【论文】Convolutional Two-Stream Network Fusion for Video Action Recognition
Convolutional Two-Stream Network Fusion for Video Action Recognition
- 双流网络的不足
- 空间融合
-
- 融合方式
- 融合位置
- 时间融合
-
- 3D Conv和3D Pooling
- 网络架构
-
- 融合
- 输入
双流网络的不足
CNN在别的领域已经取得了巨大的成功,但在动作识别领域却不尽人意,作者认为该领域在当时存在两个问题:
(1)数据集太小。动作识别中除了图像信息还包含运动和视角各种信息,需要的数据量应该要超过图像分类才对。然而现实是图像分类数据集imagenet每个类别的1000个样例,而ucf101每个类别只有100个样例。
(2)当时提出的CNN架构都不能充分利用时间维度的信息。
当时最好的双流CNN,也存在(2)这个问题,作者具体说了两点:
(1)双流网络无法学习到时间特征和空间特征的像素间的关系。我的理解是空间特征可以学习到物体是什么,例如手臂、躯干、腿… 时间特征可以学习到物体在做什么运动,例如挥动、平移、旋转… 而手臂挥动和腿挥动明显是不同的动作,躯干平移和躯干旋转也是不同的动作。换言之,将空间特征和时间特征结合起来考虑,能为动作识别提供更多线索,也就有希望提升网络的表现。
(2)双流网络对时间维度的利用很有限,空间网络只用了一帧,时间网络只用了10帧。
针对这两个问题,作者对应地提出两种解决方法
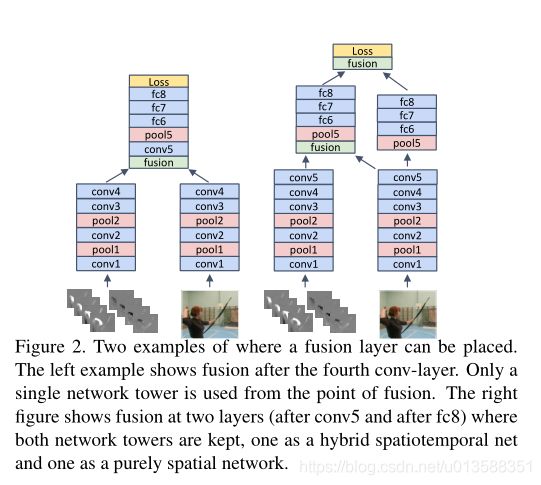
(1)空间融合:在隐藏层中间对两个网络进行融合(Figure 2),并且提出了多种融合方式;
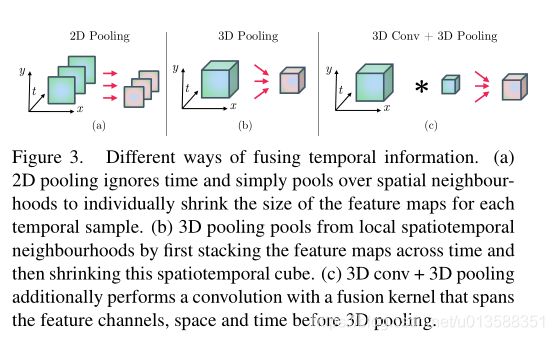
(2)时间融合:提出用Conv3D和Pool3D提取时间维度的特征,在时间维度上进行“融合”(Figure 3)。
空间融合
融合方式
融合层有两个输入,一个输出。 x t a ∈ R H × W × D x_t^a \in R^{H\times W\times D} xta∈RH×W×D 代表空间网络的输入, x t b ∈ R H × W × D x_t^b \in R^{H\times W\times D} xtb∈RH×W×D 代表时间网络的输入, y y y 代表融合层的输出。
| 融合方式 | 数学表达式 | 维度 | 增加参数 |
|---|---|---|---|
| Sum fusion | y s u m = x t a + x t b y^{sum} = x_t^a + x_t^b ysum=xta+xtb | y s u m ∈ R H × W × D y^{sum} \in R^{H\times W\times D} ysum∈RH×W×D | 无 |
| Max fusion | y m a x = m a x ( x t a , x t b ) y^{max} = max(x_t^a, x_t^b) ymax=max(xta,xtb) | y m a x ∈ R H × W × D y^{max} \in R^{H\times W\times D} ymax∈RH×W×D | 无 |
| Concat fusion | y c a t = c a t ( 3 , x t a , x t b ) y^{cat} = cat(3, x_t^a, x_t^b) ycat=cat(3,xta,xtb) | y c a t ∈ R H × W × 2 D y^{cat} \in R^{H\times W\times 2D} ycat∈RH×W×2D | 后面的全连接层 |
| Conv fusion | y c o n v = y c a t ∗ f + b y^{conv} = y^{cat} * f + b yconv=ycat∗f+b | f ∈ R 1 × 1 × 2 D × D , b ∈ R D y c o n v ∈ R H × W × D f \in R^{1\times 1\times 2D \times D}, b\in R^{D}\\ y^{conv} \in R^{H\times W\times D} f∈R1×1×2D×D,b∈RDyconv∈RH×W×D | f 和 b f和b f和b |
| Biliner fusion | y b i l = ∑ j = 1 H ∑ i = 1 M x i , j a ⊗ x i , j b y^{bil} = \sum_{j=1}^H\sum_{i=1}^M x_{i,j}^a \otimes x_{i,j}^b ybil=j=1∑Hi=1∑Mxi,ja⊗xi,jb | y b i l ∈ R D × D y^{bil} \in R^{D\times D} ybil∈RD×D | 用SVM替代全连接分类,反而减少了参数 |
cat用来拼接矩阵, ∗ * ∗ 代表卷积操作, ⊗ \otimes ⊗ 代表矩阵外积。
不同融合方式的效果如下表:

