两个实体subject和object,采用分类模型得到实体间的关系
(2)抽取实体,预测实体间可能存在的关系。如果采用先抽取实体再用预测关系,这种方式称为pipline式抽取;如果同时抽取实体和实体间的关系,这种方式称为联合抽取。
关系抽取的数据集比较复杂,数据集中的实体和关系有重叠,理想的关系抽取的数据集中subject和object对应一种关系,现实中的数据集中subject和object对应多种关系,出现实体重叠的现象。如下图:

其中EPO表示实体重复,SPO表示单实体重复。
当关系三元组(subject, relation, object)重叠时,关系分类模型很难处理重叠数据。 如果没有足够的训练示例,分类器就很难说出实体参与哪个关系,提取的三元组通常是不完整且不准确的。然而CASREL模型可以有效的处理重叠关系三元组。
CASREL模型
novel cascade binary tagging framework(CASREL)模型是A Novel Cascade Binary Tagging Framework for Relational Triple Extraction提出的,CASREL模型刷新了SOTA的结果。CASREL模型分为两步骤:
(1)通过预训练BERT模型得到所有可能的subject
(2)针对每个subject,我们应用特定于关系的标记器来同时识别所有可能的关系和相应的object。
抽取关系三元组的目的是识别句子中所有可能的(subject,relation,object),其中某些关系可能与共享相同的subject或object实体。所以CASREL的目标函数表示为:

CASREL模型结构如下图

Subject Tagger
Subject Tagger中的模型是通过直接解码N层BERT编码器产生的编码向量hN来识别输入句子中的所有可能subject,其实采用两个相同的二分类器(0/1)来标记subject的开始和结束位置,公式如下:
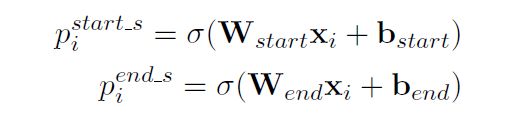
给定一个句子中subject的最大似然函数为:

Relation-specific Object Taggers
Relation-specific object taggers考虑了subject的特征,而不是直接解码预训练bert模型的HN,relation-specific object taggers的公式如下:

Relation-specific object taggers的最大似然函数为

中文实验结果
在中文数据上和英文的数据集的tokenizer处理方式基本一样,每一个汉字后加入了[unused1],采用chinese_L-12_H-768_A-12预训练模型。中文数据集处理的格式如下:
{
"text": "如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困潦倒之中的独门秘笈",
"triple_list": [
[
"喜剧之王",
"主演",
"周星驰"
]
]
}
模型参数如下:
max_length=128, batch_size=16, lr=1e-5, epoch=16
模型的评价结果如下:
f1: 0.7827, precision: 0.7736, recall: 0.7921, best f1: 0.7944
模型的预测结果如下:
{
"text": "《爱的魔幻秀》是安心亚演唱的歌曲,由吴易伟作词,MartinHansen/StefanDouglasHayOsson作曲,收录于专辑《单身极品》中",
"triple_list_gold": [
{
"subject": "爱的魔幻秀",
"relation": "所属专辑",
"object": "单身极品"
},
{
"subject": "爱的魔幻秀",
"relation": "歌手",
"object": "安心亚"
}
],
"triple_list_pred": [
{
"subject": "爱的魔幻秀",
"relation": "所属专辑",
"object": "单身极品"
},
{
"subject": "爱的魔幻秀",
"relation": "歌手",
"object": "安心亚"
},
{
"subject": "爱的魔幻秀",
"relation": "作词",
"object": "吴易伟"
}
],
"new": [
{
"subject": "爱的魔幻秀",
"relation": "作词",
"object": "吴易伟"
}
]
}
如果有错误,欢迎大家指正。