Learning-based feature matching and pose estimation
基于深度学习的特征匹配与位姿估计
- 1. Learning-based feature matching(基于深度学习的特征匹配(可直接应用于SFM、SLAM、视觉定位))
-
- 1.1. Motivation
- 1.2. Feature matching pipeline
- 1.3. Why deep learning?
- 1.4. What is deep learning?
- 1.5. How to use deep learning to solve feature matching?
-
- 1.5.1. Learning-based detectors
-
- 1.5.1.1. What is a detector?
- 1.5.1.2. What is a good detector
- 1.5.1.3. How to use CNNs
- 1.5.1.4. 损失函数怎么定义?
-
- 1.5.1.4.1. Uniqueness
- 1.5.1.4.2. Repeatability
-
- 1.5.1.4.2.1. L2 loss
- 1.5.1.4.2.2. SuperPoint
- 1.5.1.5. Performance comparison
- 1.5.2. Learning-based descriptors
-
- 1.5.2.1. What is a descriptor?
- 1.5.2.2. CNN-based descriptors
- 1.5.2.3. Training descriptors
- 1.5.2.4. Learned vs. handcrafted
- 1.5.2.5. 基于深度学习得到descriptors的方式对图像旋转平移比较敏感的问题及改进
- 1.5.2.6. Application in visual localization
- 1.5.2.7. Where is training data from?
- 1.5.2.8. Camera pose supervision
- 1.5.3. Learning-based matchers
-
- 1.5.3.1. What is matcher?
- 1.5.3.2 . Problem with RANSAC
- 1.5.3.3. Use deep net to predict which match is good
- 1.5.3.4. 基于RANSAC和基于深度学习的方法的对比
- 2. Learning-based object pose estimation(基于学习的物体6DOF位姿估计)
-
- 2.1. Problem definition
- 2.2. Traditional approaches
-
- 2.2.1. Iterative matching
- 2.2.2. Feature matching
- 2.2.3. Template matching
- 2.3. Challenges for traditional methods
- 2.4. Recent advances: deep learning
- 2.5. Deep learning for object pose estimation
- 2.6. New approach to old ideas
-
- 2.6.1. Using Convolutional Neural Networks for iterative matching
- 2.6.2. Using Convolutional Neural Networks for template matching
- 2.6.3. Using Convolutional Neural Networks for feature matching by semantic keypoint detection
- 2.7. Limitations of heatmap representation
- 2.8. PVNet: pixel-wise voting network for 6dof pose estimation
-
- 2.8.1. Vector-filed representation of keypoints
- 2.8.2. Uncertainty-aware PnP
- 2.8.3. Quantitative comparison
- 2.8.4. Comparison to direct regression
- 3.0. Summary
-
- 3.1. Most 3D vision problems boil down to correspondence problems
- 3.2. Deep nets are good at learning better representations, resulting in better correspondences
- 4.0. Discussions
1. Learning-based feature matching(基于深度学习的特征匹配(可直接应用于SFM、SLAM、视觉定位))
1.1. Motivation
问题:给我一堆二维场景的图像或视频,希望场景出场景的三维模型,并且算出相机相对于模型的位置与姿态。
如何解决这个问题?
解决上述问题的原理很简单——多视图几何原理。
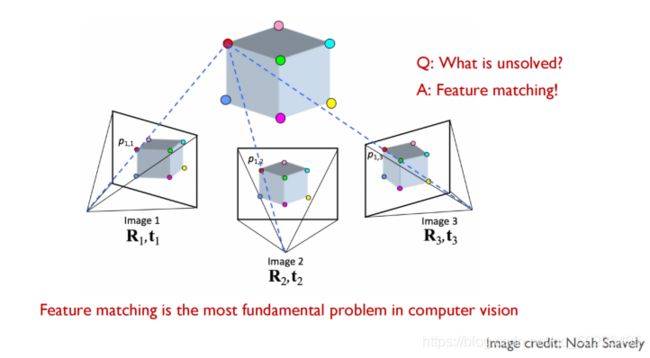
即如上图,如果我们两张图像里面特征点的匹配关系(或对应关系),那么我们就可以根据多视几何原理去算出相机之间的相对位姿,同时也能够三角化去得到空间三维点的位置。这样我们就可以重建点云,同时也能算出相机的位姿。
Feature matching is the most fundamental problem in computer vision.
1.2. Feature matching pipeline
传统特征匹配的pipeline:
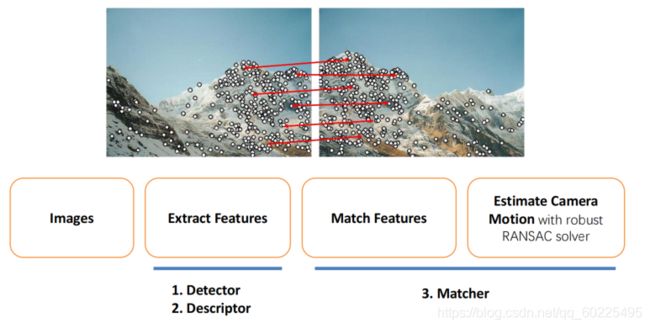
给定两张图像,我们希望能建立图像间特征点的点到点之间的对应关系。我们一般的流程是:给我一张图像,我首先提取出特征,这里的提取特征包含两层的含义:
1、检测特征点,即确定特征点的位置
2、构造特征点的描述子
而得到特征点的位置及其描述子之后,我们就可以比较两张图像的特征,算它们之间的距离,来匹配特征,然后就能得到特征点之间的关系。这些匹配关系会用来干嘛呢?
一般我们会用来算Fundamental matrix,得到相机的相对位姿。实际上在求相机位姿的过程中,我们也有一个几何约束——Epipolar Constraint(对极约束),故如果一对点是正确的匹配关系的话,左图的某个点在右图上的对应点应落在Epipolar上。我们也可以用这样的几何约束反过来,在我们的求解过程中,去掉一些不对的初始匹配,得到更好匹配结果。
特征点匹配过程目前用得最多的是RANSAC。
无论是用最近邻的方法去两个点的对应关系,还是用RANSAC去删掉一些错误的点,我们这个过程一般可以称为Matcher。
1.3. Why deep learning?
传统的特征匹配方法,无论是检测特征点还是构造特征点的描述子,基本上还是一个人工设定的方式。如DoG的detectors或者SIFT的descriptors,都是人工去构造的,故它会有一些局限:
1、目前的描述子大多还只是去描述了图像局部几何特性,而没有语义的信息,即这种人工设计的特征的表达能力是有限的。这会导致在一些没有纹理的区域,描述子不能很好地描述,故不能实现很好地匹配。
2、此外它们是人工设定的,它们会对一些环境的变化非常敏感,如当拍摄的两张图像视角变化比较大时,传统的特征不能很好地匹配。
另外,早上和傍晚,当两张图像的亮度(光照影响)发生了很明显地变化时,传统的特征可能也不能很好地匹配。
再一个就是运动模糊问题。当运动模糊时,图像里面很多特征就糊掉了,此时传统几何的特征点可能也不能很好地构建匹配关系。

1.4. What is deep learning?
我们来对比一下传统的SIFI特征匹配和基于深度学习的特征匹配方法SuperPoint的特征匹配结果:

我们可以看到,SuperPoint在这种亮度变化比较大的情况下,结果好很多。
什么是深度学习?

