LR-ASPP论文
论文地址:https://arxiv.org/abs/1905.02244、
摘要
我们提出了基于互补搜索技术的组合以及一个新颖的架构设计的下一代移动网络。MobileNetV3通过结合NetAdapt算法补充的硬件网络架构搜索(NAS)调整到移动电话cpu上,随后通过新的架构进步进行了改进。本文开始探索如何自动搜索算法和网络设计可以一起工作,利用互补的方法来改善整体的艺术状态。通过这个过程,我们为发布创建了两个新的MobileNet模型:MobileNetV3-Large和MobileNetV3-Small,它们针对高资源用例和低资源用例。然后,这些模型被调整并应用于目标检测和语义分割的任务。本文提出了一种高效的分割解码器Lite Reduced Atrous Spatial Pyramid Pooling (LR-ASPP)。我们在移动分类、检测和分割方面取得了新的进展。MobileNetV3-Large比MobileNetV2在ImageNet分类上更准确3.2%,同时减少20%的延迟。MobileNetV3-Small比具有相当延迟的MobileNetV2模型更精确6.6%。mobilenetv3 -大型检测速度超过25%,与MobileNetV2在COCO检测上大致相同的精度。MobileNetV3-Large LRASPP比MobileNetV2 R-ASPP快34%,在类似的城市景观分割精度。
介绍
高效的神经网络正在移动应用程序中变得无处不在,从而实现全新的设备上体验。它们也是个人隐私的关键,让用户无需将数据发送到服务器进行评估就能从神经网络中获益。神经网络效率的进步不仅通过更高的准确性和更低的延迟改善用户体验,而且通过减少电力消耗来帮助保存电池寿命。本文描述了我们开发MobileNetV3 Large和Small模型的方法,目的是为设备上的计算机视觉提供下一代高精度、高效的神经网络模型。新的网络推动了技术的发展,并演示了如何将自动搜索与新颖的架构相结合,以构建有效的模型。
本文的目标是开发最佳的移动计算机视觉架构,优化移动设备上的准确性和延迟的权衡。为了实现这一点,我们引入了
(1)互补搜索技术,
(2)对移动设置实用的非线性的新高效版本,
(3)新的高效网络设计,
(4)新的高效分割解码器。
我们提供了详尽的实验来证明这种技术的有效性和价值,并在广泛的使用案例和手机上进行了评估。

图一:在延迟和准确度之间的权衡。图片的尺寸为224,MobileNetV3 Large和Small使用0.75、1和1.25不同的乘数来显示性能

图2:计算量与准确度之间的权衡。输入分辨率224和使用乘数0.35,0.5,0.75,1和1.25。
相关工作
近年来,设计深度神经网络体系结构以实现精度和效率之间的最佳平衡已成为一个活跃的研究领域。新颖的人工结构和算法神经结构搜索在这一领域的发展中发挥了重要作用。
SqueezeNet广泛使用1x1卷积与挤压和扩展模块,主要关注于减少参数的数量。最近的工作将重点从减少参数转移到减少操作数量(mads)和实际测量的延迟。MobileNetV1采用深度可分卷积,大大提高了计算效率。MobileNetV2通过引入具有反向残差和线性瓶颈的资源高效块来扩展这一点。ShuffleNet利用组卷积和信道shuffle操作进一步降低mads。CondenseNet在训练阶段学习组卷积,以保持层之间有用的密集连接,以便特性重用。ShiftNet提出了与逐点卷积交织的移位操作,以取代昂贵的空间卷积。
为了使建筑设计过程自动化,首先引入了强化学习(RL)来搜索具有竞争精度的高效建筑。一个完全可配置的搜索空间可能会以指数级增长且难以处理。所以早期的架构搜索工作集中在单元层的结构搜索上,相同的单元在所有层中都被重用。最近,[43]探索了一种块级分层搜索空间,允许在网络的不同分辨率块上使用不同的层结构。为了降低搜索的计算成本,可微架构[28, 5, 45]使用了搜索框架,并进行了梯度优化。关注于使现有网络适应受限的移动平台,[48,15,12]提出了更高效的自动化网络简化算法。
量化[23,25,47,41,51,52,37]是通过降低精度算法来提高网络效率的另一项重要补充工作。最后,知识蒸馏[4,17]提供了一种补充方法,在大型“教师”网络的指导下,生成精确的小“学生”网络。
Efficient Mobile Building Blocks
移动模式建立在越来越高效的基础之上。MobileNetV1[19]引入深度可分离卷积,作为传统卷积层的有效替代。深度可分离卷积通过将空间滤波从特征生成机制中分离出来,有效地分解了传统卷积。深度可分离卷积由两个独立的层定义:用于空间滤波的轻权重深度卷积和用于特征生成的重权重1x1逐点卷积。
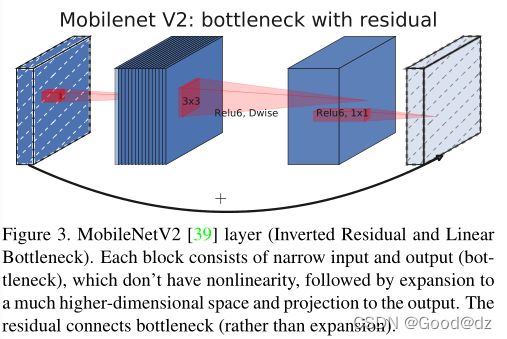
MobileNetV2[39]引入了线性瓶颈和倒置残差结构,以便利用问题的低秩性质,使层结构更有效。这个结构如图3所示,由1x1展开卷积、深度卷积和1x1投影层定义。当且仅当输入和输出具有相同数量的通道时,它们与残留连接。该结构在输入和输出处保持一个紧凑的表示,同时在内部扩展到一个高维特征空间,以增加非线性全通道转换的表达。
MnasNet[43]构建在MobileNetV2结构之上,通过在瓶颈结构中引入基于挤压和激励的轻量级注意模块。请注意,与[20]中提出的基于ResNet的模块相比,挤压和激励模块集成在不同的位置。该模块被放置在展开中的深度过滤器之后,以便将注意力应用到图4中最大的表示上。
对于MobileNetV3,我们使用这些层的组合作为构建块,以构建最有效的模型。层也可以用修正的非线性进行升级[36,13,16]。挤压和激励以及非线性都使用了sigmoid,这在不动点算法中计算效率很低,也很难保持精度,所以我们用hard sigmoid代替它[2,11],如5.2节所述。

