MedNeRF:用于从单个X射线重建3D感知CT投影的医学神经辐射场
摘要
计算机断层扫描(CT)是一种有效的医学成像方式,广泛应用于临床医学领域,用于各种病理的诊断。多探测器CT成像技术的进步实现了额外的功能,包括生成薄层多平面横截面身体成像和3D重建。然而,这涉及患者暴露于相当剂量的电离辐射。过量的电离辐射会对身体产生决定性的有害影响。本文提出了一种深度学习模型,该模型学习从少数甚至单个视图X射线重建CT投影。这是基于一种基于神经辐射场构建的新架构,该架构通过从2D图像中解开表面和内部解剖结构的形状和体积深度来学习CT扫描的连续表示。我们的模型是在胸部和膝盖数据集上训练的,我们演示了定性和定量的高保真渲染,并将我们的方法与其他最近基于辐射场的方法进行了比较。我们的代码和数据集链接可在上获得。
临床相关性-我们的模型能够从少数或单视图X射线推断出解剖3D结构,显示出在成像过程中减少电离辐射暴露的未来潜力
1、引言
3D医学成像通常涉及连接CT或磁共振成像(MRI)的多个2D切片,其工作流程的一部分包括指定患者位置、成像源和探测器的值。CT的3D表示的质量和准确性需要数百个薄片厚度的X射线投影[1]。此外,该过程使患者暴露于比典型X射线更多的电离辐射,并要求患者保持不动长达1小时以上,具体取决于测试类型[2]。连续的3D表示将为放射科医生提供内部解剖结构中每一点的光学图像。虽然这样的表示是有用的,但由于辐射暴露增加、角度相关结构和时间消耗,CT存在实际挑战
早期的医学图像重建方法对给定的输入数据使用了分析和迭代方法[4],[5]。然而,他们经常遇到成像系统的数学模型和物理特性之间的不匹配。相反,最近的几种方法利用深度学习[6]进行稀疏视图重建[7]、[8]、[9]、2D图像的3D CT重建[10]和异常检测[11]。这些深度学习方法解决了数学模型和成像系统之间的不匹配,并报告了通过微调最先进的架构改进的重建。然而,它们需要大量的训练数据,这在获取专家注释成本和时间都很高的医学领域可能很难满足。
神经辐射场(NeRF)[12]模型是用于从图像中估计3D体积表示的最新公式。这种表示将场景的辐射场和密度编码在神经网络的参数中。神经网络学习通过沿着投射光线从点采样进行体绘制来合成新视图。然而,这些表示通常在受控设置中捕获[13]。首先,场景由一组固定摄像机在短时间内拍摄。第二,场景中的所有内容都是静态的,真实的图像通常需要掩蔽。这些限制限制了NeRF在医学领域的直接应用,在医学领域,成像系统与传统相机有很大的不同,并且图像在很长的时间内被捕获,阻碍了患者的安静。此外,医学图像中解剖结构的重叠阻碍了边缘的定义,而边缘的定义无法通过掩蔽来容易地解决。这些方面解释了为什么NeRF方法在“自然图像”方面特别成功。
为了解决这些挑战,我们提出了MedNeRF,这是一种在医学领域中调整生成辐射场(GRAF)[14]的模型,以在给定几个或甚至一个单视图X射线的情况下渲染CT投影。我们的方法不仅合成了真实的图像,还捕获了数据集,并提供了解剖结构的衰减和体积深度如何随视点变化的连续表示,而无需3D监控。这是通过一种新的鉴别器架构实现的,该架构在处理CT扫描时向GRAF提供更强和更全面的信号。
与我们的目标最接近的是[8],[9],它们都在体模对象的低剂量CT的正弦图中训练基于坐标的网络,并将其应用于稀疏视图层析重建问题。与[8]相反,我们通过随机输入不同医学实例的数据,而不是为每个图像集合单独优化,在单个模型中学习多个表示。为了测试[9]重建能力,他们将其集成到重建方法中,并使用至少60个视图。与他们的方法不同,我们不依赖额外的重建算法,我们只需要在训练过程中查看多个视图。
我们绘制了胸部和膝盖的两个数字重建射线照片(DRR)数据集的CT投影。我们定性和定量地演示了高保真渲染,并将我们的方法与其他最近基于辐射场的方法进行了比较。此外,我们在给定单视图X射线的情况下绘制了医学实例的CT投影,并显示了我们的模型覆盖表面和内部结构的有效性。
