【动手学深度学习v2】注意力机制—1 注意力评分函数
注意力评分函数
- 单维注意力分数
- Attention Mechanisms
- 两种注意力评分函数
-
- 加性注意力 Additive Attention
- 缩放点积注意力 Scaled Dot-Product Attention
- 总结
- 参考
- 系列文章
单维注意力分数
f ( x ) = ∑ i = 1 n α ( x , x i ) y i = ∑ i = 1 n exp ( − 1 2 ( x − x i ) 2 ) ∑ j = 1 n exp ( − 1 2 ( x − x j ) 2 ) y i = ∑ i = 1 n s o f t m a x ( − 1 2 ( x − x i ) 2 ) y i . \begin{split}\begin{aligned} f(x) &=\sum_{i=1}^n \alpha(x, x_i) y_i \\ &= \sum_{i=1}^n \frac{\exp\left(-\frac{1}{2}(x - x_i)^2\right)}{\sum_{j=1}^n \exp\left(-\frac{1}{2}(x - x_j)^2\right)} y_i \\&= \sum_{i=1}^n \mathrm{softmax}\left(-\frac{1}{2}(x - x_i)^2\right) y_i. \end{aligned}\end{split} f(x)=i=1∑nα(x,xi)yi=i=1∑n∑j=1nexp(−21(x−xj)2)exp(−21(x−xi)2)yi=i=1∑nsoftmax(−21(x−xi)2)yi.
- α ( ) \alpha() α()是注意力权重(Attention Weight),属于(0,1);
- − 1 2 ( x − x i ) 2 -\frac{1}{2}(x - x_i)^2 −21(x−xi)2是注意力分数(Attention Score)。
Attention Mechanisms
(图从左至右)
- 有m个key-value pairs,有一个query;
- query和每一个key输入 α ( ) \alpha() α()生成注意力分数;
- 经过softmax,生成注意力权重;
- 和每个value做加权和,得到输出。
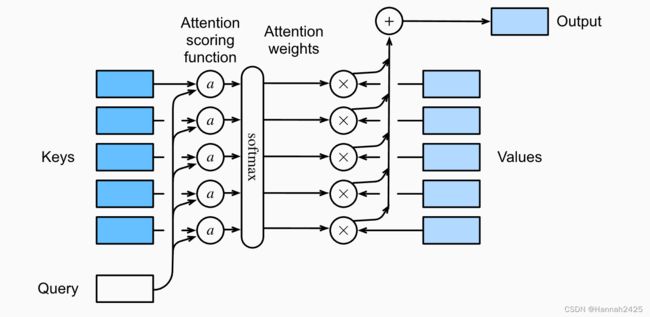
假设一个query q ∈ R q \mathbf{q} \in \mathbb{R}^q q∈Rq,和m个key-value pairs ( k 1 , v 1 ) , … , ( k m , v m ) (\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m) (k1,v1),…,(km,vm), k i ∈ R k , v i ∈ R v \mathbf{k}_i \in \mathbb{R}^k, \mathbf{v}_i \in \mathbb{R}^v ki∈Rk,vi∈Rv,注意力汇聚函数 f f f就被表示成值的加权和:
f ( q , ( k 1 , v 1 ) , … , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i ∈ R v , f(\mathbf{q}, (\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)) = \sum_{i=1}^m \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i \in \mathbb{R}^v, f(q,(k1,v1),…,(km,vm))=i=1∑mα(q,ki)vi∈Rv,
其中查询 q q q和键 k i k_i ki的注意力权重(标量) 是通过注意力评分函数 a a a将两个向量映射成标量, 再经过softmax运算得到的:
α ( q , k i ) = s o f t m a x ( a ( q , k i ) ) = exp ( a ( q , k i ) ) ∑ j = 1 m exp ( a ( q , k j ) ) ∈ R . \alpha(\mathbf{q}, \mathbf{k}_i) = \mathrm{softmax}(a(\mathbf{q}, \mathbf{k}_i)) = \frac{\exp(a(\mathbf{q}, \mathbf{k}_i))}{\sum_{j=1}^m \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}. α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))∈R.
不同的注意力评分函数会导致不同的注意力汇聚操作。
两种注意力评分函数
加性注意力 Additive Attention
给定key和query: k ∈ R k , q ∈ R q \mathbf k\in\mathbb R^{k},\mathbf q\in\mathbb R^{q} k∈Rk,q∈Rq;
可学习参数: W q ∈ R h × q , W k ∈ R h × k , v ∈ R h \mathbf W_q\in\mathbb R^{h\times q},\mathbf W_k\in\mathbb R^{h\times k},\mathbf v\in\mathbb R^{h} Wq∈Rh×q,Wk∈Rh×k,v∈Rh;
加性注意力分数函数additive attention scoring function: a ( q , k ) = v ⊤ tanh ( W q q + W k k ) ∈ R , a(\mathbf q, \mathbf k) = \mathbf v^\top \text{tanh}(\mathbf W_q\mathbf q + \mathbf W_k \mathbf k) \in \mathbb{R}, a(q,k)=v⊤tanh(Wqq+Wkk)∈R,
等价于,将query和key并在一起,丢进一个单隐藏层的MLP(hidden大小为h,output为1)。
好处:k,q,v可以是不一样长度。
缩放点积注意力 Scaled Dot-Product Attention
如果query和key都是同样长度, q , k i ∈ R d \mathbf q, \mathbf k_i \in\mathbb R^{d} q,ki∈Rd,直接 q q q和 k i k_i ki做内积,并除以根号 d d d,保证对于 k k k的长度 d d d不敏感。
缩放点积注意力 scaled dot-product attention scoring function: a ( q , k ) = q ⊤ k / d a(\mathbf q, \mathbf k) = \mathbf{q}^\top \mathbf{k} /\sqrt{d} a(q,k)=q⊤k/d
向量化版本
n个query: Q ∈ R n × d \mathbf Q\in\mathbb R^{n\times d} Q∈Rn×d;
m个key-value pairs: K ∈ R m × d , V ∈ R m × v \mathbf K\in\mathbb R^{m\times d},\mathbf V\in\mathbb R^{m\times v} K∈Rm×d,V∈Rm×v;
注意力分数: a ( Q , K ) = Q K ⊤ d ∈ R n × m a(\mathbf Q, \mathbf K) = \frac{\mathbf Q \mathbf K^\top }{\sqrt{d}} \in \mathbb{R}^{n\times m} a(Q,K)=dQK⊤∈Rn×m;
注意力池化: f = s o f t m a x ( a ( Q , K ) ) V ∈ R n × v f=\mathrm{softmax}\left(a(\mathbf Q, \mathbf K) \right) \mathbf V \in \mathbb{R}^{n\times v} f=softmax(a(Q,K))V∈Rn×v。
总结
- 注意力分数是query和key的相似度,没有被normalize;
- 注意力权重是softmax的结果;
- 加性注意力:将query和key合并,进入单输出单隐藏层的MLP;
- 缩放点积注意力:将query和key做内积。
参考
DIVE INTO DEEP LEARNING> 10 注意力机制 > 10.3. 注意力评分函数
65 注意力分数【动手学深度学习v2】
系列文章
【动手学深度学习v2】注意力机制—1 注意力评分函数
【动手学深度学习v2】注意力机制—2 使用注意力机制Seq2Seq
【动手学深度学习v2】注意力机制—3 自注意力&位置编码
【动手学深度学习v2】注意力机制—4 Transformer