融合位置

卷积融合在不同层融合的性能比较:
(1)早融合:在relu5之前融合,效果不佳
(2)早融合加多融合:效果不佳
(3)晚融合(relu5)和多融合(relu5+fc8)效果最好,但是多融合训练参数多一倍
时间融合
3D Conv和3D Pooling
通过将2D卷积和2D池化拓展到3D卷积和3D池化,可以提取到时间维度的特征。

在concat融合层之后添加3D Conv和3D Pooling,性能略有提升。
网络架构
融合
我按照文章和代码对架构的描述,把上面的Figure 1修改了,融合后的架构图如下所示(见Netscope示意图):

添加了一个concat融合层,一个Conv3D层。用两个Pool3D层替换了原来2D的pool5。这是本文提出的最终架构,相比原来的双流架构,增加的参数只有Conv3D中的少量参数,但通过融合的方式大大的提升了网络性能。
输入
假设现在正在计算第i个batch的输入:
i i i 代表当前在计算第i个batch
n F r a m e s = o p t s . n F r a m e s ( i ) nFrames=opts.nFrames(i) nFrames=opts.nFrames(i) 代表第i个视频总共的帧数
n S t a c k = o p t s . i m a g e S i z e ( 3 ) = 20 nStack=opts.imageSize(3) = 20 nStack=opts.imageSize(3)=20 代表输入图像尺寸的第三维,也就是20
时间网络的输入由几个参数决定:
L = n S t a c k / 2 = 10 L=nStack/2 = 10 L=nStack/2=10
T = o p t s . n F r a m e s P e r V i d T = opts.nFramesPerVid T=opts.nFramesPerVid 代表采样点的个数
τ = o p t s . t e m p o r a l S t r i d e τ = opts.temporalStride τ=opts.temporalStride 代表采样的时间间隔
o p t s . f r a m e S a m p l e opts.frameSample opts.frameSample 代表采样方法,可以取值uniformly, temporalStride, random, temporalStrideRandom
获取时间网络的输入可以分为以下几个步骤:
- 按特定的采样方法,得到采样点数组
frameSamples(数组长度可能大于T)uniformly均匀采样
在 [ L / 2 + 1 , n F r a m e s − L / 2 ] [L/2+1, nFrames-L/2] [L/2+1,nFrames−L/2] 区间均匀采样 T T T 个点。这种采样方法不需要设置 τ τ τ。
例:
L = 10 , n F r a m e s = 154 , T = 5 L = 10, nFrames = 154, T = 5 L=10,nFrames=154,T=5
输出 [ 6 , 42 , 78 , 113 , 149 ] [6,42,78,113,149] [6,42,78,113,149]temporalStride时间定长间隔采样
在 [ L / 2 + 1 , n F r a m e s − L / 2 ] [L/2+1, nFrames-L/2] [L/2+1,nFrames−L/2] 区间按 τ τ τ 步长采样。
例:
L = 10 , n F r a m e s = 82 , τ = 5 L = 10, nFrames = 82, τ = 5 L=10,nFrames=82,τ=5
输出 [ 6 , 11 , 16 , 21 , 26 , 31 , 36 , 41 , 46 , 51 , 56 , 61 , 66 , 71 , 76 ] [6,11,16,21,26,31,36,41,46,51,56,61,66,71,76] [6,11,16,21,26,31,36,41,46,51,56,61,66,71,76]random完全随机采样