我们这里讨论的主要是深度的卷积神经网络。卷积神经网络是由很多卷积层构成的,即我输入一个图像,对该图像不停的做卷积(Convolutions),然后中间会夹着一些降采样(池化、pooling)的过程,以及其他一些非线性变换(如:relu)的操作过程。
而对于图像分类的问题,因为我们最后希望得到的是图像对应的各个类别的可能性,它可以用向量表示,所以最后我们可能还会有一个全连接层,把上图卷积之后的结果变成一个对于各个类别的分数。
上图有个概念要注意——Feature maps,它实际上是,每次做完卷积之后,所输出的一个相应的图,基本上代表了卷积层里面各个Feature,各个卷积核在图像中不同位置的响应,这个响应图我们称为Feature maps,即特征图。
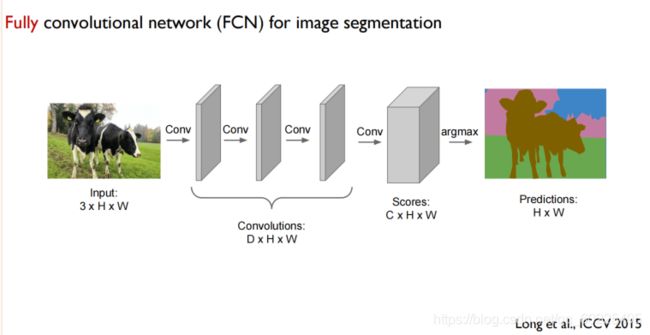
然后,卷积神经网络除了用来做分类任务,它还可以应用于图像分割。这是输出的就不是关于各个类别的分数,而是跟原图同样大小的语义标签图,此时我们不需要全连层,我们从头到尾都是一个卷积的操作即可。如下图,这样的网络叫全卷积网络——FCN。
**对深度学习直白的解释:**它是一个很通用很强大的函数拟合器。这个函数拟合器是可以学习的,它有很多可以学习的参数,所以它实际上就是一个有一些参数控制的可以学习的函数(如 f w f_w fw),如下图,我们可以把我们的输入变成我们想要的输出。

这里的参数w,在卷积神经网络里面基本上是卷积核的权重(w is network parameters (weights of convolutional filters))。
那么我们如何得到这个参数呢?这个过程即网络的训练(我们希望找到最佳的网络权重,使得我们可以最小化一个损失函数):

损失函数一般定义为,在对训练的数据上,我们一般有它的标签(即,我们希望得到的输出 y i y_i yi),那么就把网络域层输出( f w ( x i ) f_w(x_i) fw(xi))与希望得到的输出 y i y_i yi进行比较,算它们之间距离l或者误差,再把这个距离或误差在所有的样本上加起来,即可得到总的损失函数。
那么,我们只需要把网络参数w作为变量去最小化损失函数,就能得到网络最佳的一组参数,然后用这组参数去对新的样本/图像进行预测,这就是网络训练的流程。
那么什么要用深度学习呢?简单来说,深度学习为我们提供了一种端到端的学习方式。从数据里面去学习我们想要的东西,如,在特征匹配里,深度学习可以帮助我们从大量的数据选取我们希望的特征,或者具有满足我们应用所需的这些特征。
那怎么去设计一个深度学习的方法呢?
我们基本上只要去定义4个东西:输入输出的形式( input, output),损失函数(loss),训练的数据(data),设计网络的结构(architecture)。我们本章主要讨论:对于某个问题,它的输入输出是什么?损失函数怎么定义?训练数据从哪来?
1.5. How to use deep learning to solve feature matching?
怎么用深度学习去解决特征匹配问题?
整个特征匹配的流程主要即3步:检测特征点(detector)、构造特征点的描述子(descriptor)、Matcher。
故这里我们主要讨论:基于深度学习的detector、基于深度学习的descriptor、基于深度学习的Matcher。
1.5.1. Learning-based detectors
1.5.1.1. What is a detector?
detector的输入就是一张图像,输出即特征点的位置。
Example: Harris corner detector(角点检测器):
1、首先去算图像里面的梯度,每个像素点关于x、y两个方向的导数。
2、在以这个点为中心的邻域范围内,计算每个像素周围一个窗口中的协方差矩阵H,即大概就能判断这个点有没有可能是一个角点。
3、根据以上,可以算出检测器响应值(Detector response),即在可能是角点的地方,响应值会比较大,不是角点的地方,响应值比较小。

4、在得到如上的响应图之后,会设置一个阈值Threshold
5、最后通过非最大值抑制(nonmaximum suppression (NMS)),就可以对每一个响应值比较大的区域确定一个点,作为我们最后的特征点。
这样我们就能够得到我们希望检测的一些角点(特征点)。如下图所示:

1.5.1.2. What is a good detector
怎样才算是一个好的特征检测器?
1、特征检测器所得到的点具有唯一性。
如下图,蓝色方框目前所在的区域是不是一个好的特征点呢?显然不是!因为它不具有唯一性,无论该蓝色窗口是往上、下、左、右移动,我们所看到的图像都是一样的,没有任何的变化,所以该窗口里面的图像和它周围的图像没什么区别,故它不具有任何特征,不具有唯一性。
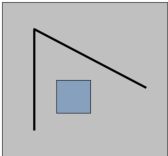
下图,对于蓝色窗口中的点,它也不具有唯一性,也不是一个好的特征点。(虽然左右移动时图像会发生变化,但沿着黑线上下移动时,并不会发生变化,故不具有唯一性)
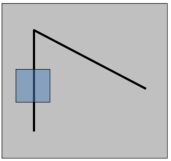
一般来说,下图所示的角点是很好的特征点,且具有唯一性。(蓝色窗口无论往那个方向移动,窗口内看到的内容都会发生变化),这也是我们经常用Harris corner detector去检测角点的原因。