2、方法
A、数据集准备
为了训练我们的模型,我们生成DRR,而不是收集成对的X射线和相应的CT重建,这将使患者暴露于更多的辐射。此外,DRR生成消除了患者数据,并实现了捕获范围和分辨率的控制。我们通过使用[15]、[16]中的20次CT胸部扫描和[17]、[18]中的5次CT膝盖扫描生成DRR。这些扫描覆盖了不同对比类型的患者,显示了正常和异常解剖结构。假设辐射源和成像面板围绕垂直轴旋转,每五度产生128×128分辨率的DRR,每个物体产生72个DRR。在训练期间,我们为每位患者使用了72个DRR(在360度垂直旋转范围内,占所有视图的五分之一),并让模型渲染其余部分。我们的工作不涉及人类受试者或动物的实验程序,因此不需要机构审查委员会的批准。
B、GRAF概述
GRAF[14]是一个基于NeRF构建的模型,并在生成对抗网络(GAN)中对其进行定义。它由预测图像补丁Ppred的生成器Gθ和将预测补丁与从真实图像中提取的补丁Preal进行比较的鉴别器Dφ组成。与原始的NeRF[12]和类似的方法(如[19])相比,GRAF已经显示出单独从2D图像中分离物体的3D形状和视点的有效能力。因此,我们的目标是将GRAF的方法转化为我们的任务,在第II-C小节中,我们描述了我们的新鉴别器架构,它允许我们从DRRs中分离3D属性。
我们考虑实验设置以获得辐射衰减响应,而不是自然图像中使用的颜色。为了获得具有姿态ξ的任意投影K的像素位置处的衰减响应,首先,我们考虑模式ν=(u,s)以在K×K图像块P内采样R个X射线束。然后,我们沿着X射线束r从像素位置采样N个3D点xir,并在投影的近平面和远平面之间排序(图1a)。
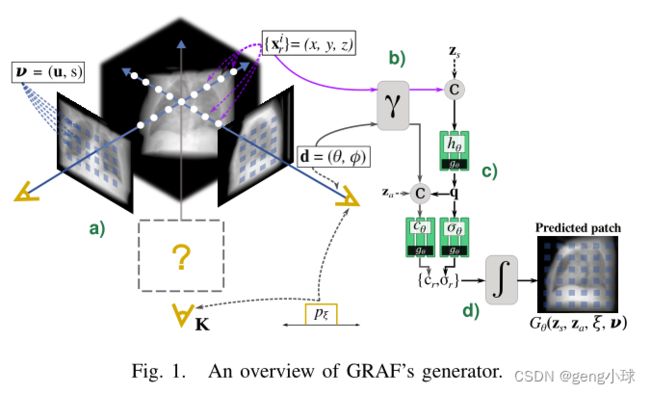 对象表示在多层感知器(MLP)中编码,该感知器将3D位置x=(x,y,z)和观看方向d=(θ,φ)作为输入,并生成密度标量σ和像素值c作为输出。为了学习高频特征,将输入映射为2L维表示(图1b):
对象表示在多层感知器(MLP)中编码,该感知器将3D位置x=(x,y,z)和观看方向d=(θ,φ)作为输入,并生成密度标量σ和像素值c作为输出。为了学习高频特征,将输入映射为2L维表示(图1b): 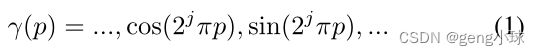
其中p表示3D位置或观看方向,j=0,…,m− 1.
为了模拟解剖结构的形状和外观,让zs∼ ps和za∼ pa分别是从标准高斯分布采样的潜码(图1c)。为了获得密度预测σ,形状编码q通过密度头σθ转换为体积密度。然后,网络gθ(·)对形状编码q=(γ(x),zs)进行操作,随后将其与d的位置编码和外观代码za(图1c)连接起来:
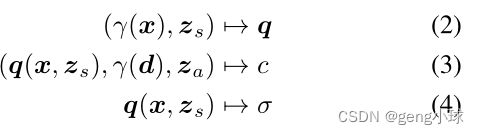
通过合成操作计算最终像素响应cr(图1c):
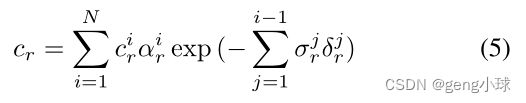
其中αir=1− 出口(−σirδir)是采样点i的α合成值,δir=k xi+1r− xir k2是相邻采样点之间的距离。
通过这种方式,在沿着具有网络gθ的波束r的每个采样点处计算密度和像素值。最后,结合所有R光束的结果,生成器Gθ预测图像块Ppred,如图所示。1d。
C、MedNeRF
我们研究了如何将GRAF应用于医学领域,并将其应用于从DRR中渲染体积表示。利用大数据集,GRAF的鉴别器Dφ能够连续提供有用的信号来训练发生器Gθ。然而,像我们问题中所考虑的医疗数据集一般都很小,这导致了两个连续问题:
生成器缺乏真实信息:在GRAF(以及一般的GAN)中,有助于生成器的训练数据的特征的唯一来源是从鉴别器传递的间接梯度。我们发现,来自GRAF鉴别器的单卷积反馈不能很好地传递DRR的精细特征,导致不准确的体积估计。
