EEGNet:一个小型的卷积神经网络,用于基于脑电的脑机接口
脑机接口(BCI)利用神经活动作为控制信号,可以与计算机直接通信。这种神经信号通常从各种研究充分的脑电图(EEG)信号中选择。对于给定的脑机接口(BCI)范式,特征提取器和分类器是针对其所期望的脑电图控制信号的不同特征而定制的,这限制了其对特定信号的应用。卷积神经网络(Convolutional neural networks,CNNs)已被用于计算机视觉和语音识别中进行自动特征提取和分类,并成功地应用于脑电信号识别中;然而,它们主要应用于单个BCI范例,因此尚不清楚这些架构如何推广到其他范例。在这里,我们想问的是,我们是否可以设计一个单一的CNN架构来准确地分类来自不同BCI范式的脑电图信号,同时尽可能小型的方法。在这项工作中,我们介绍了EEGNet,一个小型的卷积神经网络为基于脑电图的BCI。我们介绍了深度卷积和可分离卷积的使用来构建脑电图特定模型,该模型封装了众所周知的脑机接口脑电图特征提取概念。我们比较了EEGNet,包括被试内和跨被试分类,以及目前最先进的四种BCI范式:P300视觉诱发电位、错误相关负波(ERN)、运动相关皮层电位(MRCP)和感觉运动节律(SMR)。我们表明,当在所有测试范例中只有有限的训练数据可用时,EEGNet比参考算法更好地泛化,并取得了相当高的性能。此外,我们还演示了三种不同的方法来可视化训练过的EEGNet模型的内容,以支持对学习到的特征的解释。意义:我们的结果表明,EEGNet足够鲁棒,可以在一系列BCI任务中学习各种各样的可解释特征。本文发表在Journal of Neural Engineering杂志。
1 引言
脑机接口(BCI)可以通过脑信号与机器直接通信。传统上,BCI被用于医疗应用,如人工假肢的神经控制。然而,最近的研究为新型BCI开辟了可能性,这些BCI主要通过基于脑电图(EEG)的无创方法来提高健康用户的性能。一般来说,BCI包括五个主要处理阶段:
数据收集阶段,记录神经数据;
信号处理阶段,在此对记录的数据进行预处理和清理;
特征提取阶段,从神经数据中提取有意义的信息;
分类阶段,根据数据解释决策;
反馈阶段,将决策的结果提供给用户。虽然在BCI范式中这些阶段基本相同,但每个范式都依赖于信号处理、特征提取和分类方法的手动规范,而这一过程通常需要重要的专业知识和对预期脑电图信号的先验知识。还有一种可能是,由于脑电图信号预处理步骤通常针对感兴趣的脑电图特征(例如,针对特定频率范围的带通滤波),其他潜在相关的脑电图特征可能被排除在分析之外(例如,带通频率范围以外的特征)。随着BCI技术发展到新的应用领域,对鲁棒的特征提取技术的需求只会继续增加。
深度学习在很大程度上减轻了人工特征提取的需要,在计算机视觉和语音识别等领域实现了最先进的性能。具体来说,深度卷积神经网络(CNN)的使用越来越多,部分原因是它们在许多具有挑战性的图像分类问题上取得了成功,超过了依赖手工制作的特征的方法。虽然大多数BCI系统仍然依赖于使用手工制作的特征,但最近已有许多研究探索了深度学习在脑电图信号中的应用。例如,神经网络已用于癫痫预测和监测,听觉音乐检索,视觉诱发反应检测和运动图像分类,而深度信念网络(DBNs)已用于睡眠阶段检测,异常检测和运动起始视觉诱发电位分类。利用脑电数据的时频变换神经网络进行心理负荷分类和运动想象分类。受限玻尔兹曼机(rbm)已用于运动想象。有一种基于堆叠去噪自适应编码器的心理负荷分类方法。这些研究主要集中在单个BCI任务的分类上,通常使用特定于任务的知识来设计网络架构。此外,用于训练这些网络的数据量在不同的研究中差异很大,部分原因是在不同的实验设计下收集数据的难度很大。因此,目前尚不清楚这些先前的深度学习方法如何推广到其他BCI任务以及不同训练数据大小。
