DIDFuse:用于红外和可见光图像融合的深度图像分解
论文地址:https://arxiv.org/abs/2003.09210
code地址: GitHub - Zhaozixiang1228/IVIF-DIDFuse: Official implementation for "DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion" (IJCAI 2020)
摘要
红外与可见光图像融合是图像处理领域的一个热点问题,其目的是在保持源图像优势的前提下获得融合后的图像。提出了一种基于自动编码器的融合网络。其核心思想是编码器将图像分别分解为具有低、高频信息的背景特征图和细节特征图,解码器恢复原始图像。为此,loss函数使源图像的背景/细节特征图相似/不相似。在测试阶段,通过融合模块分别对背景和细节特征图进行融合,并由解码器对融合后的图像进行恢复。定性和定量结果表明,我们的方法可以生成包含高亮目标和丰富细节纹理信息的融合图像,具有较强的重现性,同时优于目前最先进的(SOTA)方法。
1 Introduction
图像融合是一种用于信息增强的图像处理技术。其原理是保留包含相同场景的源图像的互补和冗余信息而不产生伪像[Meher et al., 2019]。在图像融合中,红外和可见光图像融合,又称IVIF,可以应用于许多领域,如监视[Bhatnagar和Liu, 2015],现代军事和火灾救援任务[Lahoud和Susstrunk, 2018;Hu et al., 2017],人脸识别[Ma et al., 2016]等。
众所周知,红外图像可以避免光照变化和人为干扰引起的视觉认知障碍,但其空间分辨率较低,纹理细节信息较差。相反,可见图像具有较高的空间分辨率,具有丰富的外观和梯度信息,但容易受到障碍物和光反射的影响。因此,使融合图像既保留了红外图像的热辐射信息,又保留了可见光图像的梯度信息,将有利于目标的识别和跟踪。
一般来说,IVIF算法可以分为两类:传统方法和深度学习方法。其中,具有代表性的传统方法有图像多尺度变换[Li et al., 2011]、稀疏表示[Zong and Qiu, 2017]、子空间学习[Patil and Mudengudi, 2011]和基于显著性的方法[Zhang et al., 2017]。
目前,深度学习(deep learning, DL)已成为IVIF领域的一种流行工具。基于DL的方法可分为三类。第一组基于生成对抗网络(GANs)。在fusongan [Ma et al., 2019b]中,生成器生成具有红外热辐射和可见梯度信息的融合图像,识别器迫使融合图像从可见图像获得更多细节。根据Conditional GAN [Mirza and Osindero, 2014],保留细节GAN [Ma et al., 2020]通过改变FusionGAN的损失函数来提高细节信息的质量,锐化目标边界。第二组[Li et al., 2018;Lahoud and S¨usstrunk, 2019]是图像多尺度变换的延伸。一般来说,它们通过滤波或基于优化的方法将图像从空间域转换为背景域和细节域。背景图像只是简单的平均。由于细节图像中存在高频纹理,他们融合了从预先训练的网络中提取的细节图像的特征图(例如,VGG [Simonyan and Zisserman, 2014])。最后,将融合后的背景图像与细节图像进行融合,得到融合后的图像。第三组是基于AE的方法[Li and Wu, 2018]。在训练阶段,对AE网络进行训练。在测试阶段,他们融合源图像的特征映射,然后通过解码器恢复融合图像。综上所述,在基于DL的方法中,通常采用深度神经网络(DNNs)提取输入图像的特征,然后利用某种融合策略将特征进行组合,完成图像融合任务。
值得指出的是第二种方法的缺点,即DL只在融合阶段使用,在分解阶段使用基于滤波或优化的方法。为了克服这一缺点,结合第二组和第三组的原理,我们提出了一种新的IVIF网络,称为基于IVIF的深度图像分解(DIDFuse)。我们的贡献有两方面:
(1)据我们所知,这是第一个用于IVIF任务的深度图像分解模型,融合和分解都是通过AE网络完成的。编码器和解码器分别负责图像的分解和重构。在训练阶段,对于分解阶段,损失函数强制两幅源图像的背景和细节特征图相似/不相似。同时,在重建阶段,损失函数保持了源图像和重建图像之间的像素强度,以及可见图像的梯度细节。在测试阶段,根据特定的融合策略分别融合测试对的背景和细节特征图,然后通过解码器获取融合图像。
(2)据我们所知,现有IVIF方法的性能[Ma et al., 2016;李和吴,2018;Zhang et al., 2017;Li et al., 2018]仅在TNO数据集中有限数量的精选样本上进行验证。然而,我们在三个数据集上测试了我们的模型,包括TNO, FLIR和NIR。总共有132幅室内和室外场景、白天和夜间灯光照明的测试图像。与SOTA方法相比,该方法能够稳健地生成目标更亮、细节更丰富的融合图像。该算法在目标识别和跟踪方面具有潜在的应用价值。
其余的文章安排如下。相关工作将在第二节中介绍。提议网络的机制将在第3节中描述。然后,在第4节报告了实验结果。最后,在第5节中得出了一些结论。
2 Related Work
由于我们的网络结构与U-Net密切相关,我们将在2.1节介绍U-Net。然后,在2.2节简要回顾了传统的双尺度图像分解方法。
2.1 U-Net and Skip Connection
U-Net应用于生物医学图像分割[Ronneberger et al., 2015],与AE网络相似,U-Net由特征提取的收缩路径和精确定位的扩展路径组成。与AE相比,U-Net中收缩和扩展路径对应的特征映射具有通道级联的特点。通过这种方式,它可以提取“更厚”的特征,有助于在下采样时保持图像纹理细节。文献[Mao et al., 2016]中使用了一种类似u - net的对称网络进行图像恢复。它采用跳跃连接技术,将卷积层的特征映射添加到相应的反卷积层,增强神经网络的信息提取能力,加快收敛速度。
2.2 Two-Scale Decomposition
IVIF中的双尺度分解作为多尺度变换的子集,将原始图像分解为包含背景信息和目标信息的背景图像和细节图像。在[Li and Wu, 2018]中,给定图像I,他们通过求解以下优化问题得到背景图像Ib:

