Dogs vs. Cats比赛——代码调试&模型优化笔记
文章目录
-
- 1 图像预处理
-
- 1.1 标准化和归一化
- 1.2 灰度化
- 1.3 数据增强
- 1.4 其他
- 2 模型搭建
- 3 调参 & 模型优化
- 4 其他
- 5 待完成
1 图像预处理
1.1 标准化和归一化
- 相关资料
- 机器学习面试之归一化与标准化 - 简书
- CNN 入门讲解:什么是标准化(Normalization)? - 知乎
- 公式
- 归一化: x i − min ( x i ) max ( x i ) − min ( x i ) \frac{x_{i}-\min \left(x_{i}\right)}{\max \left(x_{i}\right)-\min \left(x_{i}\right)} max(xi)−min(xi)xi−min(xi)
- 标准化: x i − x ‾ s d ( x ) \frac{x_{i}-\overline{x}}{s d(x)} sd(x)xi−x
- 标准化适用范围更广;归一化会把数据挤到一起去eg. 1 2 10000,1 2就被挤到一起了
- 最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!
- 实测:加了BN之后,val loss震荡变小,数值降低
# 找到的一些归一化/标准化的操作,未测试
# 归一化
norm_image = cv2.normalize(img, None, alpha=0, beta=1, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_32F)
# 标准化
img -= np.mean(img, keepdims=True)
img /= np.std(img, keepdims=True) + K.epsilon()
1.2 灰度化
- 目的
- 降低维度、减小计算量(参数量)
- 算是某种意义上的标准化?减少网络对颜色的过拟合,提高模型泛化能力
# OpenCV读取
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
# Pillow读取
img = pil_image.open(expand_path(p))
img = img.convert('L')
1.3 数据增强
可用Keras中提供的ImageDataGenerator()函数
列出了一些常用的参数,详见:https://keras.io/preprocessing/image/
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=10, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False) # randomly flip images
1.4 其他
- 颜色读取顺序
- OpenCV读取颜色顺序是以BGR方式读取的
- Pillow以RGB方式读取
- plt按RGB方式显示
img1 = cv2.imread('46.bmp')
# img1 = cv2.cvtColor(img1, cv2.COLOR_BGR2RGB) # 转换通道顺序
img2 = Image.open('46.bmp')
img2 = np.asarray(img2)
plt.subplot(121),plt.imshow(img1)
plt.subplot(122),plt.imshow(img2)
- 读取or显示灰度图
img = cv2.imread(TRAIN_DIR+'cat.0.jpg', cv2.IMREAD_GRAYSCALE)
plt.imshow(img, cmap='gray')
- 增加灰度图通道维度
image = image.reshape(ROWS, COLS, 1)
2 模型搭建
-
搭建完网络后用
model.summary()查看网络结构,看是否正确 -
Keras模型可视化
-
安装相应模块
-
pip install pydot-ng pip install graphviz pip install pydot -
安装了以上模块,但是还是报错误,发现GraphViz的可执行文件没有:
OSError: pydot failed to call GraphViz.Please install GraphViz (https://www.graphviz.org/) and ensure that its executables are in the $PATH.- 使用
apt install graphviz,问题解决。
- 使用
-
打印模型图
-
from keras.utils import plot_model plot_model(model, to_file='model.png')
-
-
-
注意设置通道顺序
from keras import backend
backend.set_image_dim_ordering('th') # th通道最前,tf通道最后
-
训练技巧——Callbacks
-
early_stopping、ModelCheckpoint、learning_rate_reduction
-
不能用keras 2.2.3 保存模型的时候有bug,升级到2.2.4解决
KeyError: 'Cannot set attribute. Group with name "keras_version" exists.' -
第14章 使用保存点保存最好的模型 · 深度学习:Python教程
-
learning_rate_reduction = ReduceLROnPlateau(monitor='val_acc',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.00001)
early_stopping = EarlyStopping(monitor='val_loss', patience=6, min_delta=0.0002, verbose=1, mode='auto')
filepath="./weights/weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='auto')
model_his = model.fit_generator(datagen.flow(X_train,Y_train, batch_size=batch_size),
epochs = epochs, validation_data = (X_val,Y_val),
shuffle=True, verbose = 1,
steps_per_epoch=X_train.shape[0] // batch_size
, callbacks=[learning_rate_reduction,
early_stopping, checkpoint])
3 调参 & 模型优化
过拟合
Conv2D、Batch Normalization、activation、pooling、dropout层的效果和顺序
- 卷积网络中是否应该加dropout & 加在哪?
- 实测有用,可以加在max pooling层后面,降低验证集的loss,可提高模型泛化能力
- 论文《Max-Pooling Dropout for Regularization of Convolutional Neural Networks》
- max pooling + dropout 与 stochastic pooling 效果对比图:
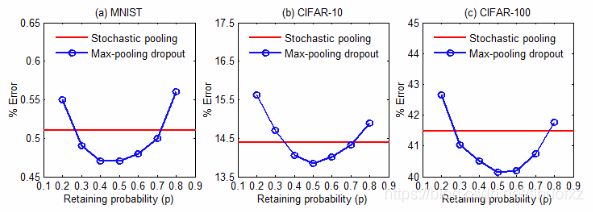
- 但也有研究指出不要在CNN中用dropoutDon’t Use Dropout in Convolutional Networks
- Batch Normalization
- BN作用是为了防止梯度弥散,让每一层的数据分布更均匀
- 什么是批标准化 (Batch Normalization) - 莫烦 - 知乎
- 深度学习中 Batch Normalization为什么效果好? - 魏秀参的回答 - 知乎

- 前三步是标准化数据,最后一步反标准化
- γ \gamma γ、 β \beta β让神经网络自己去学习,看BN到底有没有用,要是无效的话,用这两个参数抵消一些BN
- BN作用是为了防止梯度弥散,让每一层的数据分布更均匀
- conv2D、BN、ReLU层的顺序
- 说什么的都有。。。玄学
- 主流的几种:Conv->ReLU->BN、Conv->BN->ReLU、BN->ReLU->Conv
4 其他
-
图像读取顺序
- 用各种库读取进来的图片顺序和原有图像顺序很可能不一致
- 要把图像文件名和图像数据对应上
-
图像标签编码
- 分类问题最好都用One-hot编码方式,即使是二分类问题、
- 不知道为什么,本次竞赛使用单个输出0or1,在训练验证集表现ok,测试集表现很差。换成one-hot之后解决。
5 待完成
- 各种优化器的选择,适用场景 RMSProp、Adam等
- 卷积核数量的设置