tensorflow跑fashion mnist数据集全过程(利用Jupyter内含源码详细解析)
目录
- TensorFlow2.0.0安装
- fashion mnist数据集详细实现过程
-
- 导入模块
- 导入数据集
- 查看数据集
- 构建模型
- 查看模型
- 模型训练
- 绘制曲线
- 参考
- 转载请注明出处
TensorFlow2.0.0安装
(1)在win10中,打开cmd,查看自己的驱动
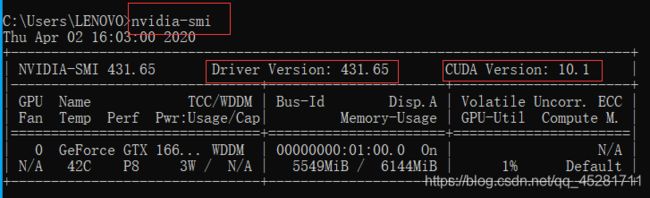
(2)在安装tensoiflow之前请先安装Anoconda。
(3)本人电脑驱动版本大于410,故使用一条命令就可安装(打开cmd)
conda install tensorflow-gpu==2.0.0
接下来一路选择yes既可以。
(4)检查GPu版本的TensorFlow是否安装成功
#打开cmd
jupyer notebook
在浏览器中弹出如下界面

import tensorflow as tf
tf.test.is_gpu_available()

fashion mnist数据集详细实现过程
希望你已经成功安装了TensorFlow,若有错误多看看其他的安装博客,不要灰心呀!!
接下来这一部分是本文的重点!!请仔细查看,如有错误请及时指出,谢谢
导入模块
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl,np,pd,sklearn,tf,keras:
print(module.__name__,module.__version__)
本人电脑导出的结果如下:
(如果和本人版本不一致的,请注意下面的代码可能和你的版本有出入,请百度)

导入数据集
#导入数据集
fashion_mnist = keras.datasets.fashion_mnist
#拆分训练集和测试集
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
#将训练集再次拆分为训练集和验证集
x_valid, x_train = x_train_all[:5000],x_train_all[5000:]
y_valid, y_train = y_train_all[:5000],y_train_all[5000:]
#打印验证集、训练集和测试集(numpy格式)
print(x_valid.shape,y_valid.shape)
print(x_train.shape,y_train.shape)
print(x_test.shape,y_test.shape)
注意:我第一次导入的时候没成功,但是查看电脑的数据集位置,分明已经完成导入了,于是我重新把这四个文件删除又导入了一遍,NICE!!成功了。。。

成功后显示:

查看数据集
#了解数据集结构,展示出一张数据集的图像
def show_single_image(img_arr):
plt.imshow(img_arr,cmap="binary")
plt.show()
show_single_image(x_train[0])
运行结果:

#显示多张图片
def show_imags(n_rows,n_cols,x_data,y_data,class_names):
assert len(x_data)==len(y_data)
assert n_rows*n_cols < len(x_data)
plt.figure(figsize=(n_cols*1.4,n_rows*1.6))
for row in range(n_rows):
for col in range(n_cols):
index = n_cols*row+col
plt.subplot(n_rows,n_cols,index+1)
plt.imshow(x_data[index],cmap = "binary",interpolation="nearest")
plt .axis("off")#不显示坐标尺寸
plt.title(class_names[y_data[index]])
plt.show()
class_names = ['T-shirt','Trouser','Pullover','Dress','Coat','Sandal','Shirt',
'Sneaker','Bag','Ankle boot']
show_imags(3,5,x_train,y_train,class_names)
显示结果:

构建模型
注意:要格外的关注下方的算法,本人第一次使用的算法是sgd,训练出来的accuracy一直不超过10%,很是纳闷,看了其他人的想法,改用adam后好一些,各位老哥还可以用一下RMSProp算法,多多尝试一下哈,本人也是小白,有大哥也可以给俺指点一下!
#构建模型
#tf.keras.Sequential
model = keras.models.Sequential()
#输入层:将输入矩阵[28,28]展平为一维向量
model.add(keras.layers.Flatten(input_shape = [28, 28]))
#全连接层;单元数设置为300;activation就是激活函数
model.add(keras.layers.Dense(300, activation="relu"))
#全连接层;单元数为100
model.add(keras.layers.Dense(100,activation="relu"))
#输出层;因为我们的输出结果是10个类别的分类,故模型输出应该是长度为10的概率分布
model.add(keras.layers.Dense(10,activation="softmax"))
# relu:y = max(0,x) ; 即 输入为一个x,当x大于0,输出为x;否则输出为0。
# softmax:将向量变为概率分布。
# 即将 x = [x1,x2,x3] -> y = [e^x1/sum, e^x2/sum, e^x3/sum] ,sum = e^x1 + e^x2 + e^x3
#loss后为损失函数,为何用spars?因为上面的x_value和y_value一一对应!
#optimizers 是选择用哪种算法(可以选 sqd、adam、rmsprop),这个关系到后面训练的loss和accuarcy
model.compile(loss = 'sparse_categorical_crossentropy',optimizer = 'adam',
metrics = ['accuracy'])
查看模型
(1)
#模型有多少层
model.layers
运行结果:

(2)
#模型的架构
model.summary()
运行结果:

(3)模型分析
#[None, 784] * W(w是指矩阵) + b(b是指偏置) -> [None, 300] ;
#其中w,shape [784,300],b = [300].
模型训练
#epochs 后是训练次数;valiation_data是验证
history = model.fit(x_train,y_train,epochs=10,validation_data=(x_valid,y_valid))
运行结果:

绘制曲线
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize = (8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
plot_learning_curves(history)
运行结果:

参考
文章上述内容,均来自互联网整理,及本人观看教程视频整理,若有侵权请联系立即删除!
如有错误请及时指出!!对你有帮助的话,那就点个赞吧(码字也不易啊)
深度学习小白,欢迎讨论!!
转载请注明出处
https://blog.csdn.net/qq_45281711/article/details/105272293