【强化学习实战-04】DQN和Double DQN保姆级教程(2):以MountainCar-v0
【强化学习实战-04】DQN和Double DQN保姆级教程(2):以MountainCar-v0
-
- 实战:用Double DQN求解MountainCar问题
-
- MountainCar问题详解
- MountainCar问题的源代码解释
-
- cartpole.py
- MountainCar的状态(Observation)
- MountainCar的动作
- MountainCar的目的
- DQN 求解MountainCar问题:完整代码详解
-
- 定义神经网络 Q ( w ) Q(\mathbf{w}) Q(w)
- 神经网络可视化:`tensorbard`
- TD-learning + experience replay更新
- Double DQN的实现
- 设计reward:方法1--只考虑小车的位置
- 设计reward:方法2--同时考虑小车位置和小车速度
- batch操作
- 使用Adam优化器,基于gradient descent 更新网络参数
- Double DQN求解MountainCar-v0问题的完整代码
-
- 训练网络的代码
- 测试网络的代码
- 小结
- 参考文献
作者: 刘兴禄,清华大学,清华-伯克利深圳学院,博士在读
实战:用Double DQN求解MountainCar问题
MountainCar问题详解
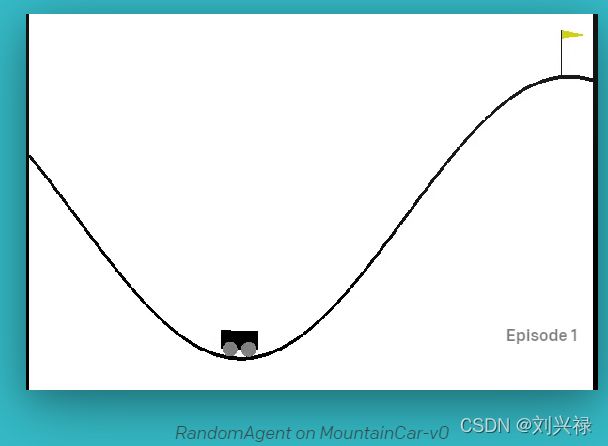
MountainCar问题是开源环境模块OpenAI gym中的一个问题。
网址:https://gym.openai.com/envs/MountainCar-v0/
该问题的目的,是想通过控制小车的动作,使得小车爬上右边的坡。如上图所示。
MountainCar问题的源代码解释
OpenAI gym中给出了MountainCar环境的源代码。其源代码如下:
cartpole.py
"""
http://incompleteideas.net/MountainCar/MountainCar1.cp
permalink: https://perma.cc/6Z2N-PFWC
"""
import math
from typing import Optional
import numpy as np
import pygame
from pygame import gfxdraw
import gym
from gym import spaces
from gym.utils import seeding
class MountainCarEnv(gym.Env):
"""
The agent (a car) is started at the bottom of a valley. For any given state
the agent may choose to accelerate to the left, right or cease any
acceleration. The code is originally based on [this code](http://incompleteideas.net/MountainCar/MountainCar1.cp)
and the environment appeared first in Andrew Moore's PhD Thesis (1990):
```
@TECHREPORT{Moore90efficientmemory-based,
author = {Andrew William Moore},
title = {Efficient Memory-based Learning for Robot Control},
institution = {},
year = {1990}
}
```
Observation space is a 2-dim vector, where the 1st element represents the "car position" and the 2nd element represents the "car velocity".
There are 3 discrete deterministic actions:
- 0: Accelerate to the Left
- 1: Don't accelerate
- 2: Accelerate to the Right
Reward: Reward of 0 is awarded if the agent reached the flag
(position = 0.5) on top of the mountain. Reward of -1 is awarded if the position of the agent is less than 0.5.
Starting State: The position of the car is assigned a uniform random value in [-0.6 , -0.4]. The starting velocity of the car is always assigned to 0.