在本工作中,我们介绍了EEGNet,一个小型的CNN,用于分类和解释基于eeg的BCI。我们介绍了深度卷积和可分离卷积的使用,以前在计算机视觉中使用,构建了一个脑电图特定的网络,封装了几个著名的脑电图特征提取概念,如最佳空间滤波和滤波器组构建,同时与现有方法相比,减少了可训练参数拟合的数量。我们评估了EEGNet在从四种不同BCI范式收集的脑电图数据集上的泛化性:P300视觉诱发电位(P300)、错误相关负性电位(ERN)、运动相关皮质电位(MRCP)和感觉运动节律(SMR),代表了基于事件相关电位(P300、ERN、MRCP)分类和振荡成分(SMR)分类的范式。此外,每个数据集合包含不同数量的数据,允许我们探索EEGNet对不同训练数据大小的有效性。结果表明:当训练数据有限时,EEGNet在几乎所有测试范式中都比现有范式不可知的EEG CNN模型实现了更好的分类性能。此外,我们还证明了EEGNet有效地推广了所有测试范例。我们还表明,EEGNet表现得与更具范式特异性的EEG CNN模型一样好,但需要拟合的参数少了两个数量级,表示更有效地使用模型参数。最后,通过使用特征可视化和模型消融(ablation)分析,我们表明可以从EEGNet模型中提取神经生理学可解释的特征。这一点很重要,因为尽管CNN具有强大的自动特征提取能力,但它们经常产生难以解释的特征。对于神经科学从业者来说,根据预期的应用,获得对CNN衍生的神经生理现象的见解的能力可能与获得良好的分类性能一样重要。我们验证了我们的架构在几个充分研究的BCI范式上提取神经生理学可解释信号的能力。
本文其余部分结构如下。第2.1节简要描述了用于验证我们的CNN模型的四个数据集。第2.2节描述了我们在模型比较中使用的EEGNet模型以及其他BCI模型(包括CNN和非CNN模型)。第3节介绍了被试内和跨被试分类性能的结果,以及我们的特征可解释性分析的结果。我们在讨论中更详细地讨论我们的发现。
2材料和方法
2.1数据描述
根据感兴趣的脑电特征,BCI一般分为两种类型:事件相关和振荡。事件相关电位(ERP) bci旨在检测已知的、时间锁定的外部刺激的高振幅和低频率脑电图反应。它们通常在不同的被试之间都是鲁棒的,并且包含了良好的定型波形,使ERP的时间过程能够通过机器学习有效地建模。基于ERP的bci主要依赖于从外部事件或刺激中检测ERP波形,而振荡型bci则利用特定EEG频带的信号功率进行外部控制,一般为去同步。当振荡信号被时间锁定到外部刺激时,它们可以通过事件相关谱扰动(ERSP)分析来表示。振荡bci更难训练,通常是由于较低的信噪比(SNR)以及被试之间更大的差异。在本文中使用的数据的总结可以在表1中找到。
表1本研究数据收集的总结。

2.1.1数据集1:P300。
P300事件相关电位是对新异视觉刺激的刻板神经反应。它通常是由视觉奇异球范式引发的,参与者看到重复的非目标视觉刺激,这些刺激以固定的呈现率(例如,1hz)与不频繁的目标刺激穿插在一起。在顶叶皮层观察到,P300波形是在刺激开始后大约300ms观察到的电活动的一个大的正偏转,观察到的偏转强度与目标刺激的频率成反比。P300 ERP是脑电图观察到的最强的神经信号之一,特别是当目标不经常出现时。当图像呈现率增加到2hz或更高时,通常称为快速序列视觉呈现(RSVP),它已用于开发用于大型图像数据库分类的bci。
这里使用的脑电图数据下面给出了一个简短的描述。18名参与者自愿参加RSVP BCI研究。研究人员向参与者展示了2hz频率的自然风景图像,图像中要么有车辆或人(目标),要么没有车辆或人(非目标)。当目标图像出现时,参与者被要求用惯用手按下按钮。目标/非目标比例为1/4。由于脑电图数据中存在过多的伪影和噪声,来自三个参与者的数据被排除在分析之外。对其余15名参与者(9名男性,14名右撇子)的数据进行了进一步分析,这些参与者的年龄从18岁到57岁(平均年龄39.5岁)。BioSemi系统,采样率512hz,64导,符合国际10-10系统,连续的脑电图数据离线重参考为双侧乳突,使用EEGLAB的FIR滤波器进行数字带通滤波至1-0 Hz,下采样至128 Hz。在刺激发生后0-1s提取目标和非目标条件的脑电图试次,并用于二分类。
2.1.2数据集2:反馈错误相关负波(ERN)
错误相关的负电位是在被试的环境或任务中发生错误或不寻常的事件后产生的脑电图扰动。可以在各种任务中观察到它们,包括时间间隔生产范式和强制选择范式。这里我们关注的是ERN,即脑电在感知BCI产生的错误反馈后的振幅扰动。在视觉反馈后,反馈ERN的特征是一个大约350ms的负的错误分量,然后是一个大约500ms的正的错误分量(见图7)。反馈ERN的检测提供了一种机制来推断并可能实时纠正BCI的错误输出。这种两阶段系统已被证明可以在在线应用中提高P300拼写器的性能。