总结:一个好的检测点,它需要有比较好的唯一性。有了唯一性,我们在特征匹配时才不会具有歧义性(至少局部是唯一的),我们才可以做一个很好地定位。
2、检测点需要具备可重复性(不变性)
可重复性:我需要匹配下面两张图,对于这两张图去检测特征点的话,得到的这两组点应该是重复的。
那什么样的检测器才能检测到下面左右两张图像的特征点是可重复的呢?这个检测器用在图像上得到的响应图对于图像的变换是不变的。即,图像发生几何变换时(如拍摄两张视角不同的图像),对于对应的检测点响应是不变的,那么我们就能在两张图像上检测出同样的点,从而保证该检测点在两张图像上具有可重复性。

而上述所说的图像变换一般有如下几种:
1、图像亮度值变换(Photometric transformation),如下图:

2、几何变换(Geometric transformation)
如旋转(Rotation):

如缩放(Scale):

我们希望无论图像怎么变,检测器用上去之后,对于变换前和变换后的图像上的同样的点的响应是一样的。这样就可保证检测点的可重复性。
那么Harris corner detector是否具有不变形?
答:对于Rotation,是具有不变性的。但是对于Intensity change和Scale,变换前图像中的Harris corner检测点和变换后图像中的Harris corner检测点是会发生改变的。
传统手工设计的detector,都不能保证检测点的唯一性和不变性。所以我们是否可以使用深度学习的方法来帮助我们构造更好的detector?
1.5.1.3. How to use CNNs
如何使用CNNs检测图像中的特征点呢?
首先我们要构造特征点位置的表示方式:
1、基于热力图(Heatmap):输入一张图像,通过卷积神经网络之后,输出的是热力图,热力图上亮度大的地方就代表有可能有一个特征点,经过NMS之后就能得到这个特征点的准确位置,如下图(来自MagicPoint),绿图就是我们传统detector的响应图(或者称为Heatmap)。但Heatmap有时候比较糊,导致特征点定位不是很准确。

2、如下图(来自KP2D),输出是(b)图那样的格子(即把图像划分成格子),对于每一个格子,我们假设里面只会有一个输出的特征点,而网络预测的是图像里每个像素到特征点的位移(截距),那么所有的点,所有的像素都输出这样的位移的话,则根据投票就可以找到最困可能的特征点在哪。
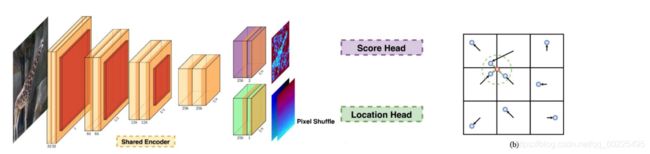
以上两种方式是比较适合卷积神经网络进行输出的。对于用神经网络去做特征检测,输入的是图像,输出的是特征点的位置(有上述两种表示方式:Heatmap和基于格子的offset)。
1.5.1.4. 损失函数怎么定义?
上述说了,我们希望最后得到的特征点具有两个性质:1、唯一性,2、可重复性。
那么我们在构造损失函数的时候,自然也希望损失函数可以帮助我们去引导神经网络,使得所输出的特征点具有这俩性质。
1.5.1.4.1. Uniqueness
**对于特征点的唯一性,**我们知道,图像里面的角点比较可能具有唯一性,那么我们就可以训练我们的神经网络,使得网络去检测和输出角点。
那么首先,我们需要训练数据。对于角点检测训练数据,需要给定图像和角点的位置。但是对于一般的图像,我们并没有这样的标注。故现在一般会用合成的数据,我们去合成一些形状(如下图(来自MagicPoint))。因为是合成的,所以知道角点的位置,把这些合成的图像当做训练数据来训练网络,使网络的输出就是这些角点的位置。

那此时,损失函数如何定义?需要最小化网络输出的特征点的位置 p t ∗ p_t^* pt∗和我们希望生成的ground truth的角点的位置之间的距离 p t p_t pt,用这样的损失函数我们就可以训练我们的网络,使得网络输出的点跟ground truth的角点非常接近。

我们来看看MagicPoint训练之后的效果:最左图是Synthetic Shape Dataset,最右图是Detection results。
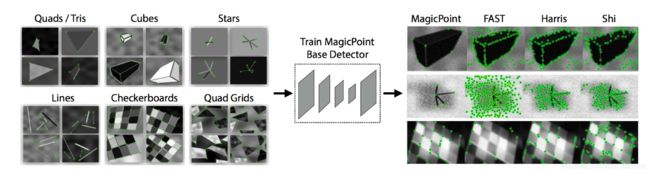
我们可以看到,对于下图这样的形状(黑桌子),MagicPoint都可以输出真实图像的角点,而对于传统方法,我们会得到含有大量噪声的特征点,它们会在图像里面梯度比较长的地方,但不在角点上,故会影响后续的特征匹配。而如果我们能输出非常干净的角点的话,后续特征匹配的难度会降低。

1.5.1.4.2. Repeatability
1.5.1.4.2.1. L2 loss
对于输出的特征点,我们也希望它具备可重复性。那么如何保证可重复性呢?
我们也可以在网络训练时,设计一个损失函数。如:下面有两种图像:

我们把上面两幅图像分别通过网络f,让网络输出两组特征点,如果我们知道图像之间的变换是什么样的,实际上就知道,对与下图第一张图的点在第二张图里落在哪里。

我们直接利用这个信息,就可以与上图网络的预测算一个差值,来使得网络的输出是可重复的。也就是说(如下图),在左下图中的网络输出(右下图),应该是正好能通过已知的变换后对应到右上图的特征点。

即我们能通过这样两张图像之间约束(损失函数)(如下图),就可以使得网络输出的点具有可重复性。
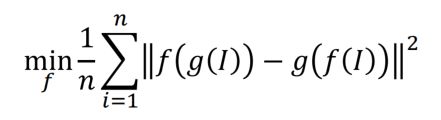
我们需要知道点到点之间的ground truth,才能做训练。得到训练数据一般有两种方式:
1、通过合成,即,给我一张图像,我认为地加一个变换上去,如单应变换,那么我们就知道对于第一张图像里面任意一个点,在第二张图像里应该在什么地方,我们就有这个ground truth,就可以训练网络。但这种变换是假设的,它不一定能解释我们真实的世界,如三维造成的一些透视的效果。