Episode Termination: The car position is more than 0.5. Episode length is greater than 200
### Arguments
```
gym.make('MountainCar-v0')
```
### Version History
* v0: Initial versions release (1.0.0)
"""
metadata = {"render.modes": ["human", "rgb_array"], "video.frames_per_second": 30}
def __init__(self, goal_velocity=0):
self.min_position = -1.2
self.max_position = 0.6
self.max_speed = 0.07
self.goal_position = 0.5
self.goal_velocity = goal_velocity
self.force = 0.001
self.gravity = 0.0025
self.low = np.array([self.min_position, -self.max_speed], dtype=np.float32)
self.high = np.array([self.max_position, self.max_speed], dtype=np.float32)
self.screen = None
self.isopen = True
self.action_space = spaces.Discrete(3)
self.observation_space = spaces.Box(self.low, self.high, dtype=np.float32)
def step(self, action):
assert self.action_space.contains(
action
), f"{action!r} ({type(action)}) invalid"
position, velocity = self.state
velocity += (action - 1) * self.force + math.cos(3 * position) * (-self.gravity)
velocity = np.clip(velocity, -self.max_speed, self.max_speed)
position += velocity
position = np.clip(position, self.min_position, self.max_position)
if position == self.min_position and velocity < 0:
velocity = 0
done = bool(position >= self.goal_position and velocity >= self.goal_velocity)
reward = -1.0
self.state = (position, velocity)
return np.array(self.state, dtype=np.float32), reward, done, {}
def reset(
self,
*,
seed: Optional[int] = None,
return_info: bool = False,
options: Optional[dict] = None,
):
super().reset(seed=seed)
self.state = np.array([self.np_random.uniform(low=-0.6, high=-0.4), 0])
if not return_info:
return np.array(self.state, dtype=np.float32)
else:
return np.array(self.state, dtype=np.float32), {}
def _height(self, xs):
return np.sin(3 * xs) * 0.45 + 0.55
def render(self, mode="human"):
screen_width = 600
screen_height = 400
world_width = self.max_position - self.min_position
scale = screen_width / world_width
carwidth = 40
carheight = 20
if self.screen is None:
pygame.init()
self.screen = pygame.display.set_mode((screen_width, screen_height))
self.surf = pygame.Surface((screen_width, screen_height))
self.surf.fill((255, 255, 255))
pos = self.state[0]
xs = np.linspace(self.min_position, self.max_position, 100)
ys = self._height(xs)
xys = list(zip((xs - self.min_position) * scale, ys * scale))
pygame.draw.aalines(self.surf, points=xys, closed=False, color=(0, 0, 0))
clearance = 10
l, r, t, b = -carwidth / 2, carwidth / 2, carheight, 0
coords = []
for c in [(l, b), (l, t), (r, t), (r, b)]:
c = pygame.math.Vector2(c).rotate_rad(math.cos(3 * pos))
coords.append(
(
c[0] + (pos - self.min_position) * scale,
c[1] + clearance + self._height(pos) * scale,
)
)
gfxdraw.aapolygon(self.surf, coords, (0, 0, 0))
gfxdraw.filled_polygon(self.surf, coords, (0, 0, 0))
for c in [(carwidth / 4, 0), (-carwidth / 4, 0)]:
c = pygame.math.Vector2(c).rotate_rad(math.cos(3 * pos))
wheel = (
int(c[0] + (pos - self.min_position) * scale),
int(c[1] + clearance + self._height(pos) * scale),
)
gfxdraw.aacircle(
self.surf, wheel[0], wheel[1], int(carheight / 2.5), (128, 128, 128)
)
gfxdraw.filled_circle(
self.surf, wheel[0], wheel[1], int(carheight / 2.5), (128, 128, 128)
)
flagx = int((self.goal_position - self.min_position) * scale)
flagy1 = int(self._height(self.goal_position) * scale)
flagy2 = flagy1 + 50
gfxdraw.vline(self.surf, flagx, flagy1, flagy2, (0, 0, 0))
gfxdraw.aapolygon(
self.surf,
[(flagx, flagy2), (flagx, flagy2 - 10), (flagx + 25, flagy2 - 5)],
(204, 204, 0),
)
gfxdraw.filled_polygon(
self.surf,
[(flagx, flagy2), (flagx, flagy2 - 10), (flagx + 25, flagy2 - 5)],
(204, 204, 0),
)
self.surf = pygame.transform.flip(self.surf, False, True)
self.screen.blit(self.surf, (0, 0))
if mode == "human":
pygame.display.flip()
if mode == "rgb_array":
return np.transpose(
np.array(pygame.surfarray.pixels3d(self.screen)), axes=(1, 0, 2)
)
else:
return self.isopen
def get_keys_to_action(self):