这里使用的脑电图数据并在Kaggle主办的BCI挑战中使用过。26名健康的参与者(16人训练,10人用来测试)参与了P300拼写任务,该系统使用一个随机的闪光字母序列,按6*6格排列,以引起P300反应。挑战的目标是确定P300拼写者的反馈是正确的还是错误的。脑电数据最初以600 Hz的频率记录,使用56个被动脑电传感器(VSM-CTF兼容系统)符合扩展10 - 20系统。在我们的分析之前,EEG数据经过带通滤波,使用在EEGLAB中的FIR滤波器,至1-40 Hz,下采样至128 Hz。在0-1.25s后的反馈陈述中提取正确和不正确反馈的脑电图试次,并将其作为特征进行两类分类。
2.1.3数据集3:运动相关的皮层电位(MRCP)
一些神经活动既包含ERP成分,又包含振荡成分。其中一个特别的例子是运动相关的皮层电位(MRCP),它可以由手和脚的随意运动引起,并可以通过脑电图(EEG)沿着手或脚运动对侧的中央和中线电极观察到。MRCP可以再运动开始前看到(一个缓慢0-5hz的准备电位和在10-12hz的早期去同步),在运动开始(一个缓慢的运动电位),运动开始后(运动执行的大约1s的20-30 Hz的晚期同步活动)。MRCP先前已被用于为健康和肢体残疾患者开发运动控制BCIs。
这里使用的脑电图数据下面给出了一个简短的描述。在这项研究中,13名被试使用左食指、左中指、右食指或右中指进行自定节奏的手指运动。使用256通道的BioSemi Active II系统以1024 Hz的频率记录数据。由于数据中存在大量的信号噪声,首先使用PREP管道对脑电图数据进行处理。数据重参考到双侧乳突,使用FIR滤波器带通滤波0.1-40 Hz之间,然后向下采样到128 Hz。并降采样电极数为64导,将每只手的食指和中指块结合起来,对来自左手或右手的动作进行二分类。提取手指运动开始前后-0.5—1s左右手指运动的脑电图,并进行二分类。
2.1.4数据集4:感觉运动节律(SMR)
基于振荡的BCI的一个常见控制信号是感觉运动节律(SMR),其中mu (8 -12 Hz)和beta (18 -26 Hz)波段在感觉运动皮层对侧与实际或想象的运动失同步。SMR与MRCP中的振荡成分非常相似。尽管基于SMR的BCI可以促进微妙的内源性BCI控制,但它们往往很弱,而且在被试之间和被试内部差异很大,为了实现合理的表现,传统上要求用户训练(神经反馈)和长校准时间(20分钟)。这里使用的脑电图数据来自BCI竞赛第四组数据集2A(称为SMR数据集)。这些数据包括9名被试的左右手、脚和舌头的动作的四类想象运动。采集时22个电极,250Hz,0.5-100hz,我们降采样为128hz,数据在4-40 Hz频段使用三阶巴特沃斯滤波器进行因果滤波,以最大限度地减少分类判别中眼睛运动的影响。对于训练集和测试集,我们在线索开始后分段为0.5-2.5s。注意,我们只对测试集中的这个时间范围进行预测。之后执行四分类。
2.2分类方法
2.2.1 EEGNet:压缩的CNN架构。
这里我们介绍EEGNet,一个压缩的CNN架构,用于基于EEG的BCI(1)可以应用于几种不同的BCI范例,(2)可以使用非常有限的数据进行训练,(3)可以产生神经生理学上可解释的特征。图1和表2分别为采集频率为128hz、有C个通道和T个时间样本的EEG试次的EEGNet模型的可视化和完整描述。我们使用Adam优化器拟合模型,使用默认参数,最小化分类交叉熵损失函数。我们运行500次训练迭代(epochs)并执行验证停止,以节省产生最小验证集损失的模型权重。所有模型都使用NVIDIA Quadro M6000 GPU,使用CUDA 9和cuDNN v7,使用Tensorflow,Keras API。在所有卷积层中,我们省略了偏置单元的使用。注意,虽然所有卷积都是一维的,但为了便于软件实现,我们使用了二维卷积函数。
在block 1中,我们依次执行两个卷积步骤。首先,我们拟合大小(1,64)为F1的2D卷积滤波器,滤波器长度为数据采样率(这里是128Hz)的一半,输出包含不同带通频率脑电图信号的F1特征图。将时间核的长度设置为采样率的一半,允许捕获2hz及以上的频率信息。然后我们使用大小为(C, 1)的深度卷积来学习一个空间滤波器。在计算机视觉的CNN应用中,深度卷积的主要好处是减少了可训练参数的拟合数量,因为这些卷积并没有完全连接到所有以前的特征映射(参见图1)。重要的是,当用于脑电图特定的应用时,该操作提供了一种直接的方法来学习每个时间滤波器的空间滤波器,从而能够有效地提取特定频率的空间滤波器(见图1的中间列)。