其中∗表示卷积算子,gx =[−1,1]和gy =[−1,1]T是梯度核。然后通过Id = I−Ib获取细节图像。类似的,在[Lahoud and S¨usstrunk, 2019]中使用box filter来获取背景图像,获取细节图像的方法与[Li and Wu, 2018]相同。对分解后的背景图像和细节图像分别采用不同的融合准则进行融合。最后,将融合后的背景图像与细节图像相结合,重建出融合后的图像。
3 Method
在本节中,我们将介绍我们的DIDFuse算法和提议的网络结构。此外,还说明了培训和测试阶段的细节。
3.1 Motivation
如2.2节所述,两尺度分解将输入图像分解为包含大尺度像素强度变化的低频信息的背景图像和包含小尺度像素强度变化的高频信息的细节图像。目前,大多数算法都结合一定的先验知识,采用基于滤波或优化的方法对图像进行分解。因此,它们是手工设计的分解算法。我们强调图像分解算法本质上是特征提取器。在形式上,它们将源图像从空间域转换为特征域。众所周知,DNN是一种很有前途的数据驱动特征提取方法,与传统的手工设计方法相比有很大的优势。遗憾的是,该算法缺乏一种用于IVIF任务的基于DL的图像分解算法。
因此,我们提出了一种新的深度图像分解网络,利用编码器进行两尺度分解并提取不同类型的信息,利用解码器恢复原始图像。
3.2 Network Architecture
我们的神经网络由一个编码器和一个解码器组成。如图1所示,编码器被输入红外或可见光图像,并生成背景和细节特征图。然后,网络沿着通道将两种特征图串联起来。最后,串联的特征图通过解码器来恢复原始图像。为了防止特征图的细节信息在多次卷积后丢失,并加快收敛速度,我们将第一次和第二次卷积的特征图添加到最后一次和倒数第二次卷积的输入中,添加策略是沿通道串联相应的特征图。因此,源图像的像素强度和梯度信息可以更好地保留在重建的图像中。