# Control with left and right arrow keys.
return {(): 1, (276,): 0, (275,): 2, (275, 276): 1}
def close(self):
if self.screen is not None:
pygame.quit()
self.isopen = False
MountainCar的状态(Observation)
在任意时刻,我们给环境一个动作,环境会返回MountainCar的状态(Observation)。从中我们可以看出,任意时刻,MountainCar的状态包括2个量,即car position和car velocity:
Observation space is a 2-dim vector,
where the 1st element represents the "car position"
and the 2nd element represents the "car velocity".
def __init__(self, goal_velocity=0):
self.min_position = -1.2
self.max_position = 0.6
self.max_speed = 0.07
self.goal_position = 0.5
self.goal_velocity = goal_velocity
self.force = 0.001
self.gravity = 0.0025
即:
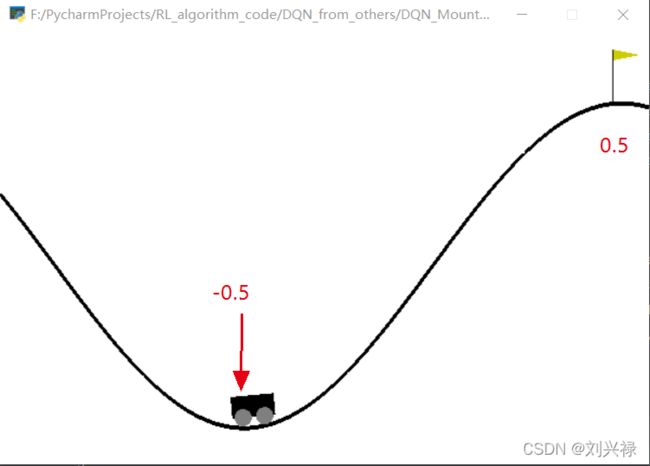
- Car的位置 x x x: 范围是 [ − 1.2 , 0.6 ] [-1.2, 0.6] [−1.2,0.6]
- Car的速度 v v v: 范围是 [ 0 , 0.07 ] [0, 0.07] [0,0.07]
下图标出了几个重要的点的坐标。
MountainCar的动作
即 MountainCar的动作,即:向左加速、不加速、向右加速,只有3个可选动作。
There are 3 discrete deterministic actions:
- 0: Accelerate to the Left
- 1: Don't accelerate
- 2: Accelerate to the Right
MountainCar的目的
就是在状态 s t = ( x t , v t ) s_t = (x_t, v_t) st=(xt,vt)的时候,我们为Car提供
- a t = Accelerate to the Left a_t = \text{Accelerate to the Left} at=Accelerate to the Left还是
- a t = Don’t accelerate a_t = \text{Don't accelerate} at=Don’t accelerate,或者是
- a t = Accelerate to the Right a_t = \text{Accelerate to the Right} at=Accelerate to the Right
的决策,使其爬上右边的坡的指定位置 0.5 0.5 0.5,也就是源码中的self.goal_position = 0.5。
def __init__(self, goal_velocity=0):
self.min_position = -1.2
self.max_position = 0.6
self.max_speed = 0.07
self.goal_position = 0.5
self.goal_velocity = goal_velocity
self.force = 0.001
self.gravity = 0.0025
DQN 求解MountainCar问题:完整代码详解
定义神经网络 Q ( w ) Q(\mathbf{w}) Q(w)
- 输入层:由于Car有2个状态 s t = ( x t , v t ) s_t = (x_t, v_t) st=(xt,vt),因此,神经网络的输入层有2个神经元。
- 输出层:由于Car可选的动作只有3个,即
向左加速、不加速或者向右加速。因此输出层为3个神经元。 - 隐藏层:隐藏层我们采用全连接即可。神经元数量和层数可以自己调整。
定义神经网络结构的代码如下。
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.fc = nn.Sequential(
nn.Linear(2, 24),
nn.ReLU(),
nn.Linear(24, 24),
nn.ReLU(),
nn.Linear(24, 3)
)
self.MSELoss = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.parameters(), lr = 0.001)
def forward(self, inputs):
return self.fc(inputs)
神经网络可视化:tensorbard
我们用tensorbard来查看网络结构的可视化:
env = gym.envs.make('CartPole-v1')
env = env.unwrapped
DQN = Network() # DQN network, 需要训练的网络
Target_net = Network() # Target network
.......