2、那么如何使用真实的数据去训练呢?
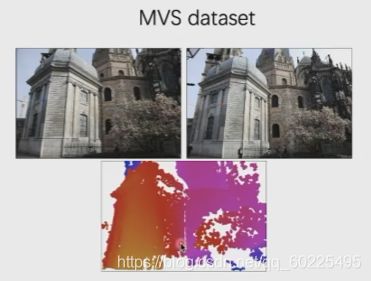
一般我们需要用到MVS的数据集(如下图)。通过MVS,我们能得到图像的深度图。有了深度图之后,即得到图像二维点的深度值。我们可以根据把第一张图里面任何一个二维点结合其相应的深度,即可获得该二维点的三维空间位置。根据第二张图相机的位姿,我们就可以把第一张图结合深度值所获得的三维空间点投影到第二张图像上。这样我们就能得到,对于第一张图像中的点在第二张图像中对应的位置。
1.5.1.4.2.2. SuperPoint
SuperPoint也提出了一种保证网络输出的特征点具有可重复性的方式(通过homographic adaptation来提高网络输出的特征点的可重复性)。

上图,假设有个初始的基于神经网络的detector。给定任意一张图像(Unlabeled image),把该图像先通过一些人为的单应变换,得到一些变换后的图像(Warp images),然后把初始的detector用在这些图像上,得到了各个图像下所检测的特征点(Point Response),这些点可能不具有可重复性,此时我们把所有点(或所有响应)都加到一起,这样就相当于得到了在原始的detector、在各种变换下的和,即相当于Aggregate Heatmap这个响应是考虑了所有变换的,故该Heatmap对于图像的变换是具有比较好的一致性、可重复性。用interest Point Superset这一组新的点集去训练(Self-supervised training)一开始的Base Detector,这样就可以改进网络输出的特征点的可重复性,所得到的新的detector就叫SuperPoint。
1.5.1.5. Performance comparison
我们可以看到,2020年,SuperPoint霸榜了:(CVPR20 Image Matching Workshop Leaderboard)
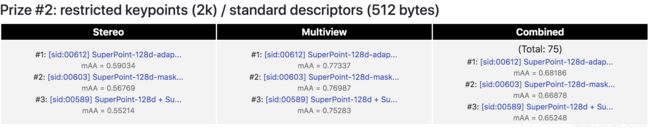
当然有些不仅仅使用了SuperPoint,还有一个叫SuperGlue的特征匹配方法。
那么SuperPoint为什么会表现地很好呢?
首先,SuperPoint有一个初始的Base Detector,这个初始的Base Detector就是我们之前提到的MagicPoint。MagicPoint是通过角点来训练的,所以它有较好的唯一性。
然后,SuperPoint通过Homography adaptation来增强了MagicPoint的可重复性。
故最后我们得到的Detector既具有比较好的唯一性又具有较好的可重复性。
1.5.2. Learning-based descriptors
接下来介绍一下基于深度学习的descriptor。
1.5.2.1. What is a descriptor?
在得到特征点的位置之后,对于每个特征点都希望构造一个描述向量,这就是descriptor。比如说,传统的SIFI(如下图)。descriptor实际上就是一个向量,来描述特征点的性质。

怎样才算是一个好的descriptor?
首先得具有比较好的辨识性。如果某个特征点的descriptor全是0的话,则没有表示该特征点的任何特征,也没法去建立对的匹配。
其次,好的descriptor同样需要对图像的变换有一定的不变性。比如我先拍摄一张图像,换了个视角再拍一张图像,我希望两张图像对应的点上的descriptor是一样的。
实际上,传统的descriptor,如SIFI这样的descriptor,对于几何变换,它还是有一个比较好的性质(唯一性,不变性)的。因为在构造SIFI时会根据Rotation或Scale去做一些归一化。但是传统的descriptor往往不具备很好地辨识性或表达能力,故在某些情况下,效果比较差,尤其是光线变化大的图像进行匹配时会出现问题。
1.5.2.2. CNN-based descriptors
那我们如何用深度学习的方法去改进descriptor?
或者说,怎么用卷积神经网络去得到特征点的描述子呢?
1、已知特征点的位置后,可以把它周围的图像块截出来,然后让该图像块通过神经网络,输出一个descriptor。
但这种方式有个问题,比如效率问题。需要对每个特征点都做一个截取的操作,然后通过神经网络,最后才得到descriptor。这样的操作比较慢。
2、最近的方法是生成一种稠密的descriptor,如下图,即输入一张图像,让该图像通过全卷积这样的网络。每次卷积之后会得到特征图,故全卷积之后我们会得到很多张特征图,这个特征图在空间上是跟原来输入的图像是对齐的,当然分辨率可能不一样,分辨率不一样的话可以通过插值的方式使它跟原来图像的分辨率一样,那么我把所有这些feature match里面对应到某一个像素的响应值串在一起,就可以得到一个向量,这个向量实际上就能够表示原始输入图像的的点的性质或特征。我们实际上就可以用这个feature match的值来作为一个descriptor,来帮助我们进行特征匹配。
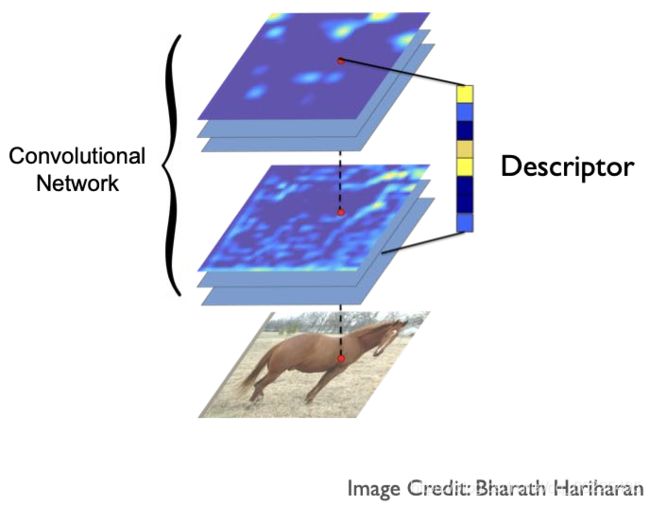
我们可以看到,这种方式对于一张图像,我们只需将它过一次卷积神经网络,就可以得到所有点的descriptor。所以效率会比较高。以下是使用了该方法的一些Examples:
• LIFT [Yi, 2016]
• UCN [Choy, 2016]
• GeoDesc [Luo, 2018]
• SuperPoint [DeTone, 2018]
…
1.5.2.3. Training descriptors
这样的话,我们就可以使用卷积神经网络去得到所有descriptor,那么我们如何训练这个网络,使得网络输出的descriptor能满足唯一性、不变性?
现在常用的训练方式如下:

中间长方体网络是一样的。把两张自由女神图都经过长方体网络,然后输入图像上两个绿点在经过神经网络之后会得到两个特征(或描述子descriptor),如果这两个点他们是真的匹配的话,我们希望他们descriptor的距离(右边绿线)能够变小。那如果对于两个不匹配的红点,我希望红点经过神经网络之后,所得到的描述子descriptor之间的距离变大。
这就是现在常用的一种训练方式,或者构造损失函数的方式。
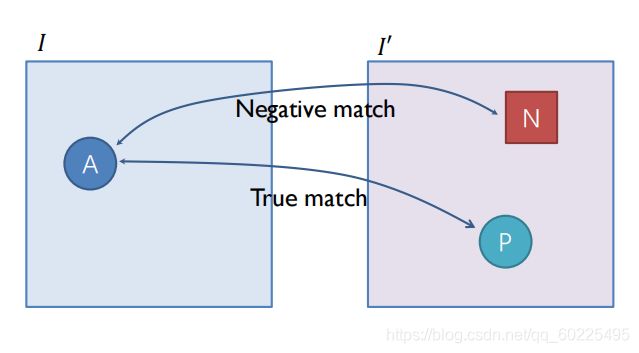
现在一种常用的损失函数叫Contrastive loss,即如上图,假设A和P是训练数据中正确的匹配,那么我们希望A和P的descriptor能尽量接近(最小化他俩的距离):
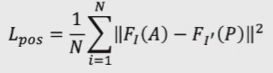
而对于A和P错误的匹配,如A和N,他们不是正确的匹配。我们希望他们descriptor的距离能够尽量的大:

同时,当他们距离大到一定程度的时候(如大于阈值m),就丢掉N。如下图。

故对于Contrastive loss,其实就包括两部分: L ( p o s ) L_(pos) L(pos)与 L ( n e g ) L_(neg) L(neg)。
Triplet loss
不是考虑两两的关系,而是考虑3个点的关系。如下图,这3个点就包括左边图像的点A,以及右边图像两个点P、N,这两个点一个是正确的匹配点、一个是错误的匹配点。然后比较点A与P、N之间的距离(AP之间的距离尽可能小;AN之间的额距离尽可能大,知道超过阈值m),这就叫Triplet loss。

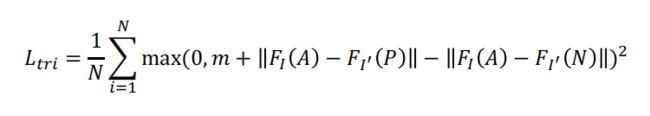
实际上这两种损失函数目前也经常会用,差别不大。但目前来说,Contrastive loss用得多一些,因为它训练时稳定性更好。
1.5.2.4. Learned vs. handcrafted
我们来看看下图基于学习的描述子与传统方法的描述子之间的对比:
当上图两幅图像的光线变化比较大时,SuperPoint比传统方法所能得到的正确特征匹配点的数量更多。但SuperPoint也有一个问题,当两幅图像视角变化比较大时(如下图,左右两图像是同一张图像,只是旋转角度不同),这时SuperPoint的效果比不过SIFT和ORB。

1.5.2.5. 基于深度学习得到descriptors的方式对图像旋转平移比较敏感的问题及改进
故,这种基于深度学习的方法,对于旋转以及图像缩放这样的几何变换,目前还不够稳定,如下图:

当图像旋转或缩放程度比较小时,特征匹配的效果比较好;当图像旋转或缩放程度比较大时,特征匹配的效果比较差。
为什么CNNs对图像的旋转这么敏感?
卷积神经网络的主要操作就是卷积,我们知道卷积对图像的平移是具有不变性的(如下图一)。但它对于旋转,则不具备不变性(下图二)。
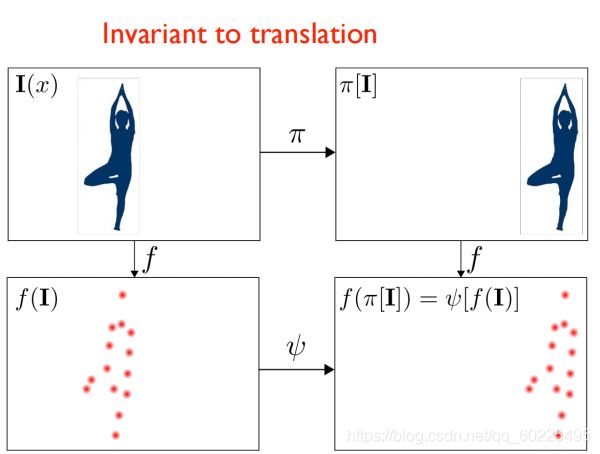

由上图二可知,当小孩在转时,整个feature match(右上、下图)会跟着转,但是对应的同一个点上面的feature也会发生一个不可预测的变化(这个点的 descriptors的也会发生不可知的变化),此时拿这个旋转后的图像跟旋转前的原图作匹配时,肯定会出错。
为了解决这个问题,有人在训练的过程中提出了了一种特征描述子——GIFT,它能比较好地解决图像旋转、缩放的问题。
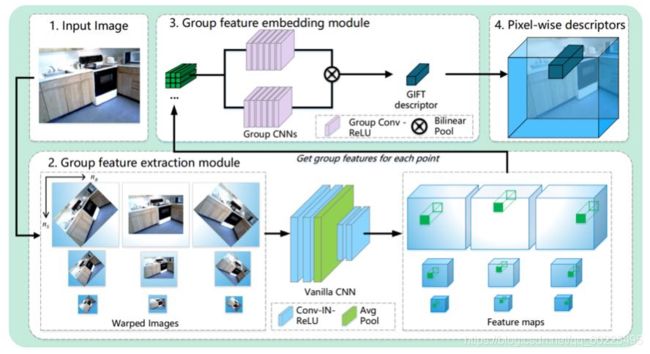
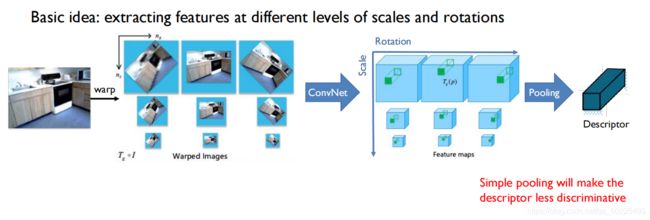

