关系抽取技术小结
目录
- 0. 前言
- 1.有监督神经网络方法
- 2.少样本学习
- 3.远程监督
- 参考文献
0. 前言
关系抽取是信息抽取领域的重要分支,是构建知识图谱的重要技术环节。本文介绍了关系抽取领域的三个主流研究方向:有监督学习、少样本学习和远程监督学习。
关系抽取(Relation extraction,RE)就是从非结构化文本中提取实体之间的关系。依据实体是否在文本中被标记,关系抽取方法可分为联合抽取和流水线式抽取。联合抽取是指从文本中完成实体识别和关系分类任务,流水线式抽取是指先使用实体识别模型识别文本中的实体对,然后判断实体对的关系。一个完整的流水线式关系抽取系统包括命名实体识别、实体链接和关系分类,本次调研限定关系分类方法。为了简述方便,下文中仍使用关系抽取表述指代关系分类。关系抽取模型大致可分为三类[1]:基于pattern的方法[2,3]、统计机器学习[4]和神经网络。其中神经网络方法效果更好,本文介绍的关系抽取方法以神经网络为主。依据抽取语料形式,关系抽取模型又可分为句子级关系抽取和段落级关系抽取。句子级关系抽取指两个实体在一个句子中,段落级关系抽取指两个实体不在同一个句子中。句子级关系抽取在实际业务中更常见,本次调研仅限于句子级关系抽取。按照关系类型是否预定义,关系抽取模型又可分为基于schema的关系抽取和开放关系抽取。前者是指实体对的关系只能从预先定义好的类别中选取,后者是指实体对关系没有限定。在构建领域知识图谱中,schema是固定的,因此实体对的关系类型是预定义的,本次调研针对基于schema的关系抽取。
神经网络可以从大规模数据中自动学习特征,此类方法的研究多集中在设计模型结构捕获文本语义。当前最好的关系抽取模型都是有监督模型,需要大量标注数据并且只能抽取预定义的关系。这种方法不能面对复杂的现实场景,例如少样本。目前已有不少工作探索在现实场景下的关系抽取任务,本文介绍三个研究方向:有监督神经网络方法、远程监督和少样本学习。
1.有监督神经网络方法
有监督神经网络方法是指采用深度学习方法在大规模有监督数据集上训练模型,此类方法是目前效果最好且研究最深入的。本文归纳总结了部分有代表性的模型结构,如图1所示,模型通常由输入层、编码层、注意力层和分类层组成。
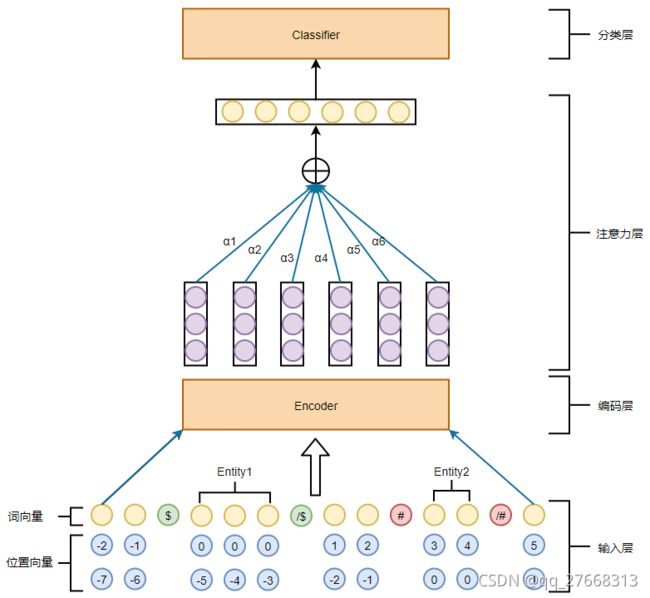
输入层将输入字符转化为向量。输入句子包含两个标记的实体,除去实体外的字符称为上下文。Peng Hao[5]分析了实体信息和上下文信息对关系抽取模型的重要度。实体信息包括实体类型、实体属性信息等,上下文信息是指上下文字符。作者通过实验发现,上下文信息和实体信息对关系抽取任务都提供了重要信息,只选用其中一种信息会导致模型性能下降严重,作者还观察到实体信息中最重要的是实体类型信息。实体位置信息对关系抽取任务同样很重要,在CNN模型中通常使用相对位置向量[6],在RNN模型中通常使用实体标记表示实体位置[7]。除了实体信息、上下文信息、实体位置信息外,其他比较重要的特征还有句子最短依赖树[8],依存句法特征[9]。编码层从输入向量中提取特征。早期使用CNN、RNN模型,Peng Hao[5]的对比结果表明这些模型的编码能力不足,目前主流使用BERT等预训练模型作为编码器。Wu[10]使用BERT+MLP结构取得了当时最好结果。句子中不同位置的字符对实体对关系分类的重要度不同,使用注意力方法对不同字符赋予不同权重。Zhang Yuhao[11]在注意力计算中加入位置信息,Wang Linlin[12]使用CNN模型抽取句子特征,并在此基础上增加了实体注意力和关系类别注意力。注意力层可有可无,在以CNN、RNN为编码器的模型中使用居多。分类层对编码层/注意力层输出的特征向量分类,主流使用MLP结构分类。损失函数一般有两种,交叉熵损失和排序损失。交叉熵损失计算过程简单,排序损失需要采样负样本,Santos[13]使用排序损失取得了比交叉熵损失很好的结果。有监督神经网络方法在大规模语料下取得了很好的效果,本文选取Wu[10]作为此类方法的baseline方法。Wu[10]使用位置标记表示实体位置,使用BERT作为编码器,按照分段池化的思想,根据实体位置将BERT输出分为三部分,然后池化拼接,使用MLP+softmax分类,取得了当时最好结果。