网络搜索
网络搜索已经成为发现和优化网络架构的一个非常强大的工具[53,43,5,48]。对于MobileNetV3,我们使用平台感知的NAS通过优化每个网络块来搜索全局网络结构。然后,我们使用NetAdapt算法在每一层中搜索过滤器的数量。这些技术是互补的,可以结合起来有效地为给定的硬件平台找到优化的模型。
Platform-Aware NAS for Block-wise Search
我们使用一种平台感知的神经体系结构方法来查找全局网络结构。由于我们使用相同的基于rnn的控制器和相同的分解层次搜索空间,对于目标延迟在80ms左右的大型移动模型,我们发现了与【43】相似的结构。因此,我们只是简单地重用相同的MnasNet-A1作为我们最初的大型移动模型,然后在其上应用NetAdapt和其他优化。
然而我们发现原始的反馈设计并不能优化small mobile模型,具体而言,它使用了一个多目标反馈来估计pareto-optimal解决方案,通过给每个基于目标时延TAR的模型来ing哼准确率与时延。我们观察到,随着小模型延时的增加,准确率变化会更加显著;因此,我们需要一个更小的权重系数w=-0.15来补偿不同延时带来的进度变化。在新权重系数w的增强下,我们从头开始搜索一个新的结构,来寻找出初始化seed模型,然后应用NetAdapt与其他优化方法来获得最终的mobilenetv3-small模型。
NetAdapt for Layer-wise Search
我们在搜索架构中使用的第二种技术时Netadapt。这种方法是对platform-aware NAS的补充:它允许按顺序地每个层的结构进行微调,而不是试图直接预测粗粒度的全局结构。我们详细参考了原文的细节。简而言之,技术流程如下:
1.第一步通过plateform-aware NAS找到seed网络结构。
2.对于每一步:
(a)生成一个新方法的集合。每一个方法表示一个架构的修改:和之前的步骤相比,在延迟方面生成至少减少δ
(b)对新方法集合中的每一方法,论文使用之前的步骤生成的模型作为预训练模型,并填充这一新的架构,裁剪和随机初始化这些丢失的权重。微调每一方法T TT步,获得一个粗糙的准确率评估。
(c)依据一些准则选择最好的方法。
3.遍历上诉步骤直到达到目标延迟
论文使用的准则:最小化延迟变化与准确率变化的比率

网络提升
除了网络搜索外,论文也引入几个新的组件到模型中来提升最终的模型。论文重新设计了在网络开始和结束部分计算昂贵的层。同时,论文也引入了一个新的非线性激活函数:h-swish,它是最近非线性激活函数swish改进版,这样能够加速计算并让量化更友好。
重新设计计算昂贵层
一旦通过架构搜索发现模型,论文发现最后几层和开始几层比其他部分计算代价更高。论文对架构提出几点改进来减少这些速度慢的层的延迟但是维护准确率