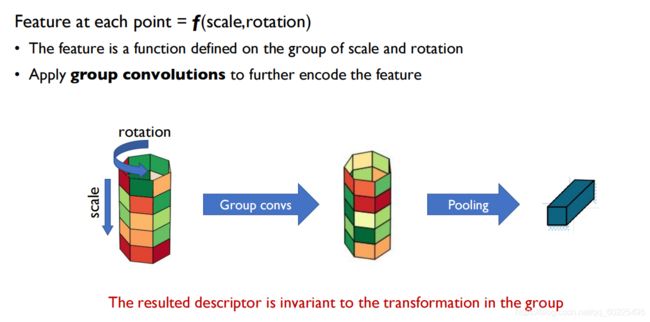
由上图,它的基本思想是把所有的图像做很多变换,再把变换后的图像通过神经网络,得到在各个变换下的描述子,再把这些描述子通过一个全卷积的方式组合在一起,得到唯一的描述子。可以理论上证明这个描述子对输入图像的旋转以及缩放具有不变性。
GIFT和SuperPoint的对比:在旋转和缩放变化比较大的情况下,GIFT效果还是要好很多的。
下图是对于缩放程度的稳定性:我们可以看到,传统的SIFT这条绿线还是比较稳定的;而SuperPoint这条蓝线在图像缩放比较小时,比SIFT要好很多,但scale较大时,SuperPoint的稳定性下滑很快;但GIFT还是相对比较稳定的。

下图是对于旋转的稳定性:

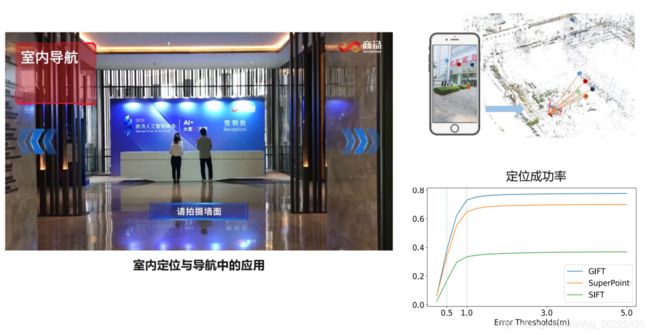
1.5.2.6. Application in visual localization
1.5.2.7. Where is training data from?
对于描述子的深度学习,其训练数据(图像、特征点的真实位置)从何而来?我们需要的训练数据是什么呢?
答:
给我两张图像,我们有他的ground truth的匹配关系。
第一种得到训练数据的方式:
就是用SFM数据集或者MVS的数据集。如果通过SFM或MVS重建好了,我们把重建好的三维点投影到各个视角下图像里面去的时候,我们就能知道他们是否是同一组点,同时也即知道他们之间的对应关系。但这种方式的问题在于它是基于传统方式重建的,所有会存在bias(偏差)。如基于SIFT matching重建,对于SIFT matching搞不定的那些点,重建结果里面可能就忽略了,也即不可能在这些被忽略的点上面进行训练。所以基于这样的方式训练,我们训练出来的神经网络会有上限。

第二种得到训练数据的方式:
在图像上施加一个人为的变换,因为是人为的变换,所以我知道图像是怎么变换的,所以就能得到ground truth的对应关系。但这种方式的问题主要在于我们能够生成的变换都是一些平面内的一些变换(如homography),但是对于真正的三维的透视变换,我们是没法去考虑的。

1.5.2.8. Camera pose supervision
为了解决上述问题,去年ECCV的一个工作中就提出,我们能不能不用点到点之间的对应关系来训练我们的网络。如果只知道两张图像的相对的相机位姿能不能训练descriptors。我们知道相机的位姿比点到点之间的对应关系更容易得到,如用SFM,或者IMU这种sensors就能得到相机的相对位姿。

那么如何用相机的位姿作为监督呢?
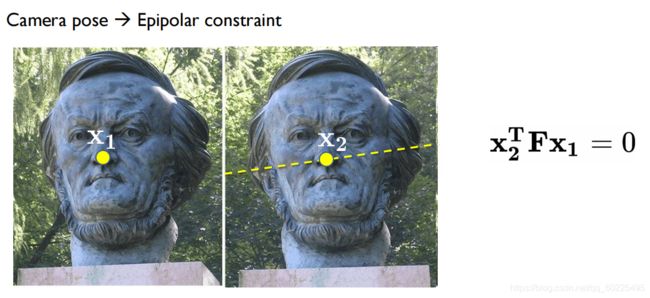
如果已知两张图像之间相机位姿,那么我们就知道Epipolar constraint(即,对于下图左图的 x 1 x_1 x1在右图中的对应点 x 2 x_2 x2一定会位于黄色虚线(极线)上)。
那么如何用这种约束来训练我们的网络呢?
比如,对于下图左图的那一个黄点,右图也在经过卷积神经网络输出之后,与左图黄点相对应的那个红点应该在右图极线上。如果红点不再极线上,我们就算以下红点与极线的距离,以该距离作为一个损失函数来训练我们的卷积神经网络。同时还有一个可以利用的性质就是,对于右图红点,它在左图里面,网络输出的匹配应该就是左图黄点,如果不是黄点,而是蓝点,则匹配错误。我们可以利用左图黄点和蓝点之间的距离作为损失函数。这叫回路一致性(Cycle consistency loss)。用这两个损失函数,我们就能得到一个很好的训练结果。

以下是一些匹配的结果:
demo:
前面已经介绍了如何利用卷积神经网络去选取detectors和descriptors,那么剩下的就是如何匹配detectors和descriptors。
1.5.3. Learning-based matchers
1.5.3.1. What is matcher?
给定两组特征点以及他们的描述子,建立他们之间的对应关系。一般分两步:
1、首先用一些比较简单的方法(如:最近邻)建立一个初始的匹配,找当前图像中每一个点在另外一张图像里面,跟它描述子最接近的那个点,以该点作为当前图像中对应点的匹配。这样的匹配比较简单,所以容易出错(因为descriptors不一定对)。

2、在1、的基础上,用RANSAC寻找inliers。

但RANSAC有两个问题:
1.5.3.2 . Problem with RANSAC
1、当错误的匹配特别多时,RANSAC可能就不管用了(一般大于50%的错误匹配时,RANSAC不管用)
2、RANSAC非常耗时,尤其当错误匹配很多时。因为RANSAC不停地做iterations,直到找到一个比较好的解,所以会导致收敛的速度非常慢。
1.5.3.3. Use deep net to predict which match is good
所以最近也有一些讨论:能不能用神经网络去替代RANSAC。
其基本想法是:首先给定一些初始的匹配,能否直接用一个神经网络去帮我们判断哪些匹配是好的,哪些匹配不好。

