孪生神经网络_Fewshot Learning(小样本学习) 之Siamese Network(孪生神经网络)
在往期的神经网络中,我们训练样本的时候需要成千上万的样本数据,在对这些数据进行收集和打标签的时候,往往需要付出比较多的代价。比如我们需要采集某个型号的设备开启时一段时间内的信号,那么我们需要对该种型号的设备,开启成千上万次,才能采集到那么多电信号用来训练,这无疑对我们的设备造成损害。因此,使用更少的样本学习到更多的特征,成为机器学习所追求的目标之一。 常说的one-shot learning和few-shot learning,都是指的是通过一个及少量的样本习得模型,然后具有分类的能力。
“one shot learning aims to learn information about object categories from one, or only a few, training samples/images” --wiki
所以说 one-shot learning 和 few shot learning 中的one 和few指的是在学习分类过程中,training samples 的数量。比如我们上一节讲的电信号分为九类,one-shot,那么就是有9个样本,每个类别一个,few-shot 就是每个类别多于一个样本,到极端情况下,我们会碰都某些类别中有0个训练样本,那么这种极端情况叫做zero-shot learning。 像这种小样本学习,他们的判别方法是通过判断进来的类型是否为同一类来作为分类的方法,在测试的时候,通过将待测数据通过习得的模型,来进行分类。 所以在训练的时候,我们也需要同时输入进去不同的样本个体,而对应的y值,分别用0和1来表示,如果输入模型中的样本为同一类那么y值为0如果不是同一类那么y值为1。通过这样的方式,我们可以减少样本训练时所需要的样本量。 而siamese neural network (孪生神经网络)使用了两个之前讲过的卷积神经网络,来作为两个样本的输入,从而搭建出小样本学习框架。“few-shot learning is refers to the practice of feeding a learning model with a very small amount of training data, contrary to the normal practice of using a large amount of data.” --Dr.Michael J.Garbade
可以简单理解为下图:“A siamese neural network (sometimes called a twin neural network) is an artificial neural network that uses the same weights while working in tandem on two different input vectors to compute comparable output vectors." --wiki

一、导入包和数据
import osimport csvimport pandas as pdimport kerasimport numpy as npfrom keras.models import Sequential,Modelfrom keras.layers import Dense, Activation, Flatten, Convolution1D, Dropout, MaxPooling1D, Inputimport timefrom datetime import datetimefrom keras import backend as Kfrom keras.layers.core import Lambda, Flatten, Densepath=r'E:\ilm\train_data'files=os.listdir(path)二、处理数据使之变为两个vectors(向量),并设好y值。(这步有点技术)
column_names=[]train=pd.DataFrame()for item in files: data_frame=pd.read_csv('E:/ilm/train_data/'+item) data_frame['mins']=range(len(data_frame)) data_frame=data_frame.drop(['Unnamed: 0'],axis=1) data_frame=pd.pivot_table(data_frame,columns=['mins']) train=train.append(data_frame)train=train[:140]train.reset_index()train1=train.sort_index()train2=train1.groupby(train1.index).head(9)train2=train2.groupby(train2.index).head(9)
x=np.array(train2)x_right=xfor i in range(len(x_right)-1): x_right=np.concatenate((x_right,x))print(x_right.shape)x_left=[]for i in range(len(x)): for j in range(len(x)): x_left.append(x[i])x_left=np.array(x_left)print(x_left.shape)
matrix_l=81y=[]count=0for i in range(matrix_l): for j in range(matrix_l): y.append(1)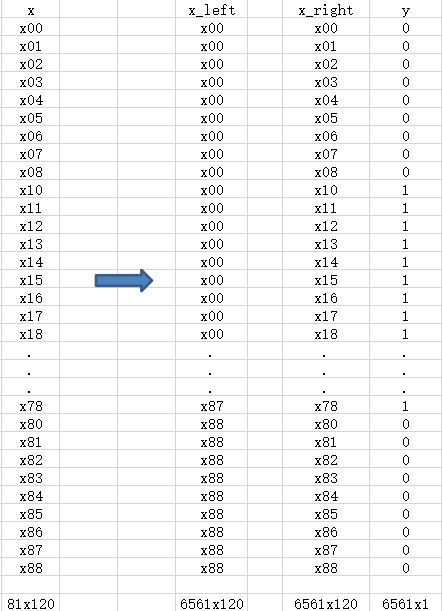

group=9for i in range(matrix_l): if i%group==0: for j in range(i*matrix_l+i-0,i*matrix_l+i+9): y[j]=0 if i%group==1: for j in range(i*matrix_l+i-1,i*matrix_l+i+8): y[j]=0 if i%group==2: for j in range(i*matrix_l+i-2,i*matrix_l+i+7): y[j]=0 if i%group==3: for j in range(i*matrix_l+i-3,i*matrix_l+i+6): y[j]=0 if i%group==4: for j in range(i*matrix_l+i-4,i*matrix_l+i+5): y[j]=0 if i%group==5: for j in range(i*matrix_l+i-5,i*matrix_l+i+4): y[j]=0 if i%group==6: for j in range(i*matrix_l+i-6,i*matrix_l+i+3): y[j]=0 if i%group==7: for j in range(i*matrix_l+i-7,i*matrix_l+i+2): y[j]=0 if i%group==8: for j in range(i*matrix_l+i-8,i*matrix_l+i+1): y[j]=0x_left_r=np.zeros((len(x_left),120,1))x_left_r[:,:,0]=x_left[:,:120]x_right_r=np.zeros((len(x_right),120,1))x_right_r[:,:,0]=x_right[:,:120]# Keras model with one Convolution1D layerinput_shape=(120,1)left_input = Input(input_shape)right_input = Input(input_shape)nb_features=120nb_class=9model = Sequential()model.add(Convolution1D(nb_filter=52, filter_length=3, input_shape=(nb_features, 1))) model.add(MaxPooling1D(pool_size=2,strides=None))model.add(Convolution1D(nb_filter=52, filter_length=3,input_shape=(60,1)))model.add(MaxPooling1D())model.add(Activation('relu'))model.add(Flatten()) #建立平坦层model.add(Dropout(0.5)) #丢掉一些神经元和神经网络model.add(Dense(162, activation='relu')) #全连接层定义model.add(Dense(81, activation='relu')) #全连接层定义model.add(Dense(nb_class))model.add(Activation('softmax'))encoded_l=model(left_input)encoded_r=model(right_input)

关于math_ops.abs()的详情可以参考下列官方链接:https://www.tensorflow.org/api_docs/cc/class/tensorflow/ops/abs
到这里我们还没有传值进去,只是搭了大致的模型,接下来在model.fit()时,值才会传进去,再进行运算。 下面计算 x_left 与 x_right 的差值:L1_layer=Lambda(lambda x:K.abs(x[0]-x[1]))L1_distance=L1_layer([encoded_l,encoded_r])prediction = Dense(1,activation='softmax')(L1_distance)siamese_net = Model(inputs=[left_input,right_input],outputs=prediction)
四、训练模型
在Compile模型时设置一些参数,我们这个问题涉及的是判断两个通道是否为同类,所以是二分类问题,上一期写的是多分类,那么这里要使用的是binary_crossentropy,而不是 categorical_crossentropy 。 然后就直接训练模型了,compile和fit的代码,如下:siamese_net.compile(loss='binary_crossentropy',optimizer=keras.optimizers.Adam(lr=0.001,beta_1=0.9,beta_2=0.999,amsgrad=False),metrics = ['accuracy'])siamese_net.fit([x_left_r,x_right_r],y,verbose=1,epochs=10)