2.少样本学习
少样本是实际业务中经常遇到的问题,少样本是指只有很少的标注数据提供给模型训练。神经网络方法在大量高质量标注数据上具有很好的效果,但在少样本场景下效果很差。少样本学习是专门针对少样本场景提出的方法,少样本关系抽取有很多解决方案,例如meta learning[14,15]、transfer learning[16,17]、prototypical network[18]等,其中prototypical network效果最好且模型简单,本文主要介绍prototypical network在少样本关系抽取中的应用。
Prototypical network对每一个类别的所有样例特征向量求均值,将这个均值作为该类别的prototype。对测试样例进行预测的时候,计算测试样例特征向量和这些prototype的距离,距离最近的prototype对应的类别作为该样例的类别。如图2所示,C1,C2,C3表示prototype,x表示测试样本,其他颜色小圆圈表示训练样本,不同颜色表示不同关系类别。

少样本方法训练过程和常规的模型训练稍有不同,少样本训练过程是将训练集分成train-support和train-query两部分,模型将train-support中每个样本编码成一个向量,然后对每类关系的所有样本向量求均值,将这个均值向量作为该类别的prototype,类似于聚类中心。然后从train-query中选取query样本,模型将query样本编码成向量,计算该向量与每个prototype的距离,选取距离最近的prototype对应的关系类别作为该query样本的关系类别,损失函数一般选用欧式距离。
原生prototypical network在计算prototype时使用全部数据,无法解决train-support中样本标注错误问题。Tianyu Gao[19]提出使用Instance-level attention从训练数据中筛选与query相关的样本计算prototype,从而减少错误样本的影响。少样本带来的另一个问题是有用特征稀疏。每个样本能提供的有用特征本来就少,再加上每个类别的样本数量不多,导致prototype中对判别关系有用的特征少,称之为特征稀疏。Tianyu Gao[19]使用feature-level attention从prototype中选择有效特征,从而减少特征稀疏的影响。ZhiXiu Ye[20]使用和Tianyu Gao[19]类似的方法,在prototype形成过程中加入query的注意力,取得了更好的效果。
Soares[21]想训练一个通用关系抽取模型,类似于BERT这样的通用语言模型。作者将句子中的实体对使用``[blank]’'代替,将实体mask的目的是让模型更加关注于上下文,通过上下文来判断句子对是否包含相同关系类型,而不是利用实体推断。将mask后的句子称为relation statement。使用BERT在relation statement数据集上预训练,然后在有实体的数据集上训练,效果好于直接在有实体的数据集上训练,尤其是在少样本数据集上效果明显。基于这个方法,作者训练一个relation statement编码器用于学习relation statement向量表征。如果两个relation statement表达相同的关系,那么等于1,否则等于0。训练数据来源于远程标注,使用Wikipedia作为文本库,wikidata为知识库。两个句子含有相同实体对则标记为正例,否则为负例。作者共远程标注了6亿条数据。在实际操作中,并不是每个实体都被mask,而是根据一定概率,这类似于BERT对token的mask。
Soares[21]中的模型使用预训练方法在少样本数据集上取得很好的效果,但是预训练是一件非常困难的事情,需要大量数据、显卡和训练技巧。ZhiXiu Ye[20]在FewRel1.0数据集上取得了仅次于Soares[21]的分数,且模型简单无需额外数据。
