行人越界识别及人流统计AI项⽬部署落地心得分享(目标检测算法+Aidlux平台部署)
1 背景
参加了智慧安防实战训练营课程,并完成了基于目标检测算法和Aidlux平台的行人越界识别及人流统计AI项⽬部署落地,在此分析一下此次课程学习心得体会
2 训练营课程
(1)学习专题:
AidLux智慧安防AI实战训练
(2)学习目的
之前在工作中接触过机器学习与人工智能方面一些相关内容,也利用开源模型(如yolov4)做过些相关测试,从而对相关领域的知识和应用开始感兴趣,但是鉴于前期理论学习知识缺乏及后面工作中也缺少相关方面的应用实践,未能进一步深入相关学习和实践。因此一方面是兴趣使然,想了解更多相关领域应用情况,另一方面也是希望作为知识扩充,补充学习相关理论知识,以便后期有可能将相关知识与工作中的需求相结合,解决实际问题,所以参加了此次训练营。
3 结业作业
(1)作业题目:
在学习了越界识别的功能后,采用人体检测+人体追踪+业务功能的方式实现人流统计。
(2)实现效果:
实现了视频中行人越界识别及人流统计显示,并结合微信中喵提醒小程序实现最终检测结果的反馈功能,具体效果如下所示。


(2)Vscode+Aidlux的PC端显示

(3)边缘设备(手机端)效果
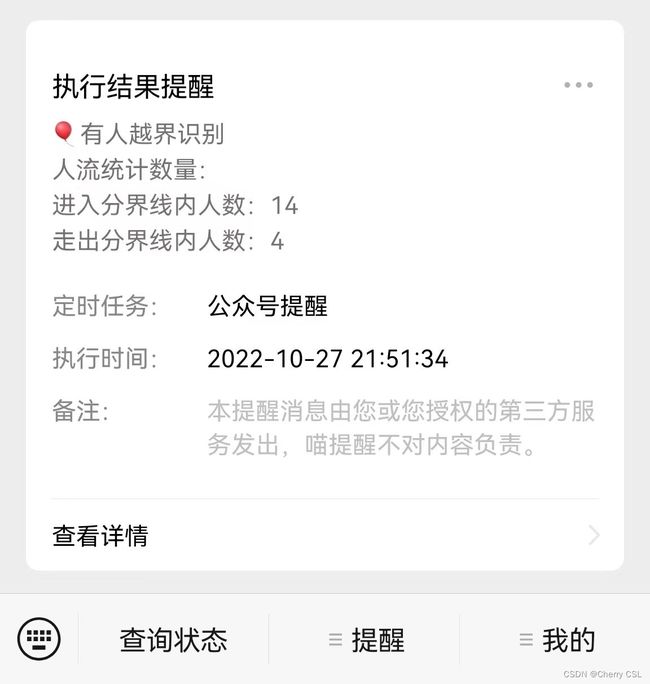
(4)喵提醒效果
(3)代码实现:
核心代码如下:
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res, scale_coords,process_points,is_in_poly,is_passing_line
# isInsidePolygon(无)
import cv2
# bytetrack
from track.tracker.byte_tracker import BYTETracker
from track.utils.visualize import plot_tracking
import requests
import time
# 加载模型
model_path = '/home/lesson4_codes/aidlux/yolov5n_best-fp16.tflite'
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 载入模型
aidlite = aidlite_gpu.aidlite()
# 载入yolov5检测模型
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
tracker = BYTETracker(frame_rate=30)
track_id_status = {}
cap = cvs.VideoCapture("/home/lesson4_codes/aidlux/video.mp4")
frame_id = 0
count_person = 0
count_person2 = 0
while True:
frame = cap.read()
if frame is None:
### 相机采集结束 ###
print("camera is over!!")
# 统计打印人流数量
# 填写对应的喵码
# id = 'tP48aPC'
id = 'tPCiTWT'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "人流统计数量:\n"+"进入分界线内人数:"+str(count_person)+"\n"+"走出分界线内人数:"+str(count_person2)
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers)
# continue
break
frame_id += 1
if frame_id % 3 != 0:
continue
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# 目标追踪相关功能
det = []
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box)
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
### 人流计数识别功能实现 ###
# 1.绘制统计人流线
lines = [[186,249],[1235,366]]
cv2.line(res_img,(186,249),(1235,366),(255,255,0),3)
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]]
# 3. 人体和违规区域的判断(人体状态追踪判断)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
# 4. 判断是否有track_id穿过统计线段
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明穿过(进入)统计线了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明穿过统计线,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
count_person +=1
# cv2.imwrite("overstep.jpg",res_img)
# 当某个track_id的状态,上一帧是1,但是这一帧是-1时,说明穿过(走出)统计线了
elif track_id_status[tid][-1] == -1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明穿过统计线,为了防止继续判别,随机的赋了一个4的值
if track_id_status[tid][-2] == 1:
track_id_status[tid].append(4)
count_person2 +=1
# cv2.imwrite("overstep.jpg",res_img)
cv2.putText(res_img,"enter_person_count:"+str(count_person),(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,255),2)
cv2.putText(res_img,"walkout_person_count:"+str(count_person2),(50,70),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,255),2)
cvs.imshow(res_img)
4 心得体会
(1)课程学习心得
参加此次训练营之前,在AI图像算法开发及应用方面,有简单接触过一些图像识别和物体检测的模型算法,但对相关领域的知识没有系统性的学习,应用实践方面也只停留在应用单一的算法模型实现目标检测。参加此次训练营后对AI算法在智慧城市中的应用领域、AI项⽬开发的一般过程、AI项⽬部署落地等有了初步整体性的学习了解,算法方面也学习了如何在⽬标检测基础上进一步结合业务需求进行越界识别和⼈流统计等算法实现,最后利用越界识别算法实现了视频行人越界识别报警功能。同时还学习了一站式AIoT应用快速开发和部署平台Aidlux的使用,并利用Aidlux平台将行人越界识别算法应用到Android系统(手机端)上,实现移动端行人越界识别报警功能。
虽然此次通过此次训练营培训并不能完全对该领域的知识有非常深入的学习,在相关算法开发方面应该说更只是一次简单初步学习探索,但是基于培训中实操较多,培训老师大白老师的讲解也是十分细致到位,所以在此次培训中还是收获颇多。
(2)AidLux使用心得
Aidlux打通了将PC端开发的算法快速应用到Android系统上的整个开发流程,通过Aidlux平台,可以将安卓设备变成边缘端设备进行AI处理,实现了在没有边缘设备的情况下,也可以使用手机版本的Aidlux,尝试边缘设备的所有功能,且部署操作简单,效果立竿见影!
Aidlux平台本身内置了多种深度学习框架,便于开发者使用,实现快速开发。并且还对多种算子进行了优化加速,许多算法的性能,也都能达到实时使用。此外Aidlux平台上有许多应用案例可以直接调用(如下图所示),便于Ai开发新手也可以快速体验尝试。

不过在本次学习使用Aidlux的过程中也遇到了一些问题,如手机端AidLux的APP运行进程容易卡住或挂掉,另外Aidlux平台上可以直接运行已有代码,但不能对代码进行调试,所以希望平台后期能扩展代码调试功能就更好了(期待ing~)。
最后,感谢此次训练营的培训老师江大白老师的用心指导。