深度学习(8)TensorFlow基础操作四: 维度变换
深度学习(8)TensorFlow基础操作四: 维度变换
- 1. View
- 2. 示例
- 3. Reshape操作可能会导致潜在的bug
- 4. tf.transpose
- 5. Squeeze VS Expand_dims
-
- (1) Expand dim(增加维度)
- (2) Squeeze dim(减少维度)
Outline
- shape,ndim
- reshape
- expand_dims/squeeze
- transpose
- broadcast_to
1. View
设[b, h, w]为一个content;
(1) View1: [b, 28, 28]
保存一个batch中的每一张图片,其中每张图片有28行28列,和content的理解是完全一致的;
![]()
(2) View2: [b, 28*28]
直接考虑图片的数据,而不会考虑行和列的数据,也就是说只记录了图片而没有记录行和列的数据;

![]()
![]()
(3) View3: [b, 2, 14*28]
将图片分为上下两部分,也就是说只有上半部分和下半部分这两个概念,至于上半部分或者下半部分有多少行多少列是不知道的;


(4) View4: [b, 28, 28, 1]
增加了channel(通道)属性,也就是RGB的概念;

2. 示例
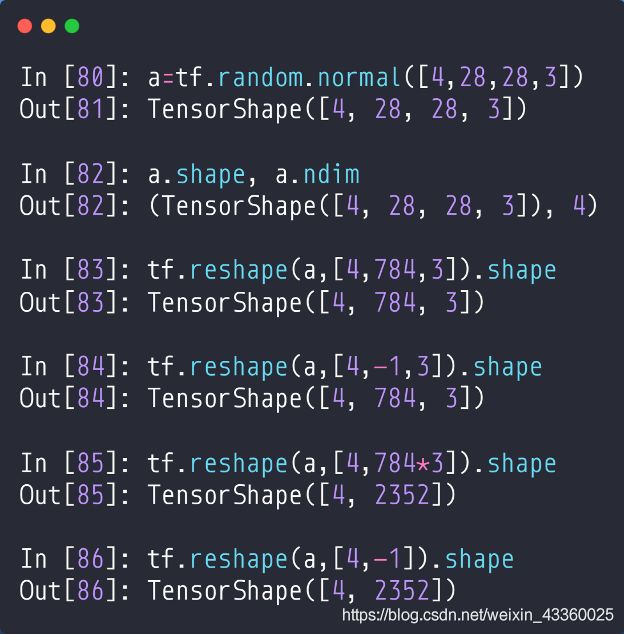
(1) tf.reshape(a, [4, 784, 3]): 将a转换为[4, 28×28, 3]的维度,可以理解为[b, pixel, c];
(2) tf.reshape(a, [4, -1, 3]): 与tf.reshape(a, [4, 784, 3])作用一样,只不过如果不想计算28×28的话可以用-1来代替;
(3) tf.reshape(a, [4, 784*3]): 可以理解我每张图片都是由7843的像素点组成的Vector,这里不但将行和列的信息抹掉了,还将channel的信息抹掉了,只通过[4, 7843]这个数据是无法恢复原数据信息的;
(4) tf.reshape(a, [4, -1]): 与tf.reshape(a, [4, 784*3])作用一样;
- Reshape is flexible

(5) tf.reshape(tf.reshape(a, [4, -1]), [4, 28, 28, 3]): 将[4, 28, 28, 3]变为[4, -1]再恢复为[4, 28, 28, 3];
3. Reshape操作可能会导致潜在的bug
- images: [4, 28, 28, 3]
- [b, h, w, 3]
- reshape to: [4, 784, 3]
- [b, pixel, 3]
注: 需要记住正确的content才能恢复到原来的view,content就是height和weight的维度以及height和weight的顺序;
- 正确的content: height: 28, width: 28
[4, 784, 3] → \to → [4, 28, 28, 3] - 错误的content: height: 14, width: 56
[4, 784, 3] → \to → [4, 14, 56, 3]
这就导致恢复后的图片是错误的; - 错误的content: width: 28, height: 28
[4, 784, 3] → \to → [4, 28, 28, 3]
这种错误更难被察觉到,恢复后的图片依然是错误的;
4. tf.transpose
有些时候我们需要将图片进行旋转操作,这时就需要tf.transpose()方法对content进行变换:

(1) tf.transpose(a): 将a进行转置,转置后的content顺序为[1, 2, 3, 4];
(2) tf.transpose(a, perm=[0, 1, 3, 2]),将content按照perm=[0, 1, 3, 2]进行变换,变换后的content顺序为[4, 3, 1, 2];

(3) tf.transpose(a, [0, 3, 2, 1]): 将content顺序按照[0, 3, 2, 1]变换为[4, 3, 28, 28],也就是[b, c, w, h];
5. Squeeze VS Expand_dims
(1) Expand dim(增加维度)
- a: [classes, students, subjects]
- [4, 35, 8]
- add school dim(dim=axis)
- [1, 4, 35, 8] + [1, 4, 35, 8]
- → \to → [2, 4, 35, 8]

tf.expand_dims(a, axis=0): 在第0维处增加一个维度;tf.expand_dims(a, axis=0): 在第3维处增加一个维度;
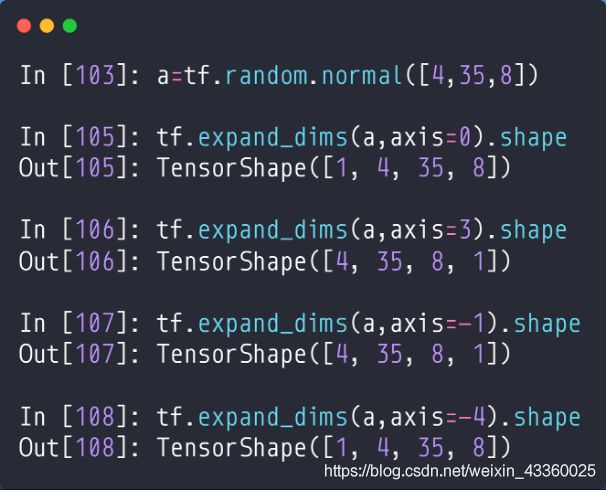
tf.expand_dims(a, axis=-1): 在第-1维,也就是倒数第1维(最后1维)处增加一个维度;tf.expand_dims(a, axis=-4): 在-4维处,也就是倒数第4维(开头处)处增加一个维度;
(2) Squeeze dim(减少维度)
- 只能针对dim=1的维度进行减少维度的操作
- [4, 35, 8, 1]
- [1, 4, 35, 8]
- [1, 4, 35, 1]

tf.squeeze(tf.zeros([1, 2, 1, 1, 3])): 去掉dim=1的所有维度;tf.squeeze(a, axis=0): 将第1个维度去掉;tf.squeeze(a, axis=2): 将第3个维度去掉;tf.squeeze(a, axis=-2): 将倒数第2个维度去掉;tf.squeeze(a, axis=-4): 将倒数第4个维度去掉;
参考文献:
[1] 龙良曲:《深度学习与TensorFlow2入门实战》