.......
# 用tensorboard可视化神经网络
if(graph_added == False):
writer.add_graph(model=DQN, input_to_model=batch_state)
writer.add_graph(model=Target_net, input_to_model=batch_state)
graph_added = True
.......
writer.close()
然后我们打开Pycharm的terminal, cd进入到"logs_DQN_MountainCar"所在的文件夹下,输入命令:
tensorboard --logdir=logs_DQN_MountainCar
- 注意:
一定要给神经网络喂了数据,导出才会成功。只建立网络是不会成功的。
即可查看可视化的神经网络。我们可视化后,神经网络如下。可见
- 输入层为batch_size * state_dim = 1000 * 2
- 输出层为batch_size * action_dim = 1000 * 3

我们仔细看network的结构,如下图:
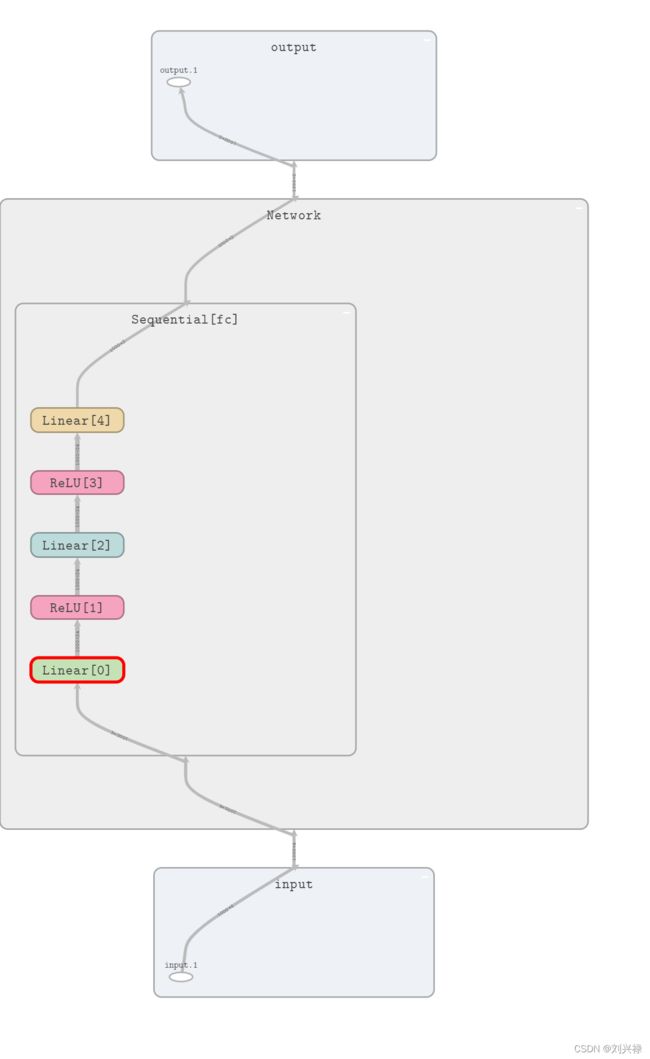
由于该问题比较简单,我们并没有引入卷积层(Conv2d)以及池化(maxpool)操作等。
TD-learning + experience replay更新
- 我们在replay buffer中存储的transitions的形式均为 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1),因此,我们可以用一个数组或者DataFrame来存储这些transitions。但是需要注意, s t s_t st是一个2元组,即 s t = ( x t , v t ) s_t = (x_t, v_t) st=(xt,vt), 所以,一个transition是1行6列的,也就是
( x t , v t ‾ , a t , x t + 1 , v t + 1 ‾ , r t ) (\underline{x_t, v_t}, a_t, \underline{x_{t+1}, v_{t+1}}, r_t) (xt,vt,at,xt+1,vt+1,rt),因此,replay buffer的形式是
t : ( x t , v t ‾ , a t , x t + 1 , v t + 1 ‾ , r t ) t + 1 : ( x t + 1 , v t + 1 ‾ , a t + 1 , x t + 2 , v t + 2 ‾ , r t + 1 ) t + 2 : ( x t + 2 , v t + 2 ‾ , a t + 2 , x t + 3 , v t + 3 ‾ , r t + 2 ) ⋯ \begin{aligned} &t: &&(\underline{x_t, v_t}, a_t, \underline{x_{t+1}, v_{t+1}}, r_t) \\ &t+1: &&(\underline{x_{t+1}, v_{t+1}}, a_{t+1}, \underline{x_{t+2}, v_{t+2}}, r_{t+1}) \\ &t+2: &&(\underline{x_{t+2}, v_{t+2}}, a_{t+2}, \underline{x_{t+3}, v_{t+3}}, r_{t+2}) \\ & \cdots \end{aligned} t:t+1:t+2:⋯(xt,vt,at,xt+1,vt+1,rt)(xt+1,vt+1,at+1,xt+2,vt+2,rt+1)(xt+2,vt+2,at+2,xt+3,vt+3,rt+2)
代码中定义replay buffer为:
replay_buffer = np.zeros((replay_buffer_size, 6)) # 初始化buffer 列中储存 s, a, s_, r
实现TD learning的部分为
# 我们用Target_net来计算TD-target
q = DQN(batch_state).gather(1, batch_action) # predict q-value by old network
q_next = Target_net(batch_state_).detach().max(1)[0].reshape(batch_size, 1) # predict q(s_t+1)
q_target = batch_reward + gamma * q_next # 用Target_net来计算TD-target
loss = DQN.MSELoss(q, q_target) # 计算loss
相应的数学公式为:
y target = r t + γ max a Q ( s t + 1 , a ; w t ) y_{\text{target}} = r_t + \gamma \underset{a}{\max \,\,}Q(s_{t+1}, a; \mathbf{w}_{t}) ytarget=rt+γamaxQ(st+1,a;wt)
Double DQN的实现