表1列出了网络配置。编码器和解码器分别包含四层和三层卷积层。每一层由填充、3 × 3卷积、批量归一化和激活函数组成。第一层和最后一层利用反射填充来防止融合图像边缘的伪影。conv3和conv4的激活函数设置为双曲正切函数(tanh),因为它们输出的是背景和细节特征图。对于conv7,由于它重建的是原始图像,因此被sigmoid函数激活。其他层之后是参数整流线性单元(PReLU)。

3.3 Loss Function
在训练阶段,我们的目标是获得一种对源图像进行两尺度分解的编码器,同时获得一种能够融合图像并很好地保留源图像信息的解码器。训练过程如图1(a)所示。
图像分解。背景特征图用于提取源图像的共同特征,细节特征图用于捕获红外和可见光图像的不同特征。因此,我们应该缩小背景特征图的差距。相反,细节特征图的差距应该很大。为此,图像分解的损失函数定义如下:

其中,BV、DV为可见光图像V的背景特征图和细节特征图,BI、DI为红外图像i的背景特征图和细节特征图。Φ(·)为将间隙限定为区间(−1,1)的双曲函数。
Image Reconstruction
对于图像重建,为了成功保留输入图像的像素强度和详细纹理信息,给出了重建损失函数

式中,I和ˆI, V和ˆV分别表示红外图像和可见光图像的输入图像和重建图像。∇为梯度算子,且

其中X和ˆX表示上述输入图像和重建图像,λ为超参数。SSIM是结构相似性指数[Wang et al., 2004],是衡量两幅图之间相似性的指标。那么LSSIM可以描述为

值得注意的是l2范数度量的是原始图像与重建图像的像素强度一致性,而LSSIM计算的是图像在亮度、对比度和结构方面的差异。特别地,由于可见光图像具有丰富的纹理,因此采用梯度稀疏惩罚对可见光图像进行正则化重建,以保证纹理一致性。
结合方程式。(1)(2),总损失Ltotal可以表示为
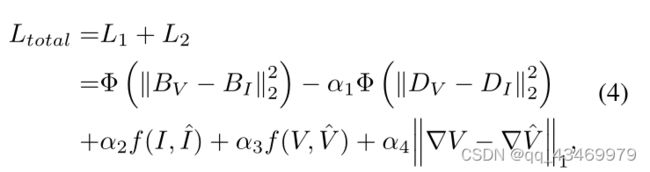
其中,α1、α2、α3、α4为调优参数。
3.4 Fusion Strategy
在上面的小节中,我们提出了网络结构和损耗函数。经过培训,我们将获得一个分解器(或者说是编码器)和一个解码器。在测试阶段,我们的目标是融合红外和可见光图像。工作流如图1(b)所示。与训练不同,在测试阶段插入融合层。它分别融合了背景和细节特征图。在公式中,有

BF和DF分别表示融合后的背景特征图和细节特征图。本文考虑了以下三种融合策略:
•求和法:BF = BI⊕BV, DF = DI⊕DV,其中符号⊕表示逐元素相加。
•加权平均法:BF = γ1BI⊕γ2BV, DF = γ3DI⊕γ4DV,其中γ1 + γ2 = γ3 + γ4 = 1, γi(i = 1,···,4)的默认值均为0.5。
•L1-norm方法:参考[Li和Wu, 2018],我们将L1-norm作为活动的度量,并结合softmax操作员。在细节中,我们可以获得活动水平的地图融合背景和细节特征图由kBi (x, y) k1和kDi (x, y) k1 (i = 1、2),B1, B2, D1和D2代表BI, BV, DI和DV,代表相应坐标(x, y)地图和融合特性图的特性。那么可以通过以下方法计算出相加权值:

where ψ(·) is a 3 × 3 box blur (also known as a mean filter operator). Consequently, we have