深度参数D控制每个特征映射要学习的空间滤波器的数量(为了便于说明,图1中显示了D = 1)。这种两步卷积序列的灵感部分来自于滤波器组公共空间模式(FBCSP)算法,并且在本质上类似于另一种分解技术,双线性判别分量分析。我们保持两个卷积都是线性的,因为我们发现在使用非线性激活时没有显着的性能提高。在应用指数线性单元(ELU)非线性之前,我们沿着特征图维度应用批量归一化。为了帮助正则化或建模,我们使用dropout技术。我们设置了被试内分类的dropout概率为0.5,以帮助防止在小样本中训练时过度拟合,设置跨被试分类的dropout概率为0.25,因为训练集规模大得多(参见2.3节获取详情)。我们应用一个平均大小(1,4)的池化层来将信号的采样率降低到32hz。我们还通过对权重使用最大范数约束1来正则化每个空间滤波器;


图1 EEGNet架构的整体可视化。线条表示输入和输出之间的卷积核连接性(称为特征映射)。该网络从时间卷积(第二列)开始学习频率滤波器,然后使用深度卷积(中间列),分别连接到每个特征图,学习频率特定的空间滤波器。可分离卷积(第四列)是一个深度卷积的组合,它分别学习每个特征映射的时间总结,然后是一个点卷积,它学习如何最优地混合这些特征映射。关于网络架构的详细信息可以在表2中找到。
表2 EEGNet架构,其中C =通道数,T =时间点数,F1 =时间滤波器数,D =深度乘法器(空间滤波器数),F2 =点滤波器数,N =类数。对于Dropout层,我们使用p = 0.5作为被试内分类,p = 0.25作为跨被试分类(详见2.2.1节)。

在block 2中,我们使用可分离(separable)卷积,这是一个深度卷积(在这里,大小为(1,16),代表在32 Hz上的500ms的脑电图活动),然后是F2(1,1)点卷积。可分离卷积的主要好处是:(1)减少拟合参数的数量;(2)通过首先学习一个核,分别总结每个特征映射,然后最优地合并输出,解耦合特征映射内部和跨特征映射的关系。当用于EEG特定的应用时,该操作将学习如何及时总结单个特征映射(深度卷积)与如何最佳地组合特征映射(点卷积)分离开来。这种操作对于脑电图信号也特别有用,因为不同的特征图可能代表不同时间尺度的信息数据。在我们的例子中,我们首先学习每个特征图的500ms,然后合并输出。一个平均大小(1,8)的池化层用于降维。
在分类block中,这些特征直接传递给一个N个单元的softmax分类,N是数据中类的数量。在softmax分类层之前,我们省略了使用稠密层进行特征聚合,以减少模型中自由参数的数量。
2.2.2与现存CNN方法的比较
我们比较了EEGNet与DeepConvNet和ShallowConvNet模型的性能。我们在Tensorflow和Keras中实现了这些模型。由于它们的架构最初是为250 Hz的EEG信号设计的(与这里使用的128 Hz信号相反),我们将它们架构中的时间核和池化层的长度分为两个,以大致对应于我们的模型中使用的采样率。我们以训练EEGNet模型的相同方式训练这些模型(见2.2.1章节)。
DeepConvNet体系结构由五个卷积层组成,其中一个softmax层用于分类(参见图1)。ShallowConvNet架构由两个卷积层(时间层和空间层)组成。我们想强调的是,ShallowConvNet架构是专门为振荡信号分类设计的(通过提取与log-功率相关的特征);因此,它可能不能很好地工作在基于ERP的分类任务上。然而,DeepConvNet架构被设计为通用架构,不局限于特定的功能类型,因此,它可以作为EEGNet的一个更有效的比较。表3显示了所有CNN模型中每个模型可训练参数的数量。
表3 所有基于CNN的模型的每个模型和每个数据集可训练参数的数量。我们发现,在所有数据集上,EEGNet模型比DeepConvNet和ShallowConvNet都要小两个数量级。注意,我们为SMR数据集使用32个样本的时间核长度,因为数据是4hz的高通滤波数据。

2.2.3与传统方法的比较
我们还将EEGNet的性能与表现最好的传统方法对每个范例的性能进行了比较。对于所有基于ERP的数据分析(P300,ERN,MRCP),传统方法是赢得Kaggle BCI竞赛的方法,使用xDAWN空间滤波,黎曼几何,选择通道子集和L1特征正则化的组合。对于基于振荡的SMR分类,传统的方法是我们自己实现one- vs -rest(OVR)滤波器组公共空间模式(FBCSP)算法。为了便于实现,我们选择使用弹性网络逻辑回归,而且事实上它已经在FBCSP的现有软件实现中使用。