另外,为了实现Double DQN,我们我们定义两个网络DQN和Target_net。我们只训练更新DQN,然后每学习一定次数后(代码中为update_interval),我们就把最新的DQN网络的参数,load到Target_net里面去,并且,我们用Target_net计算TD target,用DQN选择下一步将要做的动作。
代码中的实现为:
DQN = Network() # DQN network, 需要训练的网络
Target_net = Network() # Target network
......
......
if stored_transition_cnt > replay_buffer_size:
# 如果到达update_interval,则将net的参数load到net2中
if transition_cnt % update_interval == 0:
Target_net.load_state_dict(DQN.state_dict())
另外,刚开始的时候,我们以较大概率随机给动作,以较小概率用DQN给动作。随着时间推移,我们以较大概率DQN给动作,较小概率随机探索(也就是随机给动作)。
if (random.randint(0,100) < 100*(discount_factor**transition_cnt)): # act greedy, 就是随机探索,刚开始所及探索多,后面变少
action = random.randint(0, 2)
else:
# 超过100次,我们用DQN,也就是训练的神经网络来选动作
# 我们用DQN,也就是训练的神经网络来选动作
output = DQN(torch.Tensor(state)).detach() # output中是[左走累计奖励, 右走累计奖励]
action = torch.argmax(output).data.item() # 用argmax选取动作
设计reward:方法1–只考虑小车的位置
我们设计reward函数为
r t = { 10 , if x t ⩾ 0.5 2 3 ( x t + 0.5 ) , if − 0.5 < x t < 0.5 0 , if x t ⩽ − 0.5 r_t=\begin{cases} 10,& \text{if}\,\,x_t\geqslant 0.5\\ 2^{3(x_t+0.5)},& \text{if}\,\,-0.5
主要想就是:小车位置越往右,奖励越高。达到 0.5 0.5 0.5的位置处,奖励最高为10.如果小车走到了 < 0.5 <0.5 <0.5的部分,我们不鼓励,所以奖励为0。
这种奖励设计,就是鼓励小车可以往右走爬坡。
代码中为
reward = state_[0] + 0.5
if(state_[0] > -0.5):
# reward = state_[0] + 0.5
reward = math.pow(2, 3*(state_[0] + 0.5))
if(state_[0] > 0.5):
reward = 10
else:
reward = 0
这种方法有个缺陷,就是收敛比较慢。是因为,如果目标是让小车爬坡,就不能只关心位置,小车的速度越快,也可以使得小车尽快爬上坡。因此,reward设置中应当考虑速度。因此我们提供第二种reward的设置方式。
设计reward:方法2–同时考虑小车位置和小车速度
设计reward的逻辑是:
- 小车坐标 x < − 0.5 x< -0.5 x<−0.5时,虽然位置不好,但是为了加速往右冲,还是需要鼓励:
速度绝对值大(注意是速度的绝对值),奖励也大。- 小车坐标 x > − 0.5 x> -0.5 x>−0.5时,此时,位置越向右,reward越大,并且速度绝对值越大,奖励要陡增。
基于此,我们设计第二种reward函数为
r t = { 1000 , if x t ⩾ 0.5 2 5 ( x t + 1 ) + ( 100 ∣ v t ∣ ) 2 , if − 0.5 < x t < 0.5 0 + 100 ∣ v t ∣ , if x t ⩽ − 0.5 r_t=\begin{cases} 1000,& \text{if}\,\,x_t\geqslant 0.5\\ 2^{5(x_t+1)} + (100 |v_t|)^2,& \text{if}\,\,-0.5
代码中为
reward = state_[0] + 0.5
if (state_[0] <= -0.5):
reward = 100 * abs(state_[1])
# print('速度:', state_[1])
elif(state_[0] > -0.5 and state_[0] < 0.5):
reward = math.pow(2, 5*(state_[0] + 1)) + (100 * abs(state_[1])) ** 2
elif(state_[0] >= 0.5):
reward = 1000
batch操作
我们令batch_size=1000,并且在每一步学习的时候,我们首先从replay buffer中选取一个batch的transitions并将其转化成tensor,并且这个batch是随机选的,这样可以消除样本序列之间(尤其是相邻样本)的相关性。代码如下:
index = random.randint(0, replay_buffer_size - batch_size -1)