3.远程监督
训练强大的关系抽取模型需要更多的高质量数据,但是构建这样的数据集需要大量人工标注,耗时费力。Mike Mintz[22]首次使用远程监督方法生成标注数据,远程监督的假设是:如果两个实体有关系,那么任何包含这两个实体的句子都可以表达这种关系。例如,Ra{e1, e2}表示实体e1和e2具有关系Ra,若存在一个句子同时包含e1和e2,则认为该句子表达了关系Ra,将该句子标注为关系Ra的一个正样本。使用这种方法只需一个知识库和一个文本库便可自动得到标注数据。远程监督似乎是一种解决监督数据不足的完美解决方案,但实际上远程监督数据存在如下问题:1)并非所有同时包含e1和e2的句子都可以表达关系Ra,因此数据集中存在大量标注错误问题;2)无法解决一对实体含有多关系的情况;3)False negative问题,标记为负样本的实例实际存在关系,但这种知识在知识图谱中不存在,导致标记错误。第二个问题是远程监督无法解决的问题,因为在知识图谱中两个节点间只能存在一条边,所以无法建模一对实体存在多个关系的情况。第三个问题可以通过更好的生成负样本方式缓解,例如选择包含两个明显不存在关系的实体对的句子作为负样本。第一个问题是最严重的,目前大量的研究多集中于此,本文接下来介绍目前的主流解决方案。
缓解远程监督数据噪声有三种方法:1)多实例学习,从多个实例中选择最有效的实例作为训练样本;2)使用外部信息选择有效实例;3)使用复杂的模型和训练方法,例如soft label、增强学习、对抗学习。
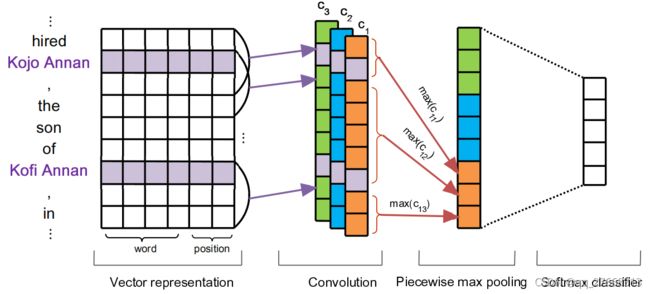
多示实例学习 Riedel[23]放松了远程监督假设,将任务建模为多实例学习问题。多实例学习的假设是:如果实体对存在某种关系,那么包中至少有一个句子反映了该关系。这里的包是指由存在该实体对的所有句子组成,即一个实体对对应一个包。如何从包中选择最能反映关系类别的句子作为训练样本是多实例学习的核心问题。在PCNN[24]模型中,作者使用CNN+softmax计算包中每个样本的分类得分,选择得分最高的样本作为该包中最能反映关系类别的样本。PCNN模型是关系抽取中常用的编码器,用于抽取句子特征,模型结构如下图所示。依据两个实体的位置,将句子分割为三个片段,左边部分包含了左边实体信息,中间部分包含了两个实体信息,右边部分包含了右边实体信息。对全局进行池化操作无法捕获这种结构信息,因此作者分别对三部分进行池化操作。
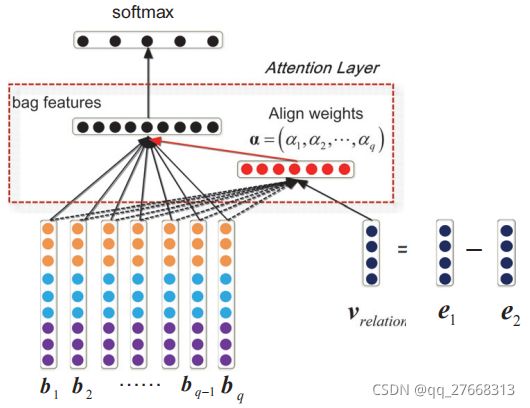
Yankai Lin[25]认为PCNN模型只选用包中一个句子作为训练样本会导致训练不够充分,因为包中可能存在多个句子都能有效表达关系,只用一个样本会遗漏其他样本所表达的特征。因此,作者使用选择性注意力对包中所有句子学习权重,对能够表达该关系的句子赋予高权重,无法表达该关系的句子赋予低权重。包中所有句子特征向量加权得到包的向量表征,使用包向量表征完成最终的关系分类。使用外部信息如果一个实例表达了某种关系,那么该实例的句向量应该和这种关系的特征向量相似度很高。基于这种想法,许多研究人员开始使用关系特征向量参与选择有效实例。这种方法首要解决的问题是如何获取关系的向量表征。 Han xu[26]借鉴TransE的思想,直接使用知识图谱中训练得到的关系向量表征。随后在此基础上改进,使用多任务学习方法,联合学习关系抽取和知识图谱知识表[27]。Guoliang Ji[28]利用Wikipedia中实体的描述文本训练得到实体向量,然后两个实体向量相减得到关系特征向量。模型结构如图3所示,bi表示包中第i个实例向量,由PCNN模型编码得到。使用关系特征向量v计算实例向量bi权重,实例向量加权得到包的向量表征。
复杂网络有部分学者引入增强学习[29,30]和对抗训练[31,32]完成关系抽取。减少远程监督数据中的噪声是正确的研究方向,但是目前的远程监督方法效果并不好,精确率和召回率都很低,在主流benchmark上F1值在0.6左右。在第十三届全国知识图谱与语义计算大会CCKS2019任务3中,最好成绩的F1值仅0.54。远程监督方法的低效目前还难以应用在实际业务中。