2.3数据分析
分类结果报告了两组分析:被试内和被试间。被试内分类使用被试数据的一部分来训练专门针对该被试的模型,而跨被试分类使用来自其他被试的数据来训练被试不可知的模型。虽然在各种任务上,被试内部模型往往比跨被试模型表现得更好,但正在进行的研究调查技术可以最小化(或可能消除)训练鲁棒系统所需的被试特定的信息。
对于被试内,我们使用四折交叉验证。我们使用重复测量方差分析(ANOVA)进行统计测试。对于P300和MRCP中的跨被试分析,我们随机选择四个被试作为验证集,一个被试作为测试集,其余的被试作为训练集(每个数据集的被试数量见表1)。
当训练被试内和跨被试模型时,我们在数据不平衡时(每个类的试次数不均等)对损失函数应用类别权重。我们应用的类别权重是训练数据中比例的倒数。例如,在P300数据集中,非目标和目标之间的几率为5.6:1(表1)。这个过程只应用于P300和ERN数据集,因为这是唯一存在显着类别不平衡的数据集。
2.4 EEGNet特征解释
在过去的几年里,从深度神经网络实现特征解释的方法的发展已经成为一个活跃的研究领域,并已被提出作为一个鲁棒的模型验证程序的重要组成部分,确保分类性能是由相关特征驱动的,而不是数据中的噪声或伪影。我们提出了三种不同的方法来理解EEGNet派生的特性:
1.汇总隐藏单元激活的平均输出。这可以定位某个频段的空间位置。
2.可视化卷积核权重:因为EEGNet限制了卷积层的连通性(使用深度卷积和可分离卷积),所以可以将时间卷积解释为窄带频率滤波器,将深度卷积解释为特定频率的空间滤波器。
3.计算单试次特征对分类决策的相关性:相关性的正值表示支持结果的证据,而相关性的负值表示反对结果的证据。这种分析可以用来阐明高置信度和低置信度预测的特征相关性,并可以用来确认学习到的相关特征是可解释的,而不是噪声或伪特征。
3 结果
3.1被试内分类
我们比较了两种基于CNN的参考算法(DeepConvNet and ShallowConvNet)与EEGNet - 4,2和EEGNet - 8,2的性能。在P300所有算法的被试4折交叉验证结果中,MRCP和ERN数据集如图2所示。我们观察到,在所有范式中,EEGNet - 4,2和EEGNet -8,2之间没有统计学上的显着差异(p > 0.05),这表明模型复杂性的增加没有统计学上的分类性能提高。对于P300数据集,所有基于CNN的模型显着优于xDAWN+RG (p < 0.05),但它们之间的表现没有显着差异。对于ERN数据集,EEGNet - 8,2优于DeepConvNet、ShallowConvNet和xDAWN+RG (p < 0.05),而EEGNet - 4,2优于DeepConvNet和ShallowConvNet (p < 0.05)。在所有方法中观察到的最大差异是在MRCP数据集中,两种EEGNet模型在统计上都显着优于其他所有模型(DeepConvNet、ShallowConvNet和xDAWN+RG,每一次比较p < 0.05)。
SMR数据集的4折交叉验证结果如图3所示。这里我们看到,ShallowConvNet和FBCSP的性能非常相似,重复了先前的结果,而DeepConvNet的性能明显较低。我们还看到EEGNet - 8,2的性能也类似于FBCSP。

图3每个模型的SMR数据集的4折被试内分类性能,平均所有折和所有被试。误差条表示平均值的两个标准误差。在这里,我们看到DeepConvNet统计上表现比所有其他模型更差(p < 0.05)。ShallowConvNet和EEGNet -8,2的性能与FBCSP相似。

图4对每个模型的P300、ERN和MRCP数据集进行跨被试分类,平均30折。误差条表示平均值的两个标准误差。对于P300和MRCP数据集,DeepConvNet和EEGNet模型的差异最小,两者的性能都优于ShallowConvNet。对于ERN数据集,参考算法(xDAWN + RG)显着优于所有其他模型。
3.2 跨被试分类