其中⊗表示基于元素的乘法。
4 Experiment
本节的目的是研究我们提出的模型的性能和比较其他SOTA模型,包括FusionGAN (Ma et al ., 2019 b), Densefuse(李、吴,2018),ImageFuse[李et al ., 2018), DeepFuse[角色et al ., 2017), TSIFVS (Bavirisetti和Dhuli, 2016),TVADMM(郭et al ., 2017), CSR(刘et al .,和ADF [Bavirisetti和Dhuli, 2015]。所有实验都是在一台配备Intel酷睿i7-9750H [email protected]和RTX2070 GPU的计算机上使用Pytorch进行的。
采用熵(EN)、互信息(MI)、标准差(SD)、空间频率(SF)、视觉信息保真度(VIF)和平均梯度(AG)等6个度量来评价融合图像的质量。这些指标的更多细节见[Ma等人,2019a]。
数据集和预处理。我们的实验是在三个数据集上进行的,包括TNO [Toet and Hogervorst, 2012], NIR [Brown and S¨usstrunk, 2011]和FLIR(可在https://github.com/jiayi-ma/RoadScene获得)。在我们的实验中,我们将它们分为训练集、验证集和测试集。表2给出了数据集的图像对个数、光照和场景信息。我们在FLIR数据集中随机选取180对图像作为训练样本。在训练之前,所有的图像都被转换成灰度。同时,我们用128 × 128像素对它们进行中心裁剪。

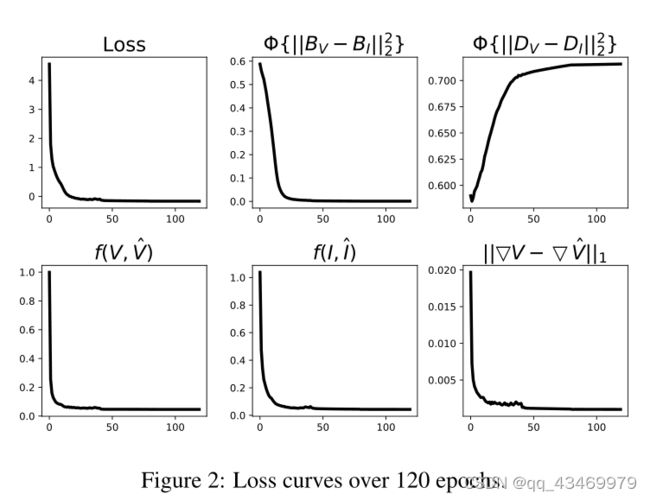
Hyperparameters设置。损失函数中的调谐参数经验设定为:α1 = 0.05, α2 = 2, α3 = 2, α4 = 10, λ = 5。在训练阶段,Adam对网络进行了120多个epoch的优化,批量大小为24个。对于学习速率,我们将其设置为10 - 3,并每40个epoch降低10倍。图2显示了与epoch索引的损耗曲线。结果表明,120代以后,所有的损耗曲线都非常平坦。换句话说,网络能够收敛于这种配置。
4.1 Experiments on Fusion Strategy
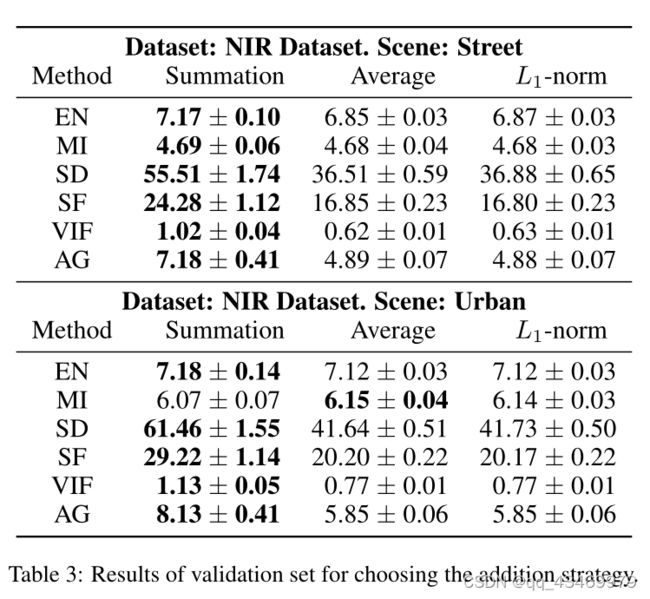
如3.4节所述,融合策略在我们的模型中起着重要的作用。我们研究了三种策略在验证集上的性能。表3报告了验证集上六个度量的数值结果。很明显,求和策略获得了较高的值,尤其是SD、SF、VIF和AG。因此,以下实验采用求和策略。
4.2 Experiments on Image Decomposition
我们的贡献之一是深度图像分解。分解的特征图是否能够满足我们的需求是一个很有趣的问题。在图3中,它显示了由conv3和conv4生成的特征图的第一个通道。实验结果表明,该方法能够有效地分离红外和可见光图像的背景和细节。对于背景特征图,我们发现BI和BV在视觉上是相似的,它们反映了同一场景的背景和环境。相反,DI和DV之间的差距较大,说明了不同源图像所包含的不同特征。即红外图像包含目标的高亮和热辐射信息,而可见光图像包含目标的梯度和纹理信息。综上所述,在一定程度上验证了我们所提出的网络结构和图像分解损失函数的合理性。