batch_state = torch.Tensor(replay_buffer[index:index + batch_size, 0:4])
batch_action = torch.Tensor(replay_buffer[index:index + batch_size, 4:5]).long()
batch_state_ = torch.Tensor(replay_buffer[index:index + batch_size, 5:9])
batch_reward = torch.Tensor(replay_buffer[index:index + batch_size, 9:10])
使用Adam优化器,基于gradient descent 更新网络参数
# 训练-更新网络:gradient descent updates
# 我们用Target_net来计算TD-target
q = DQN(batch_state).gather(1, batch_action) # predict q-value by old network
q_next = Target_net(batch_state_).detach().max(1)[0].reshape(batch_size, 1) # predict q(s_t+1)
q_target = batch_reward + gamma * q_next # 用Target_net来计算TD-target
loss = DQN.MSELoss(q, q_target) # 计算loss
DQN.optimizer.zero_grad() # 将DQN上步的梯度清零
loss.backward() # DQN反向传播,更新参数
DQN.optimizer.step() # DQN更新参数
Double DQN求解MountainCar-v0问题的完整代码
代码参考自(有改动):https://www.bilibili.com/video/BV1Ab411w7Yd?t=3359
训练网络的代码
- 训练好的网络保存为
'DQN_MountainCar-v0.pth'
# gym安装:pip install gym matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
import random
import torch
import torch.nn as nn
import numpy as np
import gym
from torch.utils.tensorboard import SummaryWriter
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.fc = nn.Sequential(
nn.Linear(2, 24),
nn.ReLU(),
nn.Linear(24, 24),
nn.ReLU(),
nn.Linear(24, 3)
)
self.MSELoss = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.parameters(), lr = 0.001)
def forward(self, inputs):
return self.fc(inputs)
env = gym.envs.make('MountainCar-v0')
env = env.unwrapped
DQN = Network() # DQN network, 需要训练的网络
Target_net = Network() # Target network
writer = SummaryWriter("logs_DQN_MountainCar") # 注意tensorboard的部分
stored_transition_cnt = 0 # 记录transition_cnt的次数
replay_buffer_size = 2000 # buffer size
discount_factor = 0.6 # 衰减系数
transition_cnt = 0 # 记录发生的transition的总次数
update_interval = 20 # 将net的参数load到net2的间隔
gamma = 0.9 # 折扣因子
batch_size = 1000 # batch size
replay_buffer = np.zeros((replay_buffer_size, 6)) # 初始化buffer 列中储存 s, a, state_, r
start_learning = False # 标记是否开始学习
Max_epoch = 50000 # 学习的回合数
epsilon = 0.1
graph_added = False
for i in range(Max_epoch):
state = env.reset() # 重置环境
while True:
if (random.randint(0,100) < 100*(discount_factor**transition_cnt)): # act greedy, 就是随机探索,刚开始所及探索多,后面变少
action = random.randint(0, 2)
else:
# 超过100次,我们用DQN,也就是训练的神经网络来选动作
# 我们用DQN,也就是训练的神经网络来选动作
output = DQN(torch.Tensor(state)).detach() # output中是[左走累计奖励, 右走累计奖励]
action = torch.argmax(output).data.item() # 用argmax选取动作
state_, reward, done, info = env.step(action) # 执行动作,获得env的反馈
# 自己定义一个reward
# 只根据小车的位置给reward
reward = state_[0] + 0.5
if (state_[0] <= -0.5):
reward = 100 * abs(state_[1])
# print('速度:', state_[1])
elif(state_[0] > -0.5 and state_[0] < 0.5):
reward = math.pow(2, 5*(state_[0] + 1)) + (100 * abs(state_[1])) ** 2
elif(state_[0] >= 0.5):
reward = 1000
replay_buffer[stored_transition_cnt % replay_buffer_size][0:2] = state
replay_buffer[stored_transition_cnt % replay_buffer_size][2:3] = action
replay_buffer[stored_transition_cnt % replay_buffer_size][3:5] = state_
replay_buffer[stored_transition_cnt % replay_buffer_size][5:6] = reward
stored_transition_cnt += 1
state = state_
if stored_transition_cnt > replay_buffer_size:
# 如果到达update_interval,则将net的参数load到net2中
if transition_cnt % update_interval == 0:
Target_net.load_state_dict(DQN.state_dict())
# 从replay buffer中提取一个batch,注意可以是随机提取.
# 提取之后将其转成tensor数据类型,以便输入给神经网络
index = random.randint(0, replay_buffer_size - batch_size -1)
batch_state = torch.Tensor(replay_buffer[index:index + batch_size, 0:2])
batch_action = torch.Tensor(replay_buffer[index:index + batch_size, 2:3]).long()
batch_state_ = torch.Tensor(replay_buffer[index:index + batch_size, 3:5])
batch_reward = torch.Tensor(replay_buffer[index:index + batch_size, 5:6])
# 用tensorboard可视化神经网络
if(graph_added == False):
writer.add_graph(model=DQN, input_to_model=batch_state)
writer.add_graph(model=Target_net, input_to_model=batch_state)
graph_added = True
# 训练-更新网络:gradient descent updates
# 我们用Target_net来计算TD-target
q = DQN(batch_state).gather(1, batch_action) # predict q-value by old network
q_next = Target_net(batch_state_).detach().max(1)[0].reshape(batch_size, 1) # predict q(s_t+1)
q_target = batch_reward + gamma * q_next # 用Target_net来计算TD-target
loss = DQN.MSELoss(q, q_target) # 计算loss
DQN.optimizer.zero_grad() # 将DQN上步的梯度清零
loss.backward() # DQN反向传播,更新参数
DQN.optimizer.step() # DQN更新参数
transition_cnt += 1
if not start_learning:
print('start learning')
start_learning= True
break
if done:
break
env.render()
torch.save(DQN.state_dict(), 'DQN_MountainCar-v0.pth')
writer.close()
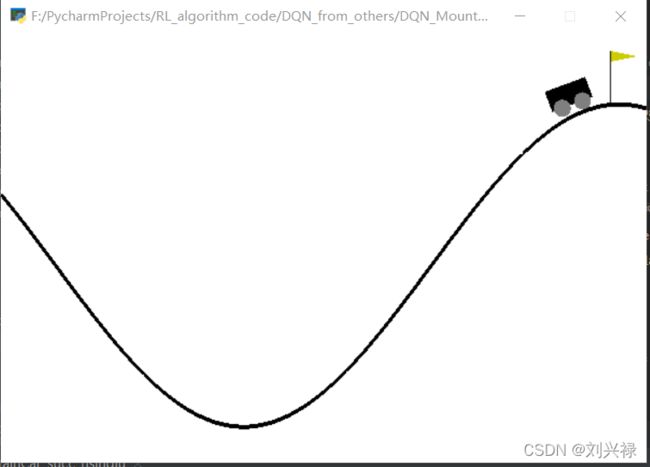