P300、MRCP和ERN数据集各算法的跨被试分类结果如图4所示。与被试内部分析相似,我们在所有数据集上观察到EEGNet - 4,2和EEGNet - 8,2之间没有统计学差异(p > 0.05)。对于P300数据集,所有基于CNN的模型显着优于xDAWN + RG (p < 0.05),但它们之间的表现没有显着差异。对于MRCP数据集,EEGNet-8、2和DeepConvNet显着优于ShallowConvNet (p < 0.05)。我们还看到,与MRCP数据集的被试内性能相比,DeepConvNet和ShallowConvNet的性能都更好。对于ERN数据集,xDAWN+RG优于所有CNN模型(p < 0.05)。SMR数据集的跨被试分类结果如图5所示,我们发现所有基于CNN的模型在性能上没有显着差异(p > 0.05)。
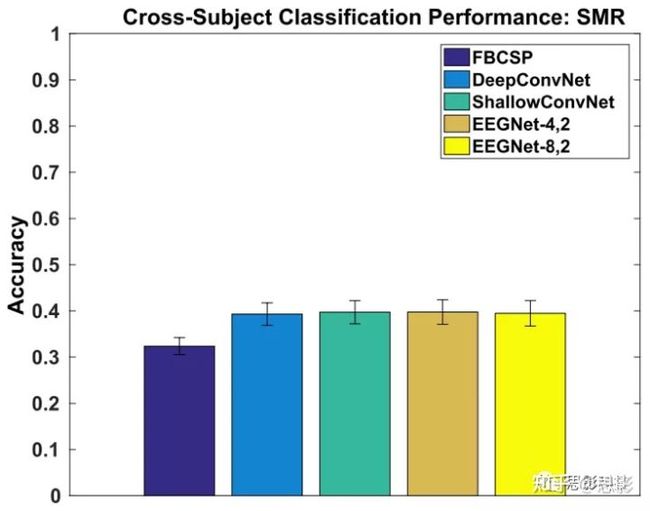
图5每个模型的SMR的跨被试分类性能,平均所有折和所有被试。误差条表示平均值的两个标准误差。我们看到,所有基于CNN的模型的表现都类似,但性能略优于FBCSP。
3.3 EEGNet特征
我们举例说明了三种不同的方法来表征EEGNet学到的特征:(1)总结隐藏单元激活的平均输出,(2)可视化卷积核权重,以及(3)计算单试次特征在分类决策上的相关性。我们在P300数据集上说明方法1,用于跨被试训练的EEGNet - 4,1模型。我们选择分析来自P300数据集的滤波器,是因为多个神经生理事件同时发生:参与者被告知,只要目标图像出现在屏幕上,就用他们的惯用手按下按钮。正因为如此,目标试次包含了P300事件相关电位以及对侧运动皮层中由于按钮按压而产生的alpha/beta去同步化。这里,我们感兴趣的是EEGNet体系结构是否能够分离这些混淆事件。当特定的滤波器从模型中移除时,我们还对量化体系结构的分类性能感兴趣。
图6显示了四个滤波器的空间拓扑以及平均的小波时频差异,使用Morlet小波计算,计算所有目标试次和所有非目标试次。这里我们看到四个不同的滤波器出现。滤波器1的时频分析显示,图像呈现后大约500ms低频功率增加,随后alpha频率失同步。由于在P300数据集中几乎所有的被试都是右撇子,我们也看到了沿着左侧运动皮层的显着活动。滤波器2的时频分析显示出显着的theta-beta关系;虽然之前在P300文献中已经注意到theta活性的增加是对靶点的反应,但之前没有注意到theta和beta之间的关系。滤波器4的时频差异与P300相对应,图像呈现后低频功率增加约350ms。我们还进行了一项特征消融研究,在该研究中,我们迭代地删除了一组滤波器(通过用零替换滤波器),并重新应用该模型来预测测试集中的试次。我们对这四个滤波器的所有组合都这样做。消融研究的分类结果如表4所示。我们看到,删除任何单个滤波器对测试集性能的影响最小,在删除滤波器4时下降最大。正如预期的那样,当移除滤波器对时,性能下降更为明显,在移滤波器3和4时观察到的下降幅度最大。与完整模型相比,删除滤波器2和3实际上不会改变分类性能,这表明该任务中最重要的特征被滤波器1和滤波器4捕获。当三个滤波器被移除时,这一发现进一步加强了分类性能;与只包含滤波器2 (0.7108 AUC)或滤波器1 (0.7970 AUC)的模型相比,只包含滤波器4 (0.8637 AUC)的模型表现得相当好。
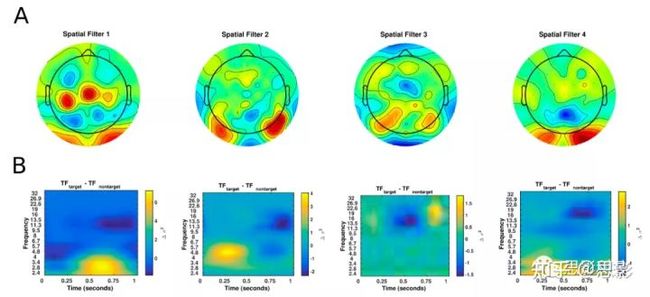
图6可视化来自EEGNet - 4,1模型配置的特性,用于P300数据集中一个特定的跨被试验证。(A)每个空间滤波器的空间拓扑图。(B)每个滤波器的目标和非目标试次的平均小波时频差异。

图7对于SMR数据集的被试3,从被试内训练的EEGNet - 8,2模型中获得特征的可视化。8列中的每一列都显示了一个0.25 s窗口的学习时间核(顶部)及其两个相关的空间滤波器(底部两个)。我们看到,虽然许多时间滤波器都隔离了慢波活动,但网络识别出一个高频率的滤波器,大约32Hz(时间滤波器3,在0.25秒的窗口中显示8个周期)。

图8 比较FBCSP在8-12 Hz滤波器组中对每个OVR类别组合学习的四个空间滤波器,(A)利用EEGNet-8,2学习的空间滤波器,(B)为SMR数据集的被试3捕捉12Hz频率活动的四个时间滤波器,我们看到,对于这个被试,类似的滤波器出现在FBCSP和EEGNet- 8,2中。