参考文献
[1] Xu, Han and Tianyu, Gao and Yankai, Lin and Hao, Peng and Yaoliang, Yang and Chaojun, Xiao and Zhiyuan, Liu and Peng, Li and Maosong, Sun and Jie, Zhou. More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction. arXiv. 2020.
[2] Meng, Jiang and Jingbo, Shang and Taylor, Cassidy and Xiang, Ren and Lance, M. Kaplan and Timothy, P. Hanray and Jiawei, Han. Metapad: Meta pattern discovery from massive text corpora. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pages 877–886. 2017.
[3] Zheng, Shun and Yu, Peilin and Chen, Lu and Huang, Ling and Xu, Wei. DIAG-NRE: A Deep Pattern Diagnosis Framework for Distant Supervision Neural Relation Extraction. pages 1419-1429. 2018.
[4] Sachin Pawar and Girish K. Palshikar and Pushpak Bhattacharyya. Relation extraction: A survey. arXiv. 2017.
[5] Hao, Peng and Tianyu, Gao and Xu, Han and Yankai, Lin and Peng, Li and Zhiyuan, Liu and Maosong, Sun and Jie, Zhou. Learning from Context or Names? An Empirical Study on Neural Relation Extraction. EMNLP. Association for Computational Linguistics. 2020.
[6] D, Zeng and K, Liu and S, Lai and G, Zhou and J, Zhao. Relation Classification via Convolutional Deep Neural Network. CoLING. 2014.
[7] Dongxu, Zhang and Dong, Wang. Relation Classification via Recurrent Neural Network. arXiv. 2015.
[8] Yang, Liu and Furu, Wei and Sujian, Li and Heng, Ji and Ming, Zhou and Houfeng, Wang. A Dependency-Based Neural Network for Relation Classification. ACL. Association for Computational Linguistics. 2015.
[9] Shu, Zhang and Dequan, Zheng and Xinchen, Hu and Ming, Yang. Bidirectional Long Short-Term Memory Networks for Relation Classification. Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation. 2015.