这里所用到的神经网络就跟我们之前的CNN就不一样了,因为之前无论是detectors还是descriptors,其输入都是图像,所以使用CNN的话,效果比较好。但在matcher环节,我们的输入是一些初始的匹配,匹配是两幅图里面对应点的位置,而不是二维的图像,故没法使用CNN去处理matcher。
我们一般使用Deep Net、 PointNet这样的神经网络来进行特征匹配。这些网络的输入可以是离散的点。我们可以把每一对匹配( ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_1,y_1),(x_2,y_2) (x1,y1),(x2,y2))当成一个四维空间的一个点,然后我们两幅图像里面有很多这样的匹配,即有很多这样的点,用PointNet去处理这些点,希望PointNet帮我们预测这堆的分数是多少。
故在特征匹配时,我们一般会使用PointNet,其实PointNet的本质就是一个全连的网络MLP:

1.5.3.4. 基于RANSAC和基于深度学习的方法的对比
我们可以看到,在RANSAC不能work的情况下,基于深度学习的方法还是能够得到很好地匹配结果。
以上讲的都是给定初始的匹配,去训练一个网络,帮我们判断匹配好不好,这里有个问题在于:初始匹配决定了网络的上限。假设初始匹配都很差,训练出来的网络也不可能返回对的点。
去年的SuperGlue这个基于深度学习的匹配方法,它不是从初始的匹配开始,它不需要通过最近邻来获取初始匹配,而是直接从需要匹配的两对特征点(红蓝点)开始,用这些特征点去构成graph:
然后再在graph上面,应用graph neural network (GNN,图网络)来帮我们从graph里面找到并留下正确的边(正确的边的意思是指边两端的红蓝点是一个正确的匹配)。这样的话就不需要用传统的方法得到初始的匹配了。我们直接从特征点构成graph,然后通过图网络直接端到端地输出最后的特征匹配关系(这个GNN是可以端到端训练的)。
Top1 approach in Visual Localization Benchmark, Image Matching Benchmark.
SuperGlue demo:

上面的no SuperGlue应该是用了 RANSAC的匹配方法,能找到的正确匹配很少。
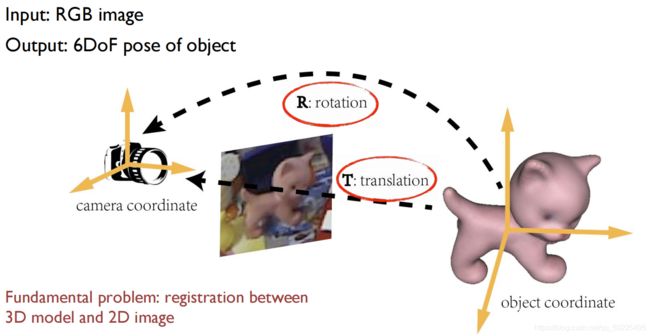
2. Learning-based object pose estimation(基于学习的物体6DOF位姿估计)
2.1. Problem definition
给定图像,希望得到物体相对于相机的6自由度位姿,跟后续帖子要说的三维物体跟踪是一模一样的。
2.2. Traditional approaches

2.2.1. Iterative matching

- Initialize a pose
- Render the 2D silhouette of the object with current pose
- Update the pose to minimize the edge distance
- Iterate until convergence
即,不停地优化位姿参数,使得投影到图像里面的轮廓与图像里面检测的边缘能够很好地拟合。
2.2.2. Feature matching

- Find 3D-2D correspondences. e.g. using feature matching
- Solve R and t by perspective-n-point (PnP) algorithm
采用PNP,如果知道空间三维点与图像二维点的对应关系,那么我们就可以用PNP的算法来求解出位姿。
2.2.3. Template matching
最后这一种是基于模板匹配的,即对于一个物体的三维模型,在所有的视角下都绘制成二维图像(Templates with known poses),然后把这些图像跟新的图像(Query image)作匹配,看跟哪张图像最接近,如果找到了对的匹配,则直接用模板中的匹配图作为测试图像(Query image)的姿态(Pose):

- Render template images from the 3D model
- Compare query image with template images
Similarity computed with global features, e.g. Gradient response map (Hinterstoisser, 2012)
2.3. Challenges for traditional methods

传统的方法一般在纹理弱、背景杂乱、运动模糊等情况下不太稳定。所以现在也有越来越多的深度学习的方法来解决物体位姿估计的问题。
2.4. Recent advances: deep learning
2.5. Deep learning for object pose estimation
其基本方式即,给定一张图像,我们先检测图像中的物体(如下图的小狗),然后对小狗这个物体做位姿估计:
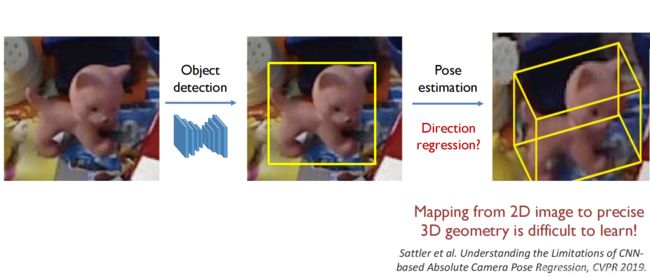
对于物体检测,现在深度学习有很多非常好的检测器——YOLO,SSD等等。所以物体检测这一个问题目前基本都可以很好地解决。、
所以接下来的问题是如何用深度学习去估计物体6自由度的位姿。
其中的一种方式是我们把物体(黄框)截取出来,让其通过一个网络,让黄框直接回归旋转矩阵和平移的参数。
但这种方式并不是最好的。因为,实际上,从一个二维图像到一个精确的几何量(如旋转矩阵)的映射关系是非常复杂的,很难用神经网络去学习的。Sattler et al. Understanding the Limitations of CNNbased Absolute Camera Pose Regression, CVPR 2019.这篇文章里面有提到这一点。
所以我们现在一般的基本思路是:用深度学习去改进传统的方式。
2.6. New approach to old ideas
2.6.1. Using Convolutional Neural Networks for iterative matching
直接用网络去估计每次姿态参数应该如何更新,相当于用网络去估计在iterative matching里面的参数的梯度,而不是用我们之前的损失函数算出位姿参数。(DeepIM: Deep Iterative Matching for 6D Pose Estimation. Li et al. (CVPR 2018))