图7显示了为用于SMR数据集的被试3的被试内分类的EEGNet -8,2模型学习的滤波器。图中的每一列表示学习的时间kernel(上一行)及其两个相关的空间滤波器(下两行)。注意,我们正在学习长度为32个样本的时间滤波器,对应于0.25 s的时间;因此,我们估计每个时间滤波器的频率为观测周期数的4倍。这里我们看到EEGNet -8,2在大约12Hz的慢频率活动和大约32Hz的高频活动中都能学习.图8比较了EEGNet -8,2学习到的8 - 12hz频段的空间滤波器与FBCSP在8 - 12hz滤波器组中学习到的四个OVR组合中的每个空间滤波器。为了便于描述,我们将使用符号X-Y来表示行-列筛选器。在这里,我们看到许多滤波器是强烈的正相关的模型,虽然有些强烈负相关,表明类似的滤波器达到了符号模糊性(sign ambiguity)。
表4 性能的交叉学科训练EEGNet - 4,1模型,当从模型中移除某些滤波器时,然后使用该模型预测测试集的一个随机选择的折的P300数据集。粗体的AUC值表示每次删除一个、两个或三个滤波器时的最佳性能模型。随着删除的滤波器数量的增加,我们看到分类性能的下降,尽管下降的幅度取决于哪些滤波器被删除。

图9显示了使用DeepLIFT对MRCP数据集的一个跨被试的三个不同试次进行计算的EEGNet -8,2的单试次特征相关性。这里我们看到高置信度的预测(图9 (A)和(B),左和右的手指运动,分别)都正确显示对侧运动皮层相关性如预期的那样,而对于一个低的预测(图9 (C)),该功能相关性更广泛分布在时间和空间上。
图10显示了使用DeepLIFT对ERN数据集的一个测试被试的跨被试训练EEGNet -4,2模型分析特征相关性的另一个示例。Margaux等人之前注意到,正确反馈试次的平均ERP具有较早的峰值电位,对应于约325 ms,而错误试次的平均峰值电位发生稍晚,约475 ms。在这里,我们可以看到错误反馈试次(图10顶部一行的垂直线)和正确反馈试次(图10底部一行的垂直线)的峰值正电位的时间上的相同差异。我们还发现,这两类的DeepLIFT特征相关性与峰值正电位的相关性非常接近,这表明该网络将峰值正电位作为ERN分类的相关特征。这一发现支持了之前报道的结果,在那里他们显示了在峰值电位的振幅和错误检测的准确性之间有很强的正相关。

图9 (上行)针对MRCP数据集的三个不同测试试次,使用DeepLIFT对跨被试训练的EEGNet -8,2模型的单试次脑电图特征相关性:
(A)高置信度,正确预测了左手手指的移动;
(B)高置信度,正确预测了右手手指的移动;(C)低置信度,错误预测了左手手指的移动。标题包括真实的类别标签和该标签的预测概率。(下一行)两个时间点的相关性空间拓扑图:大约50毫秒和按下按钮后150毫秒。正如预期的那样,高置信度试次显示,分别按下左(A)和右(B)按钮时,对侧运动皮层对应的正确相关性。对于低置信度试次,我们看到相关性更加混合和广泛分布,没有一个明确的空间定位到运动皮层。

图10针对ERN数据集的一个测试被试,使用DeepLIFT对跨被试训练的EEGNet -4,2模型进行单试次脑电图特征相关性研究。
(第一行)对错误反馈的三个正确预测试次的相关性,及其预测概率p(第一行)与第一行相同。黑线表示在Cz计算的平均ERP,即错误反馈试次(上行)和正确反馈试次(下行)。细垂直线表示ERP平均波形的正峰值。在这里,我们看到特征相关性与每个试次的平均ERP波形的正峰值强烈吻合。我们也看到正的峰值出现得稍微早一些对于正确的反馈试次。
4 讨论
在这项工作中,我们提出了EEGNet,一个小型的卷积神经网络,用于基于脑电图的BCI,它可以在有限的数据存在的情况下泛化不同的BCI范式,并产生可解释的特征。我们通过四个EEG数据集:P300视觉诱发电位、错误相关负波(ERN)、运动相关皮层电位(MRCP)和感觉运动节律(SMR),对EEGNet与基于ERP和振荡的BCIs的最先进方法进行了评估。据我们所知,这是第一次验证跨多个BCI数据集使用单一网络架构的工作,每个数据集都有自己的特征和数据集大小。我们的工作介绍了使用深度和可分离卷积脑电图信号分类,并表明它们可以用来构建一个脑电图特定的模型,其中包含众所周知的脑电图特征提取概念。最后,通过使用特征可视化和消融分析,我们表明可以从EEGNet模型中提取神经生理学可解释的特征。最后这一发现尤其重要,因为它是理解CNN模型结构的有效性和鲁棒性的关键组成部分,不仅对EEG,而且对一般的CNN结构也是如此。