训练一分钟左右,小车即可爬到goal position,如下图。
测试网络的代码
- 我们加载(
load)训好的网络'DQN_MountainCar-v0.pth',用它来测试 - 代码如下
https://pypi.tuna.tsinghua.edu.cn/simple
import random
import torch
import torch.nn as nn
import numpy as np
import gym
from torch.utils.tensorboard import SummaryWriter
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.fc = nn.Sequential(
nn.Linear(2, 24),
nn.ReLU(),
nn.Linear(24, 24),
nn.ReLU(),
nn.Linear(24, 3)
)
self.MSELoss = nn.MSELoss()
self.optimizer = torch.optim.Adam(self.parameters(), lr = 0.001)
def forward(self, inputs):
return self.fc(inputs)
env = gym.envs.make('MountainCar-v0')
env = env.unwrapped
DQN = Network() # DQN network, 需要训练的网络
DQN.load_state_dict(torch.load('DQN_MountainCar-v0.pth'))
state = env.reset() # 重置环境
episode_reward_sum = 0 # 初始化该循环对应的episode的总奖励
while True: # 开始一个episode (每一个循环代表一步)
env.render() # 显示实验动画
output = DQN.forward(torch.Tensor(state)).detach() # output中是[左走累计奖励, 右走累计奖励]
action = torch.argmax(output).data.item() # 用argmax选取动作
state_, reward, done, info = env.step(action) # 执行动作,获得env的反馈
if done:
print(f'finished')
break
运行代码,发现Car在一段时间后就会爬上坡,如下图所示。
小结
- DQN可以处理状态-动作二元组爆炸的情况,同时也可以处理状态-动作二元组较少的情况。
- DQN是用一个神经网络去近似最优状态-动作函数。
- DQN存在过高评估的现象。处理方法是:(A)
为了解决取最大化带来的过高估计,可以Double DQN的方法。(B)为了解决自提升(bootstrapping)带来的过高估计,我们可以使用一个Target network来计算TD target,而不是用训练网络来计算TD target。 - Double DQN中,我们用DQN Q ( s , a ; w ) Q(s, a; \mathbf{w}) Q(s,a;w)选择下一步要做的动作,即 a ∗ = argmax a Q ( s t + 1 , a ; w ) a^{*}=\underset{a}{\text{argmax}}{Q(s_{t+1}, a; \mathbf{w})} a∗=aargmaxQ(st+1,a;w); 用Target Network计算TD target,即 y target = r t + γ ⋅ Q ( s t + 1 , a ∗ ; w − ) y_{\text{target}}=r_t + \gamma \cdot Q(s_{t+1}, a^{*}; \mathbf{w}^{-}) ytarget=rt+γ⋅Q(st+1,a∗;w−).
- 为了消除transition序列的相关性以及经验的浪费,我们可以使用经验回放(Experience replay)。
这些笔记是小编查阅众多资料,仔细总结和推导得来的,我自己觉得写的非常之详细了,对小白也是非常友好。希望可以帮到大家。如果推文中有纰漏指出,请多多指教。
参考文献
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Hassabis, D. (2015). Human-level control through deep reinforcement learning. nature, 518(7540), 529-533.
- Van Hasselt, Hado, Arthur Guez, and David Silver. “Deep reinforcement learning with double q-learning.” Proceedings of the AAAI conference on artificial intelligence. Vol. 30. No. 1. 2016.
- Wang Shusen的教学视频,网址:https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0
作者: 刘兴禄,清华大学,清华-伯克利深圳学院,博士在读