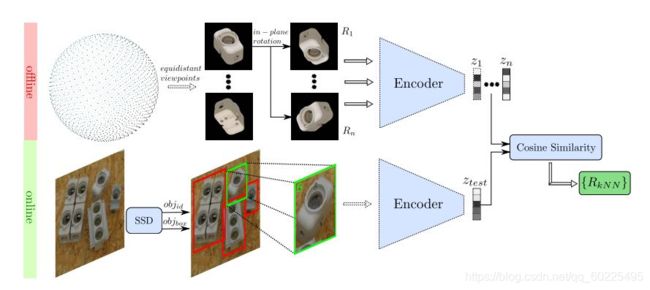
2.6.2. Using Convolutional Neural Networks for template matching
在template matching时,以前是把模板图像与测试图像进行比较,可能是基于一些传统的特征,现在可以使用深度神经网络所提取的特征去进行匹配:(Implicit 3D orientation learning for 6D object detection from RGB images. Sundermeyer et al. (ECCV 2018))
2.6.3. Using Convolutional Neural Networks for feature matching by semantic keypoint detection
对于基于特征点匹配获取物体位姿的方式,以前可能使用SIFT来matching。而现在我们可以用基于深度学习的特征点和特征描述子来进行matching,然后再用PNP就可以得到物体的位姿。
但还有一种更简单的方式: 实际上可以在物体三维模型上面定义一些关键点(如猫的耳朵、脚、尾巴),然后直接用神经网络去估计关键点在图像中的位置(直接去检测这些关键点,不需要构造descriptors去匹配),就得到了三维到二维的对应关系,有了这个对应关系我们就可以求解PNP,算出R和t:

demo:
实际上也可以把这种基于检测的方法和秦老师所讲的基于跟踪的方法结合到一起,那么我们既可以非常稳定的检测三维物体,给物体位姿一个准确初始值,同时又使用跟踪的方法,得到一个比较稳定的跟踪结果。
那么基于这种特征点检测,有何难点呢?
2.7. Limitations of heatmap representation
1、当物体被遮挡(如下图的猫),那么有些关键点就不可见了,故很难去检测:

2、所要检测的物体不全在图像里面,此时对于图像外面的这些关键点,很难检测到。尤其我们之前的关键点检测一般是基于热力图来表示。

那么如何解决这个问题呢?去年提出了一种关键点的向量场表示:PVNet: pixel-wise voting network for 6dof pose estimation. CVPR 2019
2.8. PVNet: pixel-wise voting network for 6dof pose estimation
2.8.1. Vector-filed representation of keypoints
即我们如何表示下图外面的红叉点的位置呢?

我们所提出的表示方式就是,对于每一个像素,我们都有一个二维的向量,这个向量指向红叉关键点,那么各个像素的向量指向的交点(下图星点)即我们图像外的那个关键点(红叉)。也即,如果想检测上图红叉点,我们可以把上图输入到一个全卷积网络,让网络输出下图这样的向量场,然后基于向量场即可定位到上图的红叉点(对应下图的星点),这样就提升了在遮挡或截断情况下,图像关键点检测的稳定性。


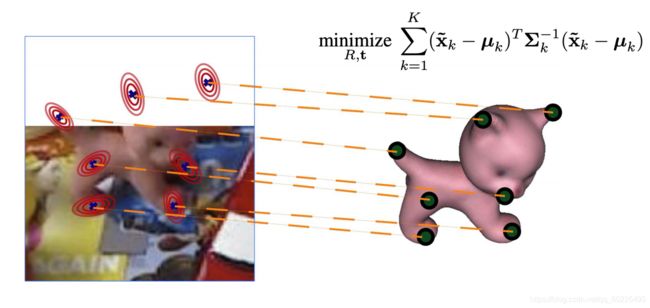
2.8.2. Uncertainty-aware PnP
2.8.3. Quantitative comparison

2.8.4. Comparison to direct regression
如果直接用网络去回归物体位姿的参数的话(如下图的PoseCNN),效果往往不好。而用PVNet,结果好很多。

当然稳定性没办法跟tracking(跟踪)的方法相比,但是基于检测的方法实际上可以作为跟踪方法的初始化。也即,我们去检测第一帧或者一些关键帧,然后用基于检测的方法得到物体位姿,然后再接下来的帧里面使用基于边缘或者秦老师介绍的一些方法去跟踪它,知道跟丢了,我再检测物体位姿。这样即保证稳定性,又可以得到比较平滑的结果。
3.0. Summary
3.1. Most 3D vision problems boil down to correspondence problems
三维视觉里面很多问题都是在找对应关系的问题。比如在SFM里面,我们希望首先建立二维到二维这样的对应关系;在位姿估计或者视觉定位里面,我们希望得到三维模型和二维图像之间点到点的对应关系;在点云的匹配与注册里面,我们希望得到的是三维到三维点之间的对应关系。
所以我们可以看到,解决三维视觉这些问题的基本数学原理(几何原理)都已经很成熟了。为什么还是不能很好地解决三维视觉中的一些问题?关键还是在特征匹配或对应关系上。
3.2. Deep nets are good at learning better representations, resulting in better correspondences
而深度学习有一个比较好的地方,它可以用数据驱动的方式,从数据里面去选择一个很好的表示方式。有了更好地表示方式,有了更好地特征,我们就能去建立特征匹配关系。
4.0. Discussions
我们用深度学习帮助我们解决以上问题时,到底是应该就使用端到端的方式去构造一个网络,让她输出我们想要的东西(如,相机位姿);还是还是基于传统的这一套系统,采用深度学习去改进里面某些部分,比如说特征匹配这一部分。
那种方式更好?后者更有希望。
我们前面也比较了对于物体位姿估计的问题,我们直接回归,效果其实很不稳定,但是在PNP的基础上去改进特征匹配,我们得到的结果就会比较好。故基于传统几何的方式更加可解释,且会有比较好的泛化能力。且实际上我不需要去学习所有的东西,故需要的训练数据也更少。
实际上除了上述介绍的(用深度学习改进特征匹配,用深度学习去改进PNP里面如何建立三维到二维的对应关系),在最近的工作中,还有很多用深度学习去改进各种传统SLAM模块的方法。
如DSAC,它相当于用深度学习去实现了RANSAC。(之前在matching部分提到过)
如Diff. Triangulation,三角化我们也可以用深度学习去做。
如DeepMVS,Stereo也可以用深度学习去做。(目前基于深度学习的MVS很火)
如BA-Net,Bundle Adjust也可用深度学习的方法去做。