脆弱的对抗性训练:在有限的训练数据集中,生成器或鉴别器可能会陷入不适定的设置,例如模式崩溃,这将导致生成有限数量的实例,从而导致次优的数据分布估计。虽然一些工作已经应用了数据增强技术来利用医学领域中的更多数据,但一些转换可能会误导生成器了解不常见甚至不存在的增强数据分布[20]。我们发现,天真地应用经典数据扩充的效果不如我们采用的框架好。
1) 高保真度合成的自监督学习:
为了允许从DRR中覆盖更丰富的特征图,从而产生更全面的信号来训练Gθ,我们用自监督方法的最新进展取代了GRAF的鉴别器架构。我们允许Dφ在借口任务上学习有用的全局和局部特征,特别是基于自动编码的自我监督方法[21]。与[21]不同,我们只使用两个解码器对比例上的特征图进行解码:322上的F1和82上的F2(图2a)。我们发现,这种选择允许更好的性能,并实现正确的体积深度估计。因此,Dφ不仅必须区分预测的Ppred和Gθ,还必须从真实图像块Preal中提取综合特征,使解码器能够模拟数据分布。
为了从Dφ评估解码块的全局结构,我们使用学习感知图像块相似性(LPIPS)度量[22]。我们计算两个VGG16特征空间之间的加权成对图像距离,其中预训练的权重适合于更好地匹配人类感知判断。因此,附加鉴别器损失为:
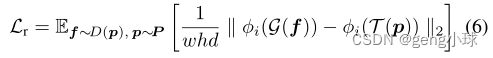
其中φi(·)表示预训练VGG16网络的第i层输出,w、h和d分别表示特征空间的宽度、高度和深度。设G是对Dφ的中间特征映射f的处理,T是对真实图像块的处理。当加上这种额外的重建损失时,网络学习跨任务传输的表示。
2) 通过数据增强改善学习:
我们通过采用针对GAN优化的数据增强(DAG)框架[20]来改进Gθ和Dφ的学习,其中数据增强变换Tk(图2b)使用多个鉴别器头{Dk}施加。为了进一步减少内存使用,我们共享Dφ的所有层,除了与每个头部对应的最后一层(图2c)。因为应用可微和可逆数据增强变换Tk具有Jenssen-Shannon(JS)保留性质[20]:
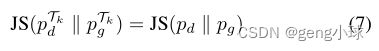
将GRAF的物流目标替换为铰链损失,然后我们将总体损失定义如下:
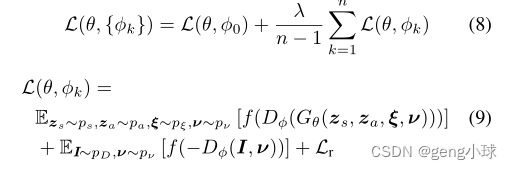
其中f(u)=最大值(0,1+u)。我们优化了n=4的损失,其中k=0对应于恒等变换,λ=0.2(如[20]所示)。
3) 单视图X射线的体积渲染:
在训练模型后,我们在给定单视图X射线的医学实例的完整垂直旋转内重建完整的X射线投影。我们遵循[23]中的松弛重建公式,该公式使生成器适合于单个图像。然后,我们允许发生器Gθ的参数与形状和外观潜矢量zs和za一起稍微微调。失真和感知权衡在GAN方法中是众所周知的[24],因此我们通过添加失真均方误差(MSE)损失来修改我们的生成目标,这激励了模糊性和准确性之间的平衡:
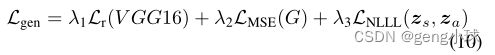
其中NLLL对应于负对数似然损失和调谐超参数lr=0.0005,β1=0,β2=0.999,λ1=0.3,λ2=0.1和λ3=0.3。
一旦模型找到了zs和za的最佳组合,我们就复制它们,并通过连续控制角度视点来渲染其余的X射线投影。
3、结果
在此,我们在数据集上对MedNeRF进行了评估。我们将模型的结果与两个基线的实际情况进行比较,进行消融研究,并进行定性和定量评估。我们对所有模型进行了100000次迭代,批量大小为8。选择投影参数(u,v)来均匀地采样球体表面上的点,特别是轻微的水平仰角为70-85度,垂直旋转360度时umin=0,umax=1。然而,我们在训练期间只提供了五分之一的视图(每个视图在五度角上有72个视图),并让模型渲染其余的视图。
