【GNN图神经网络】邻接矩阵转化coo格式的稀疏矩阵
刚开始学习图神经网络,在使用PyG框架编程的时候,有一件事很让我纠结:PyG要求输入的邻接矩阵X应该是稀疏矩阵的形式(edge_index),而不是我制作的NxN邻接矩阵形式。
举个简单的例子,看下面这个图结构:
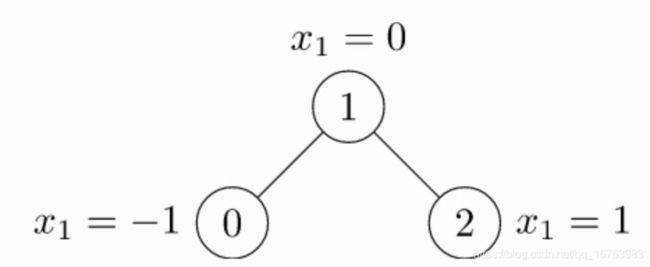
邻接矩阵的创建如下:
A = np.array([0, 1, 0],
[1, 0, 1],
[0, 1, 0])
A = torch.LongTensor(A)
然后你会发现扔进PyG搭建的GCN模型报错了啊!
ValueError: `MessagePassing.propagate` only supports `torch.LongTensor` of shape `[2, num_messages]` or `torch_sparse.SparseTensor` for argument `edge_index`.
![]()
所以很明确!我们需要的形式是[2, num_messages]的coo稀疏矩阵形式,like this:
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
那么问题来了,怎么将我现有的邻接矩阵A转化为上述coo稀疏矩阵呢?找了很多资料,也试过很多函数,把用起来最舒服的一个记录在这里。
import scipy.sparse as sp
A = np.array([[0, 3, 0, 1],
[1, 0, 2, 0],
[0, 1, 0, 0],
[1, 0, 0, 0]])
edge_index_temp = sp.coo_matrix(A)
print(edge_index_temp)
values = edge_index_temp.data # 边上对应权重值weight
indices = np.vstack((edge_index_temp.row, edge_index_temp.col)) # 我们真正需要的coo形式
edge_index_A = torch.LongTensor(indices) # 我们真正需要的coo形式
print(edge_index_A)
i = torch.LongTensor(indices) # 转tensor
v = torch.FloatTensor(values) # 转tensor
edge_index = torch.sparse_coo_tensor(i, v, edge_index_temp.shape)
print(edge_index)
输出结果:
(0, 1) 3
(0, 3) 1
(1, 0) 1
(1, 2) 2
(2, 1) 1
(3, 0) 1
tensor([[0, 0, 1, 1, 2, 3],
[1, 3, 0, 2, 1, 0]])
tensor(indices=tensor([[0, 0, 1, 1, 2, 3],
[1, 3, 0, 2, 1, 0]]),
values=tensor([3., 1., 1., 2., 1., 1.]),
size=(4, 4), nnz=6, layout=torch.sparse_coo)
可以看到,这样处理后我们的邻接矩阵就转化成了coo稀疏矩阵形式,并且边上的权重也保留了到了value中。
然后把特征矩阵X和标签矩阵Y补充完整,搭个最简易的GCN直接训练看看我们的处理是否可行。
import numpy as np
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
import scipy.sparse as sp
import pandas as pd
import networkx as nx
import warnings
warnings.filterwarnings('ignore')
A = np.array([[0, 3, 0, 1],
[1, 0, 2, 0],
[0, 1, 0, 0],
[1, 0, 0, 0]])
edge_index_temp = sp.coo_matrix(A)
print(edge_index_temp)
values = edge_index_temp.data # 边上对应权重值weight
indices = np.vstack((edge_index_temp.row, edge_index_temp.col)) # 我们真正需要的coo形式
edge_index_A = torch.LongTensor(indices) # 我们真正需要的coo形式
print(edge_index_A)
i = torch.LongTensor(indices) # 转tensor
v = torch.FloatTensor(values) # 转tensor
edge_index = torch.sparse_coo_tensor(i, v, edge_index_temp.shape)
print(edge_index)
X = np.array([[1, 0, 1, 1, 1, 1],
[0, 1, 1, 0, 0, 1],
[-1, 1, 0, 1, -1, 1],
[-1, 0, 0, 1, 1, 1]])
X = torch.FloatTensor(X)
Y = np.array([1, 0, 1, 1])
Y = torch.LongTensor(Y)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(6, 16)
self.conv2 = GCNConv(16, 2)
def forward(self):
x, edge_index, edge_weight = X, edge_index_A, v
x = self.conv1(x, edge_index, edge_weight)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index, edge_weight)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Net().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
def train():
model.train()
optimizer.zero_grad()
out = model()
loss = F.nll_loss(out, Y)
loss.backward()
optimizer.step()
@torch.no_grad()
def test():
model.eval()
logits = model()
pred = logits.max(1)[1]
acc = pred.eq(Y).sum().item() / Y.sum().item()
return acc
for epoch in range(100):
train()
acc = test()
print('acc:', acc)
输出一部分训练结果:
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
acc: 1.0
Process finished with exit code 0
最后,也看到有人用networks来处理邻接矩阵的,记录一下但是这里不展开说明:
g = nx.from_numpy_matrix(A)
edge_index_A = nx.to_edgelist(g)
输出结果:
[(0, 1, {'weight': 1}), (0, 3, {'weight': 1}), (1, 2, {'weight': 1})]