CNN的学习能力部分来自于它们从原始数据中自动提取复杂特征表示的能力。然而,由于这些特征不是由人类工程师手工设计的,理解这些特征的含义在生成可解释的模型方面是一个重大挑战。当cnn被用于脑电图数据的分析时,这一点尤其正确,因为神经信号的特征往往是非平稳的,并被噪声伪影损坏。在本研究中,我们展示了三种不同的方法来可视化EEGNet学到的特性:
(1)分析P300数据集上的空间滤波器输出,平均试次结果;
(2)可视化SMR数据集上的卷积核权值,并将其与FBCSP学到的权值进行比较;
(3)对MRCP和SMR数据集进行单试次相关性分析。对于ERN数据集,我们比较了单试次特征相关性和平均ERP,发现相关特征与正确和错误反馈试次的正峰值一致,这在之前的文献中已经表明与分类器性能呈正相关。此外,我们进行了一项特征消融研究,以了解分类决策对P300数据集上特定特征存在与否的影响。在每一项分析中,我们都表明EEGNet能够提取与已知神经生理现象相对应的可解释特征。
总体而言,DeepConvNet和EEGNet在所有跨被试分析中的分类表现相似,而DeepConvNet在几乎所有被试内分析中的分类表现较低(P300除外)。对这种差异的一种可能解释是用于训练模型的训练数据的数量;在跨被试分析中,训练集的大小大约是被试内分析的10-15倍。这表明,与EEGNet相比,DeepConvNet的数据密集型更强,考虑到DeepConvNet的模型规模比EEGNet大两个数量级,这一结果并不令人惊讶(见表3)。我们相信,这与DeepConvNet的开发人员最初报告的发现是一致的。他们指出,需要训练数据增强策略来获得对SMR数据集的良好分类性能。与他们的工作相比,我们表明EEGNet在所有测试数据集上表现良好,而不需要数据扩充,这使得模型在实践中更容易使用。
总的来说,我们发现,在被试内和跨被试分析中,ShallowConvNet倾向于在ERP BCI数据集上比在振荡BCI数据集(SMR)上表现更差,而在DeepConvNet上观察到相反的行为。我们认为这是由于ShallowConvNet架构专门设计用于提取频带特征;在主要特征是信号幅度的情况下(如许多ERP BCIs中的情况),ShallowConvNet的性能往往会受到影响。而DeepConvNet则相反;由于其架构的设计不是为了提取频率特征,所以在频率功率为主要特征的情况下,其性能较低。相比之下,我们发现EEGNet与ShallowConvNet在鼻中隔黏膜下切除术后的分类和DeepConvNet在ERP分类一样好,这表明EEGNet足够强劲的学习各种各样的功能范围的BCI任务。
鉴于MRCP和SMR之间的神经反应相似,ShallowConvNet在被试内MRCP分类上的严重不足是意料之外的,但ShallowConvNet在SMR上表现良好。这种表现上的差异并不是因为使用了大量的训练数据,因为被试内MRCP分类大约有700个训练试次,平均分布在左右手指运动中,而SMR数据集只有192个训练试次,平均分布在四个类别中。此外,在其他数据集(P300和ERN)上,我们没有观察到ShallowConvNet性能的大偏差。事实上,尽管该数据集是本研究使用的所有数据集中最小的(总共只有170个训练试次),但ShallowConvNet在被试内ERN分类方面表现得相当好。确定这一现象的潜在来源将在未来的研究中进行探索。
脑电图深度学习模型一般采用三种输入方式,取决于他们的目标应用程序:(1)脑电图信号的所有可用的通道,(2)变换后的EEG信号(通常是一个时频分解)的所有可用的通道或(3)变换后的EEG信号通道的一个子集。属于(2)的模型通常会看到数据维数显著增加,因此需要更多的数据或更多的模型正则化(或两者都需要)来学习有效的特征表示。这引入了更多必须学习的超参数,增加了由于超参数错误描述而导致的模型性能的潜在可变性。属于(3)的模型通常需要关于要选择的通道的先验知识。我们认为属于(1)的模型,例如EEGNet和其他模型,在输入维度和通过提供所有可用通道来发现相关特性的灵活性之间提供了最好的权衡。当BCI技术发展到新的应用程序空间时,这一点尤其重要,因为这些未来BCI所需的特性可能事先不知道。
总之,我们提出的EEGNet鲁棒性很好,表现很好,在多个数据集上可获得一系列可解释性特征。