4.3 Comparison with Other Models
在本小节中,我们将把我们的模型与其他流行的模型进行比较。
定性比较。图4展示了几种不同模型生成的具有代表性的融合图像。视觉检测表明,在包含人的图像中,其他方法存在高光对象弱、对比度差、目标和背景轮廓不突出等问题。同样,如果图像是自然景观,其他图像的山和树边界模糊,色彩对比差,清晰度不够。相反,我们的方法可以获得目标更亮、边缘轮廓更清晰、保留更丰富细节信息的融合图像。
图4:不同方法的定性结果用橙色和蓝色盒子标记的区域被放大以方便检查。
定量比较。随后,对测试集的定量比较结果列于表4。我们发现,在所有数据集上,我们的模型在所有指标上都是最好的。至于竞争对手,他们可能在数据集的部分指标上表现良好。结果表明,该模型融合的图像纹理丰富,满足人类视觉系统的要求。

4.4可重复性实验
众所周知,深度学习方法经常因不稳定性而受到批评。因此,我们在上一个实验中对DIDFuse的重现性进行了测试。我们反复训练网络25次,并定量比较25个并行结果。如图5所示,黑色实心曲线报告了25个实验中的6个指标。红色虚线和蓝色虚线分别代表比较方法中的最大值和第二大值。与上述结果类似,我们的方法基本上可以一直保持第一的位置,说明DIDFuse可以稳定地生成高质量的融合图像。
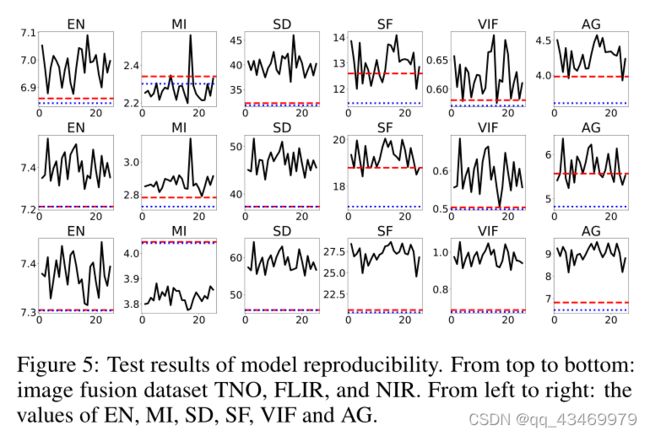
图5:模型重现性测试结果。从上到下:图像融合数据集TNO、FLIR和NIR。从左到右依次为:EN、MI、SD、SF、VIF、AG。
5 Conclusion
为了解决IVIF问题,我们构造了一种新的AE网络,其中编码器负责图像的二尺度分解,解码器负责图像的重建。在训练阶段,训练编码器输出背景图和特征图,然后解码器重构原始图像。在测试阶段,我们在编码器和解码器之间设置融合层,通过特定的融合策略融合背景和细节特征图。最后,通过译码器得到融合后的图像。我们在TNO、FLIR和NIR数据集上测试了我们的模型。定性和定量结果表明,该模型能稳定地获得高亮目标的融合图像,且细节丰富,优于其他SOTA方法。