生成 [ L / 2 + 1 , n F r a m e s − L / 2 ] [L/2+1, nFrames-L/2] [L/2+1,nFrames−L/2] 区间的随机排列。这种采样方法也不需要设置 τ τ τ。
例:
L = 10 , n F r a m e s = 30 L = 10, nFrames = 30 L=10,nFrames=30
输出 [ 6 , 13 , 18 , 8 , 22 , 15 , 11 , 9 , 19 , 17 , 20 , 14 , 10 , 12 , 25 , 24 , 7 , 21 , 23 , 16 ] [6,13,18,8,22,15,11,9,19,17,20,14,10,12,25,24,7,21,23,16] [6,13,18,8,22,15,11,9,19,17,20,14,10,12,25,24,7,21,23,16]temporalStrideRandom时间随机间隔采样
在 [ L / 2 + 1 , n F r a m e s − L / 2 ] [L/2+1, nFrames-L/2] [L/2+1,nFrames−L/2] 区间按随机步长采样,通过temporalStride设置随机步长取值范围(5:15)。

例:
L = 10 , n F r a m e s = 116 , τ = 13 ( 从 5 到 15 随 机 ) L = 10, nFrames = 116, τ = 13(从5到15随机) L=10,nFrames=116,τ=13(从5到15随机)
输出 [ 6 , 19 , 32 , 45 , 58 , 71 , 84 , 97 , 110 ] [6,19,32,45,58,71,84,97,110] [6,19,32,45,58,71,84,97,110]
- 将
frameSamples的长度设置为 T T T ,如果小于T就补充一些采样点,大于T就随机取连续的T个
例:
输入 [ 6 , 19 , 32 , 45 , 58 , 71 , 84 , 97 , 110 ] , T = 5 [6,19,32,45,58,71,84,97,110], T = 5 [6,19,32,45,58,71,84,97,110],T=5
输出 [ 32 , 45 , 58 , 71 , 84 ] [32,45,58,71,84] [32,45,58,71,84] - 将
frameSamples维度扩充为 L × T L\times T L×T
例:
输入 [ 32 , 45 , 58 , 71 , 84 ] , L = 10 , T = 5 [32,45,58,71,84], L=10, T=5 [32,45,58,71,84],L=10,T=5
输出

最终得到的输入的维度是 [ 224 , 224 , 23 , b a t c h S i z e , T ] [224, 224, 23, batchSize, T] [224,224,23,batchSize,T],每个视频采样T个点,每个时间点附近取20张光流图像堆叠+3张RGB图像:

注:后面还有数据扩充还没看,最后输入的维度应该是 [ 224 , 224 , 23 , b a t c h S i z e , a u g m e n t ∗ T ] [224, 224, 23, batchSize, augment*T] [224,224,23,batchSize,augment∗T]
通过实验,作者得出三个结论:
(1)相比在最后的Softmax层融合,在中间的卷积层融合既能够提升性能,又不会增加太多参数(见融合方式)
(2)在最后一个卷积层融合(relu5)的性能是最好的,如果再配合最后一个全连接层融合(fc8),性能还能再提升一点(见融合位置)
(3)在融合后使用pool3d代替代替pool2d能更进一步地提高性能(见3D Conv和3D Pooling)