A、 单视图X射线重建
我们评估了以单视图X射线作为输入的3D感知DRR合成的模型表示。我们发现,尽管隐式线性网络的容量有限,但我们的模型可以区分不同医学实例的3D解剖特征和衰减响应,这些都是通过II-C.3中所述的重建公式检索的,因为它为更密集的结构(例如骨骼)呈现更亮的像素值(图3)。
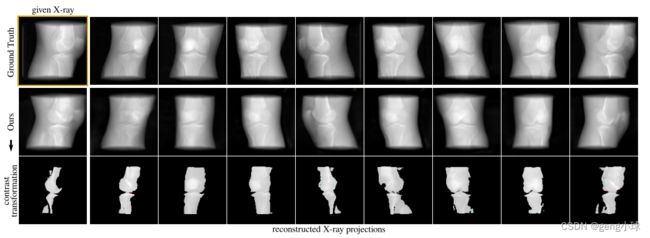
图3.连续视点旋转的膝盖渲染图,显示组织和骨骼。给定来自CT的单视图X射线,我们可以通过稍微微调预训练模型以及形状和外观潜代码,在整个垂直旋转内生成完整的CT投影集。
表I总结了我们基于峰值信号噪声比(PSNR)和结构相似性(SSIM)的结果,它们分别测量重建信号的质量和人类主观相似性。我们发现,我们的生成损失可以在渲染图中实现合理的感知失真曲线,并且与地面真实情况相比,在连续视点下显示出与解剖结构的位置和体积深度的一致性。
表I.基于单视图X射线输入的渲染X射线投影的PSNR和SSIM的定量结果。

B、DRR渲染
我们在2D渲染任务上评估了我们的模型,并将其与pixelNeRF[19]和GRAF[14]基线进行了比较,其中使用了原始架构。与GRAF和pixelNeRF相比,我们的模型可以更准确地估计体积深度(图4)。对于每个类别,我们都会找到一个具有相似视图方向和形状的不可见目标实例。体积深度估计由亮颜色(远)和暗颜色(近)给出。由于缺乏感知损失,GRAF无法产生高频纹理。相反,我们发现我们的模型呈现了具有不同衰减的更详细的内部结构。GRAF产生一致的衰减响应,但似乎无法区分解剖形状和背景。我们的自我监督鉴别器使生成器能够通过为背景渲染更亮的颜色和为形状渲染更暗的颜色来区分形状和背景,而GRAF为两者渲染亮或暗的颜色。
我们发现pixelNeRF为所有数据集生成了模糊的衰减效果图,而体积图往往表现出强烈的颜色偏移(图4)。我们认为,与训练NeRFs的类实体自然对象相比,这些伪影是由于数据集的透视性质。这种数据特征不仅损害了体积图,而且损害了精细的解剖结构。相比之下,我们的模型能够更好地呈现体积深度和衰减响应。我们还发现pixelNeRF对投影参数的轻微变化很敏感,阻碍了膝盖类别的优化。我们的模型生成一致的3D几何体,不依赖于显式投影矩阵。
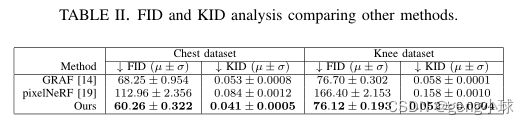
表II比较了基于Frechet起始距离(FID)和内核起始距离(KID)度量的图像质量,其中值越低意味着越好。在我们的数据集上优化pixelNeRF会导致特别差的结果,无法与GRAF基线和我们的模型竞争。相比之下,我们的模型在所有数据集的FID和KID指标上都优于基线。
C、 消融研究
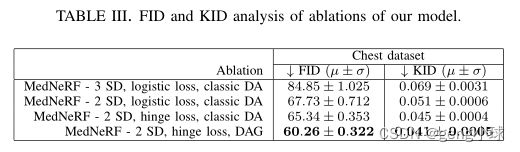
我们用三种消融评估了我们的模型(表III):其中包括一个额外的简单解码器(SD);对抗性后勤损失被其铰链版本所取代;并且其中采用非经典DAG方法。我们发现,与单纯应用经典DA相比,DAG方法带来了最大的性能提升,而铰链损失的使用性能略优于其逻辑版本。然而,我们的自监督鉴别器中的附加解码器可能会导致性能的显著下降。
4、结论
我们提出了一种基于神经辐射场的新型深度学习架构,用于学习CT扫描的连续表示。我们学习了一组2D DRR在生成器权重中的衰减响应的医学类别编码。此外,我们发现,来自鉴别器的更强和更全面的信号允许生成辐射场对3D感知CT投影进行建模。实验评估表明,与其他神经辐射场方法相比,定性和定量重建和改进显著。虽然所提出的模型可能不能完全替代CT,但从X射线生成3D感知CT投影的功能在骨创伤、发育不良的骨骼评估和矫形术前规划中具有巨大的临床应用潜力。这可能会减少给患者的辐射剂量,带来重大的经济影响,如降低调查成本。