[10] Shanchan, Wu and Yifan, He. Enriching Pre-trained Language Model with Entity Information for Relation Classification. CIKM. 2019.
[11] Yuhao, Zhang and Victor, Zhong and Danqi, Chen and Gabor, Angeli and Christopher, D. Manning. Position-aware Attention and Supervised Data Improve Slot Filling. EMNLP. Association for Computational Linguistics. 2017.
[12] Linlin, Wang and Zhu, Cao and Gerard de Melo and Zhiyuan, Liu. Relation Classification via Multi-Level Attention CNNs. ACL. Association for Computational Linguistics. 2016.
[13] Cícero dos Santos and Bing, Xiang and Bowen, Zhou. Classifying Relations by Ranking with Convolutional Neural Networks. ACL-IJCNLP. Association for Computational Linguistics. 2015.
[14] S Ravi and H Larochelle. Optimization as a model for few-shot learning. ICLR. 2016.
[15] Chelsea Finn and Pieter Abbeel and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. ICML. 2016.
[16] Yoshua Bengio. Deep learning of representations for unsupervised and transfer learning. ICML. 2012.
[17] Rich, Caruana. Learning many related tasks at the same time with backpropagation. NIPS. 1995.
[18] Jake, Snell and Kevin, Swersky and Richard S, Zemel. Prototypical Networks for Few-shot Learning. NIPS. 2017.
[19] Tianyu, Gao and Xu, Han and Zhiyuan, Liu and Maosong, Sun. Hybrid Attention-Based Prototypical Networks for Noisy Few-Shot Relation Classification. AAAI. AAAI Conference on Artificial Intelligence. 2019.
[20] ZhiXiu, Ye and ZhenHua, Ling. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics. Florence, Italy. pages 2872–2881. 2019.
[21] Livio Baldini Soares and Nicholas, FitzGerald and Jeffrey, Ling and Tom, Kwiatkowski. Matching the Blanks: Distributional Similarity for Relation Learning. ACL. Association for Computational Linguistics. 2019.
[22] Mike, Mintz and Steven, Bills and Rion, Snow and Daniel, Jurafsky. Distant supervision for relation extraction without labeled data. ACL-IJCNLP. Association for Computational Linguistics. 2009.
[23] Sebastian, Riedel and Limin, Yao and Andrew, McCallum. Modeling relations and their mentions without labeled text. ECML PKDD. 2010.
[24] Daojian, Zeng and Kang, Liu and Yubo, Chen and Jun, Zhao. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. EMNLP. Association for Computational Linguistics. 2015.
[25] Yankai, Lin and Shiqi, Shen and Zhiyuan, Liu and Huanbo, Luan and Maosong, Sun. Neural Relation Extraction with Selective Attention over Instances. ACL. Association for Computational Linguistics. 2016.
[26] Xu, Han and Pengfei, Yu and Zhiyuan, Liu and Maosong, Sun and Peng, Li. Hierarchical Relation Extraction with Coarse-to-Fine Grained Attention. EMNLP. Association for Computational Linguistics. 2018.
[27] Xu, Han and Zhiyuan, Liu and Maosong, Sun. Neural Knowledge Acquisition via Mutual Attention between Knowledge Graph and Text. AAAI. AAAI Conference on Artificial Intelligence. 2018.
[28] Guoliang, Ji and Kang, Liu and Shizhu, He and Jun, Zhao. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. AAAI. AAAI Conference on Artificial Intelligence. 2017.
[29] J, Feng and M, Huang and L, Zhao and Y, Yang and X, Zhu. Reinforcement learning for relation classification from noisy data. AAAI. AAAI Conference on Artificial Intelligence. 2018.
[30] X Zeng and S He and K Liu and J Zhao. Large scaled relation extraction with reinforcement learning. AAAI. AAAI Conference on Artificial Intelligence. 2018.
[31] Yi, Wu and David, Bamman and Stuart, Russell. Adversarial training for relation extraction. EMNLP. Association for Computational Linguistics. 2017.
[32] Xu, Han and Zhiyuan, Liu and Maosong, Sun. Denoising distant supervision for relation extraction via instance-level adversarial training. arXiv. 2018.